HDFSдёӯйңҖиҰҒжҺҢжҸЎд»Җд№ҲзҹҘиҜҶзӮ№
е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢHDFSдёӯйңҖиҰҒжҺҢжҸЎд»Җд№ҲзҹҘиҜҶзӮ№пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳдёҚжҖҺд№ҲдәҶи§ЈпјҢеӣ жӯӨеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©жҲ‘们дёҖиө·еҺ»дәҶи§ЈдёҖдёӢеҗ§пјҒ
HadoopдҪңдёәеӨ§ж•°жҚ®ж—¶д»Јд»ЈиЎЁжҖ§зҡ„и§ЈеҶіж–№жЎҲиў«еӨ§е®¶жүҖзҶҹзҹҘпјҢе®ғдё»иҰҒеҢ…еҗ«дёӨйғЁеҲҶеҶ…е®№пјҡ
еүҚйқўжҲ‘们еҲҶжһҗеӯҳеӮЁж–№жЎҲзҡ„еҸ‘еұ•зҡ„ж—¶еҖҷжңүжҸҗеҲ°еҲҶеёғејҸж–Ү件еӯҳеӮЁзҡ„еҮәзҺ°жҳҜдёәдәҶи§ЈеҶіеӯҳеӮЁзҡ„дёүеӨ§й—®йўҳпјҡеҸҜжү©еұ•жҖ§пјҢй«ҳеҗһеҗҗйҮҸпјҢй«ҳеҸҜйқ жҖ§
йӮЈд№ҲHadoopзҡ„ж ёеҝғHDFSжҳҜеҰӮдҪ•и§ЈеҶідёҠйқўдёүдёӘй—®йўҳзҡ„е‘ў?
е…¶е®һи®ҫи®ЎдёҖдёӘзі»з»ҹжҲ‘们иҰҒиҖғиҷ‘еҲ°е®ғзҡ„еә”з”ЁеңәжҷҜпјҢ然еҗҺеҜ№е®ғзҡ„еҠҹиғҪе’Ңзү№жҖ§иҝӣиЎҢи®ҫи®ЎпјҢеҒҡеҮәеҸ–иҲҚгҖӮжҲ‘们еҸҜиғҪдјҡе…іжіЁиҝҷеҮ дёӘй—®йўҳпјҡ
еҺҹе§ӢеӯҳеӮЁж јејҸ or зү№ж®ҠеӯҳеӮЁж јејҸпјҢйҖҡиҝҮд»Җд№Ҳж јејҸеӯҳеӮЁжүҚиғҪж–№дҫҝзҡ„з®ЎзҗҶж•°жҚ®пјҢдҝқиҜҒж•°жҚ®зҡ„иҝҒ移е’Ңе®үе…ЁгҖӮ
еӨ§ж–Ү件 or е°Ҹж–Ү件пјҢж–Ү件系з»ҹйҖӮеҗҲеӨ§ж–Ү件иҝҳжҳҜе°Ҹж–Ү件еӯҳеӮЁпјҢеҰӮдҪ•жҸҗдҫӣI/Oж•ҲзҺҮгҖӮ
ж•°жҚ®й«ҳеҸҜз”Ё or з©әй—ҙеҲ©з”ЁзҺҮпјҢйҖҡиҝҮеӨҚеҲ¶еүҜжң¬жҠҖжңҜжҸҗй«ҳж•°жҚ®еҸҜз”ЁжҖ§еҝ…然дјҡйҷҚдҪҺз©әй—ҙеҲ©з”ЁзҺҮпјҢеә”иҜҘеҰӮдҪ•еҸ–иҲҚгҖӮ
жҳҜеҗҰжңүе…ғж•°жҚ®жңҚеҠЎпјҢе…ғж•°жҚ®жңҚеҠЎжҳҜдҝқеӯҳеӯҳеӮЁж•°жҚ®е…ғж•°жҚ®дҝЎжҒҜзҡ„жңҚеҠЎпјҢиҜ»еҶҷж•°жҚ®йғҪйңҖиҰҒиҝһжҺҘе…ғж•°жҚ®жңҚеҠЎеҷЁдҝқиҜҒдёҖиҮҙжҖ§гҖӮеӯҳеңЁе…ғж•°жҚ®жңҚеҠЎеҠҝеҝ…дјҡеӯҳеңЁеҚ•зӮ№й—®йўҳе’ҢжҖ§иғҪ瓶йўҲй—®йўҳгҖӮ
дёҠйқўиҝҷдёӘ4дёӘй—®йўҳеҲ’йҮҚзӮ№пјҢиҰҒиҖғзҡ„!!!
