本篇内容介绍了“如何使用全排列、组合、子集”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
求全排列?
全排列即:n个元素取n个元素(所有元素)的所有排列组合情况。
求组合?
组合即:n个元素取m个元素的所有组合情况(非排列)。
求子集?
子集即:n个元素的所有子集(所有可能的组合情况)。
总的来说全排列数值个数是所有元素,不同的是排列顺序;而组合是选取固定个数的组合情况(不看排列);子集是对组合拓展,所有可能的组合情况(同不考虑排列)。
当然,这三种问题,有相似之处又略有所不同,我们接触到的全排列可能更多,所以你可以把组合和子集问题认为是全排列的拓展变形。且问题可能会遇到待处理字符是否有重复的情况。采取不同的策略去去重也是相当关键和重要的!在各个问题的具体求解上方法可能不少,在全排列上最流行的就是邻里互换法和回溯法,而其他的组合和子集问题是经典回溯问题。而本篇最重要和基础的就是要掌握这两种方法实现的无重复全排列,其他的都是基于这个进行变换和拓展。
全排列,元素总数为最大,不同是排列的顺序。
这个问题刚好在力扣46题是原题的,大家学完可以去a试试。
问题描述:
给定一个 没有重复 数字的序列,返回其所有可能的全排列。
示例:
输入: [1,2,3]
输出:
[
[1,2,3],
[1,3,2],
[2,1,3],
[2,3,1],
[3,1,2],
[3,2,1]
]回溯法实现无重复全排列
回溯算法用来解决搜索问题,而全排列刚好也是一种搜索问题,先回顾一下什么是回溯算法:
回溯算法实际上一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径.
而全排列刚好可以使用试探的方法去枚举所有中可能性。一个长度为n的序列或者集合。它的所有排列组合的可能性共有n!种。具体的试探策略如下:
从待选集合中选取第一个元素(共有n种情况),并标记该元素已经被使用不能再使用。
在步骤1的基础上进行递归到下一层,从剩余n-1个元素中按照1的方法找到一个元素并标记,继续向下递归。
