Kubernetesж—Ҙеҝ—йҮҮйӣҶдёҺзӣ‘жҺ§е‘ҠиӯҰзҹҘиҜҶзӮ№жңүе“Әдәӣ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңKubernetesж—Ҙеҝ—йҮҮйӣҶдёҺзӣ‘жҺ§е‘ҠиӯҰзҹҘиҜҶзӮ№жңүе“ӘдәӣвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңKubernetesж—Ҙеҝ—йҮҮйӣҶдёҺзӣ‘жҺ§е‘ҠиӯҰзҹҘиҜҶзӮ№жңүе“ӘдәӣвҖқеҗ§пјҒ
1. е®№еҷЁж—Ҙеҝ—йҮҮйӣҶдёҺз®ЎзҗҶ
ж—Ҙеҝ—йҮҮйӣҶеңәжҷҜ
ж—Ҙеҝ—йҮҮйӣҶеңәжҷҜдё»иҰҒеҲҶдёәд»ҘдёӢеӣӣз§Қпјҡ
йӣҶзҫӨж ёеҝғ组件ж—Ҙеҝ—пјҡ
е®Ўи®ЎйңҖиҰҒ kube-apiserver ж—Ҙеҝ—пјҢиҜҠж–ӯи°ғеәҰйңҖиҰҒ kube-scheduler ж—Ҙеҝ—пјҢжҺҘе…ҘеұӮжөҒйҮҸеҲҶжһҗйңҖиҰҒ Ingress ж—Ҙеҝ—гҖӮ
дё»жңәеҶ…ж ёж—Ҙеҝ—пјҡ
еҶ…ж ёж—Ҙеҝ—еҸҜд»Ҙз”ЁдәҺеё®еҠ©ејҖеҸ‘еҸҠиҝҗз»ҙеҗҢеӯҰиҜҠж–ӯеҪұе“ҚиҠӮзӮ№зЁіе®ҡзҡ„ејӮеёёпјҢеҰӮпјҡж–Ү件系з»ҹејӮеёёпјҢзҪ‘з»ңж ҲејӮеёёпјҢи®ҫеӨҮй©ұеҠЁејӮеёёзӯүгҖӮ
еә”з”ЁиҝҗиЎҢж—¶ж—Ҙеҝ—пјҡ
Docker жҳҜжңҖеёёи§Ғзҡ„е®№еҷЁиҝҗиЎҢж—¶пјҢеҸҜд»ҘеҲ©з”Ё Docker е’Ң Kubelet ж—Ҙеҝ—жҺ’жҹҘ Pod еҲӣе»әе’ҢеҗҜеҠЁеӨұиҙҘзӯүй—®йўҳгҖӮ
дёҡеҠЎеә”з”Ёж—Ҙеҝ—пјҡ
йҖҡиҝҮеҲҶжһҗдёҡеҠЎзҡ„иҝҗиЎҢж—Ҙеҝ—еҲҶжһҗе’Ңи§ӮеҜҹдёҡеҠЎзҠ¶жҖҒпјҢиҜҠж–ӯејӮеёёгҖӮ
ж—Ҙеҝ—йҮҮйӣҶжҢҮж Ү
Kubernetes еҜ№е®№еҷЁж—Ҙеҝ—зҡ„жңҹжңӣеӨ„зҗҶж–№ејҸдёәпјҡйӣҶзҫӨзә§ж—Ҙеҝ—еӨ„зҗҶпјҲcluster-level-loggingпјү
еҚіпјҡдёҺе®№еҷЁгҖҒPodгҖҒиҠӮзӮ№з”ҹе‘Ҫе‘Ёжңҹе®Ңе…Ёж— е…ігҖӮ
еҜ№дәҺдёҖдёӘе®№еҷЁпјҢеҪ“еә”з”Ёе°Ҷж—Ҙеҝ—иҫ“еҮәеҲ° stdout е’Ң stderr еҗҺпјҢdocker й»ҳи®Өе°Ҷиҝҷдәӣж—Ҙеҝ—иҫ“еҮәеҲ°е®ҝдё»жңәдёҠдёҖдёӘ JSON ж–Ү件дёӯгҖӮ