HDFSе®ғзҡ„и®ҫи®Ўзӣ®ж Үе°ұжҳҜжҠҠи¶…еӨ§зҡ„ж•°жҚ®йӣҶеӯҳеӮЁеҲ°еӨҡеҸ°жҷ®йҖҡи®Ўз®—жңәдёҠпјҢ并且еҸҜд»ҘжҸҗдҫӣй«ҳеҸҜйқ жҖ§е’Ңй«ҳеҗһеҗҗйҮҸзҡ„жңҚеҠЎпјҢж”ҜжҢҒйҖҡиҝҮж·»еҠ иҠӮзӮ№зҡ„ж–№ејҸеҜ№йӣҶзҫӨиҝӣиЎҢжү©е®№гҖӮжүҖд»ҘHDFSжңүзқҖе®ғиҮӘе·ұзҡ„и®ҫи®ЎеүҚжҸҗпјҡ
еҜ№еӯҳеӮЁеӨ§ж–Ү件ж”ҜжҢҒеҫҲеҘҪпјҢдёҚйҖӮз”ЁдәҺеӯҳеӮЁеӨ§йҮҸе°Ҹж–Ү件
йҖҡиҝҮжөҒејҸи®ҝй—®ж•°жҚ®пјҢдҝқиҜҒй«ҳеҗһеҗҗйҮҸиҖҢдёҚжҳҜдҪҺ延时зҡ„з”ЁжҲ·е“Қеә”
з®ҖеҚ•дёҖиҮҙжҖ§пјҢдҪҝз”ЁеңәжҷҜеә”дёәдёҖж¬ЎеҶҷе…ҘеӨҡж¬ЎиҜ»еҸ–пјҢдёҚж”ҜжҢҒеӨҡз”ЁжҲ·еҶҷе…ҘпјҢдёҚж”ҜжҢҒд»»ж„Ҹдҝ®ж”№ж–Ү件гҖӮ
еҶ—дҪҷеӨҮд»ҪжңәеҲ¶пјҢз©әй—ҙжҚўеҸҜйқ жҖ§(Hadoop3дёӯеј•е…Ҙзә еҲ з ҒжңәеҲ¶пјҢзә еҲ з ҒйңҖйҖҡиҝҮи®Ўз®—жҒўеӨҚж•°жҚ®пјҢе®һдёәйҖҡиҝҮж—¶й—ҙжҚўз©әй—ҙпјҢжңүе…ҙи¶Јзҡ„еҸҜд»ҘжҹҘзңӢRAIDзҡ„е®һзҺ°)
移еҠЁи®Ўз®—дјҳдәҺ移еҠЁж•°жҚ®пјҢдёәж”ҜжҢҒеӨ§ж•°жҚ®еӨ„зҗҶдё»еј з§»еҠЁи®Ўз®—дјҳдәҺ移еҠЁж•°жҚ®пјҢжҸҗдҫӣзӣёе…іжҺҘеҸЈгҖӮ
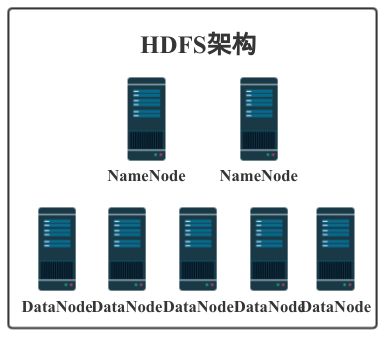
йҒөеҫӘд»ҘдёҠзҡ„и®ҫи®ЎеүҚжҸҗе’Ңзӣ®ж ҮжңҖз»Ҳзҡ„жҲҗе“Ғе°ұжҳҜжҲ‘们ж—Ҙеёёеә”з”Ёдёӯзҡ„HDFSдәҶгҖӮHDFSдё»иҰҒз”ұNameNodeе’ҢDataNodeжһ„жҲҗпјҢд»ҘMaster/SlaveжЁЎејҸиҝҗиЎҢгҖӮжҲ‘们жқҘиҜҰз»ҶдәҶи§ЈдёҖдёӢгҖӮ