当所有元素被标记后,顺序收集被标记的元素存储到结果中,当前层递归结束,回到上一层(同时将当前层标记的元素清除标记)。这样一直执行到最后。
回溯的流程如果从伪代码流程大致为这样:
递归函数: 如果集合所有元素被标记: 将临时储存添加到结果集中 否则: 从集合中未标记的元素中选取一个存储到临时集合中 标记该元素被使用 下一层递归函数 (这层递归结束)标记该元素未被使用
如果用序列 1 2 3 4来表示这么回溯的一个过程,可以用这张图来显示:
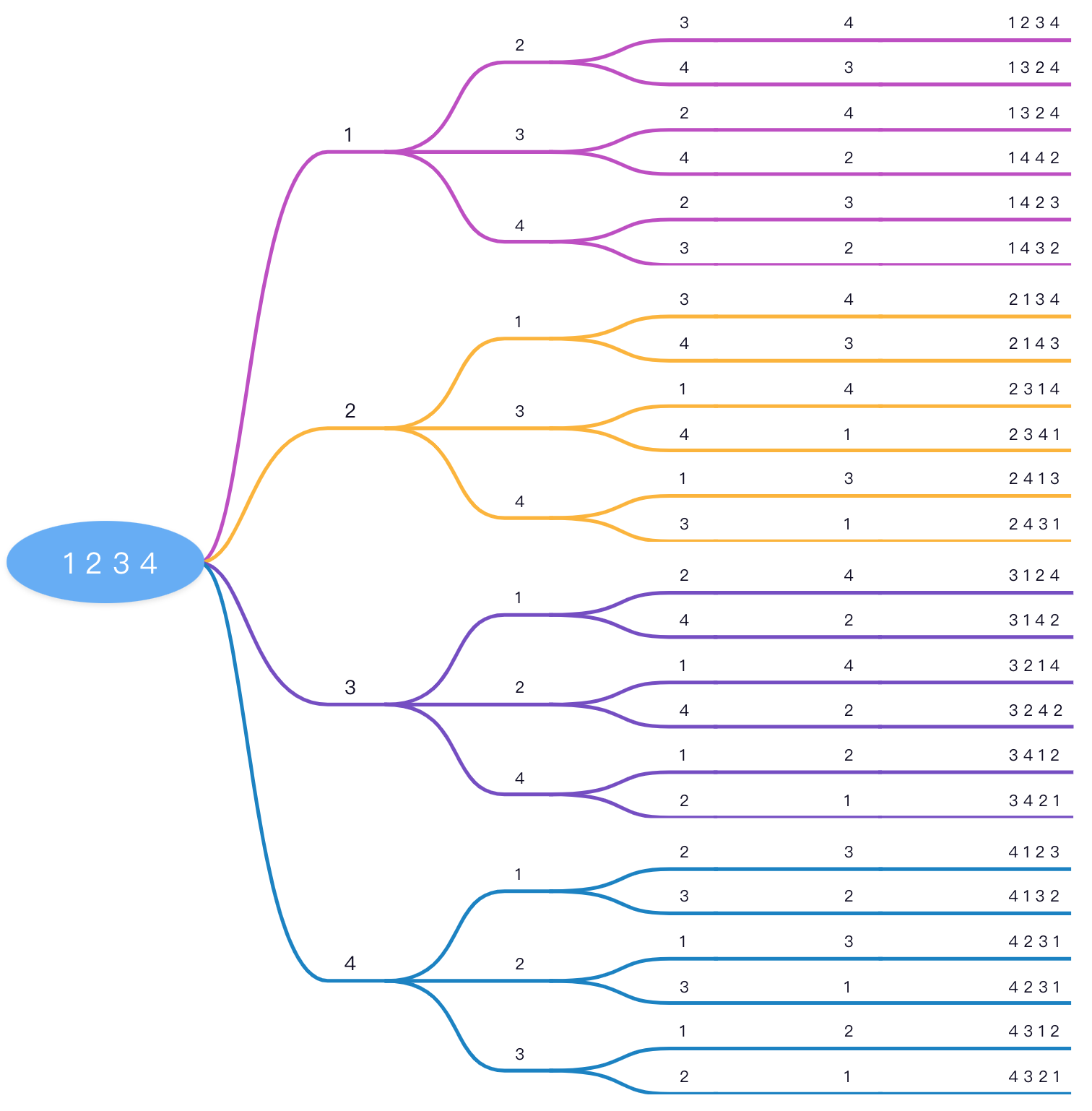
用代码来实现思路也是比较多的,需要一个List去存储临时结果是很有必要的,但是对于原集合我们标记也有两种处理思路,第一种是使用List存储集合,使用过就移除然后递归下一层,递归完毕后再添加到原来位置。另一种思路就是使用固定数组存储,使用过对应位置使用一个boolean数组对应位置标记一下,递归结束后再还原。因为List频繁查找插入删除效率一般比较低,所以我们一般使用一个boolean数组去标记该位置元素是否被使用。
具体实现的代码为:
List<List<Integer>> list;public List<List<Integer>> permuteUnique(int[] nums) {
list=new ArrayList<List<Integer>>();//最终的结果List<Integer> team=new ArrayList<Integer>();//回溯过程收集元素boolean jud[]=new boolean[nums.length];//用来标记dfs(jud, nums, team, 0);return list;}private void dfs(boolean[] jud, int[] nums, List<Integer> team, int index) {
int len = nums.length;if (index == len)// 停止{
list.add(new ArrayList<Integer>(team));} elsefor (int i = 0; i < len; i++) {
