这篇文章主要讲解了“Vertica的C-Store知识点有哪些”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Vertica的C-Store知识点有哪些”吧!
背景知识
Vertica 是 C-Store 的商业化产品,C-Store 在 2006 年发布了0.2版本之后就没在开发了。C-Store 的一部分人与 2006 年开启 Vertica 项目,在 2011 年被 Hewlett-Packard(HP)收购。Vertica 没有使用 C-Store 原型系统的代码,仅借鉴了思想。
截止2012年,有超过 500 个生产环境部署了 Vertica,其中有至少 3 个项目数据量达到 PB 级。和 C-Store 一样,Vertica 提供经典的关系型接口,Vertica 证明了一个系统既可以支持完整的 ACID 事务,也可以支持 PB 级数据高效的查询。这个说法我感觉已经超过现在的 NewSQL 分布式关系型数据库了。
业务场景
事务型:每秒有很多笔请求(上千),每个请求只处理小部分数据。大部分事务是插入一行数据或者更新一行数据。
分析型:每秒只有少数个请求(几十),但是每个请求会遍历表的一大部分数据。例如按时间和空间聚合销售数据。
现在商业公司中一张表中的数据已经达到了百万或者十亿级,事务型和分析型场景的区别越来越明显,针对分析型场景单独做优化可以比 one-size-fits-all 的系统性能提升几个数量级。
Projection 和物化视图的区别
projection 可以看做是带限制的物化视图,但是和标准的物化视图不一样,因为projection 仅仅是数据的物理结构,而不是辅助索引。传统的物化视图通常还包含聚合、连接和其他的查询结果。但是 projection 不包含。并且在分布式系统中维护物化视图的代价很高,尤其是再加上对聚合和过滤的支持是不现实的。
总而言之,物化视图比 projection 杂,实现复杂,在分布式系统中需要被抛弃掉了。
join index
C-Store 中提过的 join index 被废弃掉了,维护这个索引代价太大,而且需要多存很多 id。那如何构建一个完整的行呢? Vertica 维护了一个包含所有列的 super projection,也就是一张完整的表。
存储模型
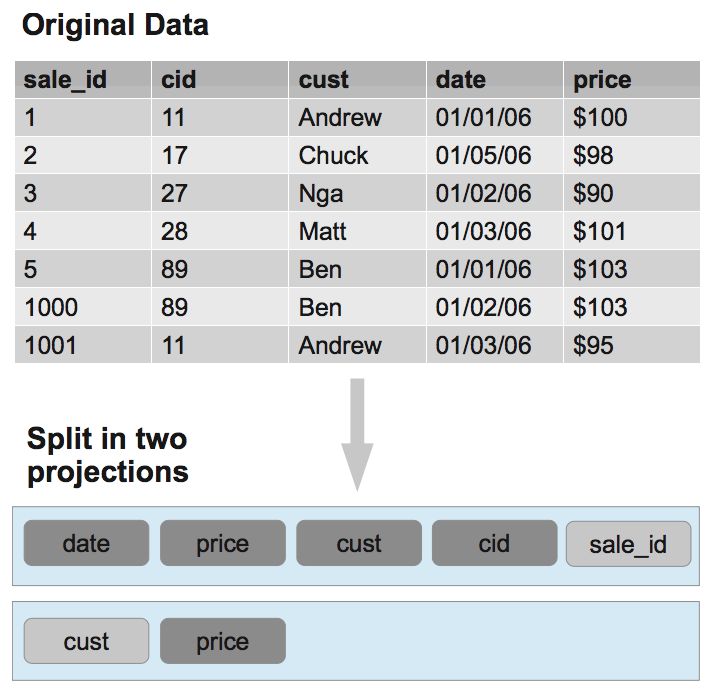
对于每个 projection 来说,哪些数据存储到一个 segment 中,放在哪个节点上是分段策略决定的。数据只在每个 segment 内部排序。第一个 projection 按 hash(sale_id) 分段,按 date 排序。第二个 projection 按 hash(cust) 分段,按 cust 排序。
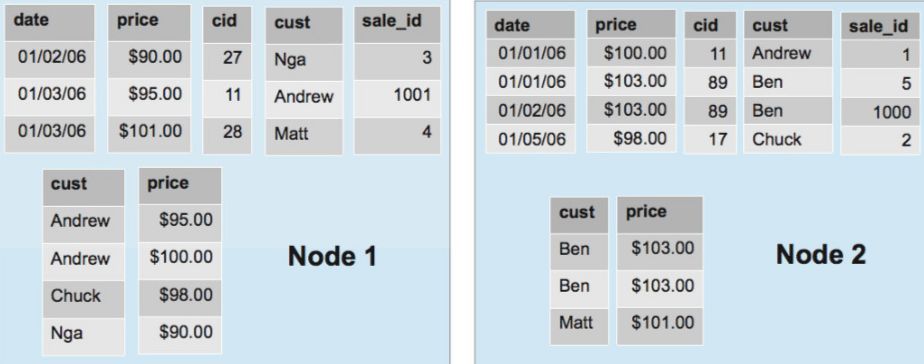
节点间分段:Segmentation
这里说的分段是节点间的,用来决定哪些数据分配在哪些节点上。分段方式是在定义 projection 时指定的。分段的依据是一个整数表达式,给一行 projection 数据,就计算出一个整数,根据这个整数的大小分配到不同节点上去。作者在这给了一个分段的公式。
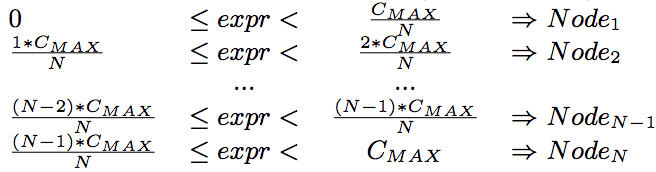
其实就是一致性hash环,以后再介绍。
节点内部数据分区:Partitioning
分区是指每个数据分区用一个文件存储,物理上分离开了。
分区的第一个好处是批量删除,通常数据按照年月分成多个文件,这样在删除一段时间数据时就可以简单的删除一个文件。如果数据没有提前分区,就需要逐个遍历记录。
批量删除只有在一个表的多个 projection 分区方式一样时才能实现,不然只能删掉部分 projection 的分区,因此 Vertica 的分区是指定在 table 层级的。
分区的另一个好处是加速查询,每个分区有一个摘要信息,可以快速跳过一些分区。
他这个对 partition 的解释我觉得很别扭,一致性hash里 partition 是用来控制数据存储在哪个节点上的。
三个组件
和 C-Store 一样,Vertica 也包括一个 Read Optimized Store(ROS),一个 Write Optimized Store(WOS)。一般来说,每个文件存一列,也可以存多列,这样类似混合架构。
数据在 WOS 里没有压缩编码,因为很小,而且在内存里采用行式或列式没有什么区别,Vertica 的 WOS 从行式改成了列式,又改成了行式,主要是出于软件工程考虑,性能上没啥区别。
Tuple mover:两个主要功能:(1)Moveout,将 WOS 中的数据移动到 ROS 中,即 flush (2)Mergeout,将 ROS 中的小文件合并成大文件。其实就是 LSM 的概念,换了个叫法。
Vertica 有个功能,当 flush 的时候,允许新来的写入直接写到 ROS 中,这个我不理解,这怎么保序?虽然作者最后又提了一遍这个功能,说初始化导入数据时写到 WOS 里是浪费内存,但是内存是用来排序的,否则 ROS 岂不是乱了?
容错
为了保证每个 projection 都可以恢复,每个 projection 都至少要有一个包含相同列和相同分段方式的 buddy projection。
因为每个 projection 可以有自己的排序键,这里恢复就有两种情况了:
(1)排序键一样,可以直接拷贝文件,副本恢复也是这么做的。
(2)排序键不一样,需要先查询再写入,没啥更好的方法。
另外,Vertica 可以容忍 K 个错,因此,数据库在设计 projection 时需要保证每个 segment 需要至少在 K+1 个节点都有备份。 这句话的意思应该是直接生成 K+1 个 projection,而不是纯粹复制 segment。
局限
Vertica 解决了 C-Store 的一个大麻烦: join index,但是还是有刺可以挑的:
没有讲如何生成 projection,顺序如何选择,要配多少个副本,不同的 projection 按照不同顺序存储,会不会拖慢写入速度没有介绍。
用户一般不会设置最大空间占用,只会设置副本数,没有用户给系统一个最大可用的空间限制,然后让数据库自己把这些空间都吃满,顶多给一个原始数据占空间多少和允许数据库占的空间的比例,根据一个预设的可用空间来选择副本数的数据库都是耍流氓。
负载均衡没有提如何做。
感谢各位的阅读,以上就是“Vertica的C-Store知识点有哪些”的内容了,经过本文的学习后,相信大家对Vertica的C-Store知识点有哪些这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3664598/blog/4430174



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



