еҰӮдҪ•иҝӣиЎҢRedis GeoHashж ёеҝғеҺҹзҗҶи§Јжһҗ
еҰӮдҪ•иҝӣиЎҢRedis GeoHashж ёеҝғеҺҹзҗҶи§ЈжһҗпјҢзӣёдҝЎеҫҲеӨҡжІЎжңүз»ҸйӘҢзҡ„дәәеҜ№жӯӨжқҹжүӢж— зӯ–пјҢдёәжӯӨжң¬ж–ҮжҖ»з»“дәҶй—®йўҳеҮәзҺ°зҡ„еҺҹеӣ е’Ңи§ЈеҶіж–№жі•пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« еёҢжңӣдҪ иғҪи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
1. еј•иЁҖ
е°ҸйәҰеҗҢеӯҰжҳҜдёӘеҗғиҙ§+жҠҖжңҜе®…пјҢе№іж—ҘйҮҢе°ұе–ңж¬ўжӢҝзқҖжүӢжңәең°еӣҫзӮ№зӮ№жҢүжҢүжқҘжҹҘиҜўдёҖдәӣеҘҪзҺ©зҡ„дёңиҘҝгҖӮжҹҗдёҖеӨ©еҲ°еҢ—жө·е…¬еӣӯжёёзҺ©пјҢиӮҡиӮҡйҘҝдәҶпјҢдәҺжҳҜд№Һжү“ејҖжүӢжңәең°еӣҫпјҢжҗңзҙўеҢ—жө·е…¬еӣӯйҷ„иҝ‘зҡ„йӨҗйҰҶпјҢ并йҖүдәҶе…¶дёӯдёҖ家用йӨҗгҖӮ
йҘұжҡ–жҖқyinж¬Ізҡ„йәҰеҸ”йҘӯеҗҺжҖқиҖғең°еӣҫеҗҺеҸ°еҰӮдҪ•ж №жҚ®иҮӘе·ұжүҖеңЁдҪҚзҪ®жҹҘиҜўжқҘжҹҘиҜўйҷ„иҝ‘йӨҗйҰҶзҡ„е‘ўпјҹиӢҰжҖқеҶҘжғідәҶеҚҠеӨ©пјҢе°ҸйәҰжғіеҮәдәҶдёӘж–№жі•пјҡи®Ўз®—жүҖеңЁдҪҚзҪ®PдёҺеҢ—дә¬жүҖжңүйӨҗйҰҶзҡ„и·қзҰ»пјҢ然еҗҺиҝ”еӣһи·қзҰ»<=1000зұізҡ„йӨҗйҰҶгҖӮе°Ҹеҫ—ж„ҸдәҶдёҖдјҡе„ҝпјҢе°ҸйәҰеҸ‘зҺ°еҢ—дә¬зҡ„йӨҗйҰҶдҪ•е…¶еӨҡе•ҠпјҢиҝҷж ·и®Ўз®—дёҚеҫ—дәҶпјҢдәҺжҳҜжғідәҶпјҢ既然зҹҘйҒ“з»Ҹзә¬еәҰдәҶпјҢйӮЈе®ғеә”иҜҘзҹҘйҒ“иҮӘе·ұеңЁиҘҝеҹҺеҢәпјҢйӮЈеә”иҜҘи®Ўз®—жүҖеңЁдҪҚзҪ®PдёҺиҘҝеҹҺеҢәжүҖжңүйӨҗйҰҶзҡ„и·қзҰ»е•ҠпјҢжңәжңәиҝҗз”ЁдәҶйҖ’еҪ’зҡ„жҖқжғіпјҢжғіеҲ°дәҶиҘҝеҹҺеҢәд№ҹеҫҲеӨҡйӨҗйҰҶе•ҠпјҢеә”иҜҘи®Ўз®—жүҖеңЁдҪҚзҪ®PдёҺжүҖеңЁиЎ—йҒ“жүҖжңүйӨҗйҰҶзҡ„и·қзҰ»пјҢиҝҷж ·и®Ўз®—йҮҸеҸҲе°ҸдәҶпјҢж•ҲзҺҮд№ҹжҸҗеҚҮдәҶгҖӮ
е°ҸйәҰзҡ„и®Ўз®—жҖқжғіеҫҲжңҙзҙ пјҢе°ұжҳҜйҖҡиҝҮиҝҮж»Өзҡ„ж–№жі•жқҘеҮҸе°ҸеҸӮдёҺи®Ўз®—зҡ„йӨҗйҰҶж•°зӣ®пјҢд»Һжҹҗз§Қи§’еәҰдёҠи®ІпјҢжңәжңәеңЁдҪҝз”Ёзҙўеј•жҠҖжңҜгҖӮ