ж•°жҚ®еқ—
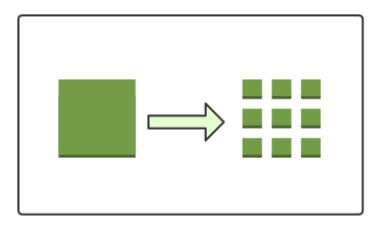
иҝҷдёӘе°ұеҜ№еә”еүҚйқўжҲ‘们жҸҗеҮәзҡ„з–‘й—®вҖңеҺҹе§ӢеӯҳеӮЁж јејҸ or зү№ж®ҠеӯҳеӮЁж јејҸвҖқпјҢеңЁHDFSдёҠжҠҪиұЎеҮәдәҶдёҖдёӘж•°жҚ®еқ—зҡ„жҰӮеҝөгҖӮеҸҜд»Ҙи®ӨдёәжҳҜHDFSзҡ„зү№ж®ҠеӯҳеӮЁж јејҸпјҢеҪ“дҪ еӯҳеӮЁж–Ү件зҡ„ж—¶еҖҷдёҚжҳҜд»Ҙж–Ү件дёәеҚ•дҪҚиҝӣиЎҢж•°жҚ®еӯҳеӮЁзҡ„пјҢиҖҢжҳҜд»Ҙж•°жҚ®еқ—дёәеҚ•дҪҚиҝӣиЎҢеӯҳеӮЁгҖӮиҝҷж ·жңүд»Җд№ҲеҘҪеӨ„е‘ў?йҰ–е…ҲпјҢе®ғеұҸи”ҪдәҶж–Ү件зҡ„жҰӮеҝөпјҢеҰӮжһңдҪ еӯҳдёҖдёӘи¶…еӨ§зҡ„ж–Ү件пјҢж–Ү件зҡ„еӨ§е°ҸеӨ§дәҺдҪ д»»дҪ•дёҖдёӘеҚ•дёӘзЈҒзӣҳзҡ„еӨ§е°ҸпјҢеңЁHDFSдёӯдјҡжҠҠдҪ зҡ„ж–Ү件еҲҮеүІжҲҗеӨҡдёӘж•°жҚ®еқ—пјҢеӯҳеӮЁеҲ°дёҚеҗҢжңәеҷЁзҡ„дёҚеҗҢзЈҒзӣҳдёӯгҖӮиҝҷж ·е°ұз®ҖеҢ–дәҶеӯҳеӮЁзі»з»ҹзҡ„и®ҫи®ЎпјҢиҖҢдё”д№ҹйҖӮз”ЁдәҺж•°жҚ®зҡ„еӨҮд»ҪгҖҒиҝҒ移еҠҹиғҪпјҢжҸҗй«ҳдәҶж•°жҚ®зҡ„е®№й”ҷжҖ§е’ҢеҸҜз”ЁжҖ§гҖӮ
NameNode
иҝҷдёӘеҜ№еә”еүҚйқўзҡ„з–‘й—®вҖңжҳҜеҗҰжңүе…ғж•°жҚ®жңҚеҠЎвҖқпјҢеңЁHDFSдёӯNameNodeе°ұиө·зқҖе…ғж•°жҚ®з®ЎзҗҶжңҚеҠЎзҡ„дҪңз”ЁпјҢе®ғз®ЎзҗҶзқҖж•ҙдёӘж–Ү件系з»ҹзҡ„е‘ҪеҗҚз©әй—ҙпјҢз»ҙжҠӨзқҖж–Ү件系з»ҹж ‘иҜҰжғ…并еҜ№е…¶жҢҒд№…еҢ–гҖӮ
