еҰӮдҪ•иҝӣиЎҢж•°жҚ®sinkеҲ°kafkaзҡ„ж“ҚдҪң
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶д»Ӣз»ҚеҰӮдҪ•иҝӣиЎҢж•°жҚ®sinkеҲ°kafkaзҡ„ж“ҚдҪңпјҢеҶ…е®№йқһеёёиҜҰз»ҶпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们еҸҜд»ҘеҸӮиҖғеҖҹйүҙпјҢеёҢжңӣеҜ№еӨ§е®¶иғҪжңүжүҖеё®еҠ©гҖӮ
дёӢйқўжқҘдҪ“йӘҢе°Ҷж•°жҚ®sinkеҲ°kafkaзҡ„ж“ҚдҪңгҖӮ
зүҲжң¬е’ҢзҺҜеўғеҮҶеӨҮ
жң¬ж¬Ўе®һжҲҳзҡ„зҺҜеўғе’ҢзүҲжң¬еҰӮдёӢпјҡ
JDKпјҡ1.8.0_211
Flinkпјҡ1.9.2
Mavenпјҡ3.6.0
ж“ҚдҪңзі»з»ҹпјҡmacOS Catalina 10.15.3 пјҲMacBook Pro 13-inch, 2018пјү
IDEAпјҡ2018.3.5 (Ultimate Edition)
Kafkaпјҡ2.4.0
Zookeeperпјҡ3.5.5
<font color="red">иҜ·зЎ®дҝқдёҠиҝ°зҺҜеўғе’ҢжңҚеҠЎе·Із»Ҹе°ұз»Әпјӣ</font>
жәҗз ҒдёӢиҪҪ
еҰӮжһңжӮЁдёҚжғіеҶҷд»Јз ҒпјҢж•ҙдёӘзі»еҲ—зҡ„жәҗз ҒеҸҜеңЁGitHubдёӢиҪҪеҲ°пјҢең°еқҖе’Ңй“ҫжҺҘдҝЎжҒҜеҰӮдёӢиЎЁжүҖзӨә(https://github.com/zq2599/blog_demos)пјҡ
| еҗҚз§° | й“ҫжҺҘ | еӨҮжіЁ |
|---|
| йЎ№зӣ®дё»йЎө | https://github.com/zq2599/blog_demos | иҜҘйЎ№зӣ®еңЁGitHubдёҠзҡ„дё»йЎө |
| gitд»“еә“ең°еқҖ(https) | https://github.com/zq2599/blog_demos.git | иҜҘйЎ№зӣ®жәҗз Ғзҡ„д»“еә“ең°еқҖпјҢhttpsеҚҸи®® |
| gitд»“еә“ең°еқҖ(ssh) | git@github.com:zq2599/blog_demos.git | иҜҘйЎ№зӣ®жәҗз Ғзҡ„д»“еә“ең°еқҖпјҢsshеҚҸи®® |
иҝҷдёӘgitйЎ№зӣ®дёӯжңүеӨҡдёӘж–Ү件еӨ№пјҢжң¬з« зҡ„еә”з”ЁеңЁ<font color="blue">flinksinkdemo</font>ж–Ү件еӨ№дёӢпјҢеҰӮдёӢеӣҫзәўжЎҶжүҖзӨәпјҡ  еҮҶеӨҮе®ҢжҜ•пјҢејҖе§ӢејҖеҸ‘пјӣ
еҮҶеӨҮе®ҢжҜ•пјҢејҖе§ӢејҖеҸ‘пјӣ
еҮҶеӨҮе·ҘдҪң
жӯЈејҸзј–з ҒеүҚпјҢе…ҲеҺ»е®ҳзҪ‘жҹҘзңӢзӣёе…іиө„ж–ҷдәҶи§Јеҹәжң¬жғ…еҶөпјҡ
ең°еқҖпјҡhttps://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/connectors/kafka.html
жҲ‘иҝҷйҮҢз”Ёзҡ„kafkaжҳҜ2.4.0зүҲжң¬пјҢеңЁе®ҳж–№ж–ҮжЎЈжҹҘжүҫеҜ№еә”зҡ„еә“е’Ңзұ»пјҢеҰӮдёӢеӣҫзәўжЎҶжүҖзӨәпјҡ 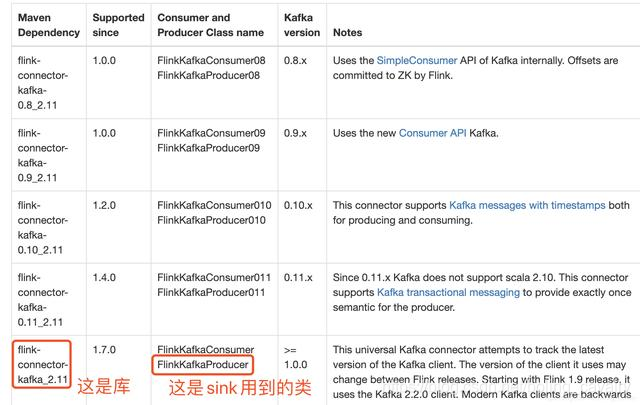
kafkaеҮҶеӨҮ
еҲӣе»әеҗҚдёәtest006зҡ„topicпјҢжңүеӣӣдёӘеҲҶеҢәпјҢеҸӮиҖғе‘Ҫд»Өпјҡ
./kafka-topics.sh \
--create \
--bootstrap-server 127.0.0.1:9092 \
--replication-factor 1 \
--partitions 4 \
--topic test006
еңЁжҺ§еҲ¶еҸ°ж¶Ҳиҙ№test006зҡ„ж¶ҲжҒҜпјҢеҸӮиҖғе‘Ҫд»Өпјҡ
./kafka-console-consumer.sh \
--bootstrap-server 127.0.0.1:9092 \
--topic test006
жӯӨж—¶еҰӮжһңиҜҘtopicжңүж¶ҲжҒҜиҝӣжқҘпјҢе°ұдјҡеңЁжҺ§еҲ¶еҸ°иҫ“еҮәпјӣ
жҺҘдёӢжқҘејҖе§Ӣзј–з Ғпјӣ
еҲӣе»әе·ҘзЁӢ
з”Ёmavenе‘Ҫд»ӨеҲӣе»әflinkе·ҘзЁӢпјҡ
mvn \
archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.9.2
ж №жҚ®жҸҗзӨәпјҢgroupidиҫ“е…Ҙ<font color="blue">com.bolingcavalry</font>пјҢartifactidиҫ“е…Ҙ<font color="blue">flinksinkdemo</font>пјҢеҚіеҸҜеҲӣе»әдёҖдёӘmavenе·ҘзЁӢпјӣ
еңЁpom.xmlдёӯеўһеҠ kafkaдҫқиө–еә“пјҡ
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.9.0</version>
</dependency>
е·ҘзЁӢеҲӣе»әе®ҢжҲҗпјҢејҖе§Ӣзј–еҶҷflinkд»»еҠЎзҡ„д»Јз Ғпјӣ
еҸ‘йҖҒеӯ—з¬ҰдёІж¶ҲжҒҜзҡ„sink
е…Ҳе°қиҜ•еҸ‘йҖҒеӯ—з¬ҰдёІзұ»еһӢзҡ„ж¶ҲжҒҜпјҡ
еҲӣе»әKafkaSerializationSchemaжҺҘеҸЈзҡ„е®һзҺ°зұ»пјҢеҗҺйқўиҝҷдёӘзұ»иҰҒдҪңдёәеҲӣе»әsinkеҜ№иұЎзҡ„еҸӮж•°дҪҝз”Ёпјҡ
package com.bolingcavalry.addsink;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.nio.charset.StandardCharsets;
public class ProducerStringSerializationSchema implements KafkaSerializationSchema<String> {
private String topic;
public ProducerStringSerializationSchema(String topic) {
super();
this.topic = topic;
}
@Override
public ProducerRecord<byte[], byte[]> serialize(String element, Long timestamp) {
return new ProducerRecord<byte[], byte[]>(topic, element.getBytes(StandardCharsets.UTF_8));
}
}еҲӣе»әд»»еҠЎзұ»KafkaStrSinkпјҢиҜ·жіЁж„ҸFlinkKafkaProducerеҜ№иұЎзҡ„еҸӮж•°пјҢFlinkKafkaProducer.Semantic.EXACTLY_ONCEиЎЁзӨәдёҘж јдёҖж¬Ўпјҡ
package com.bolingcavalry.addsink;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class KafkaStrSink {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//并иЎҢеәҰдёә1
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.50.43:9092");
String topic = "test006";
FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<>(topic,
new ProducerStringSerializationSchema(topic),
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
//еҲӣе»әдёҖдёӘListпјҢйҮҢйқўжңүдёӨдёӘTuple2е…ғзҙ
List<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
list.add("ddd");
list.add("eee");
list.add("fff");
list.add("aaa");
//з»ҹи®ЎжҜҸдёӘеҚ•иҜҚзҡ„ж•°йҮҸ
env.fromCollection(list)
.addSink(producer)
.setParallelism(4);
env.execute("sink demo : kafka str");
}
}дҪҝз”Ёmvnе‘Ҫд»Өзј–иҜ‘жһ„е»әпјҢеңЁtargetзӣ®еҪ•еҫ—еҲ°ж–Ү件<font color="blue">flinksinkdemo-1.0-SNAPSHOT.jar</font>пјӣ
еңЁflinkзҡ„webйЎөйқўжҸҗдәӨflinksinkdemo-1.0-SNAPSHOT.jarпјҢ并еҲ¶е®ҡжү§иЎҢзұ»пјҢеҰӮдёӢеӣҫпјҡ 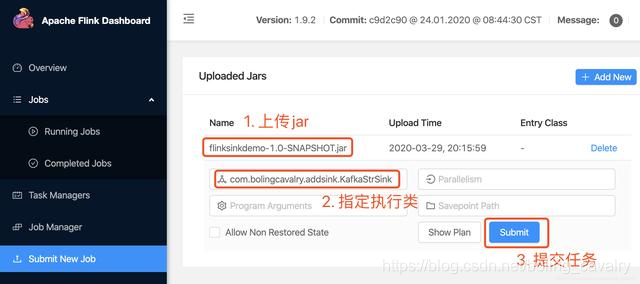
жҸҗдәӨжҲҗеҠҹеҗҺпјҢеҰӮжһңflinkжңүеӣӣдёӘеҸҜз”ЁslotпјҢд»»еҠЎдјҡз«ӢеҚіжү§иЎҢпјҢдјҡеңЁж¶Ҳиҙ№kafakж¶ҲжҒҜзҡ„з»Ҳз«Ҝ收еҲ°ж¶ҲжҒҜпјҢеҰӮдёӢеӣҫпјҡ 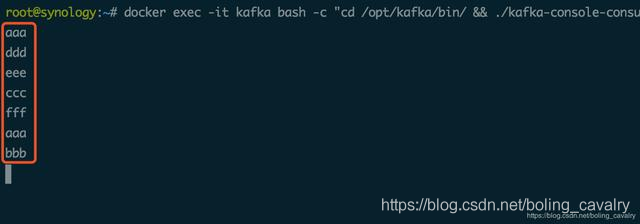
д»»еҠЎжү§иЎҢжғ…еҶөеҰӮдёӢеӣҫпјҡ 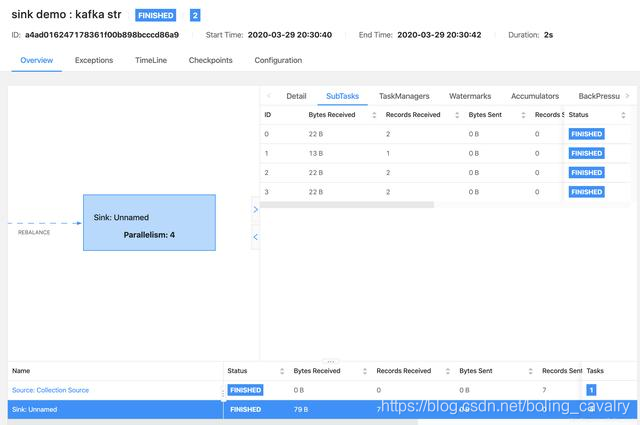
еҸ‘йҖҒеҜ№иұЎж¶ҲжҒҜзҡ„sink
еҶҚжқҘе°қиҜ•еҰӮдҪ•еҸ‘йҖҒеҜ№иұЎзұ»еһӢзҡ„ж¶ҲжҒҜпјҢиҝҷйҮҢзҡ„еҜ№иұЎйҖүжӢ©еёёз”Ёзҡ„Tuple2еҜ№иұЎпјҡ
еҲӣе»әKafkaSerializationSchemaжҺҘеҸЈзҡ„е®һзҺ°зұ»пјҢиҜҘзұ»еҗҺйқўиҰҒз”ЁдҪңsinkеҜ№иұЎзҡ„е…ҘеҸӮпјҢиҜ·жіЁж„Ҹд»Јз ҒдёӯжҚ•иҺ·ејӮеёёзҡ„йӮЈж®өжіЁйҮҠпјҡ<font color="red">з”ҹдә§зҺҜеўғж…Һз”ЁprintStackTrace()!!!</font>
package com.bolingcavalry.addsink;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.core.JsonProcessingException;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.kafka.clients.producer.ProducerRecord;
import javax.annotation.Nullable;
public class ObjSerializationSchema implements KafkaSerializationSchema<Tuple2<String, Integer>> {
private String topic;
private ObjectMapper mapper;
public ObjSerializationSchema(String topic) {
super();
this.topic = topic;
}
@Override
public ProducerRecord<byte[], byte[]> serialize(Tuple2<String, Integer> stringIntegerTuple2, @Nullable Long timestamp) {
byte[] b = null;
if (mapper == null) {
mapper = new ObjectMapper();
}
try {
b= mapper.writeValueAsBytes(stringIntegerTuple2);
} catch (JsonProcessingException e) {
// жіЁж„ҸпјҢеңЁз”ҹдә§зҺҜеўғиҝҷжҳҜдёӘйқһеёёеҚұйҷ©зҡ„ж“ҚдҪңпјҢ
