FlinkдёӯCoProcessFunctionеҰӮдҪ•дҪҝз”Ё
д»ҠеӨ©е°ұи·ҹеӨ§е®¶иҒҠиҒҠжңүе…іFlinkдёӯCoProcessFunctionеҰӮдҪ•дҪҝз”ЁпјҢеҸҜиғҪеҫҲеӨҡдәәйғҪдёҚеӨӘдәҶи§ЈпјҢдёәдәҶи®©еӨ§е®¶жӣҙеҠ дәҶи§ЈпјҢе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеёҢжңӣеӨ§е®¶ж №жҚ®иҝҷзҜҮж–Үз« еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
жң¬ж–ҮжҳҜгҖҠFlinkеӨ„зҗҶеҮҪж•°е®һжҲҳгҖӢзі»еҲ—зҡ„第дә”зҜҮпјҢеӯҰд№ еҶ…е®№жҳҜеҰӮдҪ•еҗҢж—¶еӨ„зҗҶдёӨдёӘж•°жҚ®жәҗзҡ„ж•°жҚ®пјӣ
иҜ•жғіеңЁйқўеҜ№дёӨдёӘиҫ“е…ҘжөҒж—¶пјҢеҰӮжһңиҝҷдёӨдёӘжөҒзҡ„ж•°жҚ®д№Ӣй—ҙжңүдёҡеҠЎе…ізі»пјҢиҜҘеҰӮдҪ•зј–з Ғе®һзҺ°е‘ўпјҢдҫӢеҰӮдёӢеӣҫдёӯзҡ„ж“ҚдҪңпјҢеҗҢж—¶зӣ‘еҗ¬<font color="blue">9998</font>е’Ң<font color="blue">9999</font>з«ҜеҸЈпјҢе°Ҷ收еҲ°зҡ„иҫ“еҮәеҲҶеҲ«еӨ„зҗҶеҗҺпјҢеҶҚз”ұеҗҢдёҖдёӘsinkеӨ„зҗҶ(жү“еҚ°)пјҡ 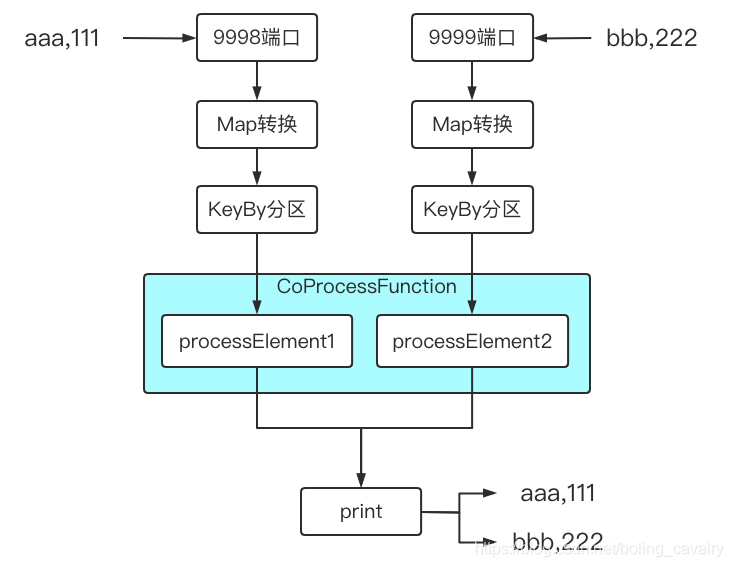
Flinkж”ҜжҢҒзҡ„ж–№ејҸжҳҜжү©еұ•CoProcessFunctionжқҘеӨ„зҗҶпјҢдёәдәҶжӣҙжё…жҘҡи®ӨиҜҶпјҢжҲ‘们жҠҠ<font color="blue">KeyedProcessFunction</font>е’Ң<font color="blue">CoProcessFunction</font>зҡ„зұ»еӣҫж‘ҶеңЁдёҖиө·зңӢпјҢеҰӮдёӢжүҖзӨәпјҡ 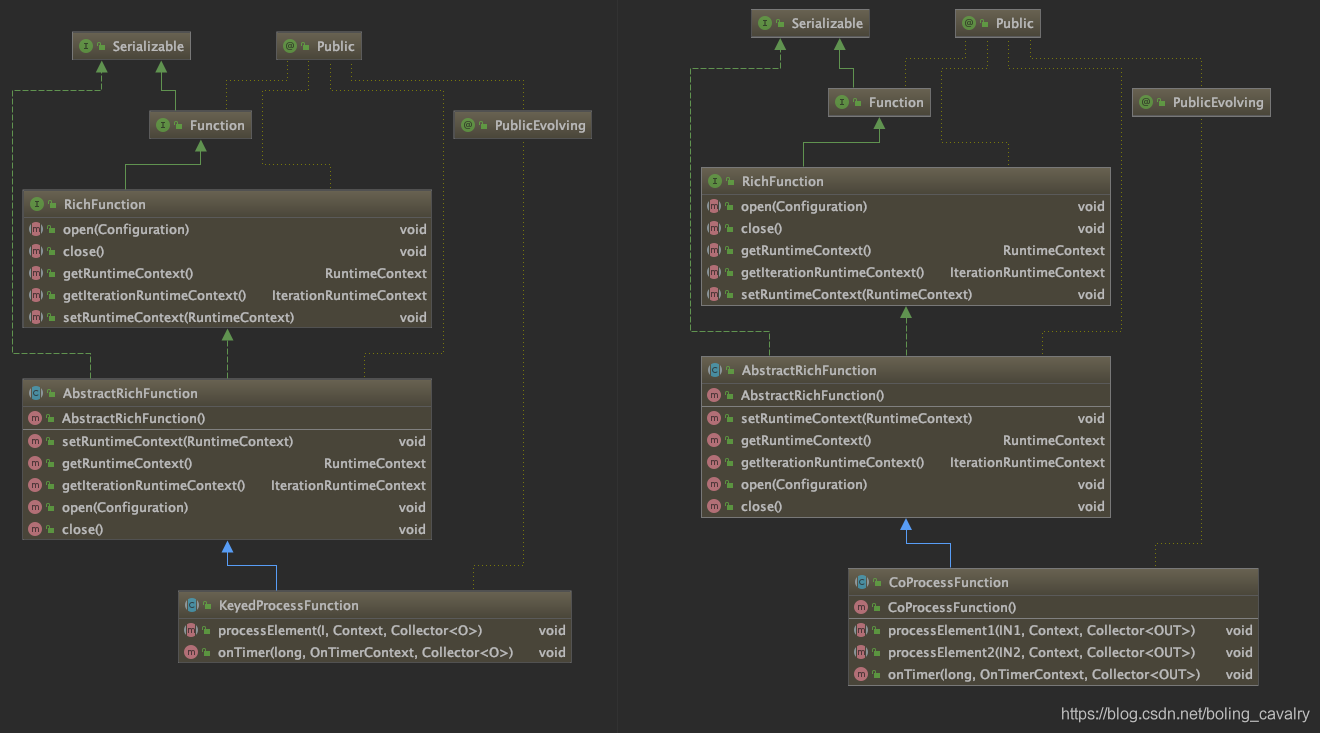
д»ҺдёҠеӣҫеҸҜи§ҒпјҢCoProcessFunctionе’ҢKeyedProcessFunctionзҡ„继жүҝе…ізі»дёҖж ·пјҢеҸҰеӨ–CoProcessFunctionиҮӘиә«д№ҹеҫҲз®ҖеҚ•пјҢеңЁprocessElement1е’ҢprocessElement2дёӯеҲҶеҲ«еӨ„зҗҶдёӨдёӘдёҠжёёжөҒе…Ҙзҡ„ж•°жҚ®еҚіеҸҜпјҢ并且д№ҹж”ҜжҢҒе®ҡж—¶еҷЁи®ҫзҪ®пјӣ
зј–з Ғе®һжҲҳ
жҺҘдёӢжқҘе’ұ们ејҖеҸ‘дёҖдёӘеә”з”ЁжқҘдҪ“йӘҢ<font color="blue">CoProcessFunction</font>пјҢеҠҹиғҪйқһеёёз®ҖеҚ•пјҢжҸҸиҝ°еҰӮдёӢпјҡ
е»әдёӨдёӘж•°жҚ®жәҗпјҢж•°жҚ®еҲҶеҲ«жқҘиҮӘжң¬ең°<font color="red">9998</font>е’Ң<font color="red">9999</font>з«ҜеҸЈпјӣ
жҜҸдёӘз«ҜеҸЈж”¶еҲ°зұ»дјј<font color="blue">aaa,123</font>иҝҷж ·зҡ„ж•°жҚ®пјҢиҪ¬жҲҗTuple2е®һдҫӢпјҢf0жҳҜ<font color="blue">aaa</font>пјҢf1жҳҜ<font color="blue">123</font>пјӣ
еңЁCoProcessFunctionзҡ„е®һзҺ°зұ»дёӯпјҢеҜ№жҜҸдёӘж•°жҚ®жәҗзҡ„ж•°жҚ®йғҪжү“ж—Ҙеҝ—пјҢ然еҗҺе…ЁйғЁдј еҲ°дёӢжёёз®—еӯҗпјӣ
дёӢжёёж“ҚдҪңжҳҜжү“еҚ°пјҢеӣ жӯӨ<font color="red">9998</font>е’Ң<font color="red">9999</font>з«ҜеҸЈж”¶еҲ°зҡ„жүҖжңүж•°жҚ®йғҪдјҡеңЁжҺ§еҲ¶еҸ°жү“еҚ°еҮәжқҘпјӣ
ж•ҙдёӘdemoзҡ„еҠҹиғҪеҰӮдёӢеӣҫжүҖзӨәпјҡ 
жәҗз ҒдёӢиҪҪ
еҰӮжһңжӮЁдёҚжғіеҶҷд»Јз ҒпјҢж•ҙдёӘзі»еҲ—зҡ„жәҗз ҒеҸҜеңЁGitHubдёӢиҪҪеҲ°пјҢең°еқҖе’Ңй“ҫжҺҘдҝЎжҒҜеҰӮдёӢиЎЁжүҖзӨә(https://github.com/zq2599/blog_demos)пјҡ
| еҗҚз§° | й“ҫжҺҘ | еӨҮжіЁ |
|---|
| йЎ№зӣ®дё»йЎө | https://github.com/zq2599/blog_demos | иҜҘйЎ№зӣ®еңЁGitHubдёҠзҡ„дё»йЎө |
| gitд»“еә“ең°еқҖ(https) | https://github.com/zq2599/blog_demos.git | иҜҘйЎ№зӣ®жәҗз Ғзҡ„д»“еә“ең°еқҖпјҢhttpsеҚҸи®® |
| gitд»“еә“ең°еқҖ(ssh) | git@github.com:zq2599/blog_demos.git | иҜҘйЎ№зӣ®жәҗз Ғзҡ„д»“еә“ең°еқҖпјҢsshеҚҸи®® |
иҝҷдёӘgitйЎ№зӣ®дёӯжңүеӨҡдёӘж–Ү件еӨ№пјҢжң¬з« зҡ„еә”з”ЁеңЁ<font color="blue">flinkstudy</font>ж–Ү件еӨ№дёӢпјҢеҰӮдёӢеӣҫзәўжЎҶжүҖзӨәпјҡ 
Mapз®—еӯҗ
еҒҡдёҖдёӘmapз®—еӯҗпјҢз”ЁжқҘе°Ҷеӯ—з¬ҰдёІ<font color="blue">aaa,123</font>иҪ¬жҲҗTuple2е®һдҫӢпјҢf0жҳҜ<font color="red">aaa</font>пјҢf1жҳҜ<font color="red">123</font>пјӣ
з®—еӯҗеҗҚдёә<font color="blue">WordCountMap.java</font>пјҡ
package com.bolingcavalry.coprocessfunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.StringUtils;
public class WordCountMap implements MapFunction<String, Tuple2<String, Integer>> {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
if(StringUtils.isNullOrWhitespaceOnly(s)) {
System.out.println("invalid line");
