жң¬зҜҮеҶ…е®№дё»иҰҒи®Іи§ЈвҖңDubboжәҗз ҒеҲ°CPUеҲҶж”Ҝйў„жөӢе®һдҫӢеҲҶжһҗвҖқпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢдёҚеҰЁжқҘзңӢзңӢгҖӮжң¬ж–Үд»Ӣз»Қзҡ„ж–№жі•ж“ҚдҪңз®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәгҖӮдёӢйқўе°ұи®©е°Ҹзј–жқҘеёҰеӨ§е®¶еӯҰд№ вҖңDubboжәҗз ҒеҲ°CPUеҲҶж”Ҝйў„жөӢе®һдҫӢеҲҶжһҗвҖқеҗ§!
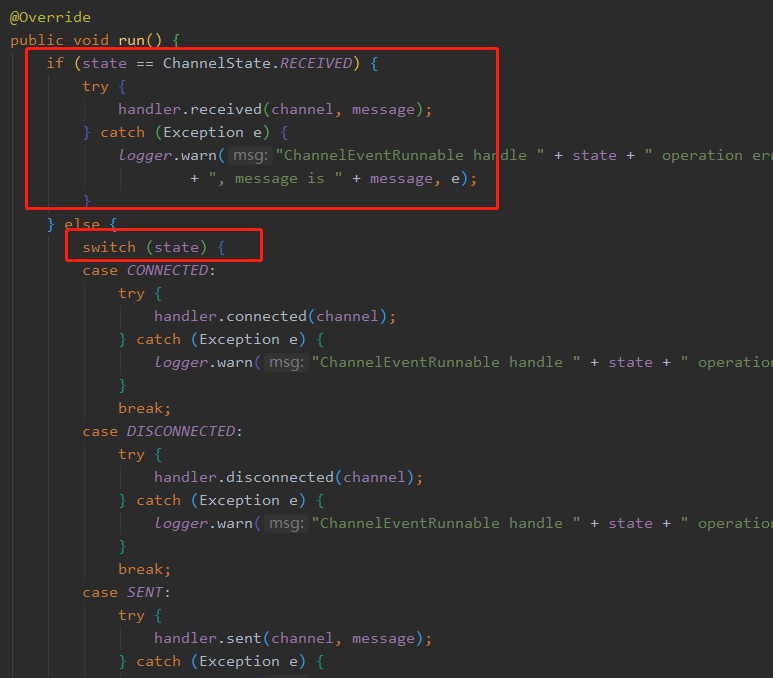
иҜҙжқҘд№ҹжҳҜе·§жңҖиҝ‘еңЁзңӢ Dubbo жәҗз ҒпјҢ然еҗҺеҸ‘зҺ°дәҶдёҖеӨ„еҫҲеҘҮжҖӘзҡ„д»Јз ҒпјҢдәҺжҳҜе°ұжңүдәҶиҝҷзҜҮж–Үз« пјҢи®©жҲ‘们жқҘзңӢдёҖдёӢиҝҷж®өд»Јз ҒпјҢе®ғеұһдәҺ ChannelEventRunnableпјҢиҝҷдёӘ runnable жҳҜ Dubbo IO зәҝзЁӢеҲӣе»әпјҢе°ҶжӯӨд»»еҠЎжү”еҲ°дёҡеҠЎзәҝзЁӢжұ дёӯеӨ„зҗҶгҖӮ
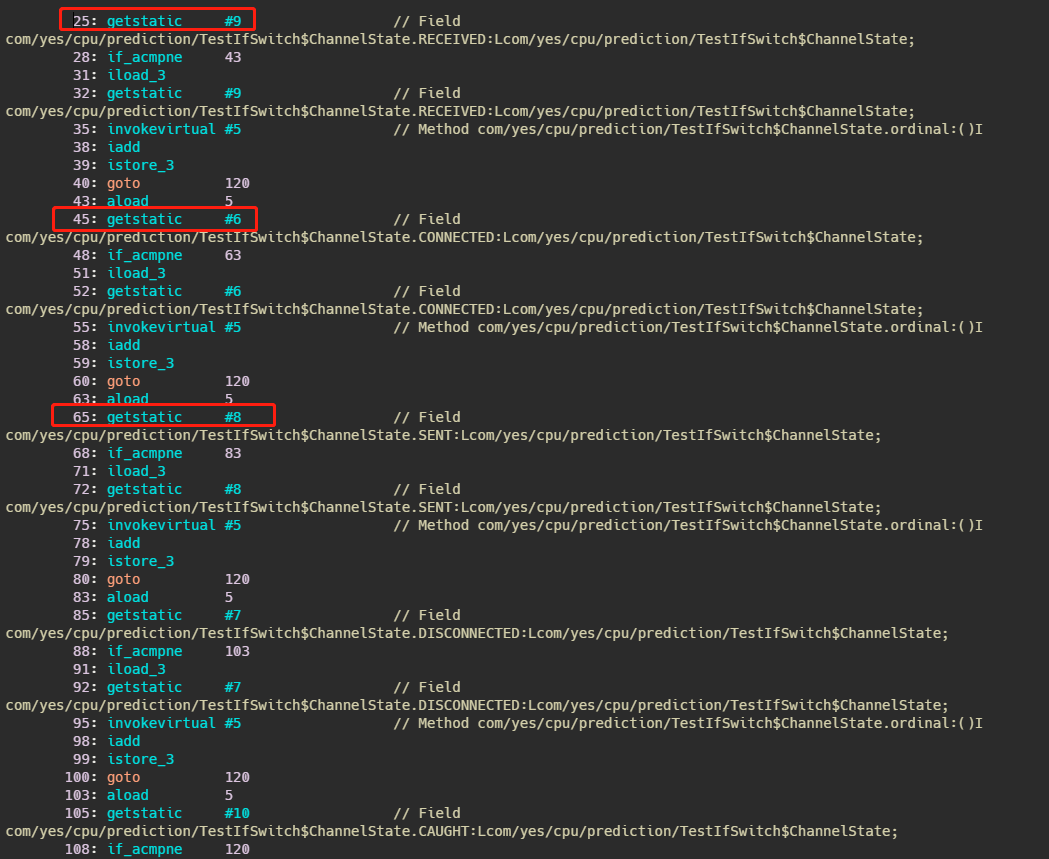
зңӢеҲ°жІЎпјҢжҠҠ state == ChannelState.RECEIVED жӢҺеҮәжқҘзӢ¬з«ӢдёҖдёӘ ifпјҢиҖҢе…¶д»–зҡ„ state иҝҳжҳҜж”ҫеңЁ switch йҮҢйқўеҲӨж–ӯгҖӮ
жҲ‘еҪ“ж—¶и„‘еӯҗйҮҢе°ұжқҘеӣһжү«жҸҸпјҢжғіжғіиҝҷдёӘеҲ°еә•жңүд»Җд№ҲиҠұеӨҙпјҢеҘҲдҪ•зҹҘиҜҶжө…и–„дёҖи„ёжҮөйҖјгҖӮ
дәҺжҳҜе°ұејҖе§ӢдәҶдёҖжіўжҺўйҷ©д№Ӣж—…пјҒ
еҺҹжқҘжҳҜ CPU еҲҶж”Ҝйў„жөӢ йҒҮеҲ°й—®йўҳеҪ“然жҳҜй—®жҗңзҙўеј•ж“ҺдәҶпјҢдёҖиҲ¬иҖҢиЁҖжҲ‘дјҡеҗҢж—¶жҗңзҙўеҗ„еӨ§еј•ж“ҺпјҢе’ұиҝҷд№ҹдёҚиҜҙи°ҒжҜ”и°ҒеҘҪпјҢеҸҚжӯЈжңүдәӣж—¶еҖҷеәҰеЁҳиҝҳжҳҜдёҚй”ҷзҡ„пјҢжҜ”еҰӮиҝҷж¬ЎжҗңзҙўеәҰеЁҳз»ҷзҡ„з»“жһңжҜ”иҫғйқ еүҚпјҢgoogle иҫғйқ еҗҺгҖӮ
дёҖиҲ¬жҗңзҙўдёңиҘҝжҲ‘йғҪе–ңж¬ўе…ҲеңЁе®ҳзҪ‘дёҠжҗңпјҢжүҫдёҚеҲ°дәҶеҶҚж”ҫејҖжҗңпјҢжүҖд»Ҙе…Ҳиҝҷд№Ҳжҗң site:xxx.com keyгҖӮ
дҪ зңӢиҝҷе°ұжңүдәҶпјҢе®ҢзҫҺе•ҠпјҒ
жҲ‘们е…ҲжқҘзңӢзңӢе®ҳзҪ‘зҡ„иҝҷзҜҮеҚҡе®ўжҖҺд№ҲиҜҙзҡ„пјҢ然еҗҺеҶҚиҜҰз»Ҷең°еҲҶжһҗдёҖжіўгҖӮ
Dubbo е®ҳзҪ‘зҡ„еҚҡе®ў зҺ°д»Ј CPU йғҪж”ҜжҢҒеҲҶж”Ҝйў„жөӢ (branch prediction) е’ҢжҢҮд»ӨжөҒж°ҙзәҝ (instruction pipeline)пјҢиҝҷдёӨдёӘз»“еҗҲеҸҜд»ҘжһҒеӨ§жҸҗй«ҳ CPU ж•ҲзҺҮгҖӮеҜ№дәҺеғҸз®ҖеҚ•зҡ„ if и·іиҪ¬пјҢCPU жҳҜеҸҜд»ҘжҜ”иҫғеҘҪең°еҒҡеҲҶж”Ҝйў„жөӢзҡ„гҖӮдҪҶжҳҜеҜ№дәҺ switch и·іиҪ¬пјҢCPU еҲҷжІЎжңүеӨӘеӨҡзҡ„еҠһжі•гҖӮswitch жң¬иҙЁдёҠжҳҜж №жҚ®зҙўеј•пјҢд»Һең°еқҖж•°з»„йҮҢеҸ–ең°еқҖеҶҚи·іиҪ¬гҖӮ
д№ҹе°ұжҳҜиҜҙ if жҳҜи·іиҪ¬жҢҮд»ӨпјҢеҰӮжһңжҳҜз®ҖеҚ•зҡ„и·іиҪ¬жҢҮд»Өзҡ„иҜқ CPU еҸҜд»ҘеҲ©з”ЁеҲҶж”Ҝйў„жөӢжқҘйў„жү§иЎҢжҢҮд»ӨпјҢиҖҢ switch жҳҜиҰҒе…Ҳж №жҚ®еҖјеҺ»дёҖдёӘзұ»дјјж•°з»„з»“жһ„жүҫеҲ°еҜ№еә”зҡ„ең°еқҖпјҢ然еҗҺеҶҚиҝӣиЎҢи·іиҪ¬пјҢиҝҷж ·зҡ„иҜқ CPU йў„жөӢе°ұеё®дёҚдёҠеҝҷдәҶгҖӮ
然еҗҺеҸҲеӣ дёәдёҖдёӘ channel е»әз«ӢдәҶд№ӢеҗҺпјҢи¶…иҝҮ99.9%жғ…еҶөе®ғзҡ„ state йғҪжҳҜ ChannelState.RECEIVEDпјҢеӣ жӯӨе°ұжҠҠиҝҷдёӘзҠ¶жҖҒз»ҷжҢ‘еҮәжқҘпјҢиҝҷж ·е°ұиғҪеҲ©з”Ё CPU еҲҶж”Ҝйў„жөӢжңәеҲ¶жқҘжҸҗй«ҳд»Јз Ғзҡ„жү§иЎҢж•ҲзҺҮгҖӮ
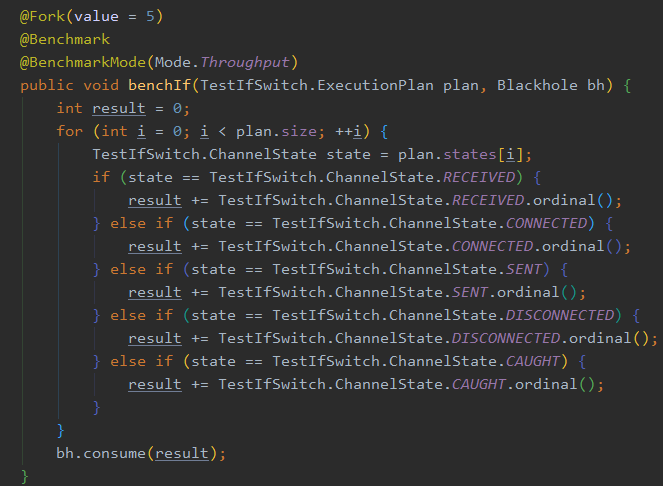
并且иҝҳз»ҷеҮәдәҶ Benchmark зҡ„д»Јз ҒпјҢе°ұжҳҜйҖҡиҝҮйҡҸжңәз”ҹжҲҗ 100W дёӘ stateпјҢ并且 99.99% жҳҜ ChannelState.RECEIVEDпјҢ然еҗҺжҢүз…§д»ҘдёӢдёӨз§Қж–№ејҸжқҘжҜ”дёҖжҜ”пјҲиҝҷ benchSwitch е®ҳзҪ‘зҡ„дҫӢеӯҗеҗҚеӯ—жү“й”ҷдәҶпјҢжҲ‘дёҖејҖе§ӢжІЎеҸ‘зҺ°еҗҺжқҘж ЎеҜ№ж–Үз« жүҚеҸ‘зҺ°пјүгҖӮ
иҷҪ然еҚҡе®ўд№ҹз»ҷеҮәдәҶе®ғзҡ„еҜ№жҜ”з»“жһңпјҢдҪҶжҳҜжҲ‘иҝҳжҳҜжң¬ең°жқҘи·‘дёҖдёӢзңӢзңӢз»“жһңеҰӮдҪ•пјҢе…¶е®һ JMH дёҚжҺЁиҚҗеңЁ ide йҮҢйқўи·‘пјҢдҪҶжҳҜжҲ‘жҮ’пјҢзӣҙжҺҘ idea йҮҢйқўи·‘дәҶгҖӮ
д»Һз»“жһңжқҘзңӢзЎ®е®һйҖҡиҝҮ if зӢ¬з«ӢеҮәжқҘд»Јз Ғзҡ„жү§иЎҢж•ҲзҺҮжӣҙй«ҳпјҲжіЁж„ҸиҝҷйҮҢжөӢзҡ„жҳҜеҗһеҗҗпјүпјҢеҚҡе®ўиҝҳжҸҗеҮәдәҶиҝҷз§ҚжҠҖе·§еҸҜд»Ҙж”ҫеңЁжҖ§иғҪиҰҒжұӮдёҘж јзҡ„ең°ж–№пјҢд№ҹе°ұжҳҜдёҖиҲ¬жғ…еҶөдёӢжІЎеҝ…иҰҒиҝҷж ·зү№ж®ҠеҒҡгҖӮ
иҮіжӯӨжҲ‘们已з»ҸзҹҘйҒ“дәҶиҝҷдёӘз»“и®әжҳҜеҜ№зҡ„пјҢдёҚиҝҮжҲ‘们иҝҳйңҖиҰҒж·ұе…ҘеҲҶжһҗдёҖжіўпјҢйҰ–е…Ҳеҫ—зңӢзңӢ if е’Ң switch зҡ„жү§иЎҢж–№ејҸеҲ°еә•е·®еҲ«еңЁе“ӘйҮҢпјҢ然еҗҺеҶҚзңӢзңӢ CPU еҲҶж”Ҝйў„жөӢе’ҢжҢҮд»ӨжөҒж°ҙзәҝзҡ„еҲ°еә•жҳҜе№Іе•Ҙзҡ„пјҢдёәд»Җд№ҲдјҡжңүиҝҷдёӨдёӘдёңиҘҝпјҹ
if vs switch жҲ‘们е…Ҳз®ҖеҚ•жқҘдёӘе°Ҹ demo зңӢзңӢ if е’Ң switch зҡ„жү§иЎҢж•ҲзҺҮпјҢе…¶е®һе°ұжҳҜж·»еҠ дёҖдёӘе…ЁйғЁжҳҜ if else жҺ§еҲ¶зҡ„д»Јз ҒпјҢ switch е’Ң if + switch зҡ„дёҚеҠЁпјҢзңӢзңӢе®ғ们д№Ӣй—ҙеҜ№жҜ”ж•ҲзҺҮеҰӮдҪ•пјҲжӯӨж—¶иҝҳжҳҜ RECEIVED и¶…иҝҮ99.9%пјүгҖӮ
жқҘзңӢдёҖдёӢжү§иЎҢзҡ„з»“жһңеҰӮдҪ•пјҡ
еҘҪ家дјҷпјҢжҲ‘и·‘дәҶеҘҪеҮ ж¬ЎпјҢиҝҷе…Ё if зҡ„жҜ” if + switch ејәдёҚе°‘е•ҠпјҢжүҖд»ҘжҳҜдёҚжҳҜжәҗз Ғеә”иҜҘе…Ёж”№жҲҗ if else зҡ„ж–№ејҸпјҢдҪ зңӢиҝҷеҗһеҗҗйҮҸеҸҲй«ҳпјҢиҝҳдёҚдјҡеғҸзҺ°еңЁдёҖдёӢ if дёҖдёӢеҸҲ switch жңүзӮ№дёҚдјҰдёҚзұ»зҡ„ж ·еӯҗгҖӮ
жҲ‘еҸҲжҠҠ state з”ҹжҲҗзҡ„еҖјж”№жҲҗйҡҸжңәзҡ„пјҢеҶҚжқҘи·‘дёҖдёӢзңӢзңӢз»“жһңеҰӮдҪ•пјҡ
жҲ‘и·‘дәҶеӨҡж¬ЎиҝҳжҳҜ if зҡ„еҗһеҗҗйҮҸйғҪжҳҜжңҖй«ҳзҡ„пјҢжҖҺд№Ҳж•ҙиҝҷдёӘе…Ё if зҡ„йғҪжҳҜжңҖжЈ’ж»ҙгҖӮ
еҸҚзј–иҜ‘ if е’Ң switch еңЁжҲ‘зҡ„еҚ°иұЎйҮҢиҝҷдёӘ switch еә”иҜҘжҳҜдјҳдәҺ if зҡ„пјҢдёҚиҖғиҷ‘ CPU еҲҶж”Ҝйў„жөӢзҡ„иҜқпјҢеҪ“д»Һеӯ—иҠӮз Ғи§’еәҰжқҘиҜҙжҳҜиҝҷж ·зҡ„пјҢжҲ‘们жқҘзңӢзңӢеҗ„иҮӘз”ҹжҲҗзҡ„еӯ—иҠӮз ҒгҖӮ
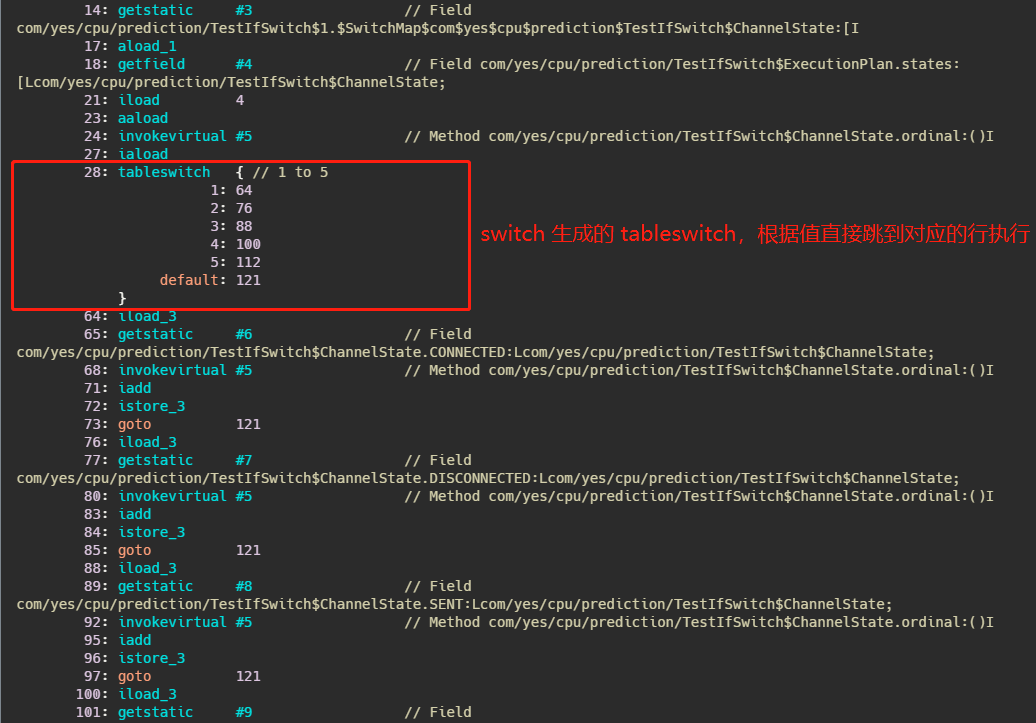
е…ҲзңӢдёҖдёӢ switch зҡ„еҸҚзј–иҜ‘пјҢе°ұжҲӘеҸ–дәҶе…ій”®йғЁеҲҶгҖӮ
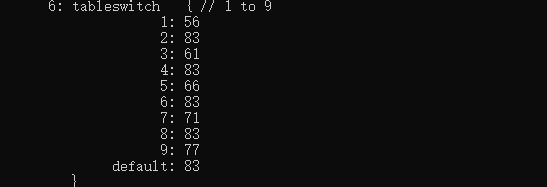
д№ҹе°ұжҳҜиҜҙ switch з”ҹжҲҗдәҶдёҖдёӘ tableswitchпјҢдёҠйқўзҡ„ getstatic жӢҝеҲ°еҖјд№ӢеҗҺеҸҜд»Ҙж №жҚ®зҙўеј•зӣҙжҺҘжҹҘиҝҷдёӘ tableпјҢ然еҗҺи·іиҪ¬еҲ°еҜ№еә”зҡ„иЎҢжү§иЎҢеҚіеҸҜпјҢд№ҹе°ұжҳҜж—¶й—ҙеӨҚжқӮеәҰжҳҜ O(1)гҖӮ
жҜ”еҰӮеҖјжҳҜ 1 йӮЈд№ҲзӣҙжҺҘи·іеҲ°жү§иЎҢ 64 иЎҢпјҢеҰӮжһңжҳҜ 4 е°ұзӣҙжҺҘи·іеҲ° 100 иЎҢгҖӮ
е…ідәҺ switch иҝҳжңүдёҖдәӣе°Ҹз»ҶиҠӮпјҢеҪ“ swtich еҶ…зҡ„еҖјдёҚиҝһз»ӯдё”е·®и·қеҫҲеӨ§зҡ„ж—¶еҖҷпјҢз”ҹжҲҗзҡ„жҳҜ lookupswitchпјҢжҢүзҪ‘дёҠзҡ„иҜҙжі•жҳҜдәҢеҲҶжі•иҝӣиЎҢжҹҘиҜўпјҲжҲ‘жІЎеҺ»йӘҢиҜҒиҝҮпјүпјҢж—¶й—ҙеӨҚжқӮеәҰжҳҜ O(logn)пјҢдёҚжҳҜж №жҚ®зҙўеј•зӣҙжҺҘиғҪжүҫеҲ°дәҶпјҢжҲ‘зңӢз”ҹжҲҗзҡ„ lookup зҡ„ж ·еӯҗеә”иҜҘе°ұжҳҜдәҢеҲҶдәҶпјҢеӣ дёәжҢүеҖјеӨ§е°ҸжҺ’еәҸдәҶгҖӮ
иҝҳжңүеҪ“ switch йҮҢйқўзҡ„еҖјдёҚиҝһз»ӯдҪҶжҳҜе·®и·қжҜ”иҫғе°Ҹзҡ„ж—¶еҖҷпјҢиҝҳжҳҜдјҡз”ҹжҲҗ tableswtich дёҚиҝҮеЎ«е……дәҶдёҖдәӣеҖјпјҢжҜ”еҰӮиҝҷдёӘдҫӢеӯҗжҲ‘ switch йҮҢйқўзҡ„еҖје°ұ 1гҖҒ3гҖҒ5гҖҒ7гҖҒ9пјҢе®ғиҮӘеҠЁеЎ«е……дәҶ2гҖҒ4гҖҒ6гҖҒ8 йғҪжҢҮеҲ° default жүҖи·ізҡ„иЎҢгҖӮ
и®©жҲ‘们еҶҚжқҘзңӢзңӢ if зҡ„еҸҚзј–иҜ‘з»“жһңпјҡ
еҸҜд»ҘзңӢеҲ° if жҳҜжҜҸж¬ЎйғҪдјҡеҸ–еҮәеҸҳйҮҸе’ҢжқЎд»¶иҝӣиЎҢжҜ”иҫғпјҢиҖҢ switch еҲҷжҳҜеҸ–дёҖж¬ЎеҸҳйҮҸд№ӢеҗҺжҹҘиЎЁзӣҙжҺҘи·іеҲ°жӯЈзЎ®зҡ„иЎҢпјҢд»Һиҝҷж–№йқўжқҘзңӢ switch зҡ„ж•ҲзҺҮеә”иҜҘжҳҜдјҳдәҺ if зҡ„гҖӮеҪ“然еҰӮжһң if еңЁз¬¬дёҖж¬ЎеҲӨж–ӯе°ұиҝҮдәҶзҡ„иҜқд№ҹе°ұзӣҙжҺҘ goto дәҶпјҢдёҚдјҡеҶҚжү§иЎҢдёӢйқўзҡ„е“ӘдәӣеҲӨж–ӯдәҶгҖӮ
жүҖд»Ҙд»Һз”ҹжҲҗзҡ„еӯ—иҠӮз Ғи§’еәҰжқҘзңӢ switch ж•ҲзҺҮеә”иҜҘжҳҜеӨ§дәҺ if зҡ„пјҢдҪҶжҳҜд»ҺжөӢиҜ•з»“жһңзҡ„и§’еәҰжқҘзңӢ if зҡ„ж•ҲзҺҮеҸҲжҳҜй«ҳдәҺ switch зҡ„пјҢдёҚи®әжҳҜйҡҸжңәз”ҹжҲҗ stateпјҢиҝҳжҳҜ 99.99% йғҪжҳҜеҗҢдёҖдёӘ state зҡ„жғ…еҶөдёӢгҖӮ
йҰ–е…Ҳ CPU еҲҶж”Ҝйў„жөӢзҡ„дјҳеҢ–жҳҜиӮҜе®ҡзҡ„пјҢйӮЈе…ідәҺйҡҸжңәжғ…еҶөдёӢ if иҝҳжҳҜдјҳдәҺ switch зҡ„иҜқиҝҷжҲ‘е°ұжңүзӮ№дёҚеӨӘзЎ®е®ҡдёәд»Җд№ҲдәҶпјҢеҸҜиғҪжҳҜ JIT еҒҡдәҶд»Җд№ҲдјҳеҢ–ж“ҚдҪңпјҢжҲ–иҖ…жҳҜйҡҸжңәжғ…еҶөдёӢеҲҶж”Ҝйў„жөӢжҲҗеҠҹеёҰжқҘзҡ„ж•ҲзӣҠеӨ§дәҺйў„жөӢеӨұиҙҘзҡ„жғ…еҪўпјҹ
йҡҫйҒ“жҳҜжҲ‘жһҡдёҫеҖјеӨӘе°‘дәҶдҪ“зҺ°дёҚеҮә switch зҡ„ж•ҲжһңпјҹдёҚиҝҮеңЁйҡҸжңәжғ…еҶөдёӢ switch д№ҹдёҚеә”иҜҘејұдәҺ if е•ҠпјҢжҲ‘еҸҲеҠ дәҶ 7 дёӘжһҡдёҫеҖјпјҢдёҖе…ұ 12 дёӘеҖјеҸҲжөӢиҜ•дәҶдёҖйҒҚпјҢз»“жһңеҰӮдёӢпјҡ
еҘҪеғҸи·қзҰ»иў«жӢүиҝ‘дәҶпјҢжҲ‘зңӢжңүжҲҸпјҢдәҺжҳҜжҲ‘иғҢдәҶжіў 26 дёӘеӯ—жҜҚпјҢе®һдёҚзӣёзһ’иҝҳжҳҜе”ұзқҖжү“зҡ„еӯ—жҜҚгҖӮ
жү©е……дәҶеҲҶж”Ҝзҡ„ж•°йҮҸеҗҺеҸҲиҝӣиЎҢдәҶдёҖжіўжөӢиҜ•пјҢиҝҷж¬Ў swtich дәүж°”дәҶпјҢз»ҲдәҺжҜ” if ејәдәҶгҖӮ
йўҳеӨ–иҜқ: жҲ‘зңӢзҪ‘дёҠд№ҹжңүеҜ№жҜ” if е’Ң switch зҡ„пјҢе®ғ们еҜ№жҜ”еҮәжқҘзҡ„з»“жһңжҳҜ switch дјҳдәҺ ifпјҢйҰ–е…Ҳ jmh е°ұжІЎеҶҷеҜ№пјҢе®ҡд№үдёҖдёӘеёёйҮҸжқҘжөӢиҜ• if е’Ң switchпјҢ并且жөӢиҜ•ж–№жі•зҡ„ result еҶҷдәҶжІЎжңүж¶Ҳиҙ№пјҢиҝҷд»Јз Ғд№ҹдёҚзҹҘйҒ“дјҡиў« JIT дјҳеҢ–жҲҗе•Ҙж ·дәҶпјҢеҶҷдәҶеҮ еҚҒиЎҢпјҢеҸҜиғҪзӣҙжҺҘдјҳеҢ–жҲҗ return жҹҗдёӘеҖјдәҶгҖӮ
е°Ҹз»“дёҖдёӢжөӢиҜ•з»“жһң еҜ№жҜ”дәҶиҝҷд№ҲеӨҡжҲ‘们жқҘе°Ҹз»“дёҖдёӢгҖӮ
йҰ–е…ҲеҜ№дәҺзғӯзӮ№еҲҶж”Ҝе°Ҷе…¶д»Һ switch жҸҗеҸ–еҮәжқҘз”Ё if зӢ¬з«ӢеҲӨж–ӯпјҢе……еҲҶеҲ©з”Ё CPU еҲҶж”Ҝйў„жөӢеёҰжқҘзҡ„дҫҝеҲ©зЎ®е®һдјҳдәҺзәҜ swtichпјҢд»ҺжҲ‘们зҡ„д»Јз ҒжөӢиҜ•з»“жһңжқҘзңӢпјҢеӨ§иҮҙеҗһеҗҗйҮҸй«ҳдәҶдёӨеҖҚгҖӮ
иҖҢеңЁзғӯзӮ№еҲҶж”Ҝзҡ„жғ…еҪўдёӢж”№жҲҗзәҜ if еҲӨж–ӯиҖҢдёҚжҳҜ if + swtichзҡ„жғ…еҪўдёӢпјҢеҗһеҗҗйҮҸжҸҗй«ҳзҡ„жӣҙеӨҡгҖӮжҳҜзәҜ switch зҡ„ 3.3 еҖҚпјҢжҳҜ if + switch зҡ„ 1.6 еҖҚгҖӮ
еңЁйҡҸжңәеҲҶж”Ҝзҡ„жғ…еҪўдёӢпјҢдёүиҖ…е·®еҲ«дёҚжҳҜеҫҲеӨ§пјҢдҪҶжҳҜиҝҳжҳҜзәҜ if зҡ„жғ…еҶөжңҖдјҳз§ҖгҖӮ
дҪҶжҳҜд»Һеӯ—иҠӮз Ғи§’еәҰжқҘзңӢе…¶е®һ switch зҡ„жңәеҲ¶ж•ҲзҺҮеә”иҜҘжӣҙй«ҳзҡ„пјҢдёҚи®әжҳҜ O(1) иҝҳжҳҜ O(logn)пјҢдҪҶжҳҜд»ҺжөӢиҜ•з»“жһңзҡ„и§’еәҰжқҘиҜҙдёҚжҳҜзҡ„гҖӮ
еңЁйҖүжӢ©жқЎд»¶е°‘зҡ„жғ…еҶөдёӢ if жҳҜдјҳдәҺ switch зҡ„пјҢиҝҷдёӘжҲ‘дёҚеӨӘжё…жҘҡдёәд»Җд№ҲпјҢеҸҜиғҪжҳҜеңЁеҖјиҫғе°‘зҡ„жғ…еҶөдёӢжҹҘиЎЁзҡ„ж¶ҲиҖ—зӣёжҜ”еёҰжқҘзҡ„收зӣҠжӣҙеӨ§дёҖдәӣпјҹжңүзҹҘйҒ“зҡ„е°ҸдјҷдјҙеҸҜд»ҘеңЁж–Үжң«з•ҷиЁҖгҖӮ
еңЁйҖүжӢ©жқЎд»¶еҫҲеӨҡзҡ„жғ…еҶөдёӢ switch жҳҜдјҳдәҺ if зҡ„пјҢеҶҚеӨҡзҡ„йҖүжӢ©еҖјжҲ‘е°ұжІЎжөӢдәҶпјҢеӨ§дјҷжңүе…ҙи¶ЈеҸҜд»ҘиҮӘе·ұжөӢжөӢпјҢдёҚиҝҮи¶ӢеҠҝе°ұжҳҜиҝҷж ·зҡ„гҖӮ
CPU еҲҶж”Ҝйў„жөӢ жҺҘдёӢжқҘе’ұ们еҶҚжқҘзңӢзңӢиҝҷдёӘеҲҶж”Ҝйў„жөӢеҲ°еә•жҳҜжҖҺд№Ҳеј„зҡ„пјҢдёәд»Җд№ҲдјҡжңүеҲҶж”Ҝйў„жөӢиҝҷзҺ©ж„ҸпјҢдёҚиҝҮеңЁи°ҲеҲ°еҲҶж”Ҝйў„жөӢд№ӢеүҚйңҖиҰҒе…Ҳд»Ӣз»ҚдёӢжҢҮд»ӨжөҒж°ҙзәҝпјҲInstruction pipeliningпјүпјҢд№ҹе°ұжҳҜзҺ°д»Јеҫ®еӨ„зҗҶеҷЁзҡ„ pipelineгҖӮ
CPU жң¬иҙЁе°ұжҳҜеҸ–жҢҮжү§иЎҢпјҢиҖҢеҸ–жҢҮжү§иЎҢжҲ‘们жқҘзңӢдёӢдә”еӨ§жӯҘйӘӨпјҢеҲҶеҲ«жҳҜиҺ·еҸ–жҢҮд»Ө(IF)гҖҒжҢҮд»Өи§Јз Ғ(ID)гҖҒжү§иЎҢжҢҮд»Ө(EX)гҖҒеҶ…еӯҳи®ҝй—®(MEM)гҖҒеҶҷеӣһз»“жһң(WB)пјҢеҶҚжқҘзңӢдёӢз»ҙеҹәзҷҫ科дёҠзҡ„дёҖдёӘеӣҫгҖӮ
еҪ“然жӯҘйӘӨе®һйҷ…еҸҜиғҪжӣҙеӨҡпјҢеҸҚжӯЈе°ұжҳҜиҝҷдёӘж„ҸжҖқйңҖиҰҒз»ҸеҺҶиҝҷд№ҲеӨҡжӯҘпјҢжүҖд»ҘиҜҙдёҖж¬Ўжү§иЎҢеҸҜд»ҘеҲҶжҲҗеҫҲеӨҡжӯҘйӘӨпјҢйӮЈд№Ҳиҝҷд№ҲеӨҡжӯҘйӘӨе°ұеҸҜд»Ҙ并иЎҢпјҢжқҘжҸҗеҚҮеӨ„зҗҶзҡ„ж•ҲзҺҮгҖӮ
жүҖд»ҘиҜҙжҢҮд»ӨжөҒж°ҙзәҝе°ұжҳҜиҜ•еӣҫз”ЁдёҖдәӣжҢҮд»ӨдҪҝеӨ„зҗҶеҷЁзҡ„жҜҸдёҖйғЁеҲҶдҝқжҢҒеҝҷзўҢпјҢж–№жі•жҳҜе°Ҷдј е…Ҙзҡ„жҢҮд»ӨеҲҶжҲҗдёҖзі»еҲ—иҝһз»ӯзҡ„жӯҘйӘӨпјҢз”ұдёҚеҗҢзҡ„еӨ„зҗҶеҷЁеҚ•е…ғжү§иЎҢпјҢдёҚеҗҢзҡ„жҢҮд»ӨйғЁеҲҶ并иЎҢеӨ„зҗҶгҖӮ
е°ұеғҸжҲ‘们е·ҘеҺӮзҡ„жөҒж°ҙзәҝдёҖж ·пјҢжҲ‘иҝҷдёӘеҘҘзү№жӣјзҡ„и„ҡжӢјдёҠеҺ»дәҶ马дёҠжӢјдёӢдёҖдёӘеҘҘзү№жӣјзҡ„и„ҡпјҢжҲ‘еҸҜдёҚдјҡзӯүдёҠдёҖдёӘеҘҘзү№жӣјзҡ„йғҪз»„иЈ…е®ҢдәҶеҶҚз»„иЈ…дёӢдёҖдёӘеҘҘзү№жӣјгҖӮ
еҪ“然д№ҹжІЎжңүиҝҷд№Ҳжӯ»жқҝпјҢдёҚдёҖе®ҡе°ұжҳҜйЎәеәҸжү§иЎҢпјҢжңүдәӣжҢҮд»ӨеңЁзӯүеҫ…иҖҢеҗҺйқўзҡ„жҢҮд»Өе…¶е®һдёҚдҫқиө–еүҚйқўзҡ„з»“жһңпјҢжүҖд»ҘеҸҜд»ҘжҸҗеүҚжү§иЎҢпјҢиҝҷз§ҚеҸ«д№ұеәҸжү§иЎҢгҖӮ
жҲ‘们еҶҚиҜҙеӣһжҲ‘们зҡ„еҲҶж”Ҝйў„жөӢгҖӮ
иҝҷд»Јз Ғе°ұеғҸжҲ‘们зҡ„дәәз”ҹдёҖж ·жҖ»дјҡйқўдёҙзқҖйҖүжӢ©пјҢеҸӘжңүеҒҡдәҶйҖүжӢ©д№ӢеҗҺжүҚзҹҘйҒ“еҗҺйқўзҡ„и·ҜжҖҺд№Ҳиө°е‘ҖпјҢдҪҶжҳҜдәӢе®һдёҠеҸ‘зҺ°иҝҷд»Јз Ғз»Ҹеёёиө°зҡ„жҳҜеҗҢдёҖдёӘйҖүжӢ©пјҢдәҺжҳҜе°ұжғіеҮәдәҶдёҖдёӘеҲҶж”Ҝйў„жөӢеҷЁпјҢи®©е®ғжқҘйў„жөӢиө°еҠҝпјҢжҸҗеүҚжү§иЎҢдёҖи·Ҝзҡ„жҢҮд»ӨгҖӮ
йӮЈйў„жөӢй”ҷдәҶжҖҺд№ҲеҠһпјҹиҝҷе’Ңе’ұ们дәәз”ҹдёҚдёҖж ·пјҢе®ғеҸҜд»ҘжҠҠд№ӢеүҚжү§иЎҢзҡ„з»“жһңе…ЁжҠӣдәҶ然еҗҺеҶҚжқҘдёҖйҒҚпјҢдҪҶжҳҜд№ҹжңүеҪұе“ҚпјҢд№ҹе°ұжҳҜжөҒж°ҙзәҝи¶Ҡж·ұпјҢй”ҷзҡ„и¶ҠеӨҡжөӘиҙ№зҡ„д№ҹе°ұи¶ҠеӨҡпјҢй”ҷиҜҜзҡ„йў„жөӢ延иҝҹжҳҜ10иҮі20дёӘж—¶й’ҹе‘Ёжңҹд№Ӣй—ҙпјҢжүҖд»ҘиҝҳжҳҜжңүеүҜдҪңз”Ёзҡ„гҖӮ
з®ҖеҚ•зҡ„иҜҙе°ұжҳҜйҖҡиҝҮеҲҶж”Ҝйў„жөӢеҷЁжқҘйў„жөӢе°ҶжқҘиҰҒи·іиҪ¬жү§иЎҢзҡ„йӮЈдәӣжҢҮд»ӨпјҢ然еҗҺйў„жү§иЎҢпјҢиҝҷж ·еҲ°зңҹжӯЈйңҖиҰҒе®ғзҡ„ж—¶еҖҷеҸҜд»ҘзӣҙжҺҘжӢҝеҲ°з»“жһңдәҶпјҢжҸҗеҚҮдәҶж•ҲзҺҮгҖӮ
еҲҶж”Ҝйў„жөӢеҸҲеҲҶдәҶеҫҲеӨҡз§Қйў„жөӢж–№ејҸпјҢжңүйқҷжҖҒйў„жөӢгҖҒеҠЁжҖҒйў„жөӢгҖҒйҡҸжңәйў„жөӢзӯүзӯүпјҢд»Һз»ҙеҹәзҷҫ科дёҠзңӢжңү16з§ҚгҖӮ
жҲ‘з®ҖеҚ•иҜҙдёӢжҲ‘жҸҗеҲ°зҡ„дёүз§ҚпјҢйқҷжҖҒйў„жөӢе°ұжҳҜж„ЈеӨҙйқ’пјҢе°ұе’Ңи’ҷиӢұиҜӯйҖүжӢ©йўҳдёҖж ·пјҢжҲ‘з®ЎдҪ д»Җд№ҲйўҳжҲ‘йғҪйҖүAпјҢд№ҹе°ұжҳҜиҜҙе®ғдјҡйў„жөӢдёҖдёӘиө°еҠҝпјҢдёҖеҫҖж— еүҚпјҢз®ҖеҚ•зІ—жҡҙгҖӮ
еҠЁжҖҒйў„жөӢеҲҷдјҡж №жҚ®еҺҶеҸІи®°еҪ•жқҘеҶіе®ҡйў„жөӢзҡ„ж–№еҗ‘пјҢжҜ”еҰӮеүҚйқўеҮ ж¬ЎйҖүжӢ©йғҪжҳҜ true пјҢйӮЈжҲ‘е°ұиө° true иҰҒжү§иЎҢзҡ„иҝҷдәӣжҢҮд»ӨпјҢеҰӮжһңеҸҳдәҶжңҖиҝ‘еҮ ж¬ЎйғҪжҳҜ false пјҢйӮЈжҲ‘е°ұеҸҳжҲҗ false иҰҒжү§иЎҢзҡ„иҝҷдәӣжҢҮд»ӨпјҢе…¶е®һд№ҹжҳҜеҲ©з”ЁдәҶеұҖйғЁжҖ§еҺҹзҗҶгҖӮ
йҡҸжңәйў„жөӢзңӢеҗҚеӯ—е°ұзҹҘйҒ“дәҶпјҢиҝҷжҳҜи’ҷиӢұиҜӯйҖүжӢ©йўҳзҡ„еҸҰдёҖз§Қж–№ејҸпјҢзһҺзҢңпјҢйҡҸжңәйҖүдёҖдёӘж–№еҗ‘зӣҙжҺҘжү§иЎҢгҖӮ
иҝҳжңүеҫҲеӨҡе°ұдёҚдёҖдёҖеҲ—дёҫдәҶпјҢеҗ„дҪҚжңүе…ҙи¶ЈиҮӘиЎҢеҺ»з ”究пјҢйЎәдҫҝжҸҗдёҖдёӢеңЁ 2018 е№ҙи°·жӯҢзҡ„йӣ¶йЎ№зӣ®е’Ңе…¶д»–з ”з©¶дәәе‘ҳе…¬еёғдәҶдёҖдёӘеҗҚдёә Spectre зҡ„зҒҫйҡҫжҖ§е®үе…ЁжјҸжҙһпјҢе…¶еҸҜеҲ©з”Ё CPU зҡ„еҲҶж”Ҝйў„жөӢжү§иЎҢжі„жјҸж•Ҹж„ҹдҝЎжҒҜпјҢиҝҷйҮҢе°ұдёҚеұ•ејҖдәҶпјҢж–Үжң«дјҡйҷ„дёҠй“ҫжҺҘгҖӮ
д№ӢеҗҺеҸҲжңүдёӘеҗҚдёә BranchScope зҡ„ж”»еҮ»пјҢд№ҹжҳҜеҲ©з”Ёйў„жөӢжү§иЎҢпјҢжүҖд»ҘиҜҙжҜҸеҪ“дёҖдёӘж–°зҡ„зҺ©ж„ҸеҮәжқҘжҖ»жҳҜдјҡеёҰжқҘеҲ©ејҠгҖӮ
иҮіжӯӨжҲ‘们已з»ҸзҹҘжҷ“дәҶд»Җд№ҲеҸ«жҢҮд»ӨжөҒж°ҙзәҝе’ҢеҲҶж”Ҝйў„жөӢдәҶпјҢд№ҹзҗҶи§ЈдәҶ Dubbo дёәд»Җд№ҲиҰҒиҝҷд№ҲдјҳеҢ–дәҶпјҢдҪҶжҳҜж–Үз« иҝҳжІЎжңүз»“жқҹпјҢжҲ‘иҝҳжғіжҸҗдёҖжҸҗиҝҷдёӘ stackoverflow йқһеёёжңүеҗҚзҡ„й—®йўҳпјҢзңӢзңӢиҝҷж•°йҮҸгҖӮ
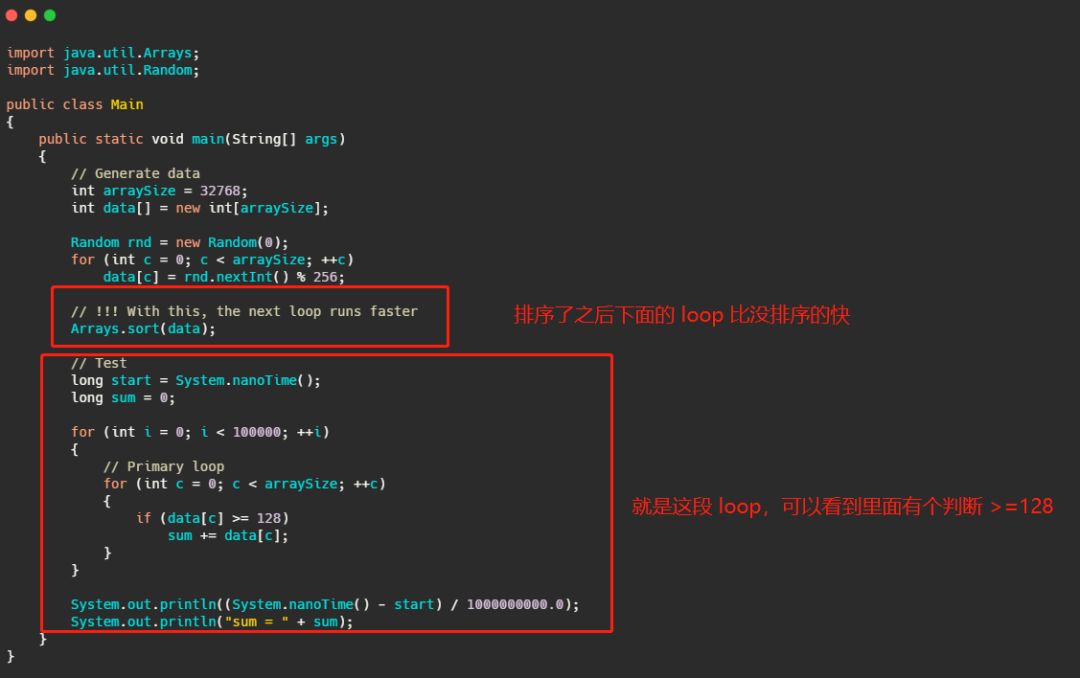
дёәд»Җд№ҲеӨ„зҗҶжңүеәҸж•°з»„иҰҒжҜ”йқһжңүеәҸж•°з»„еҝ«пјҹ иҝҷдёӘй—®йўҳеңЁйӮЈзҜҮеҚҡе®ўејҖеӨҙе°ұиў«жҸҗеҮәжқҘдәҶпјҢеҫҲжҳҺжҳҫиҝҷд№ҹжҳҜе’ҢеҲҶж”Ҝйў„жөӢжңүе…ізі»пјҢ既然зңӢеҲ°дәҶзҙўжҖ§е°ұеҶҚеҲҶжһҗдёҖжіўпјҢеӨ§дјҷеҸҜд»ҘеңЁи„‘жө·йҮҢе…Ҳеӣһзӯ”дёҖдёӢиҝҷдёӘй—®йўҳпјҢжҜ•з«ҹе’ұ们йғҪзҹҘйҒ“зӯ”жЎҲдәҶпјҢзңӢзңӢжҖқи·Ҝжё…жҷ°дёҚгҖӮ
е°ұжҳҜдёӢйқўиҝҷж®өд»Јз ҒпјҢж•°з»„жҺ’еәҸдәҶд№ӢеҗҺеҫӘзҺҜзҡ„жӣҙеҝ«гҖӮ
然еҗҺеҗ„и·ҜеӨ§зҘһе°ұи№ҰеҮәжқҘдәҶпјҢжҲ‘们жқҘзңӢдёҖдёӢйҰ–иөһзҡ„еӨ§дҪ¬жҖҺд№ҲиҜҙзҡ„гҖӮ
дёҖејҖеҸЈе°ұжҳҜпјҢзӣҙеҮ»иҰҒе®ігҖӮ
You are a victim of branch prediction fail.
зҙ§жҺҘзқҖе°ұдёҠеӣҫдәҶпјҢдёҖзңӢе°ұжҳҜиҖҒеҸёжңәгҖӮ
д»–иҜҙи®©жҲ‘们еӣһеҲ° 19дё–зәӘпјҢдёҖдёӘж— жі•иҝңи·қзҰ»дәӨжөҒдё”ж— зәҝз”өиҝҳжңӘжҷ®еҸҠзҡ„ж—¶еҖҷпјҢеҰӮжһңжҳҜдҪ иҝҷдёӘй“Ғи·ҜдәӨеҸүеҸЈзҡ„жүійҒ“е·ҘпјҢеҪ“зҒ«иҪҰеҝ«жқҘзҡ„ж—¶еҖҷпјҢдҪ еҰӮдҪ•еҫ—зҹҘиҜҘжүіе“ӘдёҖиҫ№пјҹ
зҒ«иҪҰеҒңиҪҰеҶҚйҮҚеҗҜзҡ„ж¶ҲиҖ—жҳҜеҫҲеӨ§зҡ„пјҢжҜҸж¬ЎеҲ°еҲҶеҸүеҸЈйғҪеҒңиҪҰпјҢ然еҗҺдҪ й—®д»–пјҢе“Ҙ们еҺ»е“Әе•ҠпјҢ然еҗҺжүідәҶйҒ“пјҢеҶҚйҮҚеҗҜе°ұеҫҲиҖ—ж—¶пјҢжҖҺд№ҲеҠһпјҹзҢңпјҒ
зҢңеҜ№дәҶзҒ«иҪҰе°ұдёҚз”ЁеҒңпјҢ继з»ӯејҖгҖӮзҢңй”ҷдәҶе°ұеҒңиҪҰ然еҗҺеҖ’иҪҰ然еҗҺжҚўйҒ“еҶҚејҖгҖӮ
жүҖд»Ҙе°ұзңӢзҢңзҡ„еҮҶдёҚеҮҶдәҶпјҒжҗҸдёҖжҗҸеҚ•иҪҰеҸҳж‘©жүҳгҖӮ
然еҗҺеӨ§дҪ¬еҸҲжҢҮеҮәдәҶе…ій”®д»Јз ҒеҜ№еә”зҡ„жұҮзј–д»Јз ҒпјҢд№ҹе°ұжҳҜи·іиҪ¬жҢҮд»ӨдәҶпјҢиҝҷеҜ№еә”зҡ„е°ұжҳҜзҒ«иҪҰзҡ„еІ”еҸЈпјҢиҜҘйҖүжқЎи·ҜдәҶгҖӮ
еҗҺйқўжҲ‘е°ұдёҚеҲҶжһҗдәҶпјҢеӨ§дјҷе„ҝеә”иҜҘйғҪзҹҘйҒ“дәҶпјҢжҺ’е®ҢеәҸзҡ„ж•°з»„жү§иЎҢеҲ°еҖјеӨ§дәҺ 128 зҡ„д№ӢеҗҺиӮҜе®ҡе…ЁйғЁеӨ§дәҺ128дәҶпјҢжүҖд»ҘжҜҸж¬ЎеҲҶж”Ҝйў„жөӢзҡ„з»“жһңйғҪжҳҜеҜ№дәҶпјҒжүҖд»Ҙжү§иЎҢзҡ„ж•ҲзҺҮеҫҲй«ҳгҖӮ
иҖҢжІЎжҺ’еәҸзҡ„ж•°з»„жҳҜд№ұеәҸзҡ„пјҢжүҖд»ҘеҫҲеӨҡж—¶еҖҷйғҪдјҡйў„жөӢй”ҷиҜҜпјҢиҖҢйў„жөӢй”ҷиҜҜе°ұеҫ—жҢҮд»ӨжөҒж°ҙзәҝжҺ’з©әе•ҠпјҢ然еҗҺеҶҚжқҘдёҖйҒҚпјҢиҝҷйҖҹеәҰеҪ“然е°ұж…ўдәҶгҖӮ
жүҖд»ҘеӨ§дҪ¬иҜҙиҝҷдёӘйўҳдё»дҪ жҳҜеҲҶж”Ҝйў„жөӢй”ҷиҜҜзҡ„еҸ—е®іиҖ…гҖӮ
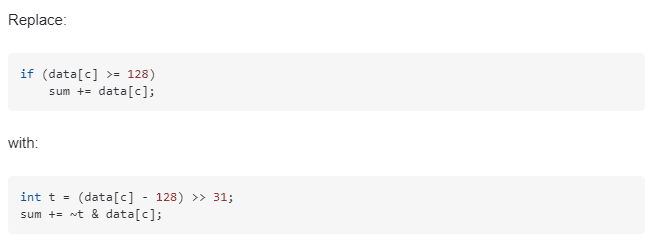
жңҖз»ҲеӨ§дҪ¬з»ҷеҮәзҡ„дҝ®ж”№ж–№жЎҲжҳҜе’ұдёҚз”Ё if дәҶпјҢжғ№дёҚиө·е’ұиҝҳиәІдёҚиө·еҳӣпјҹзӣҙжҺҘеҲ©з”ЁдҪҚиҝҗз®—жқҘе®һзҺ°иҝҷдёӘеҠҹиғҪпјҢе…·дҪ“жҲ‘е°ұдёҚеҲҶжһҗдәҶпјҢз»ҷеӨ§е®¶зңӢдёӢеӨ§дҪ¬зҡ„е»әи®®дҝ®ж”№ж–№жЎҲгҖӮ
еҲ°жӯӨпјҢзӣёдҝЎеӨ§е®¶еҜ№вҖңDubboжәҗз ҒеҲ°CPUеҲҶж”Ҝйў„жөӢе®һдҫӢеҲҶжһҗвҖқжңүдәҶжӣҙж·ұзҡ„дәҶи§ЈпјҢдёҚеҰЁжқҘе®һйҷ…ж“ҚдҪңдёҖз•Әеҗ§пјҒиҝҷйҮҢжҳҜдәҝйҖҹдә‘зҪ‘з«ҷпјҢжӣҙеӨҡзӣёе…іеҶ…е®№еҸҜд»Ҙиҝӣе…Ҙзӣёе…ійў‘йҒ“иҝӣиЎҢжҹҘиҜўпјҢе…іжіЁжҲ‘们пјҢ继з»ӯеӯҰд№ пјҒ