ж—Ҙеҝ—йҮҮйӣҶж–№ејҸ
Kubernetes жң¬иә«е№¶дёҚдјҡеҜ№з”ЁжҲ·иҝӣиЎҢд»»дҪ•зҡ„ж—Ҙеҝ—жҗңйӣҶе·ҘдҪңгҖӮдёәдәҶе®һзҺ°йӣҶзҫӨзә§ж—Ҙеҝ—еӨ„зҗҶпјҢйңҖиҰҒеңЁйӣҶзҫӨеүҚпјҢжҸҗеүҚеҜ№ж—Ҙеҝ—йҮҮйӣҶз®ЎзҗҶиҝӣиЎҢж–№жЎҲ规еҲ’гҖӮ
Kubernetes жң¬иә«жҺЁиҚҗ3з§Қж—Ҙеҝ—ж–№жЎҲгҖӮ
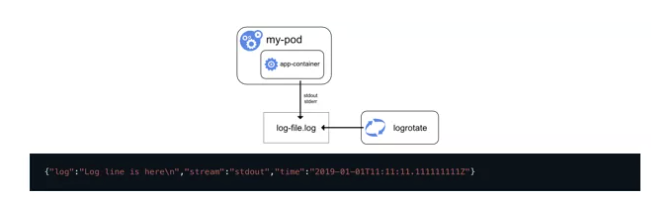
ж—Ҙеҝ—йҮҮйӣҶж–№ејҸ1пјҡдҪҝз”ЁиҠӮзӮ№зә§ж—Ҙеҝ—д»ЈзҗҶ
ж ёеҝғжҳҜ logging-agent пјҲfluentdпјҢetc пјүпјӣ
Logging-agent д»Ҙ DaemonSet ж–№ејҸиҝҗиЎҢеңЁиҠӮзӮ№дёҠпјӣ
жҢӮиҪҪе®ҝдё»жңәдёҠзҡ„е®№еҷЁж—Ҙеҝ—зӣ®еҪ•пјӣ
иҪ¬еҸ‘ж—Ҙеҝ—иҮіеҗҺз«ҜеӯҳеӮЁпјҲElasticSearch, etcпјү;
дјҳзӮ№пјҡеҜ№еә”з”Ёе’ҢPodе®Ңе…Ёж— дҫөе…ҘпјҢдёҖдёӘиҠӮзӮ№д»…йңҖйғЁзҪІдёҖдёӘ agentгҖӮ
зјәзӮ№пјҡиҰҒжұӮеә”з”Ёж—Ҙеҝ—зӣҙжҺҘиҫ“еҮәиҮіе®№еҷЁзҡ„ stdout е’Ң stderrгҖӮ
ж—Ҙеҝ—йҮҮйӣҶж–№ејҸ2пјҡдҪҝз”Ё sidecar е®№еҷЁе’Ңж—Ҙеҝ—д»ЈзҗҶ
е®№еҷЁе…ЁйғЁжҲ–йғЁеҲҶж—Ҙеҝ—иҫ“еҮәеҲ°ж–Ү件
дёҖдёӘжҲ–еӨҡдёӘ sidecar е®№еҷЁе°Ҷеә”з”ЁзЁӢеәҸж—Ҙеҝ—дј йҖҒеҲ°иҮӘе·ұзҡ„ stdout е’Ң stderrгҖӮ

дјҳзӮ№пјҡиғҪеӨҹ继з»ӯдҪҝз”Ёж—Ҙеҝ—йҮҮйӣҶж–№ејҸ1гҖӮ
зјәзӮ№пјҡжҲҗеҖҚеўһеҠ зЈҒзӣҳеҚ з”ЁпјҢйҖ жҲҗжөӘиҙ№гҖӮпјҲеә”з”Ёе’Ңsidecarе®№еҷЁеҶҷе…ҘдёӨд»ҪзӣёеҗҢж—Ҙеҝ—ж–Ү件пјү
ж—Ҙеҝ—йҮҮйӣҶж–№ејҸ3пјҡдҪҝз”Ёе…·жңүж—Ҙеҝ—д»ЈзҗҶеҠҹиғҪзҡ„ sidecar е®№еҷЁ
зӣёеҪ“дәҺе°Ҷ logging-agent зӣҙжҺҘйӣҶжҲҗиҝӣ PodгҖӮ
еә”з”Ёе’Ңиҫ“еҮәж—Ҙеҝ—иҮі stdout&stderr жҲ–ж–Ү件гҖӮ
Logging-agent зҡ„иҫ“е…Ҙжәҗдёәеә”з”Ёж—Ҙеҝ—ж–Ү件гҖӮ
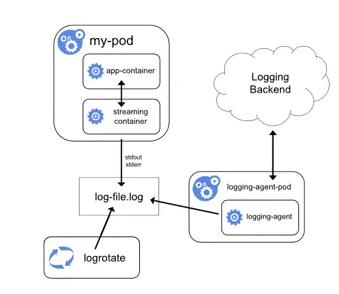