еҪ“жҲ‘们еҶҷе…ҘжҲ–иҖ…иҜ»еҸ–ж•°жҚ®ж—¶йғҪйңҖиҰҒе…ҲиҝһжҺҘNameNodeпјҢиҺ·еҸ–еҸҜж“ҚдҪңзҡ„DataNodeиҠӮзӮ№жүҚиғҪ继з»ӯж“ҚдҪңгҖӮжүҖд»ҘNameNodeжҳҜеӯҳеңЁеҚ•зӮ№й—®йўҳе’ҢжҖ§иғҪй—®йўҳзҡ„гҖӮHadoop2дёӯеҸҜд»Ҙй…ҚзҪ®HAзҡ„жЁЎејҸпјҢдёҖдёӘйӣҶзҫӨжӢҘжңүдёӨдёӘNameNodeдёҖдёӘеӨ„дәҺActiveзҠ¶жҖҒдёҖдёӘеӨ„дәҺStandbyзҠ¶жҖҒпјҢе…¶дёӯдёҖдёӘеӨұж•ҲеҗҺеҸҰдёҖдёӘеҸҜд»ҘиҮӘеҠЁеҲҮжҚўжҲҗActiveпјҢиҝӣиҖҢи§ЈеҶідәҶдёҖйғЁеҲҶеҚ•зӮ№й—®йўҳгҖӮ(еңЁHadoop3дёӯж”ҜжҢҒй…ҚзҪ®еӨҡдёӘNameNodeпјҢиҝӣдёҖжӯҘи§ЈеҶіNameNodeзҡ„еҚ•зӮ№й—®йўҳ)гҖӮNameNodeе°Ҷе…ғж•°жҚ®дҝЎжҒҜдҝқеӯҳеңЁеҶ…еӯҳдёӯпјҢеҶ…еӯҳе°ұжҳҜNameNodeзҡ„жҖ§иғҪ瓶йўҲпјҢеҰӮжһңйӣҶзҫӨдёӯе°Ҹж–Ү件иҝҮеӨҡдјҡдә§з”ҹеӨ§йҮҸе…ғж•°жҚ®дҝЎжҒҜеҚ з”ЁNameNodeзҡ„еҶ…еӯҳгҖӮжүҖд»ҘHDFSеҜ№еӨ§ж–Ү件зҡ„ж”ҜжҢҒжӣҙеҘҪгҖӮNameNodeдјҡеҚ з”ЁиҫғеӨҡзҡ„еҶ…еӯҳе’ҢI/Oиө„жәҗпјҢжүҖд»ҘиҝҗиЎҢNameNodeзҡ„иҠӮзӮ№дёҚдјҡеҗҜеҠЁDataNodeжҲ–иҖ…жү§иЎҢMapReduceд»»еҠЎгҖӮ
DataNode
DataNodeе°ұжҳҜHDFSзҡ„е·ҘдҪңиҠӮзӮ№дәҶпјҢе®ғиҙҹиҙЈеӯҳеӮЁж•°жҚ®пјҢдёәе®ўжҲ·з«ҜжҸҗдҫӣж•°жҚ®еқ—зҡ„иҜ»еҶҷжңҚеҠЎгҖӮеңЁеҗҜеҠЁж—¶дјҡе°Ҷе®ғеӯҳеӮЁзҡ„ж•°жҚ®еқ—зҡ„еҲ—иЎЁеҸ‘йҖҒз»ҷNameNodeпјҢж №жҚ®NameNodeзҡ„иҰҒжұӮеҜ№ж•°жҚ®еқ—иҝӣиЎҢеҲӣе»әгҖҒеҲ йҷӨе’ҢеӨҮд»ҪпјҢиҝҳдјҡйҖҡиҝҮеҝғи·іе®ҡжңҹеҗ‘NameNodeжӣҙж–°еӯҳеӮЁж•°жҚ®еқ—дҝЎжҒҜгҖӮ
