小编给大家分享一下Flink 1.11与Hive批流一体数仓的示例分析,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
为什么要做 Flink 和 Hive 集成的功能呢?最早的初衷是我们希望挖掘 Flink 在批处理方面的能力。众所周知,Flink 在流计算方面已经是成功的引擎了,使用的用户也非常多。在 Flink 的设计理念当中,批计算是流处理中的一个特例。也就意味着,如果 Flink 在流计算方面做好,其实它的架构也能很好的支持批计算的场景。在批计算的场景中,SQL 是一个很重要的切入点。因为做数据分析的同学,他们更习惯使用SQL 进行开发,而不是去写 DataStream 或者 DataSet 这样的程序。
Hadoop 生态圈的 SQL 引擎,Hive 是一个事实上的标准。大部分的用户环境中都会使用到了 Hive 的一些功能,来搭建数仓。一些比较新的 SQL 的引擎,例如 Spark SQL、Impala ,它们其实都提供了与 Hive 集成的能力。为了方便的能够对接上目前用户已有的使用场景,所以我们认为对 Flink 而言,对接 Hive 也是不可缺少的功能。
因此,我们在 Flink 1.9 当中,就开始提供了与 Hive 集成的功能。当然在 1.9 版本里面,这个功能是作为试用版发布的。到了 Flink 1.10 版本,与 Hive 集成的功能就达到了生产可用。同时在 Flink 1.10 发布的时候,我们用 10TB 的 TPC-DS 测试集,对 Flink 和 Hive on MapReduce 进行了对比,对比结果如下:
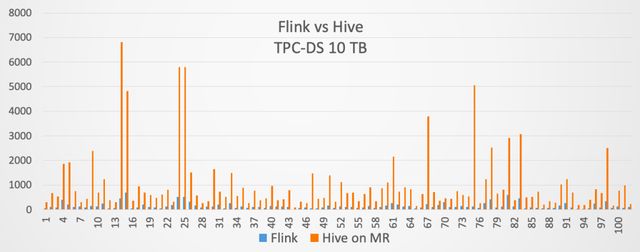
蓝色的方框表示 Flink 用的时间,桔红色的方框表示 Hive on MapReduce 用的时间。最终的结果是 Flink 对于 Hive on MapReduce 大概提升了 7 倍左右的性能。所以验证了 Flink SQL 可以很好的支持批计算的场景。
接下来介绍下 Flink 对接 Hive 的设计架构。对接 Hive 的时候需要几个层面,分别是:
能够访问 Hive 的元数据;
读写 Hive 表数据;
Production Ready ;
1. 访问 Hive 元数据
使用过 Hive 的同学应该都知道,Hive 的元数据是通过 Hive Metastore 来管理的。所以意味着 Flink 需要打通与 Hive Metastore 的通信。为了更好的访问 Hive 元数据,在 Flink 这边是提出了一套全新设计的 Catalog API 。
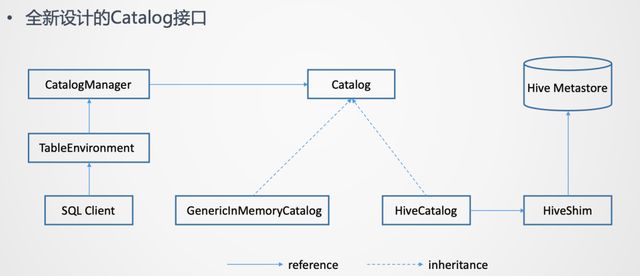
这个全新的接口是一个通用化的设计。它并不只是为了对接 Hive 元数据,理论上是它可以对接不同外部系统的元数据。
而且在一个 Flink Session 当中,是可以创建多个 Catalog ,每一个 Catalog 对应于一个外部系统。用户可以在 Flink Table API 或者如果使用的是 SQL Client 的话,可以在 Yaml 文件里指定定义哪些 Catalog 。然后在 SQL Client 创建 TableEnvironment 的时候,就会把这些 Catalog 加载起来。TableEnvironment 通过CatalogManager 来管理这些不同的 Catalog 的实例。这样 SQL Client 在后续的提交 SQL 语句的过程中,就可以使用这些 Catalog 去访问外部系统的元数据了。
上面这张图里列出了 2 个 Catalog 的实现。一个是 GenericlnMemoryCatalog ,把所有的元数据都保存在 Flink Client 端的内存里。它的行为是类似于 Catalog 接口出现之前 Flink 的行为。也就是所有的元数据的生命周期跟 SQL Client 的 Session 周期是一样的。当 Session 结束,在 Session 里面创建的元数据也就自动的丢失了。
另一个是对接 Hive 着重介绍的 HiveCatalog 。HiveCatalog 背后对接的是 Hive Metastore 的实例,要与 Hive Metastore 进行通信来做元数据的读写。为了支持多个版本的 Hive,不同版本的 Hive Metastore 的API可能存在不兼容。所以在 HiveCatalog 和 Hive Metastore 之间又加了一个 HiveShim ,通过 HiveShim 可以支持不同版本的 Hive 。
这里的 HiveCatalog 一方面可以让 Flink 去访问 Hive 自身有的元数据,另一方面它也为 Flink 提供了持久化元数据的能力。也就是 HiveCatalog 既可以用来存储 Hive的元数据,也可以存 Flink 使用的元数据。例如,在 Flink 中创建一张 Kafka 的表,那么这张表也是可以存到 HiveCatalog 里的。这样也就是为 Flink 提供了持久化元数据的能力。在没有 HiveCatalog 之前,是没有持久化能力的。
2. 读写 Hive 表数据
有了访问 Hive 元数据的能力后,另一个重要的方面是读写 Hive 表数据。Hive 的表是存在 Hadoop 的 file system 里的,这个 file system 是一个 HDFS ,也可能是其他文件系统。只要是实现了 Hadoop 的 file system 接口的,理论上都可以存储Hive 的表。
在 Flink 当中:
读数据时实现了 HiveTableSource
写数据时实现了 HiveTableSink
而且设计的一个原则是:希望尽可能去复用 Hive 原有的 Input/Output Format、SerDe 等,来读写 Hive 的数据。这样做的好处主要是 2 点,一个是复用可以减少开发的工作量。另一个是复用好处是尽可能与 Hive 保证写入数据的兼容性。目标是Flink 写入的数据,Hive 必须可以正常的读取。反之, Hive 写入的数据,Flink 也可以正常读取。
3. Production Ready
在 Flink 1.10 中,对接 Hive 的功能已经实现了 Production Ready 。实现 Production Ready 主要是认为在功能上已经完备了。具体实现的功能如下:

下面将介绍下,在 Flink 1.11 版本中,对接 Hive 的一些新特性。
1. 简化的依赖管理
首先做的是简化使用 Hive connector 的依赖管理。Hive connector 的一个痛点是需要添加若干个 jar 包的依赖,而且使用的 Hive 版本的不同,所需添加的 jar 包就不同。例如下图:
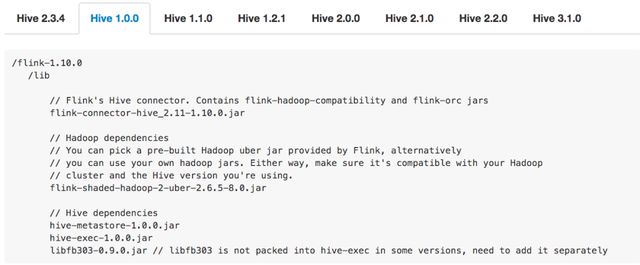
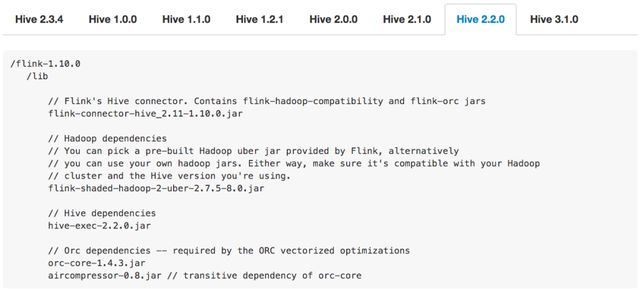
第一张图是使用的 Hive 1.0.0 版本需要添加的 jar 包。第二张图是用 Hive 2.2.0 版本需要添加的 jar 包。可以看出,不管是从 jar 包的个数、版本等,不同 Hive 版本添加的 jar 包是不一样的。所以如果不仔细去读文档的话,就很容易导致用户添加的依赖错误。一旦添加错误,例如添加少了或者版本不对,那么会报出来一些比较奇怪、难理解的错误。这也是用户在使用 Hive connector 时暴露最多的问题之一。
所以我们希望能简化依赖管理,给用户提供更好的体验。具体的做法是,在 Flink 1.11 版本中开始,会提供一些预先打好的 Hive 依赖包:

用户可以根据自己的 Hive 版本,选择对应的依赖包就可以了。
如果用户使用的 Hive 并不是开源版本的 Hive ,用户还是可以使用 1.10 那种方式,去自己添加单个 jar 包。
2. Hive Dialect 的增强
在 Flink 1.10 就引入了 Hive Dialect ,但是很少有人使用,因为这个版本的 Hive Dialect 功能比较弱。仅仅的一个功能是:是否允许创建分区表的开关。就是如果设置了 Hive Dialect ,那就可以在 Flink SQL 中创建分区表。如果没设置,则不允许创建。
另一个关键的是它不提供 Hive 语法的兼容。如果设置了 Hive Dialect 并可以创建分区表,但是创建分区表的 DDL 并不是 Hive 的语法。
在 Flink 1.11 中着重对 Hive Dialect 的功能进行了增强。增强的目标是:希望用户在使用 Flink SQL Client 的时候,能够获得与使用 Hive CLI 或 Beeline 近似的使用体验。就是在使用 Flink SQL Client 中,可以去写一些 Hive 特定的一些语法。或者说用户在迁移至 Flink 的时候, Hive 的脚本可以完全不用修改。
为了实现上述目标,在 Flink 1.11 中做了如下改进:
给 Dialect 做了参数化,目前参数支持 default 和 hive 两种值。default 是Flink 自身的 Dialect ,hive 是 Hive 的 Dialect。
SQL Client 和 API 均可以使用。
可以灵活的做动态切换,切换是语句级别的。例如 Session 创建后,第一个语句想用 Flink 的 Dialect 来写,就设置成 default 。在执行了几行语句后,想用 Hive 的 Dialect 来写,就可以设置成 hive 。在切换时,就不需要重启 Session。
兼容 Hive 常用 DDL 以及基础的 DML。
提供与 Hive CLI 或 Beeline 近似的使用体验。
3. 开启 Hive Dialect
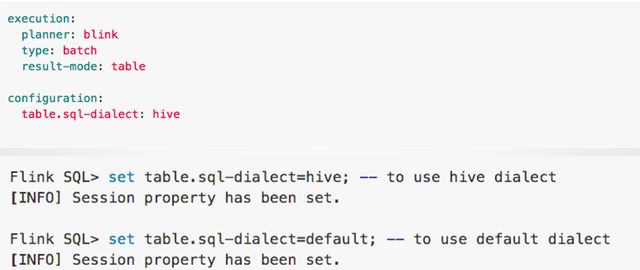
上图是在 SQL Client 中开启 Hive Dialect 的方法。在 SQL Client 中可以设置初始的 Dialect。可以在 Yaml 文件里设置,也可以在 SQL Client 起来后,进行动态的切换。
还可以通过 Flink Table API 的方式开启 Hive Dialect :

可以看到通过 TableEnvironment 去获取 Config 然后设置开启。
4. Hive Dialect 支持的语法
Hive Dialect 的语法主要是在 DDL 方面进行了增强。因为在 1.10 中通过 Flink SQL写 DDL 去操作 Hive 的元数据不是十分可用,所以要解决这个痛点,将主要精力集中在 DDL 方向了。
目前所支持的 DDL 如下:


5. 流式数据写入Hive
在 Flink 1.11 中还做了流式数据场景,以及跟 Hive 相结合的功能,通过 Flink 与Hive 的结合,来帮助 Hive 数仓进行实时化的改造。

流式数据写入 Hive 是借助 Streaming File Sink 实现的,它是完全 SQL 化的,不需要用户进行代码开发。流式数据写入 Hive 也支持分区和非分区表。Hive 数仓一般都是离线数据,用户对数据一致性要求比较高,所以支持 Exactly-Once 语义。流式数据写 Hive 大概有 5-10 分钟级别的延迟。如果希望延迟尽可能的低,那么产生的一个结果就是会生成更多的小文件。小文件对 HDFS 来说是不友好的,小文件多了以后,会影响 HDFS 的性能。这种情况下可以做一些小文的合并操作。
流式数据写入 Hive 需要有几个配置的地方:

对于分区表来说,要设置 Partition Commit Delay 的参数。这个参数的意义就是控制每个分区包含多长时间的数据,例如可设置成天、小时等。
Partition Commit Trigger 表示 Partition Commit 什么时候触发,在 1.11 版本中支持 Process-time 和 Partition-time 触发机制。
Partition Commit Policy 表示用什么方式提交分区。对于 Hive 来说,是需要将分区提交到 metastore, 这样分区才是可见的。metastore 策略只支持 Hive 表。还有一个是 success-file 方式,success-file 是告诉下游的作业分区的数据已经准备好了。用户也可以自定义,自己去实现一个提交方式。另外 Policy 可以指定多个的,例如可以同时指定 metastore 和 success-file。
下面看下流式数据写入Hive的实现原理:
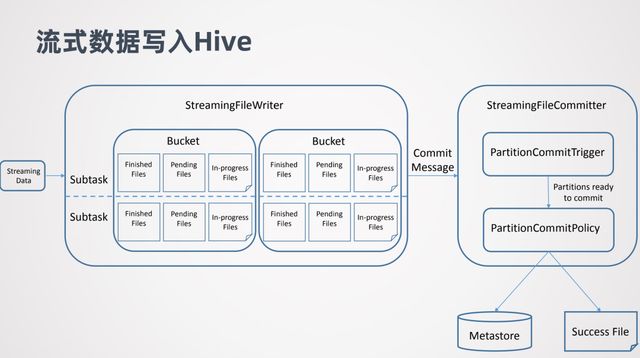
主要是两个部分,一个是 StreamingFileWriter ,借助它实现数据的写入,它会区分 Bucket,这里的 Buck 类似 Hive 的分区概念,每个 Subtask 都会往不同的 Bucket去写数据。每个 Subtask 写的 Bucket 同一个时间可能会维持 3 种文件,In-progress Files 表示正在写的文件,Pending Files 表示文件已经写完了但是还没有提交,Finished Files 表示文件已经写完并且也已经提交了。
另一个是 StreamingFileCommitter,在 StreamingFileWriter 后执行。它是用来提交分区的,所以对于非分区表就不需要它了。当 StreamingFileWriter 的一个分区数据准备好后,StreamingFileWriter 会向 StreamingFileCommitter 发一个 Commit Message,Commit Message 告诉 StreamingFileCommitter 那些数据已经准备好了的。然后进行提交的触发 Commit Trigger,以及提交方式 Commit Policy。
下面是一个具体的例子:

例子中创建了一个叫 hive_table 的分区表,它有两个分区 dt 和 hour。dt 代表的是日期的字符串,hour 代表小时的字符串。Commit trigger 设置的是 partition-time,Commit delay 设置的是1小时,Commit Policy 设置的是 metastore 和success-file。
6. 流式消费 Hive
在 Flink 1.10 中读 Hive 数据的方式是批的方式去读的,从 1.11 版本中,提供了流式的去读 Hive 数据。

通过不断的监控 Hive 数据表有没有新数据,有的话就进行增量数据的消费。
如果要针对某一张 Hive 表开启流式消费,可以在 table property 中开启,或者也可以使用在 1.11 中新加的 dynamic options 功能,可以查询的时候动态的指定 Hive 表是否需要打开流式读取。
流式消费 Hive 支持分区表和非分区表。对于非分区表会监控表目录下新文件添加,并增量读取。对于分区表通过监控分区目录和 Metastore 的方式确认是否有新分区添加,如果有新增分区,就会把新增分区数据读取出来。这里需要注意,读新增分区数据是一次性的。也就是新增加分区后,会把这个分区数据一次性都读出来,在这之后就不再监控这个分区的数据了。所以如果需要用 Flink 流式消费 Hive 的分区表,那应该保证分区在添加的时候它的数据是完整的。

流式消费 Hive 数据也需要额外的指定一些参数。首先要指定消费顺序,因为数据是增量读取,所以需要指定要用什么顺序消费数据,目前支持两种消费顺序 create-time 和 partition-time。
用户还可以指定消费起点,类似于消费 kafka 指定 offset 这样的功能,希望从哪个时间点的数据开始消费。Flink 去消费数据的时候,就会检查并只会读取这个时间点之后的数据。
最后还可以指定监控的间隔。因为目前监控新数据的添加都是要扫描文件系统的,可能你希望监控的不要太频繁,太频繁会给文件系统造成比较大的压力。所以可以控制一个间隔。
最后看下流式消费的原理。先看流式消费非分区表:
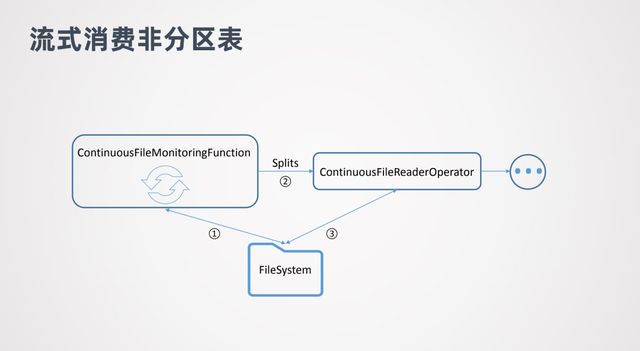
图中 ContinuoousFileMonitoringFunction 会不断监控非分区表目录下面的文件,会不断的跟文件系统进行交互。一旦发现有新的文件添加了,就会对这些文件生成Splits ,并将 Splits 传到 ContinuoousFileReaderOperator,FileReaderOperator 拿到 Splits 后就会到文件系统中实际的消费这些数据,然后把读出来的数据再传往下游处理。
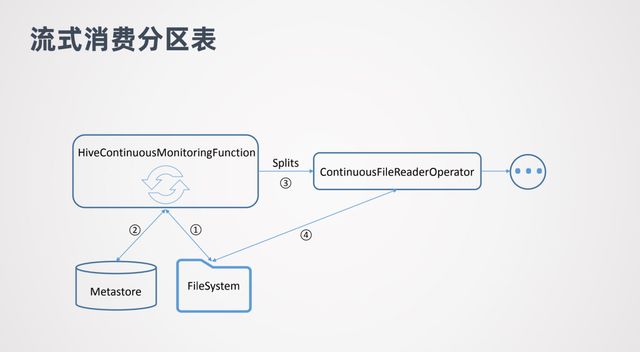
对于流式消费分区表和非分区表区别不是很大,其中 HiveContinuousMonitoringFunction 也会去不断的扫描文件系统,但是它扫描的是新增分区的目录。当它发现有新增的分区目录后,会进一步到 metstore 中做核查,查看是否这个分区已经提交到 metstore 中。如果已经提交,那就可以消费分区中的数据了。然后会把分区中的数据生成 Splits 传给 ContinuousFileReaderOperator ,然后就可以对数据进行消费了。
7. 关联 Hive 维表
关于 Hive 跟流式数据结合的另一个场景就是:关联 Hive 维表。例如在消费流式数据时,与一张线下的 Hive 维表进行 join。

关联Hive维表采用了 Flink 的 Temporal Table 的语法,就是把 Hive 的维表作为Temporal Table,然后与流式的表进行 join。想了解更多关于 Temporal Table 的内容,可查看 Flink 的官网。
关联 Hive 维表的实现是每个 sub-task 将 Hive 表缓存在内存中,是缓存整张的Hive 表。如果 Hive 维表大小超过 sub-task 的可用内存,那么作业会失败。
Hive 维表在关联的时候,Hive 维表可能会发生更新,所以会允许用户设置 hive 表缓存的超时时间。超过这个时间后,sub-task 会重新加载 Hive 维表。需要注意,这种场景不适用于 Hive 维表频繁更新的情况,这样会对 HDFS 文件系统造成很大的压力。所以适用于 Hive 维表缓慢更新的情况。缓存超时时间一般设置的比较长,一般是小时级别的。
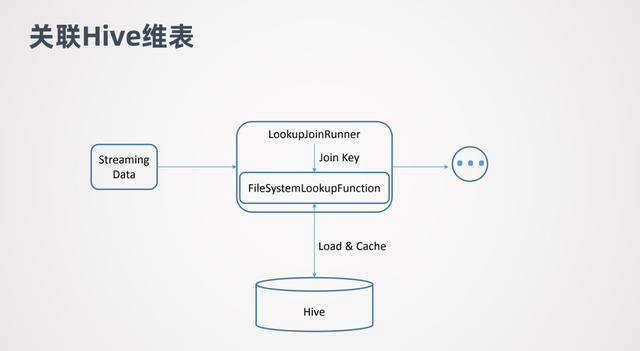
这张图表示的是关联 Hive 维表的原理。Streaming Data 代表流式数据,LookupJoinRunner 表示 Join 算子,它会拿到流式数据的 join key,并把 join key 传给FileSystemLookupFunction。
FileSystemLookupFunction 是 一个Table function,它会去跟底层的文件系统交互并加载 Hive 表,然后在 Hive 表中查询 join key,判断哪些行数据是可以 join的。
下面是关联 Hive 维表的例子:

这是 Flink 官网的一个例子,流式表是 Orders,LatestTates 是 Hive 的维表。
经过上面的介绍可以看出,在 Flink 1.11 中,在 Hive 数仓和批流一体的功能是进行了着重的开发。因为 Flink 是一个流处理的引擎,希望帮用户更好的将批和流结合,让 Hive 数仓实现实时化的改造,让用户更方便的挖掘数据的价值。

在 Flink 1.11 之前,Flink 对接 Hive 会做些批处理的计算,并且只支持离线的场景。离线的场景一个问题是延迟比较大,批作业的调度一般都会通过一些调度的框架去调度。这样其实延迟会有累加的作用。例如第一个 job 跑完,才能去跑第二个 job...这样依次执行。所以端对端的延迟就是所有 job 的叠加。
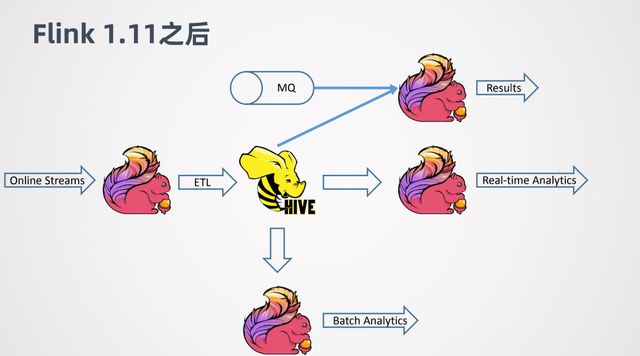
到了 1.11 之后,支持了 Hive 的流式处理的能力,就可以对 Hive 数仓进行一个实时化的改造。
例如 Online 的一些数据,用 Flink 做 ETL,去实时的写入 Hive。当数据写入 Hive之后,可以进一步接一个新的 Flink job,来做实时的查询或者近似实时的查询,可以很快的返回结果。同时,其他的 Flink job 还可以利用写入 Hive 数仓的数据作为维表,来跟其它线上的数据进行关联整合,来得到分析的结果。
以上是“Flink 1.11与Hive批流一体数仓的示例分析”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