дјҳзӮ№пјҡйғЁзҪІз®ҖеҚ•пјҢеҜ№е®ҝдё»жңәеҸӢеҘҪгҖӮ
зјәзӮ№пјҡ1. Sidecar е®№еҷЁеҸҜиғҪж¶ҲиҖ—иҫғеӨҡиө„жәҗпјҢз”ҡиҮіжӢ–жҢӮеә”з”Ёе®№еҷЁгҖӮ
2. ж— жі•дҪҝз”Ё kubectl logs е‘Ҫд»ӨжҹҘзңӢе®№еҷЁж—Ҙеҝ—гҖӮ
жҖ»з»“пјҡ
е®һзҺ°йӣҶзҫӨзә§ж—Ҙеҝ—йҮҮйӣҶзҡ„дёүз§Қж–№ејҸпјҡ
дҪҝз”ЁиҠӮзӮ№зә§ж—Ҙеҝ—д»ЈзҗҶгҖӮ
дҪҝз”Ё sidecar е®№еҷЁе’Ңж—Ҙеҝ—д»ЈзҗҶгҖӮ
дҪҝз”Ёе…·жңүж—Ҙеҝ—д»ЈзҗҶеҠҹиғҪзҡ„ sidecar е®№еҷЁгҖӮ
е»әи®®пјҡдҪҝз”Ёж–№жЎҲ1пјҢе°Ҷеә”з”Ёж—Ҙеҝ—иҫ“еҮәеҲ° stdout&stderrпјҢйҖҡиҝҮе®ҝдё»жңәдёҠзӣҙжҺҘйғЁзҪІlogging-agent зҡ„ж–№ејҸйӣҶдёӯеӨ„зҗҶж—Ҙеҝ—гҖӮ
з®ЎзҗҶз®ҖеҚ•гҖӮ
еҸҜд»ҘдҪҝз”Ё kubectl logs е‘Ҫд»ӨжҹҘзңӢж—Ҙеҝ—гҖӮ
е®ҝдё»жңәжң¬иә«еҸҜиғҪе·Іжңү rstlogd зӯүжҲҗзҶҹж—Ҙеҝ—收йӣҶ组件еҸҜдҪҝз”ЁгҖӮ
йҖүеһӢжҺЁиҚҗ
2. е®№еҷЁзӣ‘жҺ§жҢҮж Үзҡ„йҮҮйӣҶдёҺз®ЎзҗҶ
зӣ‘жҺ§еңәжҷҜ
д»Һзӣ‘жҺ§зұ»еһӢеҲ’еҲҶпјҢеҸҜеҲҶдёәд»ҘдёӢеҮ дёӘеңәжҷҜ:
иө„жәҗзӣ‘жҺ§пјҡ
CPUпјҢеҶ…еӯҳпјҢзҪ‘з»ңзӯүиө„жәҗзұ»жҢҮж ҮпјҢеёёд»Ҙж•°еҖјпјҢзҷҫеҲҶжҜ”дёәеҚ•дҪҚиҝӣиЎҢз»ҹи®ЎпјҢжҳҜжңҖеёёи§Ғзҡ„иө„жәҗзӣ‘жҺ§ж–№ејҸгҖӮ
жҖ§иғҪзӣ‘жҺ§пјҡ
еә”з”Ёзҡ„еҶ…йғЁзӣ‘жҺ§гҖӮйҖҡеёёжҳҜ Hock жңәеҲ¶еңЁиҷҡжӢҹжңәеұӮпјҢеӯ—иҠӮз Ғжү§иЎҢеұӮйҡҗејҸеӣһи°ғпјҢжҲ–иҖ…еңЁеә”з”ЁеұӮжҳҫејҸжіЁе…ҘпјҢиҺ·еҸ–жӣҙж·ұеұӮж¬Ўзҡ„зӣ‘жҺ§жҢҮж ҮпјҢеёёз”ЁжқҘеә”з”ЁиҜҠж–ӯдёҺи°ғдјҳгҖӮ
жҜ”еҰӮ Jvm йҖҡиҝҮ Hock жңәеҲ¶,жӢҝеҲ°зұ»дјј Jvm йҮҢйқўзҡ„еһғеңҫеӣһ收зҡ„ж¬Ўж•°пјҢеҗ„з§ҚеҶ…еӯҳеёҰзҡ„еҲҶеёғд»ҘеҸҠзҪ‘з»ңиҝһжҺҘж•°зҡ„дёҖдәӣжҢҮж ҮгҖӮйҖҡиҝҮиҝҷж ·зҡ„ж–№ејҸжқҘиҝӣиЎҢеә”з”Ёзҡ„иҜҠж–ӯдёҺи°ғдјҳгҖӮ