// иҝҮеӨҡзҡ„й”ҷиҜҜжү“еҚ°дјҡдёҘйҮҚеҪұе“Қзі»з»ҹжҖ§иғҪпјҢиҜ·ж №жҚ®з”ҹдә§зҺҜеўғжғ…еҶөеҒҡи°ғж•ҙ
e.printStackTrace();
}
return new ProducerRecord<byte[], byte[]>(topic, b);
}
}еҲӣе»әflinkд»»еҠЎзұ»пјҡ
package com.bolingcavalry.addsink;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class KafkaObjSink {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//并иЎҢеәҰдёә1
env.setParallelism(1);
Properties properties = new Properties();
//kafkaзҡ„brokerең°еқҖ
properties.setProperty("bootstrap.servers", "192.168.50.43:9092");
String topic = "test006";
FlinkKafkaProducer<Tuple2<String, Integer>> producer = new FlinkKafkaProducer<>(topic,
new ObjSerializationSchema(topic),
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
//еҲӣе»әдёҖдёӘListпјҢйҮҢйқўжңүдёӨдёӘTuple2е…ғзҙ
List<Tuple2<String, Integer>> list = new ArrayList<>();
list.add(new Tuple2("aaa", 1));
list.add(new Tuple2("bbb", 1));
list.add(new Tuple2("ccc", 1));
list.add(new Tuple2("ddd", 1));
list.add(new Tuple2("eee", 1));
list.add(new Tuple2("fff", 1));
list.add(new Tuple2("aaa", 1));
//з»ҹи®ЎжҜҸдёӘеҚ•иҜҚзҡ„ж•°йҮҸ
env.fromCollection(list)
.keyBy(0)
.sum(1)
.addSink(producer)
.setParallelism(4);
env.execute("sink demo : kafka obj");
}
}еғҸеүҚдёҖдёӘд»»еҠЎйӮЈж ·зј–иҜ‘жһ„е»әпјҢжҠҠjarжҸҗдәӨеҲ°flinkпјҢ并жҢҮе®ҡжү§иЎҢзұ»жҳҜ<font color="blue">com.bolingcavalry.addsink.KafkaObjSink</font>пјӣ
ж¶Ҳиҙ№kafkaж¶ҲжҒҜзҡ„жҺ§еҲ¶еҸ°иҫ“еҮәеҰӮдёӢпјҡ 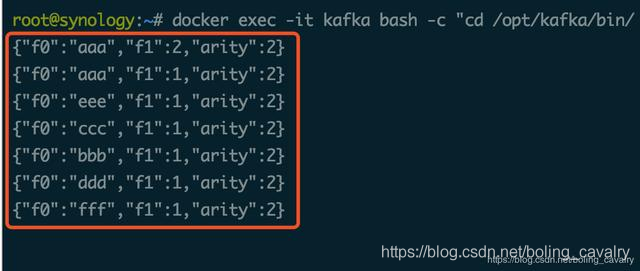
еңЁwebйЎөйқўеҸҜи§Ғжү§иЎҢжғ…еҶөеҰӮдёӢпјҡ  иҮіжӯӨпјҢflinkе°Ҷи®Ўз®—з»“жһңдҪңдёәkafkaж¶ҲжҒҜеҸ‘йҖҒеҮәеҺ»зҡ„е®һжҲҳе°ұе®ҢжҲҗдәҶпјҢеёҢжңӣиғҪз»ҷжӮЁжҸҗдҫӣеҸӮиҖғпјҢжҺҘдёӢжқҘзҡ„з« иҠӮпјҢжҲ‘们дјҡ继з»ӯдҪ“йӘҢе®ҳж–№жҸҗдҫӣзҡ„sinkиғҪеҠӣпјӣ
иҮіжӯӨпјҢflinkе°Ҷи®Ўз®—з»“жһңдҪңдёәkafkaж¶ҲжҒҜеҸ‘йҖҒеҮәеҺ»зҡ„е®һжҲҳе°ұе®ҢжҲҗдәҶпјҢеёҢжңӣиғҪз»ҷжӮЁжҸҗдҫӣеҸӮиҖғпјҢжҺҘдёӢжқҘзҡ„з« иҠӮпјҢжҲ‘们дјҡ继з»ӯдҪ“йӘҢе®ҳж–№жҸҗдҫӣзҡ„sinkиғҪеҠӣпјӣ
е…ідәҺеҰӮдҪ•иҝӣиЎҢж•°жҚ®sinkеҲ°kafkaзҡ„ж“ҚдҪңе°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