HDFSйҖҡиҝҮеӨҮд»ҪеүҜжң¬зҡ„ж–№ејҸе®һзҺ°еҸҜйқ жҖ§пјҢHadoop2зјәзңҒзҡ„ж•°жҚ®еқ—еӨ§е°Ҹдёә128MпјҢеӨҚеҲ¶еӣ еӯҗдёәпјҢй»ҳи®Өзҡ„еӨҮд»ҪеүҜжң¬зҡ„еҲҶеёғдҪҚзҪ®дёҺжңәжһ¶е’ҢиҠӮзӮ№жңүе…ігҖӮеҪ“DataNodeдёўеӨұиҝһжҺҘеҗҺпјҢNameNodeдјҡжҠҠеӨұиҙҘиҠӮзӮ№зҡ„ж•°жҚ®(д»Һе…¶д»–еӨҮд»ҪеүҜжң¬иҠӮзӮ№)еӨҚеҲ¶еҲ°еҸҰеӨ–дёҖдёӘеҒҘеә·зҡ„DataNodeиҠӮзӮ№пјҢдҝқиҜҒйӣҶзҫӨйҮҢйқўзҡ„ж•°жҚ®еә“е§Ӣз»Ҳз»ҙжҢҒжҢҮе®ҡзҡ„еүҜжң¬ж•°йҮҸгҖӮ
еҶҷжөҒзЁӢ
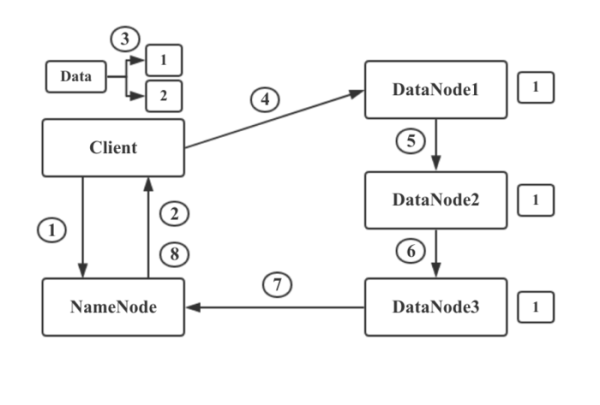
йҰ–е…ҲпјҢHDFS Clientе’ҢNameNodeе»әз«ӢиҝһжҺҘпјҢе‘ҠиҜүNameNodeиҰҒеӯҳеӮЁдёҖдёӘж–Ү件гҖӮNameNodeз»ҙжҠӨзқҖDataNodeзҡ„еҲ—иЎЁпјҢзҹҘйҒ“е“ӘдәӣDataNodeдёҠйқўиҝҳжңүз©әй—ҙеҸҜд»ҘиҝӣиЎҢеӯҳеӮЁгҖӮ
NameNodeйҖҡиҝҮжҹҘзңӢеӯҳеӮЁзҡ„е…ғж•°жҚ®дҝЎжҒҜпјҢеҸ‘зҺ°DataNode1,2,3дёҠеҸҜд»ҘиҝӣиЎҢеӯҳеӮЁгҖӮдәҺжҳҜд»–е°ҶжӯӨдҝЎжҒҜиҝ”еӣһз»ҷHDFS ClientгҖӮ
HDFS ClientжҺҘеҸ—еҲ°NameNodeзҡ„иҝ”еӣһзҡ„DataNodeеҲ—иЎЁеҗҺпјҢClientдјҡдёҺи·қзҰ»жңҖиҝ‘DataNode1е»әз«ӢиҝһжҺҘпјҢи®©е…¶еҮҶеӨҮеҘҪжҺҘ收数жҚ®гҖӮ然еҗҺе°Ҷж–Ү件иҝӣиЎҢеҲҶеқ—пјҢе°Ҷж•°жҚ®еқ—1е’ҢNameNodeиҝ”еӣһзҡ„DataNodeеҲ—иЎЁдҝЎжҒҜдёҖиө·еҸ‘йҖҒз»ҷDataNode1.
DataNode1йҖҡиҝҮеҲ—иЎЁдҝЎжҒҜеҫ—зҹҘиҰҒеҸ‘йҖҒз»ҷDataNode2.жүҖд»ҘDataNode1е°Ҷж•°жҚ®дёҺеҲ—иЎЁдҝЎжҒҜеҸ‘йҖҒз»ҷDataNode2.DataNode2еҸҲеҸ‘йҖҒз»ҷDataNode3пјҢжӯӨж—¶ж•°жҚ®еқ—1е·Із»ҸеӯҳеӮЁе®ҢжҲҗ并еӨҮд»ҪдәҶдёүд»ҪгҖӮ
еҪ“DataNode1,2,3йғҪжҺҘ收并еӯҳеӮЁж•°жҚ®еқ—1еҗҺпјҢдјҡеҗ‘NameNodeеҸ‘йҖҒдҝЎжҒҜпјҢе‘ҠзҹҘе·Із»ҸжҺҘ收еҲ°дәҶж•°жҚ®еқ—1.并жҠҠж•°жҚ®еқ—1зӣёе…ідҝЎжҒҜеҸ‘йҖҒз»ҷNameNodeпјҢNameNodeжӣҙж–°е…ғж•°жҚ®дҝЎжҒҜ并 дёҺClientйҖҡдҝЎе‘ҠзҹҘж•°жҚ®еқ—1е·Із»ҸеӯҳеӮЁе®ҢжҜ•гҖӮ然еҗҺClientејҖе§ӢиҝӣиЎҢж•°жҚ®еқ—2зҡ„еӯҳеӮЁгҖӮ
иҝҷйҮҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜдёҖдёӘеӨ§еһӢзҡ„HDFSж–Ү件系з»ҹдёҖиҲ¬йғҪжҳҜйңҖиҰҒи·ЁеҫҲеӨҡжңәжһ¶зҡ„пјҢдёҚеҗҢжңәжһ¶д№Ӣй—ҙзҡ„ж•°жҚ®дј иҫ“йңҖиҰҒз»ҸиҝҮзҪ‘е…іпјҢ并且пјҢеҗҢдёҖдёӘжңәжһ¶дёӯжңәеҷЁд№Ӣй—ҙзҡ„еёҰе®ҪиҰҒеӨ§дәҺдёҚеҗҢжңәжһ¶жңәеҷЁд№Ӣй—ҙзҡ„еёҰе®ҪгҖӮеҰӮжһңжҠҠжүҖжңүзҡ„еүҜжң¬йғҪж”ҫеңЁдёҚеҗҢзҡ„жңәжһ¶дёӯпјҢиҝҷж ·ж—ўеҸҜд»ҘйҳІжӯўжңәжһ¶еӨұиҙҘеҜјиҮҙж•°жҚ®еқ—дёҚеҸҜз”ЁпјҢеҸҲеҸҜд»ҘеңЁиҜ»ж•°жҚ®ж—¶еҲ©з”ЁеҲ°еӨҡдёӘжңәжһ¶зҡ„еёҰе®ҪпјҢ并且д№ҹеҸҜд»ҘеҫҲе®№жҳ“зҡ„е®һзҺ°иҙҹиҪҪеқҮиЎЎгҖӮеҰӮжһңеүҜжң¬ж•°йҮҸжҳҜ3зҡ„жғ…