е®үе…Ёзӣ‘жҺ§пјҡ
й’ҲеҜ№е®үе…ЁиҝӣиЎҢдёҖзі»еҲ—зӣ‘жҺ§зӯ–з•ҘпјҢдҫӢеҰӮи¶Ҡжқғз®ЎзҗҶпјҢе®үе…ЁжјҸжҙһжү«жҸҸзӯүгҖӮ
дәӢ件зӣ‘жҺ§пјҡ
Kubernetes дёӯзү№жңүзҡ„зӣ‘жҺ§ж–№ејҸпјҢиҙҙеҗҲ Kubernetes и®ҫи®ЎзҗҶеҝөпјҢдҪңдёә常规зӣ‘жҺ§ж–№жЎҲзҡ„иЎҘе……гҖӮ
дёәд»Җд№ҲиҜҙдәӢ件зӣ‘жҺ§иҙҙеҗҲ Kubernetes и®ҫи®ЎзҗҶеҝөе‘ўпјҹиҝҷжҳҜеӣ дёә Kubernetes е…¶дёӯдёҖдёӘи®ҫи®ЎзҗҶеҝөе°ұжҳҜеҹәдәҺзҠ¶жҖҒжңәзҡ„зҠ¶жҖҒиҪ¬жҚўгҖӮд»ҺжӯЈеёёзҠ¶жҖҒиҪ¬жҚўжҲҗеҸҰдёҖдёӘзҠ¶жҖҒзҡ„ж—¶еҖҷпјҢдјҡеҸ‘з”ҹдёҖдёӘ Normal зә§еҲ«зҡ„дәӢ件(д№ҹе°ұжҳҜжӯЈеёёзҡ„дәӢ件)иҖҢд»ҺдёҖдёӘжӯЈеёёзҠ¶жҖҒиҪ¬жҚўжҲҗејӮеёёзҠ¶жҖҒж—¶пјҢе№іеҸ°дјҡи§ҰеҸ‘дёҖдёӘ Warning зә§еҲ«пјҲд№ҹе°ұжҳҜиӯҰе‘Ҡзә§еҲ«зҡ„дәӢ件пјүйҖҡеёёпјҢWarning зә§еҲ«зҡ„дәӢ件жҳҜжҲ‘们关еҝғзҡ„дәӢ件гҖӮ
иҖҢдәӢ件зӣ‘жҺ§е°ұеҸҜд»ҘжҠҠ Normal зә§еҲ«зҡ„дәӢ件жҲ– Warning зә§еҲ«зҡ„дәӢ件зҰ»зәҝеӯҳеӮЁеҲ°ж•°жҚ®дёӯеҝғпјҢ然еҗҺйҖҡиҝҮж•°жҚ®дёӯеҝғзҡ„еҲҶжһҗдёҺжҠҘиӯҰпјҢе°Ҷзӣёеә”зҡ„ејӮеёёйҖҡиҝҮзҹӯдҝЎпјҢйӮ®д»¶зҡ„ж–№ејҸжҡҙйңІпјҢејҘиЎҘ常规зӣ‘жҺ§зҡ„ејҠз«ҜгҖӮ
Prometheus зҡ„иө·жәҗеҸҠзҺ°зҠ¶
Prometheus дёҺ Kubernetes дёҖж ·пјҢжқҘиҮӘдәҺ Borg дҪ“зі»гҖӮеҺҹеһӢеҸ«еҒҡ BorgMonпјҢжҳҜдёҺBorgеҗҢж—¶иҜһз”ҹзҡ„еҶ…йғЁзӣ‘жҺ§зі»з»ҹгҖӮиҖҢPrometheusйЎ№зӣ®еҸ‘иө·зҡ„еҺҹеӣ д№ҹдёҺKubernetes зұ»дјјпјҢеёҢжңӣйҖҡиҝҮеҜ№з”ЁжҲ·жӣҙеҸӢеҘҪзҡ„ж–№ејҸпјҢе°Ҷ Google еҶ…йғЁзі»з»ҹзҡ„и®ҫи®ЎзҗҶеҝөдј йҖ’з»ҷејҖеҸ‘иҖ…е’Ңз”ЁжҲ·гҖӮ
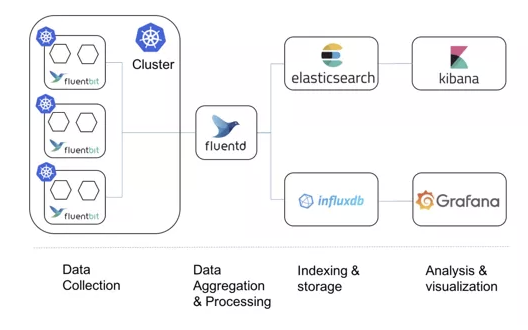
