这篇文章主要介绍如何安装单机版hadoop相关套件,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
配置文件在 $HADOOP_HOME/etc/hadoop 目录下。
配置 hadoop-env.sh ,添加属性
# The java implementation to use. export JAVA_HOME=/home/java/jdk1.8.0_191 export HADOOP_OPTS="$HADOOP_OPTS -Duser.timezone=GMT+08"
配置 core-site.xml
<configuration> <!-- 用来指定hdfs的NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-standalone:9000</value> </property> <!-- 用来指定Hadoop运行时产生文件的存放目录 --> <property> <name>hadoop.tmp.dir</name> <value>/home/data/hadoop</value> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property> </configuration>
配置 hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
配置 mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 日志查看页面. --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop-standalone:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop-standalone:19888</value> </property> <!-- 配置正在运行中的日志在hdfs上的存放路径 --> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/history/done_intermediate</value> </property> <!-- 配置运行过的日志存放在hdfs上的存放路径 --> <property> <name>mapreduce.jobhistory.done-dir</name> <value>/history/done</value> </property> </configuration>
配置 yarn-site.xml
<configuration> <!-- NodeManager获取数据的方式是shuffle--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的老大(resourcemanager)的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop-standalone</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.nodemanager.log-aggregation.debug-enabled</name> <value>true</value> </property> <property> <name>yarn.nodemanager.log-aggregation.roll-monitoring-interval-seconds</name> <value>3600</value> </property> <property> <name>yarn.log.server.url</name> <value>http://hadoop-standalone:19888/jobhistory/logs</value> </property> </configuration>
yarn-env.sh 配置中添加
YARN_OPTS="$YARN_OPTS -Duser.timezone=GMT+08"
格式化namenode
hdfs namenode -format
分别启动 hdfs / yarn / jobhistory服务器
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
$HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver
分别访问
http://hadoop-standalone:50070
http://hadoop-standalone:8088
先安装scala, 再在系统的环境变量中配置SPARK_HOME
然后配置 spark-env.sh
export JAVA_HOME=/home/java/jdk1.8.0_191 export SCALA_HOME=/home/scala2.11.12 export HADOOP_HOME=/home/hadoop-2.7.7 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export SPARK_LOCAL_DIRS=/home/data/spark
配置 spark-defaults.conf
spark.yarn.jars hdfs://hadoop-standalone:9000/spark/share/lib/*.jar spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop-standalone:9000/spark/spark-events spark.history.ui.port 18080 spark.history.retainedApplications 10 spark.history.fs.logDirectory hdfs://hadoop-standalone:9000/spark/spark-events
spark的运行包上传到dfs
hdfs dfs -put $SPARK_HOME/jars/* /spark/share/lib
启动 spark history 服务器
$SPARK_HOME/sbin/start-history-server.sh
master和slave都是同一台机子, 即管理者和工人都是自己
启动 spark master 和 slaves服务
$SPARK_HOME/sbin/start-master.sh
$SPARK_HOME/sbin/start-slaves.sh
下面是默认的端口
SPARK_MASTER_PORT=7077 # 提交任务的端口 SPARK_MASTER_WEBUI_PORT=8080 # webui端口,查看任务进程
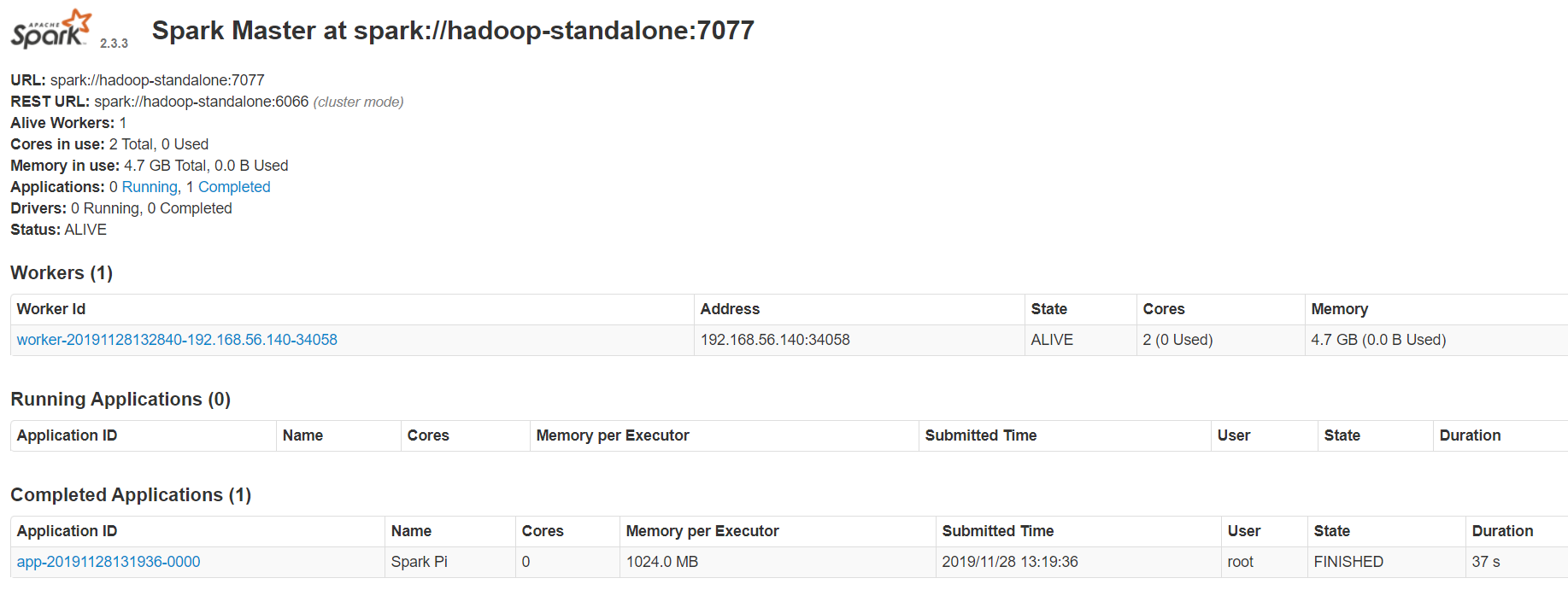
打开页面 http://hadoop-standalone:8080/ , 可以看到有worker已经加入到集群
用于一些组件的元数据 ,需要事先启动
添加环境变量
#hive export HIVE_HOME=/usr/local/hive export PATH=$PATH:$HIVE_HOME/bin
复制mysql的驱动程序到hive/lib
配置hive.env.sh
export HADOOP_HOME=/opt/hadoop-2.6.5 # Hive Configuration Directory can be controlled by: export HIVE_CONF_DIR=/opt/hive-2.3.5/conf
修改log生成的目录。配置文件hive-log4j.properties。修改到你所需的目录
property.hive.log.dir = /opt/hive-2.3.5/logs
配置 hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!--hdfs上hive数据存放位置 --> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <!--连接数据库地址,名称 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value> </property> <!--连接数据库驱动 --> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <!--连接数据库用户名称 --> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <!--连接数据库用户密码 --> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> <!--客户端显示当前查询表的头信息 --> <property> <name>hive.cli.print.header</name> <value>true</value> </property> <!--客户端显示当前数据库名称信息 --> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property> <property> <name>hive.metastore.port</name> <value>9083</value> <description>Hive metastore listener port</description> </property> <property> <name>hive.server2.thrift.port</name> <value>10000</value> <description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.</description> </property> <!-- 客户端配置,连接远端的metadata --> <property> <name>hive.metastore.local</name> <value>false</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://192.168.56.140:9083</value> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> </configuration>
初始化hive的meta数据库(mysql)
schematool -dbType mysql -initSchema
启动hive的命令行客户端,试运行
hive
创建个数据库测试下:
create database test_connect_hive;

使用jdbc客户端连接hiveserver2
在hadoop/core-site.xml 添加配置。其中 root 是现在用的用户名(报错那里有)
<property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property>
修改hadoop要重启.
下面分别启动 metastore 访问服务和hiveserver2服务
nohup hive --service metastore >> /home/data/hive/metastore.log 2>&1 & nohup hive --service hiveserver2 >> /home/data/hive/hiveserver2.log 2>&1 &
通过 beelines 客户端连接 hiveserver2 测试。
beeline
输入连接的地址
!connect jdbc:hive2://localhost:10000
将hive的配置文件拷贝给spark
将 $HIVE_HOME/conf/hive-site.xml copy $SPARK_HOME/conf/
dfs: http://hadoop-standalone:50070/explorer.html#/ spark master(standalone): http://hadoop-standalone:8080 spark history: http://hadoop-standalone:18080/
以上是“如何安装单机版hadoop相关套件”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





