之前在arduino上的实现的新的步进电机算法,需要移植到32位MKE06K128上。这个任务听上去事实而非,整个Marlin固件还涉及别的部分,比如PID加热控制模块,舵机模块,串口指令读取代码。但是我们cocky的Teamleader很反感移植Marlin。没办法,这一步我的理解,只要能实现plan_buffer_line就算完成任务。进一步简化,只要实现一个轴的plan_buffer_line就算完成任务。
硬件连接部分:
我们cocky的Teamleader是个能干的人,很快画出并焊好了MKE06K128的电路板供我当作开发板使用。Freescale有基于eclipse的专用开发环境Kinetis Design Studio,简称KDS,KDS既集成了MKE的交叉编译器,而且以插件的形式提供了“专家系统”,能够可视化的配置硬件管脚,并且生成示意图方便review(如下图),看上去很酷。
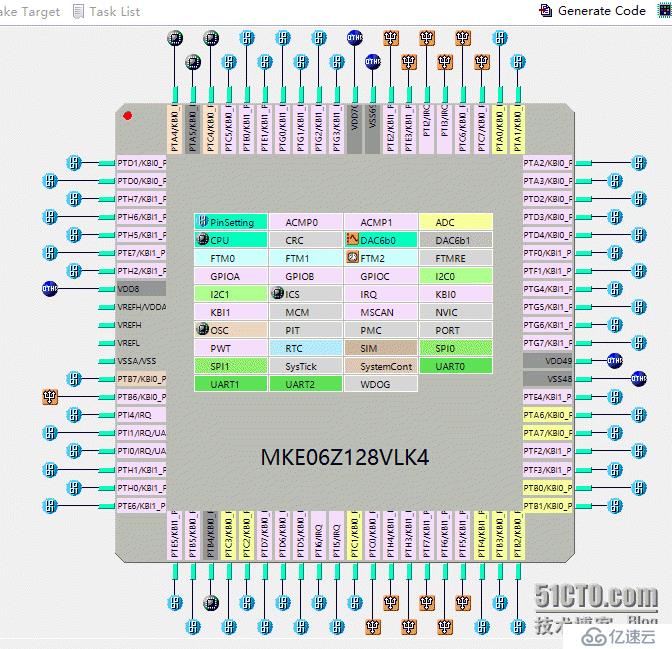
这个专家工具在调试硬件和快速实现阶段也非常方便。我在电路板上接上Jlink,并且连接上A4988和步进电机,在排除掉A4988的损坏之后。编写一个简答的定时器程序,并把周期写成3.2KHz(请参考arduino上的实现中关于3.2K的来历),步进电机就应该以1rad/s的速度转,如果不是,就要用示波器和万用表排除芯片,电路板,电源和Jlink的故障可能。如果是,就为下一步编写固件代码打下了坚实的基础。最终调试好的硬件连接图如下:

使用jlink时注意,
在系统上电的情况下,需要去掉jlink上供电的跳线帽,否则无法进行刷写工作。
即使脉冲宽度很窄,也可以驱动电机,而且窄脉冲的噪音很小。
A4988的EN路上拉到电路5V,需要软件将其拉低,步进电机才能正常驱动,否则驱动电路不使能。
软件实现部分:
首先实现plan_buffer_line()函数,需要编写%Planner和%Stepper两个模块。前者管理队列,后者管理步进电机的中断响应驱动。和Marlin固件的区别在于,这里的%Planner不必计算执行的各个速度节点,而是只需要设置稳定后的速度值,%Stepper会动态的计算出瞬时速度。
队列和队列指针都在%Planner模块中定义为全局变量,由于声明了external 关键字,当其他项目包含planner.h时就会引入该变量,即等效于该全局变量为全项目全局变量。
%Planner.cpp中:
block_t block_buffer[BLOCK_BUFFER_SIZE]; volatile unsigned char block_buffer_head; volatile unsigned char block_buffer_tail;
另外设置了几个强制内联函数:
FORCE_INLINE block_t *plan_get_current_block();//读取当前block函数
FORCE_INLINE bool blocks_queued() { return (block_buffer_head != block_buffer_tail); }//队列是否非空在这里:
#define FORCE_INLINE attribute((always_inline)) inline
告诉编译器,设置为强制内联型;对于此,Cpp的语法解释是:
inline关键字仅仅是建议编译器做内联展开处理,而不是强制。在gcc编译器中,如果编译优化设置为-O0,即使是inline函数也不会被内联展开,除非设置了强制内联(attribute((always_inline)))属性。
关于内联函数,补充一点基础知识:
在内联函数内不允许用循环语句和开关语句。否则会被编译器当作普通函数。
在%stepper.cpp中定义了:
block_t *current_block //当前运动实例
由于没有在stepper.h中定义相应的extern 类型,所以该变量为模块内的private全局变量。
即使是使用32位单片机,也不应该在中断响应函数中进行浮点运算,否则中断频率会被大大拖慢。所以%stepper函数的最终结果为:
void ST_PULSE_TI_OnInterrupt(void) {
/* Write your code here ... */
#ifndef HARDWARE_DEBUG_MODE
if (!current_block) {
current_block = plan_get_current_block();
}
#define DISTANCE_COUNT_RESET current_block->rounds_count_per_mstep-=current_block->one_micro_step_mm
#define DISTANCE_IS_ONESTEP current_block->rounds_count_per_mstep>=current_block->one_micro_step_mm
#define DRIVE_PULSE E0_STE_SetVal(); \
E0_STE_ClrVal()
/*==========generate a pulse when a step accumulated===========*/
if (DISTANCE_IS_ONESTEP) {
DRIVE_PULSE;
DISTANCE_COUNT_RESET;
}
/*update the new speed and ... */
if (current_block) {
if (current_block->rounds_behind + current_block->rounds_ahead
< current_block->rounds) {
// accumulate the rounds and the microstep_count_for_rounds
current_block->rounds_behind += current_block->instance_rate;
current_block->rounds_count_per_mstep +=current_block->instance_rate;