return null;
}
String[] array = s.split(",");
if(null==array || array.length<2) {
System.out.println("invalid line for array");
return null;
}
return new Tuple2<>(array[0], Integer.valueOf(array[1]));
}
}дҫҝдәҺжү©еұ•зҡ„жҠҪиұЎзұ»
ејҖеҸ‘дёҖдёӘжҠҪиұЎзұ»пјҢе°ҶеүҚйқўеӣҫдёӯжҸҗеҲ°зҡ„зӣ‘еҗ¬з«ҜеҸЈгҖҒmapеӨ„зҗҶгҖҒkeybyеӨ„зҗҶгҖҒжү“еҚ°йғҪеҒҡеҲ°иҝҷдёӘжҠҪиұЎзұ»дёӯпјҢдҪҶжҳҜCoProcessFunctionзҡ„йҖ»иҫ‘еҚҙдёҚж”ҫеңЁиҝҷйҮҢпјҢиҖҢжҳҜдәӨз»ҷеӯҗзұ»жқҘе®һзҺ°пјҢиҝҷж ·еҰӮжһңжҲ‘们жғіиҝӣдёҖжӯҘе®һи·өе’Ңжү©еұ•CoProcessFunctionзҡ„иғҪеҠӣпјҢеҸӘиҰҒеңЁеӯҗзұ»дёӯдё“жіЁеҒҡеҘҪCoProcessFunctionзӣёе…іејҖеҸ‘еҚіеҸҜпјҢеҰӮдёӢеӣҫпјҢзәўиүІйғЁеҲҶдәӨз»ҷеӯҗзұ»е®һзҺ°пјҢе…¶дҪҷзҡ„йғҪжҳҜжҠҪиұЎзұ»е®ҢжҲҗзҡ„пјҡ 
жҠҪиұЎзұ»AbstractCoProcessFunctionExecutor.javaпјҢжәҗз ҒеҰӮдёӢпјҢзЁҚеҗҺдјҡиҜҙжҳҺеҮ дёӘе…ій”®зӮ№пјҡ
package com.bolingcavalry.coprocessfunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
/**
* @author will
* @email zq2599@gmail.com
* @date 2020-11-09 17:33
* @description дёІиө·ж•ҙдёӘйҖ»иҫ‘зҡ„жү§иЎҢзұ»пјҢз”ЁдәҺдҪ“йӘҢCoProcessFunction
*/
public abstract class AbstractCoProcessFunctionExecutor {
/**
* иҝ”еӣһCoProcessFunctionзҡ„е®һдҫӢпјҢиҝҷдёӘж–№жі•з•ҷз»ҷеӯҗзұ»е®һзҺ°
* @return
*/
protected abstract CoProcessFunction<
Tuple2<String, Integer>,
Tuple2<String, Integer>,
Tuple2<String, Integer>> getCoProcessFunctionInstance();
/**
* зӣ‘еҗ¬ж №жҚ®жҢҮе®ҡзҡ„з«ҜеҸЈпјҢ
* еҫ—еҲ°зҡ„ж•°жҚ®е…ҲйҖҡиҝҮmapиҪ¬дёәTuple2е®һдҫӢпјҢ
* з»ҷе…ғзҙ еҠ е…Ҙж—¶й—ҙжҲіпјҢ
* еҶҚжҢүf0еӯ—ж®өеҲҶеҢәпјҢ
* е°ҶеҲҶеҢәеҗҺзҡ„KeyedStreamиҝ”еӣһ
* @param port
* @return
*/
protected KeyedStream<Tuple2<String, Integer>, Tuple> buildStreamFromSocket(StreamExecutionEnvironment env, int port) {
return env
// зӣ‘еҗ¬з«ҜеҸЈ
.socketTextStream("localhost", port)
// еҫ—еҲ°зҡ„еӯ—з¬ҰдёІ"aaa,3"иҪ¬жҲҗTuple2е®һдҫӢпјҢf0="aaa"пјҢf1=3
.map(new WordCountMap())
// е°ҶеҚ•иҜҚдҪңдёәkeyеҲҶеҢә
.keyBy(0);
}
/**
* еҰӮжһңеӯҗзұ»жңүдҫ§иҫ“еҮәйңҖиҰҒеӨ„зҗҶпјҢиҜ·йҮҚеҶҷжӯӨж–№жі•пјҢдјҡеңЁдё»жөҒзЁӢжү§иЎҢе®ҢжҜ•еҗҺиў«и°ғз”Ё
*/
protected void doSideOutput(SingleOutputStreamOperator<Tuple2<String, Integer>> mainDataStream) {
}
/**
* жү§иЎҢдёҡеҠЎзҡ„ж–№жі•
* @throws Exception
*/
public void execute() throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 并иЎҢеәҰ1
env.setParallelism(1);
// зӣ‘еҗ¬9998з«ҜеҸЈзҡ„иҫ“е…Ҙ
KeyedStream<Tuple2<String, Integer>, Tuple> stream1 = buildStreamFromSocket(env, 9998);
// зӣ‘еҗ¬9999з«ҜеҸЈзҡ„иҫ“е…Ҙ
KeyedStream<Tuple2<String, Integer>, Tuple> stream2 = buildStreamFromSocket(env, 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> mainDataStream = stream1
// дёӨдёӘжөҒиҝһжҺҘ
.connect(stream2)
// жү§иЎҢдҪҺйҳ¶еӨ„зҗҶеҮҪж•°пјҢе…·дҪ“еӨ„зҗҶйҖ»иҫ‘еңЁеӯҗзұ»дёӯе®һзҺ°
.process(getCoProcessFunctionInstance());
// е°ҶдҪҺйҳ¶еӨ„зҗҶеҮҪж•°иҫ“еҮәзҡ„е…ғзҙ е…ЁйғЁжү“еҚ°еҮәжқҘ
mainDataStream.print();
// дҫ§иҫ“еҮәзӣёе…ійҖ»иҫ‘пјҢеӯҗзұ»жңүдҫ§иҫ“еҮәйңҖжұӮж—¶йҮҚеҶҷжӯӨж–№жі•
doSideOutput(mainDataStream);
// жү§иЎҢ
env.execute("ProcessFunction demo : CoProcessFunction");
}
}е…ій”®зӮ№д№ӢдёҖпјҡдёҖе…ұжңүдёӨдёӘж•°жҚ®жәҗпјҢжҜҸдёӘжәҗзҡ„еӨ„зҗҶйҖ»иҫ‘йғҪе°ҒиЈ…еҲ°<font color="blue">buildStreamFromSocket</font>ж–№жі•дёӯпјӣ
е…ій”®зӮ№д№ӢдәҢпјҡ<font color="blue">stream1.connect(stream2)</font>е°ҶдёӨдёӘжөҒиҝһжҺҘиө·жқҘпјӣ
е…ій”®зӮ№д№Ӣдёүпјҡ<font color="blue">process</font>жҺҘ收CoProcessFunctionе®һдҫӢпјҢеҗҲ并еҗҺзҡ„жөҒзҡ„еӨ„зҗҶйҖ»иҫ‘е°ұеңЁиҝҷйҮҢйқўпјӣ
е…ій”®зӮ№д№Ӣеӣӣпјҡ<font color="blue">getCoProcessFunctionInstance</font>жҳҜжҠҪиұЎж–№жі•пјҢиҝ”еӣһ<font color="blue">CoProcessFunction</font>е®һдҫӢпјҢдәӨз»ҷеӯҗзұ»е®һзҺ°пјҢжүҖд»ҘCoProcessFunctionдёӯеҒҡд»Җд№ҲдәӢжғ…е®Ңе…Ёз”ұеӯҗзұ»еҶіе®ҡпјӣ
е…ій”®зӮ№д№Ӣдә”пјҡdoSideOutputж–№жі•дёӯе•Ҙд№ҹжІЎеҒҡпјҢдҪҶжҳҜеңЁдё»жөҒзЁӢд»Јз Ғзҡ„жң«е°ҫдјҡиў«и°ғз”ЁпјҢеҰӮжһңеӯҗзұ»жңүдҫ§иҫ“еҮә(SideOutput)зҡ„йңҖжұӮпјҢйҮҚеҶҷжӯӨж–№жі•еҚіеҸҜпјҢжӯӨж–№жі•зҡ„е…ҘеҸӮжҳҜеӨ„зҗҶиҝҮзҡ„ж•°жҚ®йӣҶпјҢеҸҜд»Ҙд»ҺиҝҷйҮҢеҸ–еҫ—дҫ§иҫ“еҮәпјӣ
еӯҗзұ»еҶіе®ҡCoProcessFunctionзҡ„еҠҹиғҪ
еӯҗзұ»<font color="blue">CollectEveryOne.java</font>еҰӮдёӢжүҖзӨәпјҢйҖ»иҫ‘еҫҲз®ҖеҚ•пјҢе°ҶжҜҸдёӘжәҗзҡ„дёҠжёёж•°жҚ®зӣҙжҺҘиҫ“еҮәеҲ°дёӢжёёз®—еӯҗпјҡ
package com.bolingcavalry.coprocessfunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.util.Collector;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class CollectEveryOne extends AbstractCoProcessFunctionExecutor {
private static final Logger logger = LoggerFactory.getLogger(CollectEveryOne.class);
@Override
protected CoProcessFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple2<String, Integer>> getCoProcessFunctionInstance() {
return new CoProcessFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple2<String, Integer>>() {
@Override
public void processElement1(Tuple2<String, Integer> value, Context ctx, Collector<Tuple2<String, Integer>> out) {
logger.info("еӨ„зҗҶ1еҸ·жөҒзҡ„е…ғзҙ пјҡ{},", value);
out.collect(value);
}
@Override
public void processElement2(Tuple2<String, Integer> value, Context ctx, Collector<Tuple2<String, Integer>> out) {