Kubernetes зӣ‘жҺ§дҪ“зі»жӣҫз»Ҹйқһеёёз№ҒжқӮпјҢдҪҶд»ҠеӨ©е·Із»Ҹжј”еҸҳжҲҗдәҶд»Ҙ Prometheus дёәж ёеҝғзҡ„дёҖеҘ—з»ҹдёҖзҡ„ж–№жЎҲгҖӮ
Prometheus зҡ„жһ¶жһ„дёҺе·ҘдҪңж–№ејҸ

Prometheus жҢҮж ҮжқҘжәҗ
е®ҝдё»жңәзҡ„зӣ‘жҺ§ж•°жҚ®пјҡйңҖиҰҒеҖҹеҠ© Node Exporter еҗ‘еӨ–жҡҙйңІ; Exporter д»Јжӣҝиў«зӣ‘жҺ§еҜ№иұЎжқҘеҗ‘ Prometheus жҡҙйңІеҸҜд»Ҙиў«жҠ“еҸ–зҡ„жҢҮж ҮдҝЎжҒҜгҖӮ
Kubernetes 组件еҰӮ APIServer, kubelet зӯүзҡ„/metrics AP:йҷӨCPUпјҢеҶ…еӯҳеӨ–пјҢиҝҳеҢ…жӢ¬еҗ„дёӘ组件зҡ„ж ёеҝғзӣ‘жҺ§жҢҮж ҮгҖӮ
Kubernetes ж ёеҝғзҡ„зӣ‘жҺ§ж•°жҚ®пјҡеҢ…жӢ¬PodгҖҒNodeгҖҒе®№еҷЁгҖҒServiceзӯүдё»иҰҒж ёеҝғжҰӮеҝөзҡ„ metricsпјҢе…¶дёӯе®№еҷЁзӣёе…ізҡ„жҢҮж ҮжқҘжәҗдәҺ kubectl еҶ…зҪ®зҡ„ cAdvisor жңҚеҠЎгҖӮ
Prometheus зү№зӮ№
з®ҖжҙҒејәеӨ§зҡ„жҺҘе…Ҙж ҮеҮҶгҖӮеҸӘиҰҒе®һзҺ° Promethus Client жҺҘеҸЈпјҢе°ұеҸҜд»ҘзӣҙжҺҘе®һзҺ°ж•°жҚ®зҡ„йҮҮйӣҶгҖӮ
еӨҡз§Қж•°жҚ®йҮҮйӣҶж–№ејҸгҖӮеҢ…жӢ¬пјҡеңЁзәҝпјҢзҰ»зәҝпјҢpush, pull иҒ”йӮҰзҡ„ж–№ејҸиҝӣиЎҢж•°жҚ®йҮҮйӣҶгҖӮ
е’Ң Kubernetesе®Ң е…Ёе…је®№гҖӮ
дё°еҜҢзҡ„жҸ’件жңәеҲ¶е’Ңз”ҹжҖҒгҖӮ
Prometheus Operator еҠ©еҠӣгҖӮдҪҝ Prometheus зҡ„иҝҗз»ҙе®һзҺ°иҮӘеҠЁеҢ–гҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңKubernetesж—Ҙеҝ—йҮҮйӣҶдёҺзӣ‘жҺ§е‘ҠиӯҰзҹҘиҜҶзӮ№жңүе“ӘдәӣвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№Kubernetesж—Ҙеҝ—йҮҮйӣҶдёҺзӣ‘жҺ§е‘ҠиӯҰзҹҘиҜҶзӮ№жңүе“ӘдәӣиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ