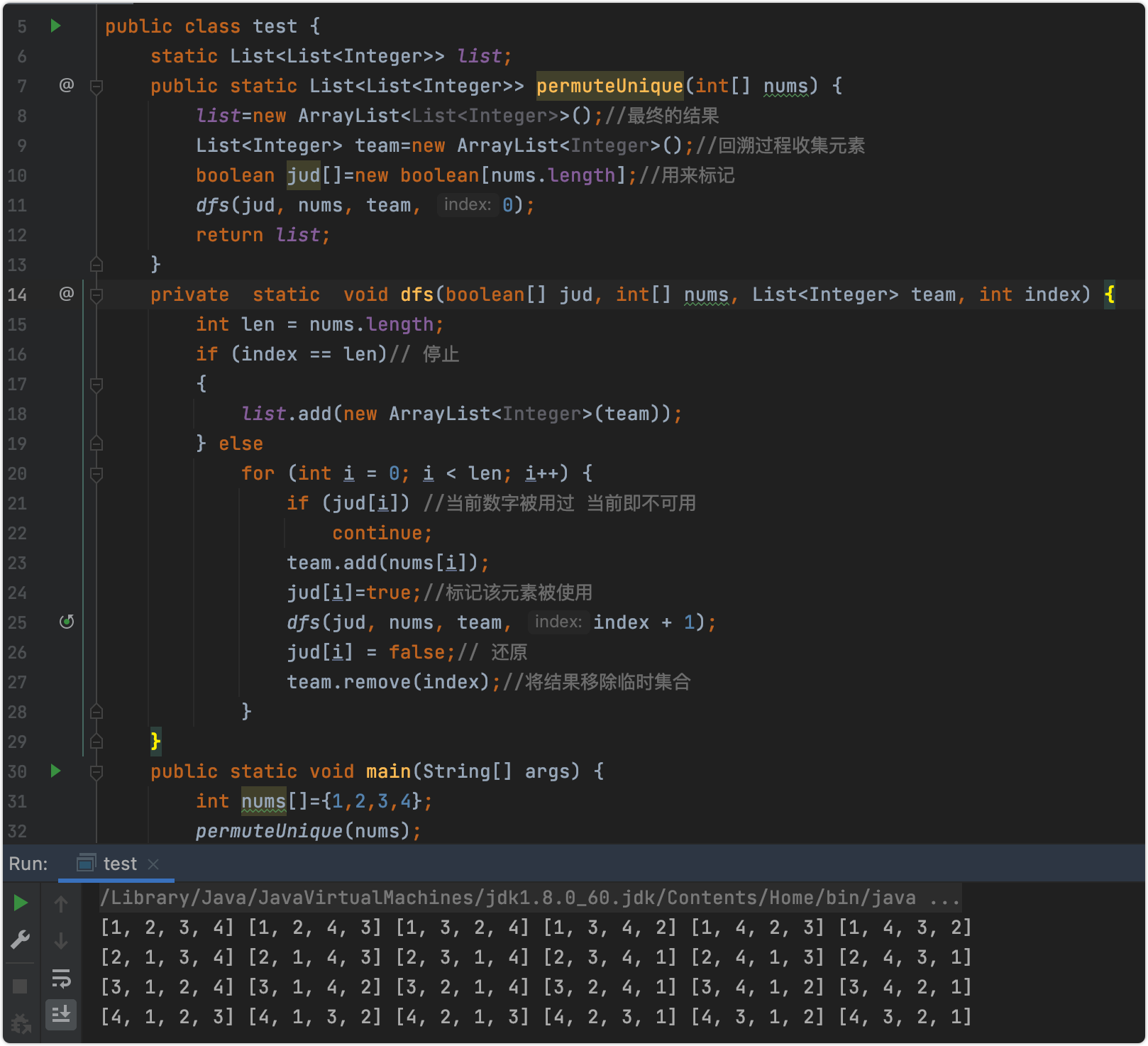
if (jud[i]) //当前数字被用过 当前即不可用continue;team.add(nums[i]);jud[i]=true;//标记该元素被使用dfs(jud, nums, team, index + 1);jud[i] = false;// 还原team.remove(index);//将结果移除临时集合}}修改一下输出的结果和上面思维导图也是一致的:
邻里互换法实现无重复全排列
回溯的测试是试探性填充,是对每个位置进行单独考虑赋值。而邻里互换的方法虽然是也是递归实现的,但是他是一种基于交换的策略和思路。而理解起来也是非常简单,邻里互换的思路是从左向右进行考虑。
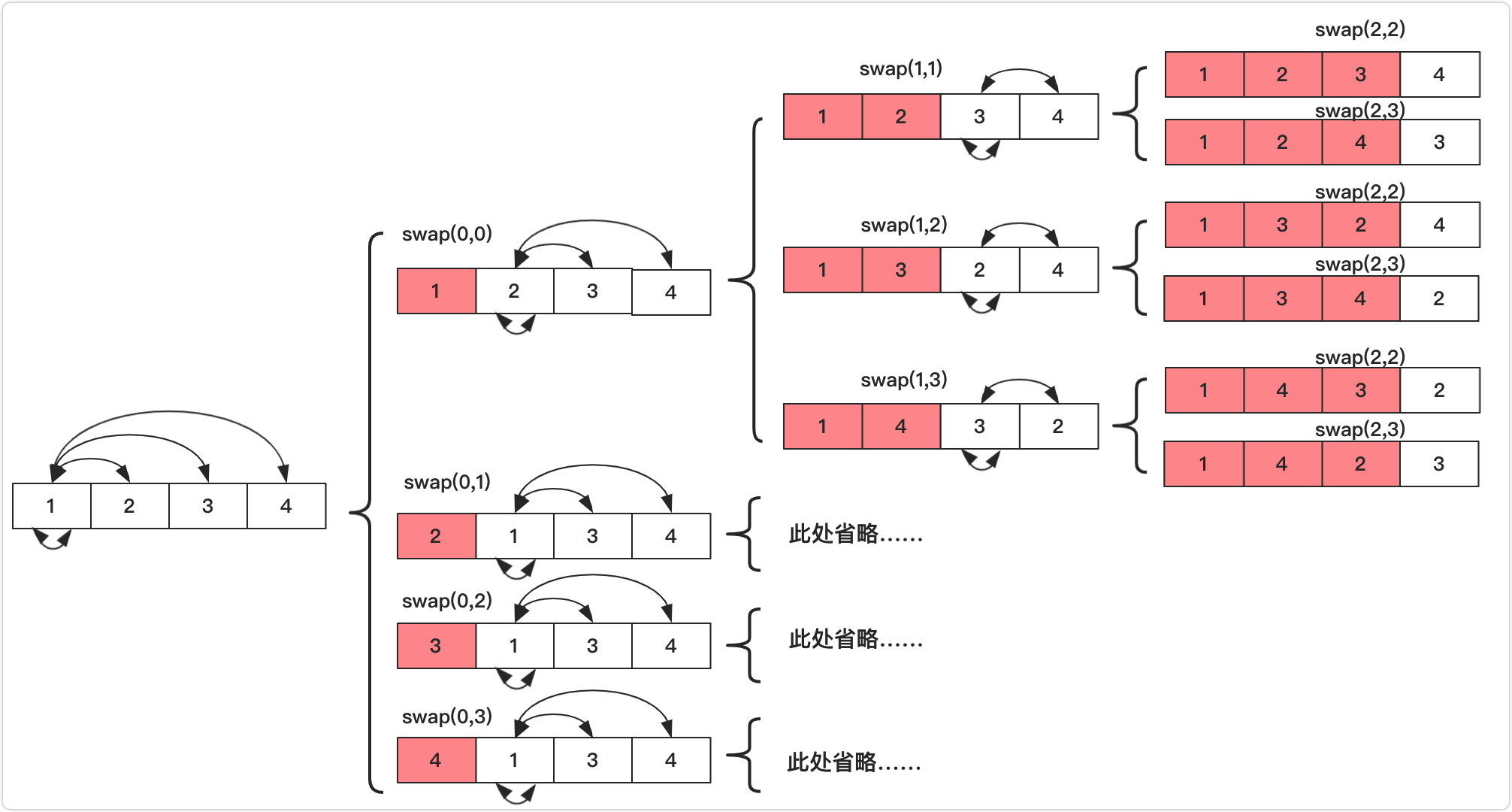
因为序列是没有重复的,我们开始将数组分成两个部分:暂时确定部分和未确定部分。开始的时候均是未确定部分,我们需要妥善处理的就是未确定部分。在未确定部分的序列中,我们需要让后面未确定的每一位都有机会处在未确定的首位,所以未确定部分的第一个元素就要和每一个依次进行交换(包括自己),交换完成之后再向下进行递归求解其他的可能性,求解完毕之后要交换回来(还原)再和后面的进行交换。这样当递归进行到最后一层的时候就将数组的值添加到结果集中。如果不理解可以参考下图进行理解:
实现代码为:
class Solution {
public List<List<Integer>> permute(int[] nums) {
List<List<Integer>>list=new ArrayList<List<Integer>>();arrange(nums,0,nums.length-1,list);return list;
}private void arrange(int[] nums, int start, int end, List<List<Integer>> list) {
if(start==end)//到最后一个 添加到结果中
{
List<Integer>list2=new ArrayList<Integer>();
for(int a:nums)
{
list2.add(a);
}
list.add(list2);
}
for(int i=start;i<=end;i++)//未确定部分开始交换
{
swap(nums,i,start);
arrange(nums, start+1, end, list);
swap(nums, i, start);//还原
}}private void swap(int[] nums, int i, int j) {
int team=nums[i];
nums[i]=nums[j];
nums[j]=team;}}那么邻里互换和回溯求解的全排列有什么区别呢?首先回溯法求得的全排列如果这个序列有序得到的结果是字典序的,因为其策略是填充,先小后大有序,而邻里互换没有这个特征。其次邻里互换在这种情况下的效率要高于回溯算法的,虽然量级差不多但是回溯算法需要维护一个集合频繁增删等占用一定的资源。
有重复对应的是力扣第47题 ,题目描述为:
给定一个可包含重复数字的序列
nums,按任意顺序 返回所有不重复的全排列。
示例 1:
输入:nums = [1,1,2]
输出:
[[1,1,2],
[1,2,1],
[2,1,1]]示例 2:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]提示:
1 <= nums.length <= 8
-10 <= nums[i] <= 10
这个和上面不重复的全排列略有不同,这个输入数组中可能包含重复的序列,我们怎么样采取合适的策略去重复才是至关重要的。我们同样针对回溯和邻里互换两种方法进行分析。
回溯剪枝法
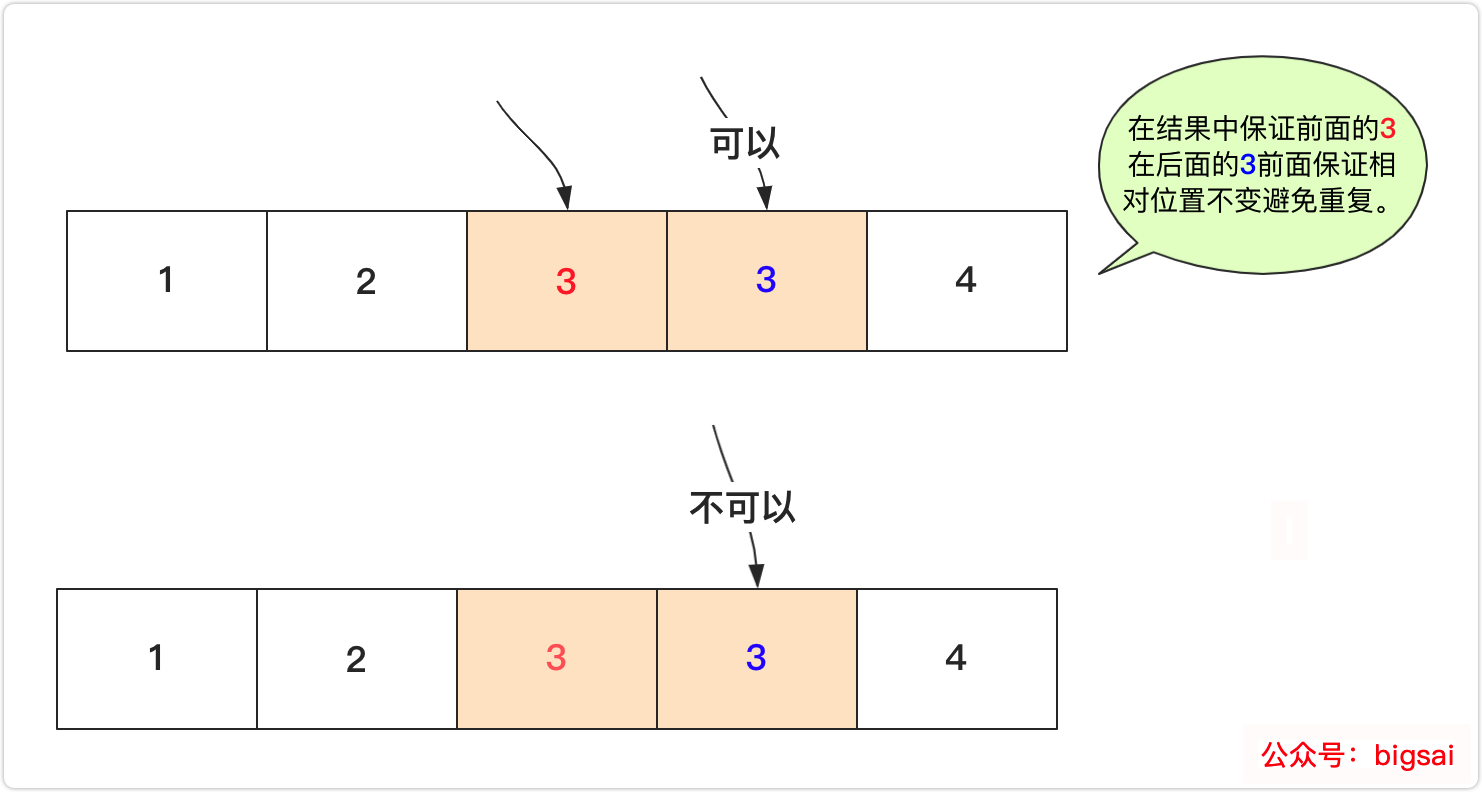
因为回溯完整的比直接递归慢,所以刚开始并没有考虑使用回溯算法,但是这里用回溯剪枝相比递归邻里互换方法更好一些,对于不使用哈希去重的方法,首先进行排序预处理是没有悬念的,而回溯法去重的关键就是避免相同的数字因为相对次序问题造成重复,所以在这里相同数字在使用上相对位置必须不变,而具体剪枝条的规则如下:
先对序列进行排序
试探性将数据放到当前位置
如果当前位置数字已经被使用,那么不可使用
如果当前数字和前一个相等但是前一个没有被使用,那么当前不能使用,需要使用前一个数字。
思路很简单,实现起来也很简单:
List<List<Integer>> list;public List<List<Integer>> permuteUnique(int[] nums) {
list=new ArrayList<List<Integer>>();
List<Integer> team=new ArrayList<Integer>();boolean jud[]=new boolean[nums.length];
Arrays.sort(nums);dfs(jud, nums, team, 0);return list;}private void dfs(boolean[] jud, int[] nums, List<Integer> team, int index) {
// TODO Auto-generated method stubint len = nums.length;if (index == len)// 停止{
list.add(new ArrayList<Integer>(team));} elsefor (int i = 0; i < len; i++) {
if (jud[i]||(i>0&&nums[i]==nums[i-1]&&!jud[i-1])) //当前数字被用过 或者前一个相等的还没用,当前即不可用continue;
team.add(nums[i]);
jud[i]=true;
dfs(jud, nums, team, index + 1);jud[i] = false;// 还原team.remove(index);}}邻里互换法
我们在执行递归全排列的时候,主要考的是要把重复的情况搞下去,邻里互换又要怎么去重呢?
使用HashSet这种方式这里就不讨论啦,我们在进行交换swap的时候从前往后,前面的确定之后就不会在动,所以我们要慎重考虑和谁交换。比如1 1 2 3第一个数有三种情况而不是四种情况(两个1 1 2 3为一个结果):
1 1 2 3 // 0 0位置交换
2 1 1 3 // 0 2位置交换
3 1 2 1 // 0 3位置交换
另外比如3 1 1序列,3和自己交换,和后面两个1只能和其中一个进行交换,我们这里可以约定和第一个出现的进行交换,我们看一个图解部分过程:

所以,当我们从一个index开始的时候要记住以下的规则:同一个数只交换一次(包括值等于自己的数)。在判断后面值是否出现的时候,你可以遍历,也可以使用hashSet().当然这种方法的痛点就是判断后面出现的数字效率较低。所以在可能重复的情况这种方法效率一般般。
具体实现的代码为:
public List<List<Integer>> permuteUnique(int[] nums) {
List<List<Integer>> list=new ArrayList<List<Integer>>();
arrange(nums, 0, nums.length-1, list);
return list;
}private void arrange(int[] nums, int start, int end, List<List<Integer>> list) {
if(start==end)
{
List<Integer>list2=new ArrayList<Integer>();
for(int a:nums)
{
list2.add(a);
}
list.add(list2);
}
Set<Integer>set=new HashSet<Integer>();
for(int i=start;i<=end;i++)
{
if(set.contains(nums[i]))
continue; set.add(nums[i]);
swap(nums,i,start);
arrange(nums, start+1, end, list);
swap(nums, i, start);
}}private void swap(int[] nums, int i, int j) {
int team=nums[i];
nums[i]=nums[j];
nums[j]=team;}组合问题可以认为是全排列的变种,问题描述(力扣77题):
给定两个整数 n 和 k,返回 1 … n 中所有可能的 k 个数的组合。
示例:
输入: n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]分析:
这个问题经典回溯问题。组合需要记住只看元素而不看元素的顺序,比如a b和b a是同一个组合。要避免这样的重复是核心,而避免这样的重复,需要借助一个int类型保存当前选择元素的位置,下次只能遍历选取下标位置后面的数字,而k个数,可以通过一个数字类型来记录回溯到当前层处理数字的个数来控制。

具体实现也很容易,需要创建一个数组储存对应数字,用boolean数组判断对应位置数字是否使用,这里就不用List存储数字了,最后通过判断boolean数组将数值添加到结果中也是可行的。实现代码为:
class Solution {
public List<List<Integer>> combine(int n, int k) {
List<List<Integer>> valueList=new ArrayList<List<Integer>>();//结果int num[]=new int[n];//数组存储1-nboolean jud[]=new boolean[n];//用于判断是否使用for(int i=0;i<n;i++){
num[i]=i+1;}
List<Integer>team=new ArrayList<Integer>();dfs(num,-1,k,valueList,jud,n);return valueList;}private void dfs(int[] num,int index, int count,List<List<Integer>> valueList,boolean jud[],int n) {
if(count==0)//k个元素满{
List<Integer>list=new ArrayList<Integer>();for(int i=0;i<n;i++){
if (jud[i]) {
list.add(i+1);}}
valueList.add(list);}else {
for(int i=index+1;i<n;i++)//只能在index后遍历 回溯向下{
jud[i]=true;dfs(num, i, count-1, valueList,jud,n);
jud[i]=false;//还原}}}}子集问题和组合有些相似。这里讲解数组中无重复和有重复的两种情况。
问题描述(力扣78题):
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]示例 2:
输入:nums = [0]
输出:[[],[0]]提示:
1 <= nums.length <= 10
-10 <= nums[i] <= 10
nums 中的所有元素 互不相同
子集和上面的组合有些相似,当然我们不需要判断有多少个,只需要按照组合回溯的策略递归进行到最后,每进行的一次递归函数都是一种情况都要加入到结果中(因为采取的策略不会有重复的情况)。
实现的代码为:
class Solution {
public List<List<Integer>> subsets(int[] nums) {
List<List<Integer>> valueList=new ArrayList<List<Integer>>();boolean jud[]=new boolean[nums.length];
List<Integer>team=new ArrayList<Integer>();dfs(nums,-1,valueList,jud);return valueList;}private void dfs(int[] num,int index,List<List<Integer>> valueList,boolean jud[]) {
{
//每进行递归函数都要加入到结果中
List<Integer>list=new ArrayList<Integer>();for(int i=0;i<num.length;i++){
if (jud[i]) {
list.add(num[i]);}}
valueList.add(list);}{
for(int i=index+1;i<num.length;i++){
jud[i]=true;dfs(num, i, valueList,jud);
jud[i]=false;}}}}题目描述(力扣90题):
给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。
示例:
输入: [1,2,2]
输出:
[
[2],
[1],
[1,2,2],
[2,2],
[1,2],
[]
]和上面无重复数组求子集不同的是这里面可能会出现重复的元素。我们需要在结果中过滤掉重复的元素。
首先,子集问题无疑是使用回溯法求得结果,首先分析如果序列没有重复的情况,我们会借助一个boolean[]数组标记使用过的元素和index表示当前的下标,在进行回溯的时候我们只向后进行递归并且将枚举到的那个元素boolean[index]置为true(回来的时候复原)。每次递归收集boolean[]数组中true的元素为其中一个子集。
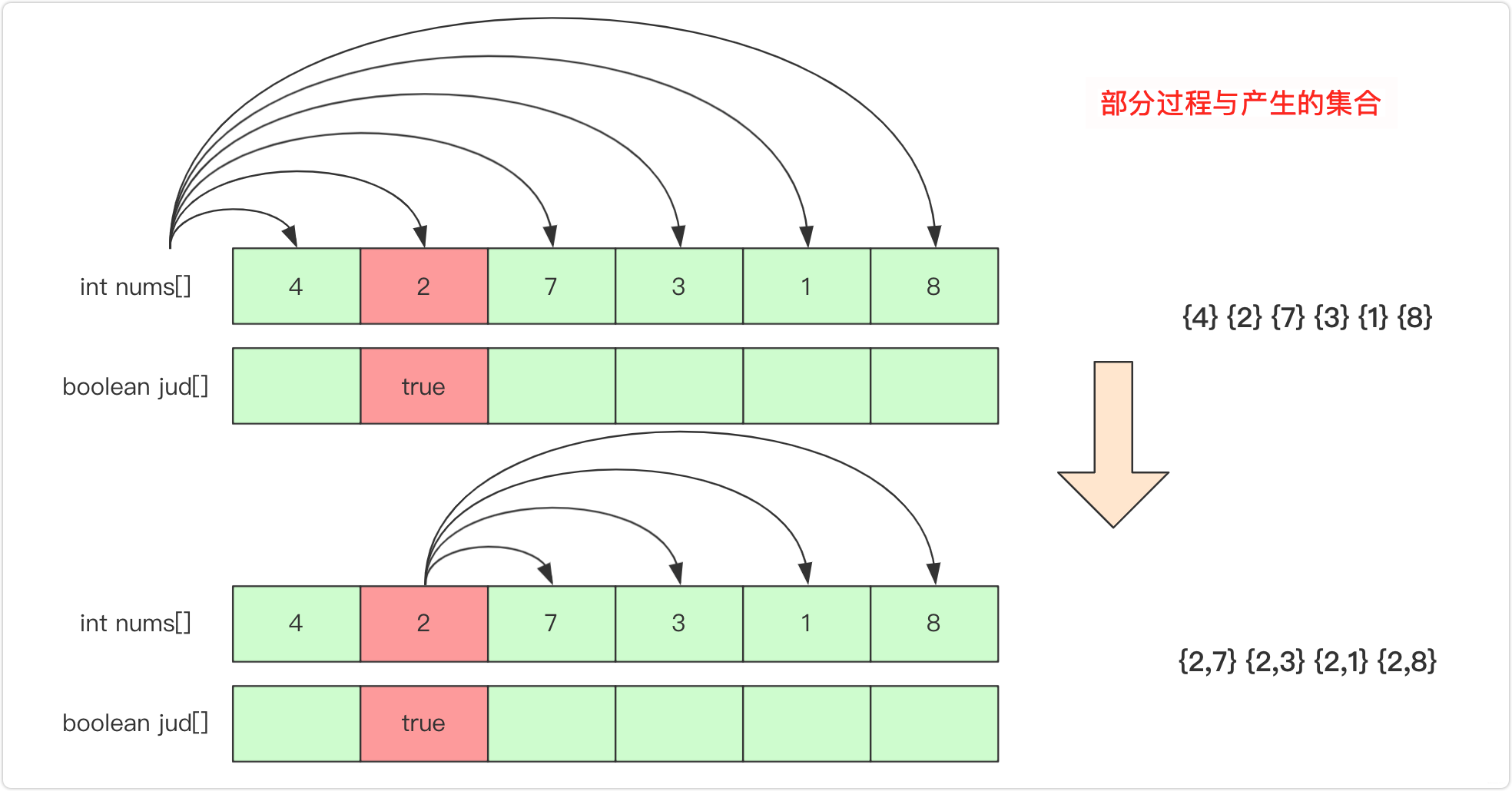
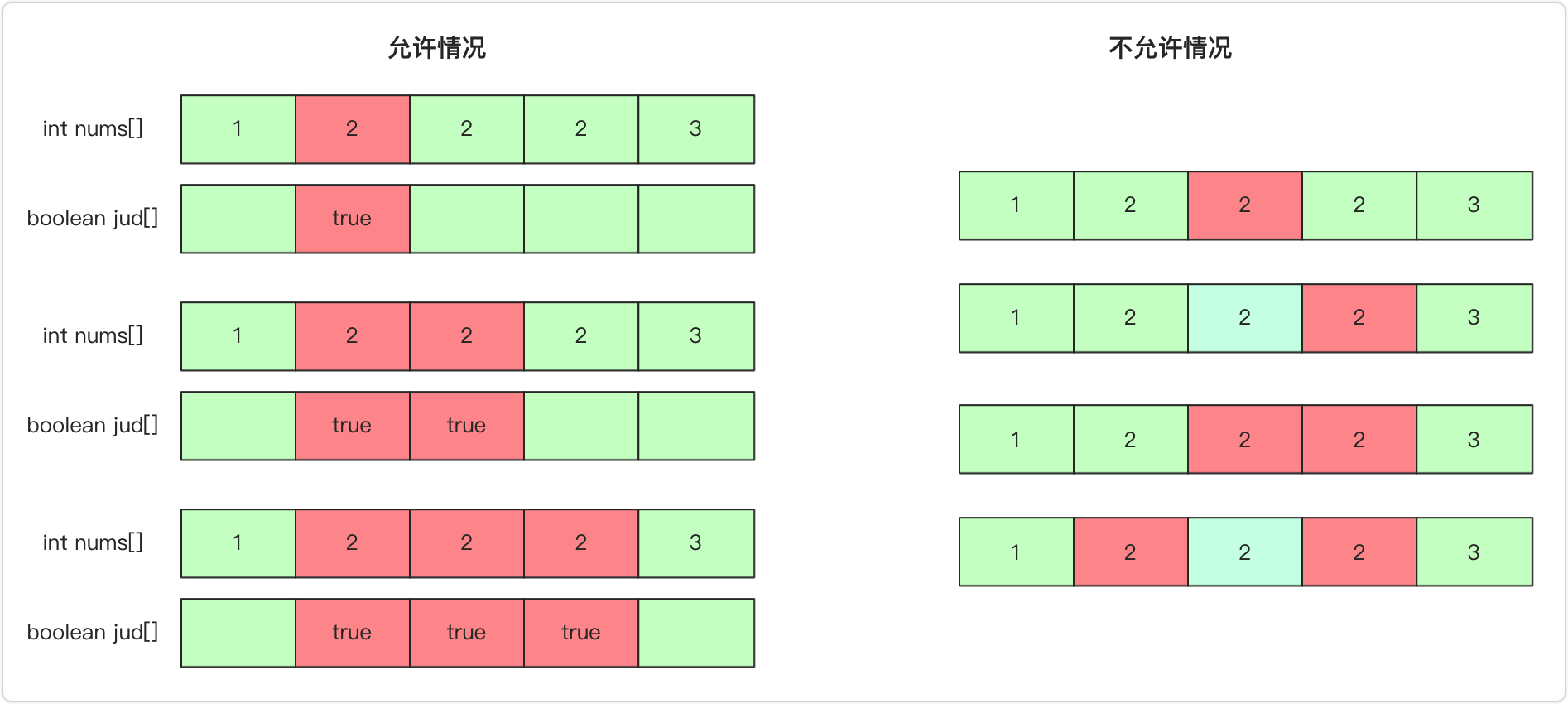
而有重复元素的处理上,和前面全排列的处理很相似,首先进行排序,然后在进行递归处理的时候遇到相同元素只允许从第一位连续使用而不允许跳着使用,所以在递归向下时候需要判断是否满足条件(第一个元素或和前一个不同或和前一个同且前一个已使用),具体可以参考这张图:
实现代码为:
class Solution {
public List<List<Integer>> subsetsWithDup(int[] nums) {
Arrays.sort(nums);boolean jud[]=new boolean[nums.length];List<List<Integer>> valueList=new ArrayList<List<Integer>>();dfs(nums,-1,valueList,jud);return valueList;
}private void dfs(int[] nums, int index, List<List<Integer>> valueList, boolean[] jud) {
// TODO Auto-generated method stub
List<Integer>list=new ArrayList<Integer>();for(int i=0;i<nums.length;i++){
if (jud[i]) {
list.add(nums[i]);}}
valueList.add(list);for(int i=index+1;i<nums.length;i++){
//第一个元素 或 当前元素不和前面相同 或者相同且前面被使用了可以继续进行if((i==0)||(nums[i]!=nums[i-1])||(i>0&&jud[i-1]&&nums[i]==nums[i-1])){
jud[i]=true;dfs(nums, i, valueList,jud);
jud[i]=false;}}}}“如何使用全排列、组合、子集”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4160637/blog/4974467



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