//when speed climbing up case
if (current_block->instance_rate < current_block->nominal_rate) {
current_block->instance_rate += current_block->acceleration;
}
//when hold the nominal_rate case
else {
//make sure the rate remains nominal_rate
current_block->instance_rate = current_block->nominal_rate;
}
// update the rounds left for all the three case.
current_block->rounds_ahead=current_block->instance_rate/2/current_block->acceleration*current_block->instance_rate;
}
//when speed slipping down case
else if (current_block->instance_rate > current_block->exit_rate) {
current_block->rounds_behind+= current_block->instance_rate;
current_block->rounds_count_per_mstep +=current_block->instance_rate;
current_block->instance_rate -= current_block->acceleration;
}
// at the end of the block
else if (current_block->instance_rate <= current_block->exit_rate) {
current_block->instance_rate = 0;
current_block->nominal_rate = 0;
current_block->rounds_ahead = 0;
current_block->acceleration = 0;
current_block->rounds = 0;
current_block->rounds_count_per_mstep = 0;
//ST_PULSE_TI_Disable();//current_block should update
current_block = NULL;
}
}
#endif
}浮点数主要来自两方面,一是每个中断响应函数中的单位时间delta t;另一个是转每秒这个单位中,转往往是小数。为了消灭浮点数,我们对单位进行了转换:
void plan_buffer_line(const float e, float feed_rate) {
//void plan_buffer_line(const float x, const float y, const float z, const float e, float feed_rate, const uint8_t extruder){
// e is unit of round
// feedrate is unit of round per second
// push a block into pipeline
block_t *block = &block_buffer[block_buffer_head];
//update the ini value of the block
block->nominal_rate =(unsigned int)(feed_rate*ST_PULSE_FREQ);
block->rounds = (unsigned int)(e - position[E_AXIS])*FLOAT_FACTOR;
block->entry_rate = 0;
block->exit_rate = 0;
block->acceleration = (unsigned int)(DEFAULT_ACCELERATION);
block->direction_bits = e > position[E_AXIS] ? 1 : 0;
block->one_micro_step_mm=(unsigned int)FLOAT_FACTOR/MICROSTEP/RESOLUTION;
ST_PULSE_TI_Enable();
//Enable the Interruption for stepper control and plannerS
// Move buffer head
block_buffer_head = next_block_index(block_buffer_head);
//block_buffer_head=block_buffer_head+1;
// Update position
position[E_AXIS] = e;
}其中,在configuration.h中定义了转换宏:
#define ST_PULSE_FREQ 10000 #define FLOAT_FACTOR (ST_PULSE_FREQ*ST_PULSE_FREQ)
由此可见,为了在计时器中断响应函数中不出现浮点数,必须要给位移,速度和加速度乘以一个因子。而为了防止程序中出现变量超出整型大小而溢出,计时器频率不能太高。具体的范围,又受限于打印机的位移范围(往往是0~200mm)。这种算法,数据结构和处理器浮点运算性能局限性的共同作用,产生了最终的代码,非常的经典。
正是由于Team leader质疑修改步进电机算法,我才能发现这么多隐藏在理所当然中的深刻限制和工程智慧,感谢他的偏执。同时我更加深刻理解了Marlin固件中步进电机算法的合理和经典。
(完)
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