logger.info("еӨ„зҗҶ2еҸ·жөҒзҡ„е…ғзҙ пјҡ{}", value);
out.collect(value);
}
};
}
public static void main(String[] args) throws Exception {
new CollectEveryOne().execute();
}
}дёҠиҝ°д»Јз ҒдёӯпјҢCoProcessFunctionеҗҺйқўзҡ„жіӣеһӢе®ҡд№үеҫҲй•ҝпјҡ<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple2<String, Integer>> пјҢдёҖе…ұдёүдёӘTuple2пјҢеҲҶеҲ«д»ЈиЎЁдёҖеҸ·ж•°жҚ®жәҗиҫ“е…ҘгҖҒдәҢеҸ·ж•°жҚ®жәҗиҫ“е…ҘгҖҒдёӢжёёиҫ“еҮәзҡ„зұ»еһӢпјӣ
йӘҢиҜҒ
еҲҶеҲ«ејҖеҗҜжң¬жңәзҡ„<font color="blue">9998</font>е’Ң<font color="blue">9999</font>з«ҜеҸЈпјҢжҲ‘иҝҷйҮҢжҳҜMacBookпјҢжү§иЎҢ<font color="blue">nc -l 9998</font>е’Ң<font color="blue">nc -l 9999</font>
еҗҜеҠЁFlinkеә”з”ЁпјҢеҰӮжһңжӮЁе’ҢжҲ‘дёҖж ·жҳҜMacз”өи„‘пјҢзӣҙжҺҘиҝҗиЎҢ<font color="blue">CollectEveryOne.main</font>ж–№жі•еҚіеҸҜпјҲеҰӮжһңжҳҜwindowsз”өи„‘пјҢжҲ‘иҝҷжІЎиҜ•иҝҮпјҢдёҚиҝҮеҒҡжҲҗjarеңЁзәҝйғЁзҪІд№ҹжҳҜеҸҜд»Ҙзҡ„пјүпјӣ
еңЁзӣ‘еҗ¬9998е’Ң9999з«ҜеҸЈзҡ„жҺ§еҲ¶еҸ°еҲҶеҲ«иҫ“е…Ҙ<font color="blue">aaa,111</font>е’Ң<font color="blue">bbb,222</font>
д»ҘдёӢжҳҜflinkжҺ§еҲ¶еҸ°иҫ“еҮәзҡ„еҶ…е®№пјҢеҸҜи§ҒprocessElement1е’ҢprocessElement1ж–№жі•зҡ„ж—Ҙеҝ—д»Јз Ғе·Із»Ҹжү§иЎҢпјҢ并且printж–№жі•дҪңдёәжңҖдёӢжёёпјҢе°ҶдёӨдёӘж•°жҚ®жәҗзҡ„ж•°жҚ®йғҪжү“еҚ°еҮәжқҘдәҶпјҢз¬ҰеҗҲйў„жңҹпјҡ
12:45:38,774 INFO CollectEveryOne - еӨ„зҗҶ1еҸ·жөҒзҡ„е…ғзҙ пјҡ(aaa,111),
(aaa,111)
12:45:43,816 INFO CollectEveryOne - еӨ„зҗҶ2еҸ·жөҒзҡ„е…ғзҙ пјҡ(bbb,222)
(bbb,222)
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们еҜ№FlinkдёӯCoProcessFunctionеҰӮдҪ•дҪҝз”ЁжңүиҝӣдёҖжӯҘзҡ„дәҶи§Јеҗ—пјҹеҰӮжһңиҝҳжғідәҶи§ЈжӣҙеӨҡзҹҘиҜҶжҲ–иҖ…зӣёе…іеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеӨ§е®¶зҡ„ж”ҜжҢҒгҖӮ





