本篇内容介绍了“Apache四个大型开源数据和数据湖系统是什么”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
管理大数据所需的许多功能是其中一些是事务,数据突变,数据校正,流媒体支持,架构演进,因为酸性事务能力Apache提供了四种,用于满足和管理大数据。
Apache Sharding Sphere
它是一个众所周知的数据库中间件系统。它包含三个独立的模块,JDBC,Proxy和Sidecar(计划),但在部署时它们都混合在一起。Apache Shardingsphere提供标准化的数据分片,分布式事务和数据库治理功能,可以针对各种多样化应用方案,例如Java同义,异构语言和云本机。
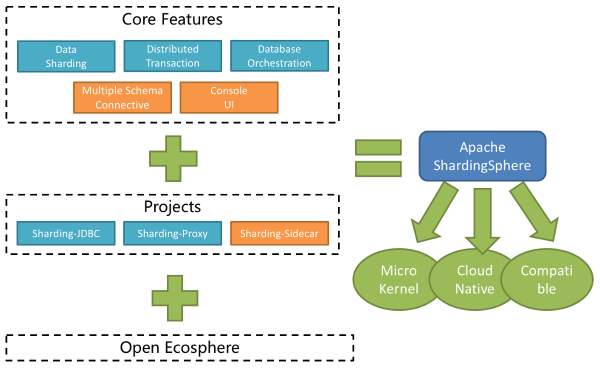
今天的电子商务主要依赖于关系数据库和分布式环境,高效查询的激增和数据快速转移成为公司关系数据库的主要目标Apache Shardingsphere是伟大的关系数据库中间件生态系统,它为其开发人员提供了合理的计算和存储功能关系数据库。

Apache Iceberg
Apache Iceberg 最初由Netflix设计和开发。关键的想法是组织目录树中的所有文件,如果您需要在2018年5月创建的文件在Apache iceBerg中,您只需找出该文件并只读该文件,也没有必要阅读您可以阅读的其他文件忽略您对当前情况不太重要的其他数据。核心思想是跟踪时间表上表中的所有更改。
它是一种用于跟踪非常大的表的数据湖解决方案,它是一个轻量级数据湖解决方案,旨在解决列出大量分区和耗时和不一致的元数据和HDFS数据的问题。它包含三种类型的表格格式木质,Avro和Orc.in Apache iceberg表格格式与文件集合和文件格式的集合执行相同的东西,允许您在单个文件中跳过数据
它是一种用于在非常大型和比例表上跟踪和控制的新技术格式。它专为对象存储而设计(例如S3)。Iceberg 中更重要的概念是一个快照。快照表示一组完整的表数据文件。为每个更新操作生成新快照。
Apache Iceberg 有以下特征:
ACID 事务能力,可以在不影响当前运行数据处理任务的情况下进行上游数据写入,这大大简化了ETL; Iceberg 提供更好的合并能力,可以大大减少数据存储延迟;
支持更多的分析引擎优异的内核抽象使其不绑定到特定的计算引擎。目前,冰山支持的计算发动机是Spark,Flink,Presto和Hive。
Apache Iceberg为文件存储,组织,基于流的增量计算模型和基于批处理的全尺度计算模型提供统一和灵活的数据。批处理和流式传输任务可以使用类似的存储模型,并且不再隔离数据。iceberg支持隐藏的分区和分区演进,这促进了业务更新数据分区策略。支持三个存储格式木质,Avro和Orc。
增量读取处理能力iceBerg支持以流式方式读取增量数据,支持流和传输表源。
Apache Hudi
Apache Hudi是一个大数据增量处理框架,它试图解决摄取管道的效率问题和在大数据中需要插入,更新和增量消耗基元的ETL管道。它是针对分析和扫描优化的数据存储抽象,其可以在几分钟内将更改应用于HDF中的数据集,并支持多个增量处理系统来处理数据。通过自定义InputFormat与当前Hadoop生态系统(包括Apache Hive,Apache Parquet,Presto和Apache Spark)的集成使框架无缝为最终用户。
Hudi的设计目标是快速且逐步更新HDFS上的数据集。有两种更新数据的方法:读写编写并合并读取。写入模式上的副本是当我们更新数据时,我们需要通过索引获取更新数据中涉及的文件,然后读取数据并合并更新的数据。这种模式更易于更新数据,但是当涉及的数据更新时更新时,效率非常低;并合并读取是要将更新写入单独的新文件,然后我们可以选择与原始数据同步或异步地将更新的数据与原始数据合并(可以调用组合),因为更新的仅编写新文件,所以此模式将更新更快。
在Hudi系统的帮助下,很容易在MySQL,HBase和Cassandra中收集增量数据,并将其保存到Hudi。然后,presto,spark和hive可以快速阅读这些递增更新的数据。
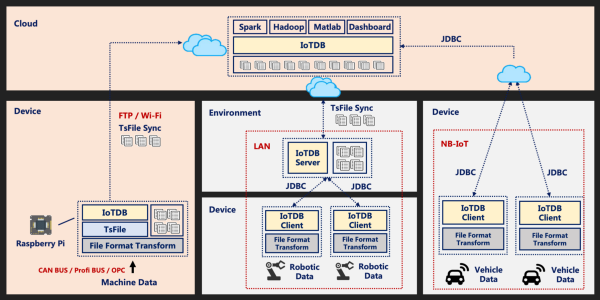
Apache Iotdb
它是一种物联网时间序列工业数据库,Apache IOTDB是一款集成,存储,管理和Anallyze Thge IoT时间序列数据的软件系统。Apache IOTDB采用具有高性能和丰富功能的轻量级架构,并与Apache Hadoop,Spark和Flink等进行深度集成,可以满足工业中大规模数据存储,高速数据读数和复杂数据分析的需求事物互联网领域。
Apache IOTDB套件由多个组件组成,它们一起形成一系列功能,例如“数据收集 - 数据写入数据存储 - 数据查询 - 数据可视化数据分析”。其结构如下:
用户可以导入从设备上的传感器收集的时间序列数据,服务器负载和CPU内存等消息队列中的时间序列数据,时间序列数据,应用程序的时间序列数据或从其他数据库到本地或远程IOTDB的时间序列数据JDBC。在。用户还可以直接将上述数据写入本地(或在HDFS上)TSFile文件。TSFile文件可以写入HDF,以实现数据处理平台的数据处理平台等异常检测和机器学习等数据处理任务。对于写入HDFS或本地的TSFile文件,您可以使用TSFile-Hadoop或TSFile-Spark连接器来允许Hadoop或Spark处理数据。分析结果可以写回TSFile文件。IOTDB和TSFile还提供相应的客户端工具,以满足用户在SQL,脚本和图形格式中查看数据的需求。
“Apache四个大型开源数据和数据湖系统是什么”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