еҶөдёӢпјҢHDFSй»ҳи®ӨжҠҠ***дёӘеүҜжң¬ж”ҫеҲ°жңәжһ¶зҡ„дёҖдёӘиҠӮзӮ№дёҠпјҢеҸҰдёҖдёӘеүҜжң¬ж”ҫеҲ°еҗҢдёҖдёӘжңәжһ¶зҡ„еҸҰдёҖдёӘиҠӮзӮ№дёҠпјҢжҠҠ***дёҖдёӘиҠӮзӮ№ж”ҫеҲ°дёҚеҗҢзҡ„жңәжһ¶дёҠгҖӮиҝҷз§Қзӯ–з•ҘеҮҸе°‘дәҶи·Ёжңәжһ¶еүҜжң¬зҡ„дёӘж•°жҸҗй«ҳдәҶеҶҷзҡ„жҖ§иғҪпјҢд№ҹиғҪеӨҹе…Ғи®ёдёҖдёӘжңәжһ¶еӨұиҙҘзҡ„жғ…еҶөпјҢз®—жҳҜдёҖдёӘеҫҲеҘҪзҡ„жқғиЎЎгҖӮ
иҜ»жөҒзЁӢ
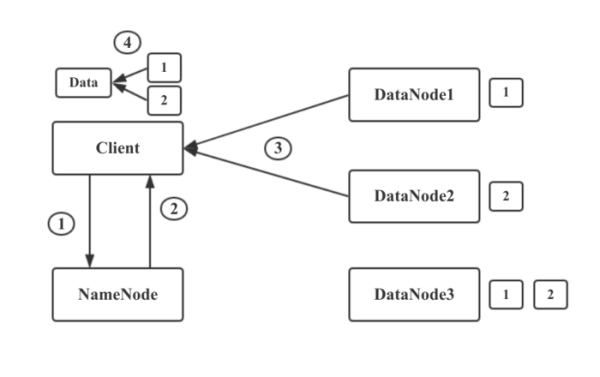
HDFS ClientдёҺNameNodeе»әз«Ӣй“ҫжҺҘпјҢе‘ҠиҜүNameNodeиҰҒиҜ»еҸ–ж–Ү件xxxгҖӮ
NameNodeйҖҡиҝҮжҹҘиҜўиҮӘе·ұзҡ„е…ғж•°жҚ®дҝЎжҒҜпјҢеҫ—еҲ°ж–Ү件xxxзҡ„ж•°жҚ®еқ—жҳ е°„дҝЎжҒҜеҸҠеӯҳеӮЁж•°жҚ®еқ—зҡ„DataNodeеҲ—иЎЁгҖӮ然еҗҺе°ҶиҝҷдәӣдҝЎжҒҜеҸ‘йҖҒз»ҷClientгҖӮ
Clientеҫ—еҲ°иҝҷдәӣдҝЎжҒҜд№ӢеҗҺпјҢеҜ»жүҫжңҖиҝ‘еҸҜз”Ёзҡ„DataNode1.еҸ–еӣһж•°жҚ®еқ—1.д»ҺDataNode2еҸ–еӣһж•°жҚ®еқ—2. иҮӘжӯӨжҲҗеҠҹиҜ»еҸ–ж–Ү件xxx
еҰӮжһңDataNode2еҮәзҺ°й—®йўҳжҢӮжҺүдәҶпјҢеҲҷд»ҺDataNode3иҝӣиЎҢж•°жҚ®еқ—иҜ»еҸ–гҖӮ
ж–Ү件иҜ»еҸ–ж—¶пјҢNameNodeдјҡйҖүжӢ©жңҖиҝ‘зҡ„DataNodeжҸҗдҫӣз»ҷе®ўжҲ·з«ҜгҖӮ
д»ҘдёҠжҳҜвҖңHDFSдёӯйңҖиҰҒжҺҢжҸЎд»Җд№ҲзҹҘиҜҶзӮ№вҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ





