这篇文章给大家介绍JVM FullGC引发的宕机事故的实例分析,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
先简单说说线上生产系统的一个背景,因为仅仅是文章作为案例来讲,所以弱化大量的业务背景。
简单来说,这是一套分布式系统,系统 A 需要将一个非常核心以及关键的数据通过网络请求,传输给另外一个系统 B。
这里其实就考虑到了一个问题,如果系统 A 刚刚将核心数据传递给了系统 B,结果系统 B 莫名其妙宕机了,岂不是会导致数据丢失?
所以在这个分布式系统的架构设计中,采取了非常经典的一个 Quorum 算法。
这个算法简单来说,就是系统 B 必须要部署奇数个节点,比如说至少部署 3 台机器,或者是 5 台机器,7 台机器,类似这样子。
然后系统 A 每次传输一个数据给系统,都必须要对系统 B 部署的全部机器都发送请求,将一份数据传输给系统B部署的所有机器。
要判定系统 A 对系统 B 的一次数据写是成功的,要求系统 A 必须在指定时间范围内对超过 Quorum 数量的系统 B 所在机器传输成功。
举个例子,假设系统 B 部署了 3 台机器,那么他的 Quorum 数量就是:3 / 2 + 1 = 2,也就是说系统 B 的 Quorum 数量就是:所有机器数量 / 2 + 1。
所以系统 A 要判定一个核心数据是否写成功,如果系统 B 一共部署了 3 台机器的话,那么系统 A 必须在指定时间内收到 2 台系统 B 所在机器返回的写成功的响应。
此时系统 A 才能认为这条数据对系统 B 是写成功了。这个就是所谓的 Quorum 机制。
也就是说,分布式架构下,系统之间传输数据,一个系统要确保自己给另外一个系统传输的数据不会丢失,必须要在指定时间内,收到另外一个系统 Quorum(大多数)数量的机器响应说写成功。
这套机制实际上在很多分布式系统、中间件系统中都有非常广泛的使用,我们线上的分布式系统也是采用了这个 Quorum 机制在两个系统之间传输数据。
给大家上一张图,一起来看一下这套架构长啥样:
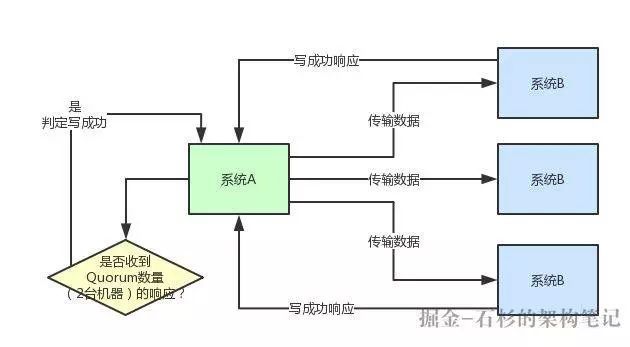
如上图所示,图中很清晰的展示了系统 A 和系统 B 之间传输一份数据时的 Quorum 机制。
接下来,我们用代码给大家展示一下,上面的 Quorum 写机制在代码层面大概是什么样子的。
PS:因为实际这套机制涉及大量的底层网络传输、通信、容错、优化的东西,所以下面代码经过了大幅度简化,仅仅表达出了一个核心的意思。
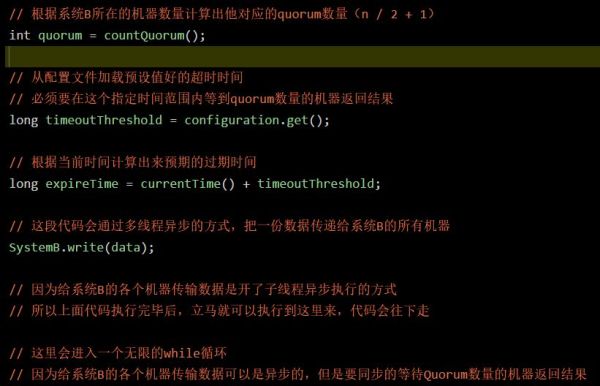
上面就是经过大幅精简后的代码,不过核心的意思是表达清晰了。大家可以仔细看两遍,其实还是很容易弄懂的。
这段代码含义很简单,说白了就是异步开启线程发送数据给系统 B 所有的机器,同时进入一个 while 循环等待系统 B 的 Quorum 数量的机器返回响应结果。
如果超过指定超时时间还没收到预期数量的机器返回结果,那么就判定系统 B 部署的集群出现故障,接着让系统 A 直接退出,相当于系统 A 宕机。
整个代码,就是这么个意思!
光是看代码其实没啥难的,但是问题就在于线上运行的时候,可不是跟你写代码的时候想的一样简单。
有一次线上生产系统运行的过程中,整体系统负载都很平稳,本来是不应该有什么问题,但是结果突然收到报警,说系统 A 突然宕机了。
然后就开始进行排查,左排查右排查,发现系统 B 集群都好好的,不应该有问题。
然后再查查系统 A,发现系统 A 别的地方也没什么问题。***结合系统 A 自身的日志,以及系统 A 的 JVM FullGC 进行垃圾回收的日志,我们才算是搞清楚了具体的故障原因。
其实原因非常的简单,就是系统 A 在线上运行一段时间后,会偶发性的进行长时间 Stop the World 的 JVM FullGC,也就是大面积垃圾回收。
但是,此时会造成系统 A 内部的工作线程大量的卡顿,不再工作。要等 JVM FullGC 结束之后,工作线程才会恢复运作。
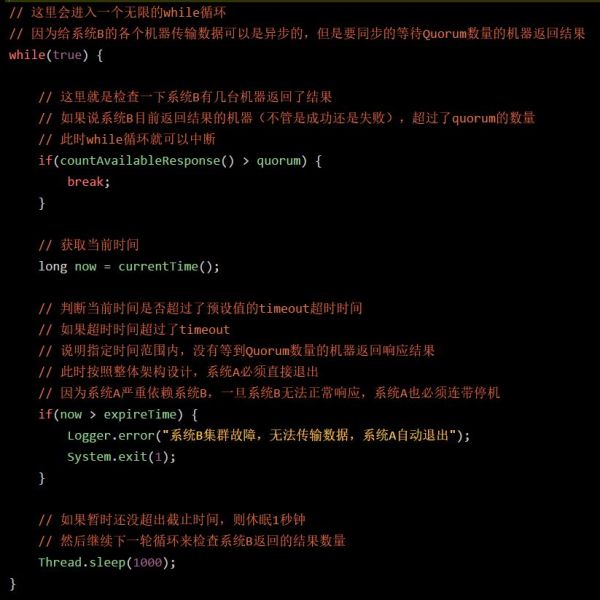
我们来看下面那个代码片段:

但是这种系统 A 的莫名宕机是不正确的,因为如果没有 JVM FullGC,本来上面那个 if 语句是不会成立的。
它会停顿 1 秒钟进入下一轮 while 循环,接着就可以收到系统 B 返回的 Quorum 数量的结果,这个 while 循环就可以中断,继续运行了。
结果因为出现了 JVM FullGC 卡顿了几十秒,导致莫名其妙就触发了 if 判断的执行,系统 A 莫名其妙就退出宕机了。
所以,线上的 JVM FullGC 导致的系统长时间卡顿,真是造成系统不稳定运行的隐形杀手之一啊!
至于上述代码稳定性的优化,也很简单。我们只要在代码里加入一些东西,监控一下上述代码中是否发生了 JVM FullGC。
如果发生了 JVM FullGC,就自动延长 expireTime 就可以了。
比如下面代码的改进:
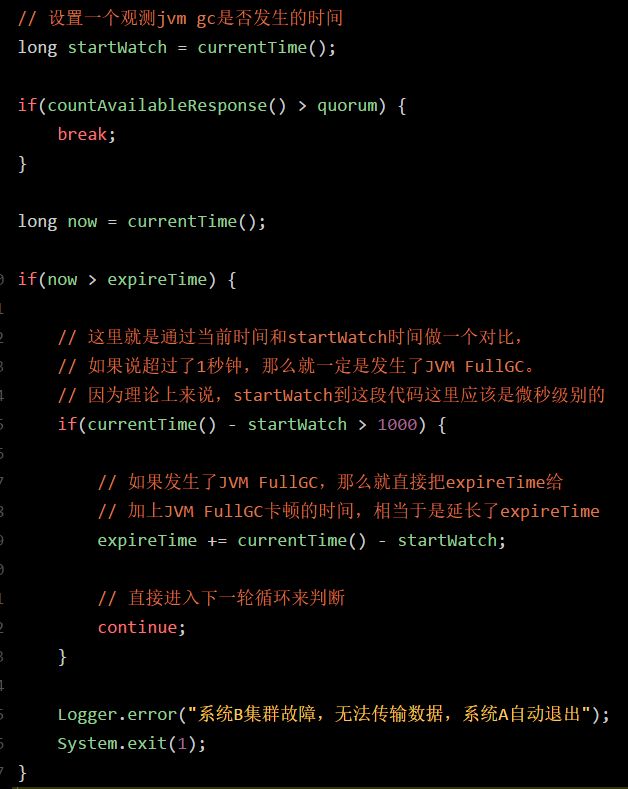
通过上述代码的改进,就可以有效的优化线上系统的稳定性,保证其在 JVM FullGC 发生的情况下,也不会随意出现异常宕机退出的情况了。
关于JVM FullGC引发的宕机事故的实例分析就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://mp.weixin.qq.com/s/o5H_1GBVvF-3MPf1xVWqJg?tdsourcetag=s_pcqq_aiomsg



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