дёҖжҸҗеҲ°зҙўеј•пјҢеӨ§е®¶и„‘еӯҗйҮҢ马дёҠжө®зҺ°еҮәBж ‘зҙўеј•пјҢеӣ дёәеӨ§йҮҸзҡ„ж•°жҚ®еә“пјҲеҰӮMySQLгҖҒoracleгҖҒPostgreSQLзӯүпјүйғҪеңЁдҪҝз”ЁBж ‘гҖӮBж ‘зҙўеј•жң¬иҙЁдёҠжҳҜеҜ№зҙўеј•еӯ—ж®өиҝӣиЎҢжҺ’еәҸпјҢ然еҗҺйҖҡиҝҮзұ»дјјдәҢеҲҶжҹҘжүҫзҡ„ж–№жі•иҝӣиЎҢеҝ«йҖҹжҹҘжүҫпјҢеҚіе®ғиҰҒжұӮзҙўеј•зҡ„еӯ—ж®өжҳҜеҸҜжҺ’еәҸзҡ„пјҢдёҖиҲ¬иҖҢиЁҖпјҢеҸҜжҺ’еәҸзҡ„жҳҜдёҖз»ҙеӯ—ж®өпјҢжҜ”еҰӮж—¶й—ҙгҖҒе№ҙйҫ„гҖҒи–Әж°ҙзӯүзӯүгҖӮдҪҶжҳҜеҜ№дәҺз©әй—ҙдёҠзҡ„дёҖдёӘзӮ№пјҲдәҢз»ҙпјҢеҢ…жӢ¬з»ҸеәҰе’Ңзә¬еәҰпјүпјҢеҰӮдҪ•жҺ’еәҸе‘ўпјҹеҸҲеҰӮдҪ•зҙўеј•е‘ўпјҹи§ЈеҶізҡ„ж–№жі•еҫҲеӨҡпјҢдёӢж–Үд»Ӣз»ҚдёҖз§Қж–№жі•жқҘи§ЈеҶіиҝҷдёҖй—®йўҳгҖӮ
жҖқжғіпјҡеҰӮжһңиғҪйҖҡиҝҮжҹҗз§Қж–№жі•е°ҶдәҢз»ҙзҡ„зӮ№ж•°жҚ®иҪ¬жҚўжҲҗдёҖз»ҙзҡ„ж•°жҚ®пјҢйӮЈж ·дёҚе°ұеҸҜд»Ҙ继з»ӯдҪҝз”ЁBж ‘зҙўеј•дәҶеҳӣгҖӮйӮЈиҝҷз§Қж–№жі•зңҹзҡ„еӯҳеңЁеҳӣпјҢзӯ”жЎҲжҳҜиӮҜе®ҡзҡ„гҖӮзӣ®еүҚеҫҲзҒ«зҡ„GeoHashз®—жі•е°ұжҳҜиҝҗз”ЁдәҶдёҠиҝ°жҖқжғіпјҢдёӢйқўжҲ‘们е°ұејҖе§ӢGeoHashд№Ӣж—…еҗ§гҖӮ
2. ж„ҹжҖ§и®ӨиҜҶ
е…ҲжқҘдёӨдёӘе№Іиҙ§пјҢеңЁзәҝжҹҘзңӢGPSжҹҗдёӘеҢәеҹҹзҡ„GeoHashеҖјгҖӮ
1. http://geohash.gofreerange.com/
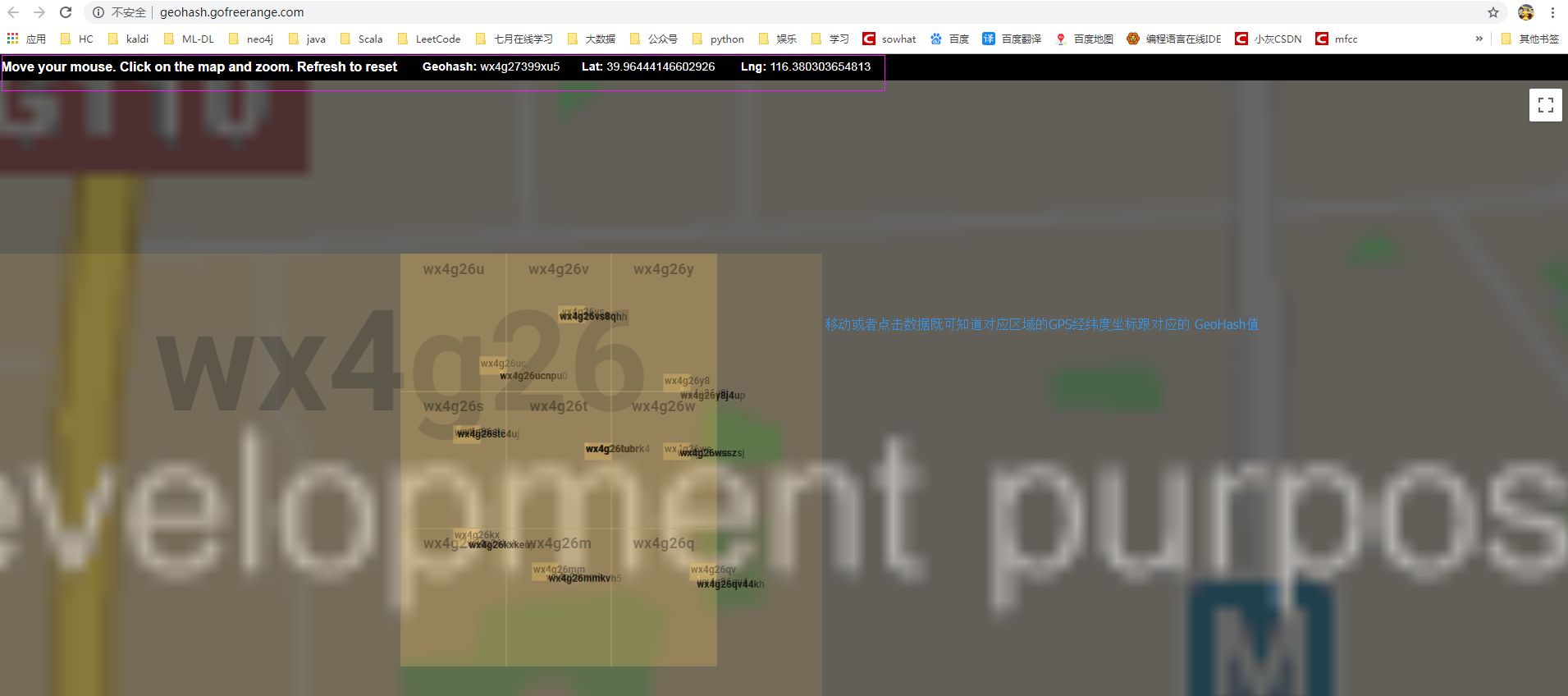
2. http://www.geohash.cn/
и·ҹжӣҙеҘҪз”Ёдәӣ
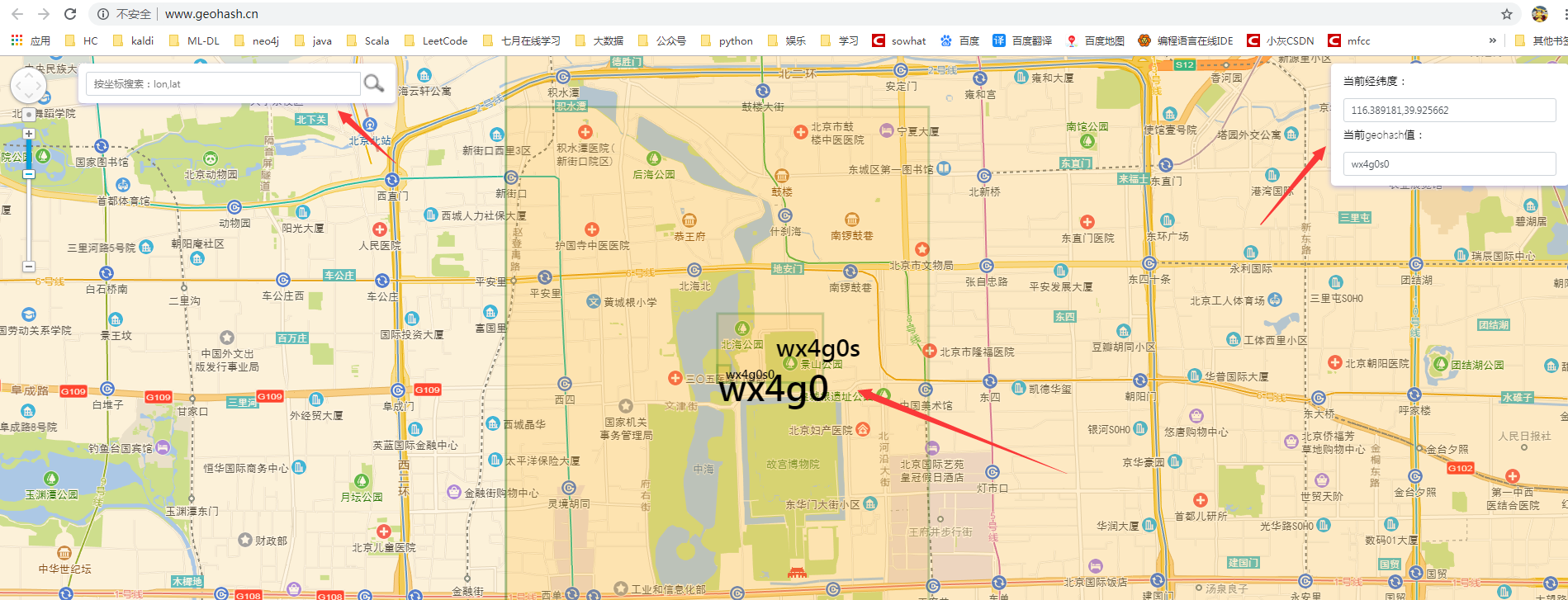
3. йҖҡдҝ—иҜҙ
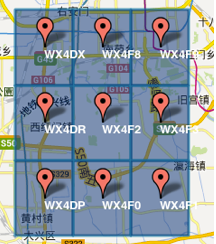
GeoHashе°ҶдәҢз»ҙзҡ„з»Ҹзә¬еәҰиҪ¬жҚўжҲҗеӯ—з¬ҰдёІпјҢжҜ”еҰӮдёӢеӣҫеұ•зӨәдәҶеҢ—дә¬9дёӘеҢәеҹҹзҡ„GeoHashеӯ—з¬ҰдёІпјҢеҲҶеҲ«жҳҜWX4ERпјҢWX4G2гҖҒWX4G3зӯүзӯүпјҢжҜҸдёҖдёӘеӯ—з¬ҰдёІд»ЈиЎЁдәҶжҹҗдёҖзҹ©еҪўеҢәеҹҹгҖӮд№ҹе°ұжҳҜиҜҙпјҢиҝҷдёӘзҹ©еҪўеҢәеҹҹеҶ…жүҖжңүзҡ„зӮ№пјҲз»Ҹзә¬еәҰеқҗж ҮпјүйғҪе…ұдә«зӣёеҗҢзҡ„GeoHashеӯ—з¬ҰдёІпјҢиҝҷж ·ж—ўеҸҜд»ҘдҝқжҠӨйҡҗз§ҒпјҲеҸӘиЎЁзӨәеӨ§жҰӮеҢәеҹҹдҪҚзҪ®иҖҢдёҚжҳҜе…·дҪ“зҡ„зӮ№пјүпјҢеҸҲжҜ”иҫғе®№жҳ“еҒҡзј“еӯҳпјҢжҜ”еҰӮе·ҰдёҠи§’иҝҷдёӘеҢәеҹҹеҶ…зҡ„з”ЁжҲ·дёҚж–ӯеҸ‘йҖҒдҪҚзҪ®дҝЎжҒҜиҜ·жұӮйӨҗйҰҶж•°жҚ®пјҢз”ұдәҺиҝҷдәӣз”ЁжҲ·зҡ„GeoHashеӯ—з¬ҰдёІйғҪжҳҜWX4ERпјҢжүҖд»ҘеҸҜд»ҘжҠҠWX4ERеҪ“дҪңkeyпјҢжҠҠиҜҘеҢәеҹҹзҡ„йӨҗйҰҶдҝЎжҒҜеҪ“дҪңvalueжқҘиҝӣиЎҢзј“еӯҳпјҢиҖҢеҰӮжһңдёҚдҪҝз”ЁGeoHashзҡ„иҜқпјҢз”ұдәҺеҢәеҹҹеҶ…зҡ„з”ЁжҲ·дј жқҘзҡ„з»Ҹзә¬еәҰжҳҜеҗ„дёҚзӣёеҗҢзҡ„пјҢеҫҲйҡҫеҒҡзј“еӯҳгҖӮ
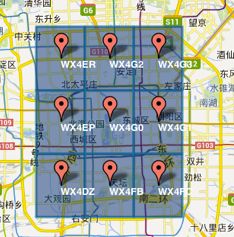
еӯ—з¬ҰдёІи¶Ҡй•ҝпјҢиЎЁзӨәзҡ„иҢғеӣҙи¶ҠзІҫзЎ®гҖӮеҰӮеӣҫжүҖзӨәпјҢ5дҪҚзҡ„зј–з ҒиғҪиЎЁзӨә10е№іж–№еҚғзұіиҢғеӣҙзҡ„зҹ©еҪўеҢәеҹҹпјҢиҖҢ6дҪҚзј–з ҒиғҪиЎЁзӨәжӣҙзІҫз»Ҷзҡ„еҢәеҹҹпјҲзәҰ0.34е№іж–№еҚғзұіпјү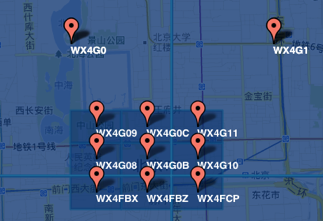
еӯ—з¬ҰдёІзӣёдјјзҡ„иЎЁзӨәи·қзҰ»зӣёиҝ‘пјҲзү№ж®Ҡжғ…еҶөеҗҺж–Үйҳҗиҝ°пјүпјҢиҝҷж ·еҸҜд»ҘеҲ©з”Ёеӯ—з¬ҰдёІзҡ„еүҚзјҖеҢ№й…ҚжқҘжҹҘиҜўйҷ„иҝ‘зҡ„POIдҝЎжҒҜгҖӮеҰӮдёӢдёӨдёӘеӣҫжүҖзӨәпјҢ第дёҖдёӘеңЁеҹҺеҢәпјҢ第дәҢдёӘеңЁйғҠеҢәпјҢеҹҺеҢәзҡ„GeoHashеӯ—з¬ҰдёІд№Ӣй—ҙжҜ”иҫғзӣёдјјпјҢйғҠеҢәзҡ„еӯ—з¬ҰдёІд№Ӣй—ҙд№ҹжҜ”иҫғзӣёдјјпјҢиҖҢеҹҺеҢәе’ҢйғҠеҢәзҡ„GeoHashеӯ—з¬ҰдёІзӣёдјјзЁӢеәҰиҰҒдҪҺдәӣгҖӮ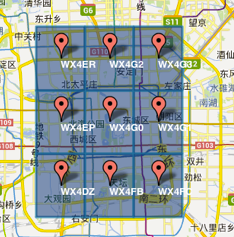
йҖҡиҝҮдёҠйқўзҡ„д»Ӣз»ҚжҲ‘们зҹҘйҒ“дәҶGeoHashе°ұжҳҜдёҖз§Қе°Ҷз»Ҹзә¬еәҰиҪ¬жҚўжҲҗеӯ—з¬ҰдёІзҡ„ж–№жі•пјҢ并且дҪҝеҫ—еңЁеӨ§йғЁеҲҶжғ…еҶөдёӢпјҢеӯ—з¬ҰдёІеүҚзјҖеҢ№й…Қи¶ҠеӨҡзҡ„и·қзҰ»и¶Ҡиҝ‘пјҢеӣһеҲ°жҲ‘们зҡ„жЎҲдҫӢпјҢж №жҚ®жүҖеңЁдҪҚзҪ®жҹҘиҜўжқҘжҹҘиҜўйҷ„иҝ‘йӨҗйҰҶж—¶пјҢеҸӘйңҖиҰҒе°ҶжүҖеңЁдҪҚзҪ®з»Ҹзә¬еәҰиҪ¬жҚўжҲҗGeoHashеӯ—з¬ҰдёІпјҢ并дёҺеҗ„дёӘйӨҗйҰҶзҡ„GeoHashеӯ—з¬ҰдёІиҝӣиЎҢеүҚзјҖеҢ№й…ҚпјҢеҢ№й…Қи¶ҠеӨҡзҡ„и·қзҰ»и¶Ҡиҝ‘гҖӮ
4. GeoHashз®—жі•зҡ„жӯҘйӘӨ
дёӢйқўд»ҘеҢ—жө·е…¬еӣӯйҷ„иҝ‘йҡҸдҫҝдёҖдёӘдҪҚзҪ®дёәдҫӢд»Ӣз»ҚGeoHashз®—жі•зҡ„и®Ўз®—жӯҘйӘӨ,е…Ҳз”ЁзҷҫеәҰ GPSеҸҚе®ҡдҪҚзі»з»ҹжҹҘжүҫзңӢдёӢз»Ҹзә¬еәҰгҖӮ
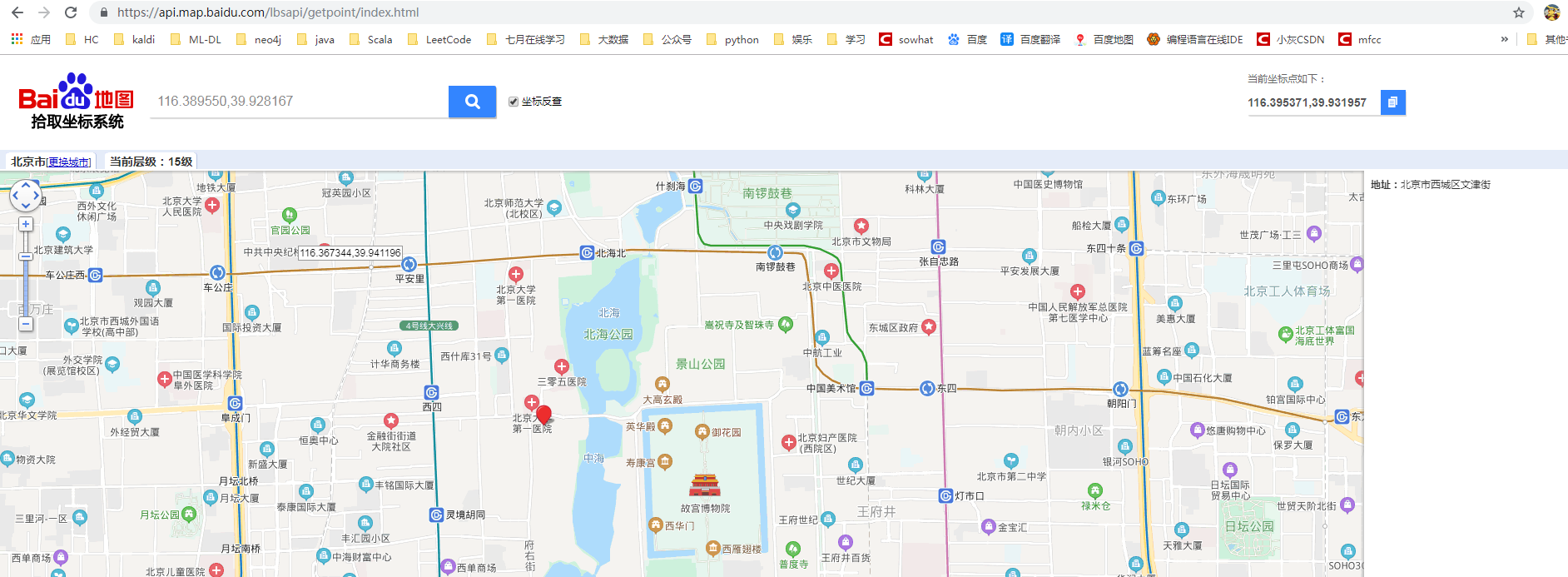
зә¬еәҰ=116.395371пјҢз»ҸеәҰ=39.931957гҖӮ
ж №жҚ®з»Ҹзә¬еәҰи®Ўз®—GeoHashдәҢиҝӣеҲ¶зј–з Ғ
ең°зҗғзә¬еәҰеҢәй—ҙжҳҜ[-90,90]пјҢ еҢ—жө·е…¬еӣӯзҡ„зә¬еәҰжҳҜ39.928167пјҢеҸҜд»ҘйҖҡиҝҮдёӢйқўз®—жі•еҜ№зә¬еәҰ39.928167иҝӣиЎҢйҖјиҝ‘зј–з Ғ:
еҢәй—ҙ[-90,90]иҝӣиЎҢдәҢеҲҶдёә[-90,0),[0,90]пјҢз§°дёәе·ҰеҸіеҢәй—ҙпјҢеҸҜд»ҘзЎ®е®ҡ39.928167еұһдәҺеҸіеҢәй—ҙ[0,90]пјҢз»ҷж Үи®°дёә1пјӣ
жҺҘзқҖе°ҶеҢәй—ҙ[0,90]иҝӣиЎҢдәҢеҲҶдёә [0,45),[45,90]пјҢеҸҜд»ҘзЎ®е®ҡ39.928167еұһдәҺе·ҰеҢәй—ҙ [0,45)пјҢз»ҷж Үи®°дёә0пјӣ
йҖ’еҪ’дёҠиҝ°иҝҮзЁӢ39.928167жҖ»жҳҜеұһдәҺжҹҗдёӘеҢәй—ҙ[a,b]гҖӮйҡҸзқҖжҜҸж¬Ўиҝӯд»ЈеҢәй—ҙ[a,b]жҖ»еңЁзј©е°ҸпјҢ并и¶ҠжқҘи¶ҠйҖјиҝ‘39.928167пјӣ
еҰӮжһңз»ҷе®ҡзҡ„зә¬еәҰxпјҲ39.928167пјүеұһдәҺе·ҰеҢәй—ҙпјҢеҲҷи®°еҪ•0пјҢеҰӮжһңеұһдәҺеҸіеҢәй—ҙеҲҷи®°еҪ•1пјҢиҝҷж ·йҡҸзқҖз®—жі•зҡ„иҝӣиЎҢдјҡдә§з”ҹдёҖдёӘеәҸеҲ—1011100пјҢеәҸеҲ—зҡ„й•ҝеәҰи·ҹз»ҷе®ҡзҡ„еҢәй—ҙеҲ’еҲҶж¬Ўж•°жңүе…ігҖӮ
39.928167 ж №жҚ®зә¬еәҰз®—зј–з Ғ
| bit | min | mid | max |
|---|
| 1 | -90.000 | 0.000 | 90.000 |
| 0 | 0.000 | 45.000 | 90.000 |
| 1 | 0.000 | 22.500 | 45.000 |
| 1 | 22.500 | 33.750 | 45.000 |
| 1 | 33.750 | 39.375 | 45.000 |
| 0 | 39.375 | 42.188 | 45.000 |
| 0 | 39.375 | 40.7815 | 42.188 |
| 0 | 39.375 | 40.07825 | 40.7815 |
| 1 | 39.375 | 39.726625 | 40.07825 |
| 1 | 39.726625 | 39.9024375 | 40.07825 |
еҗҢзҗҶпјҢең°зҗғз»ҸеәҰеҢәй—ҙжҳҜ[-180,180]пјҢеҸҜд»ҘеҜ№з»ҸеәҰ116.389550иҝӣиЎҢзј–з ҒгҖӮж №жҚ®з»ҸеәҰз®—зј–з Ғ
| bit | min | mid | max |
|---|
| 1 | -180 | 0.000 | 180 |
| 1 | 0.000 | 90 | 180 |
| 0 | 90 | 135 | 180 |
| 1 | 90 | 112.5 | 135 |
| 0 | 112.5 | 123.75 | 135 |
| 0 | 112.5 | 118.125 | 123.75 |
| 1 | 112.5 | 115.3125 | 118.125 |
| 0 | 115.3125 | 116.71875 | 118.125 |
| 1 | 115.3125 | 116.015625 | 116.71875 |
| 1 | 116.015625 | 116.3671875 | 116.71875 |
з»„з Ғ
йҖҡиҝҮдёҠиҝ°и®Ўз®—пјҢзә¬еәҰдә§з”ҹзҡ„зј–з Ғдёә10111 00011пјҢз»ҸеәҰдә§з”ҹзҡ„зј–з Ғдёә11010 01011гҖӮеҒ¶ж•°дҪҚж”ҫз»ҸеәҰпјҢеҘҮж•°дҪҚж”ҫзә¬еәҰпјҢжҠҠ2дёІзј–з Ғз»„еҗҲз”ҹжҲҗж–°дёІпјҡ11100 11101 00100 01111гҖӮ
жңҖеҗҺдҪҝз”Ёз”Ё0-9гҖҒb-zпјҲеҺ»жҺүa, i, l, oпјүиҝҷ32дёӘеӯ—жҜҚиҝӣиЎҢbase32зј–з ҒпјҢйҰ–е…Ҳе°Ҷ11100 11101 00100 01111иҪ¬жҲҗеҚҒиҝӣеҲ¶пјҢеҜ№еә”зқҖ28гҖҒ29гҖҒ4гҖҒ15пјҢеҚҒиҝӣеҲ¶еҜ№еә”зҡ„зј–з Ғе°ұжҳҜwx4gгҖӮеҗҢзҗҶпјҢе°Ҷзј–з ҒиҪ¬жҚўжҲҗз»Ҹзә¬еәҰзҡ„и§Јз Ғз®—жі•дёҺд№ӢзӣёеҸҚпјҢе…·дҪ“дёҚеҶҚиөҳиҝ°гҖӮ
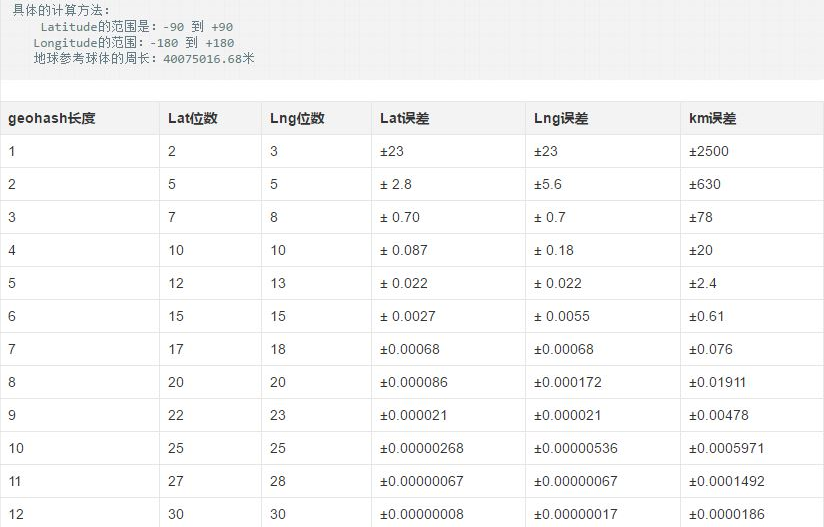
5. GeoHash Base32зј–з Ғй•ҝеәҰдёҺзІҫеәҰ
еҸҜд»ҘзңӢеҮәпјҢеҪ“geohash base32зј–з Ғй•ҝеәҰдёә8ж—¶пјҢзІҫеәҰеңЁ19зұіе·ҰеҸіпјҢиҖҢеҪ“зј–з Ғй•ҝеәҰдёә9ж—¶пјҢзІҫеәҰеңЁ2зұіе·ҰеҸіпјҢзј–з Ғй•ҝеәҰйңҖиҰҒж №жҚ®ж•°жҚ®жғ…еҶөиҝӣиЎҢйҖүжӢ©гҖӮ
дёҖгҖҒз»Ҹзә¬еәҰи·қзҰ»жҚўз®—
еңЁзә¬еәҰзӣёзӯүзҡ„жғ…еҶөдёӢпјҡ
з»ҸеәҰжҜҸйҡ”0.00001еәҰпјҢи·қзҰ»зӣёе·®зәҰ1зұіпјӣ
жҜҸйҡ”0.0001еәҰпјҢи·қзҰ»зӣёе·®зәҰ10зұіпјӣ
жҜҸйҡ”0.001еәҰпјҢи·қзҰ»зӣёе·®зәҰ100зұіпјӣ
жҜҸйҡ”0.01еәҰпјҢи·қзҰ»зӣёе·®зәҰ1000зұіпјӣ
жҜҸйҡ”0.1еәҰпјҢи·қзҰ»зӣёе·®зәҰ10000зұігҖӮ
еңЁз»ҸеәҰзӣёзӯүзҡ„жғ…еҶөдёӢпјҡ
зә¬еәҰжҜҸйҡ”0.00001еәҰпјҢи·қзҰ»зӣёе·®зәҰ1.1зұіпјӣ
жҜҸйҡ”0.0001еәҰпјҢи·қзҰ»зӣёе·®зәҰ11зұіпјӣ
жҜҸйҡ”0.001еәҰпјҢи·қзҰ»зӣёе·®зәҰ111зұіпјӣ
жҜҸйҡ”0.01еәҰпјҢи·қзҰ»зӣёе·®зәҰ1113зұіпјӣ
жҜҸйҡ”0.1еәҰпјҢи·қзҰ»зӣёе·®зәҰ11132зұігҖӮ
6. GeoHashз®—жі•
дёҠж–Үи®ІдәҶGeoHashзҡ„и®Ўз®—жӯҘйӘӨпјҢд»…д»…иҜҙжҳҺжҳҜд»Җд№ҲиҖҢжІЎжңүиҜҙжҳҺдёәд»Җд№Ҳпјҹдёәд»Җд№ҲеҲҶеҲ«з»ҷз»ҸеәҰе’Ңз»ҙеәҰзј–з Ғпјҹдёәд»Җд№ҲйңҖиҰҒе°Ҷз»Ҹзә¬еәҰдёӨдёІзј–з ҒдәӨеҸүз»„еҗҲжҲҗдёҖдёІзј–з Ғпјҹжң¬иҠӮиҜ•еӣҫеӣһзӯ”иҝҷдёҖй—®йўҳгҖӮ
еҰӮдёӢеӣҫжүҖзӨәпјҢжҲ‘们е°ҶдәҢиҝӣеҲ¶зј–з Ғзҡ„з»“жһңеЎ«еҶҷеҲ°з©әй—ҙдёӯпјҢеҪ“е°Ҷз©әй—ҙеҲ’еҲҶдёәеӣӣеқ—ж—¶еҖҷпјҢзј–з Ғзҡ„йЎәеәҸеҲҶеҲ«жҳҜе·ҰдёӢи§’00пјҢе·ҰдёҠи§’01пјҢеҸідёӢи„ҡ10пјҢеҸідёҠи§’11пјҢд№ҹе°ұжҳҜзұ»дјјдәҺZзҡ„жӣІзәҝпјҢеҪ“жҲ‘们йҖ’еҪ’зҡ„е°Ҷеҗ„дёӘеқ—еҲҶи§ЈжҲҗжӣҙе°Ҹзҡ„еӯҗеқ—ж—¶пјҢзј–з Ғзҡ„йЎәеәҸжҳҜиҮӘзӣёдјјзҡ„пјҲеҲҶеҪўпјүпјҢжҜҸдёҖдёӘеӯҗеҝ«д№ҹеҪўжҲҗZжӣІзәҝпјҢиҝҷз§Қзұ»еһӢзҡ„жӣІзәҝиў«з§°дёәPeanoз©әй—ҙеЎ«е……жӣІзәҝгҖӮ
иҝҷз§Қзұ»еһӢзҡ„з©әй—ҙеЎ«е……жӣІзәҝзҡ„дјҳзӮ№жҳҜе°ҶдәҢз»ҙз©әй—ҙиҪ¬жҚўжҲҗдёҖз»ҙжӣІзәҝпјҲдәӢе®һдёҠжҳҜеҲҶеҪўз»ҙпјүпјҢеҜ№еӨ§йғЁеҲҶиҖҢиЁҖпјҢзј–з Ғзӣёдјјзҡ„и·қзҰ»д№ҹзӣёиҝ‘пјҢ дҪҶPeanoз©әй—ҙеЎ«е……жӣІзәҝжңҖеӨ§зҡ„зјәзӮ№е°ұжҳҜзӘҒеҸҳжҖ§пјҢжңүдәӣзј–з ҒзӣёйӮ»дҪҶи·қзҰ»еҚҙзӣёе·®еҫҲиҝңпјҢжҜ”еҰӮ0111дёҺ1000пјҢзј–з ҒжҳҜзӣёйӮ»зҡ„пјҢдҪҶи·қзҰ»зӣёе·®еҫҲеӨ§гҖӮ
гҖҖгҖҖ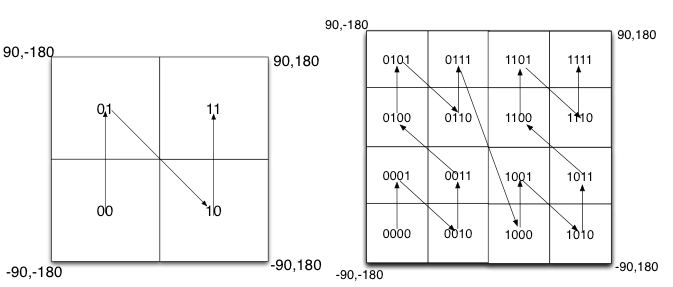
йҷӨPeanoз©әй—ҙеЎ«е……жӣІзәҝеӨ–пјҢиҝҳжңүеҫҲеӨҡз©әй—ҙеЎ«е……жӣІзәҝпјҢеҰӮеӣҫжүҖзӨәпјҢе…¶дёӯж•Ҳжһңе…¬и®ӨиҫғеҘҪжҳҜHilbertз©әй—ҙеЎ«е……жӣІзәҝпјҢзӣёиҫғдәҺPeanoжӣІзәҝиҖҢиЁҖпјҢHilbertжӣІзәҝжІЎжңүиҫғеӨ§зҡ„зӘҒеҸҳгҖӮдёәд»Җд№ҲGeoHashдёҚйҖүжӢ©Hilbertз©әй—ҙеЎ«е……жӣІзәҝе‘ўпјҹеҸҜиғҪжҳҜPeanoжӣІзәҝжҖқи·Ҝд»ҘеҸҠи®Ўз®—дёҠжҜ”иҫғз®ҖеҚ•еҗ§пјҢдәӢе®һдёҠпјҢPeanoжӣІзәҝе°ұжҳҜдёҖз§ҚеӣӣеҸүж ‘зәҝжҖ§зј–з Ғж–№ејҸгҖӮ

7. дҪҝз”ЁжіЁж„ҸзӮ№
1. дёҙз•Ңй—®йўҳ
з”ұдәҺGeoHashжҳҜе°ҶеҢәеҹҹеҲ’еҲҶдёәдёҖдёӘдёӘ规еҲҷзҹ©еҪўпјҢ并еҜ№жҜҸдёӘзҹ©еҪўиҝӣиЎҢзј–з ҒпјҢиҝҷж ·еңЁжҹҘиҜўйҷ„иҝ‘POIдҝЎжҒҜж—¶дјҡеҜјиҮҙд»ҘдёӢй—®йўҳпјҢжҜ”еҰӮзәўиүІзҡ„зӮ№жҳҜжҲ‘们зҡ„дҪҚзҪ®пјҢз»ҝиүІзҡ„дёӨдёӘзӮ№еҲҶеҲ«жҳҜйҷ„иҝ‘зҡ„дёӨдёӘйӨҗйҰҶпјҢдҪҶжҳҜеңЁжҹҘиҜўзҡ„ж—¶еҖҷдјҡеҸ‘зҺ°и·қзҰ»иҫғиҝңйӨҗйҰҶзҡ„GeoHashзј–з ҒдёҺжҲ‘们дёҖж ·пјҲеӣ дёәеңЁеҗҢдёҖдёӘGeoHashеҢәеҹҹеқ—дёҠпјүпјҢиҖҢиҫғиҝ‘йӨҗйҰҶзҡ„GeoHashзј–з ҒдёҺжҲ‘们дёҚдёҖиҮҙгҖӮиҝҷдёӘй—®йўҳеҫҖеҫҖдә§з”ҹеңЁиҫ№з•ҢеӨ„гҖӮ
и§ЈеҶізҡ„жҖқи·ҜеҫҲз®ҖеҚ•пјҢжҲ‘们жҹҘиҜўж—¶пјҢйҷӨдәҶдҪҝз”Ёе®ҡдҪҚзӮ№зҡ„GeoHashзј–з ҒиҝӣиЎҢеҢ№й…ҚеӨ–пјҢиҝҳдҪҝз”Ёе‘Ёеӣҙ8дёӘеҢәеҹҹзҡ„GeoHashзј–з ҒпјҢиҝҷж ·еҸҜд»ҘйҒҝе…ҚиҝҷдёӘй—®йўҳгҖӮ
2. жіЁж„ҸзӮ№
жҲ‘们已з»ҸзҹҘйҒ“зҺ°жңүзҡ„GeoHashз®—жі•дҪҝз”Ёзҡ„жҳҜPeanoз©әй—ҙеЎ«е……жӣІзәҝпјҢиҝҷз§ҚжӣІзәҝдјҡдә§з”ҹзӘҒеҸҳпјҢйҖ жҲҗдәҶзј–з ҒиҷҪ然зӣёдјјдҪҶи·қзҰ»еҸҜиғҪзӣёе·®еҫҲеӨ§зҡ„й—®йўҳпјҢеӣ жӯӨеңЁжҹҘиҜўйҷ„иҝ‘йӨҗйҰҶж—¶еҖҷпјҢйҰ–е…ҲзӯӣйҖүGeoHashзј–з Ғзӣёдјјзҡ„POI(point of interest)зӮ№пјҢ然еҗҺиҝӣиЎҢе®һйҷ…и·қзҰ»и®Ўз®—гҖӮ
3. дҪҝз”Ёеҝғеҫ—
GeoHashеҸӘжҳҜз©әй—ҙзҙўеј•зҡ„дёҖз§Қж–№ејҸпјҢзү№еҲ«йҖӮеҗҲзӮ№ж•°жҚ®пјҢиҖҢеҜ№зәҝгҖҒйқўж•°жҚ®йҮҮз”ЁRж ‘зҙўеј•жӣҙжңүдјҳеҠҝпјҲеҸҜдёәд»Җд№ҲйңҖиҰҒз©әй—ҙзҙўеј•пјүгҖӮ
GeoHashеҖјеҸҜд»ҘеҢәеҲҶзІҫеәҰпјҢдҪҚж•°и¶ҠеӨҡпјҢзІҫеәҰи¶Ҡй«ҳпјҢиЎЁиҫҫзҡ„ең°зҗҶдҪҚзҪ®и¶ҠзІҫз»ҶпјӣеҰӮдёҖдҪҚзҡ„GeoHashеҖјжҠҠең°зҗғеҲ’еҲҶдёә32дёӘзҹ©еҪўпјҢ8дҪҚзҡ„geohashеҖјжҠҠең°зҗғеҲ’еҲҶдёә32^8дёӘе°Ҹзҹ©еҪў
йҖӮеҗҲж №жҚ®жҹҗдёӘз»Ҹзә¬еәҰеқҗж Үpositionи®Ўз®—еҮәGeoHashеҖјпјҢ然еҗҺе’Ңж•°жҚ®еә“дёӯзІҫеәҰжӣҙй«ҳзҡ„GeoHashеҖјеҒҡеүҚзјҖжҜ”иҫғ
8.з©әй—ҙзҙўеј•
еёёи§Ғй—®йўҳпјҡеҰӮдҪ•ж №жҚ®иҮӘе·ұжүҖеңЁдҪҚзҪ®жҹҘиҜўжқҘжҹҘиҜўйҷ„иҝ‘50зұізҡ„POIпјҲpoint of interestпјҢжҜ”еҰӮе•Ҷ家гҖҒжҷҜзӮ№зӯүпјүе‘ўпјҲеӣҫ1aпјүпјҹ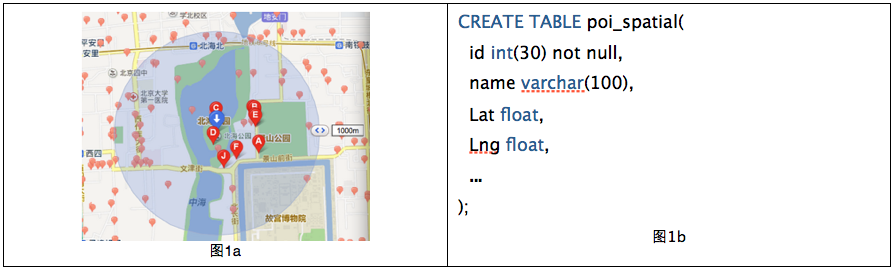
жҜҸдёӘPOIйғҪжңүз»Ҹзә¬еәҰдҝЎжҒҜпјҢз”Ёеӣҫ1bзҡ„SQLиҜӯеҸҘеңЁmySQLдёӯе»әз«ӢдәҶPOI_spatialзҡ„иЎЁпјҢе…¶дёӯlatе’ҢlngдёӨдёӘеӯ—ж®өжқҘд»ЈиЎЁзә¬еәҰе’Ңз»ҸеәҰгҖӮдёәеҗҺз»ӯеҲҶжһҗж–№дҫҝиө·и§ҒпјҢжҲ‘дәәйҖ дәҶ40дёҮдёӘPOIж•°жҚ®гҖӮ
ж–№жі•дёҖпјҡжҡҙеҠӣж–№жі•
иҜҘж–№жі•зҡ„жҖқи·ҜеҫҲзӣҙжҺҘпјҡи®Ўз®—дҪҚзҪ®дёҺжүҖжңүPOIзҡ„и·қзҰ»пјҢ并дҝқз•ҷи·қзҰ»е°ҸдәҺ50зұізҡ„POIгҖӮ
жҸ’еҸҘйўҳеӨ–иҜқпјҢи®Ўз®—з»Ҹзә¬еәҰд№Ӣй—ҙзҡ„и·қзҰ»дёҚиғҪеғҸжұӮ欧ејҸи·қзҰ»йӮЈж ·е№іж–№ејҖж №еҸ·пјҢеӣ дёәең°зҗғжҳҜдёӘдёҚ规ж•ҙзҡ„зҗғдҪ“пјҲеӣҫ2aпјүпјҢжҷ®йҖҡи®Ўз®—йҖӮеҗҲйғҪжҳҜй»ҳи®ӨжҢүжңҖз®ҖеҚ•зҡ„е®ҢзҫҺзҗғдҪ“еҒҮи®ҫпјҢдёӨзӮ№д№Ӣй—ҙзҡ„и·қзҰ»еҮҪж•°еә”иҜҘеҰӮеӣҫ2bжүҖзӨәгҖӮ

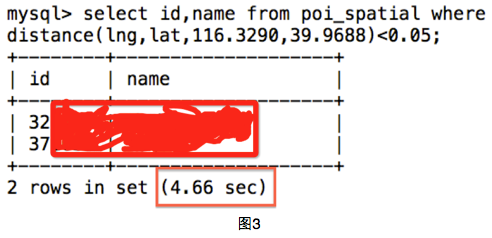
иҜҘж–№жі•зҡ„еӨҚжқӮеәҰдёәпјҡ40дёҮ*и·қзҰ»еҮҪж•°гҖӮжҲ‘们е°ҶзҗғдҪ“и·қзҰ»еҮҪж•°еҶҷдёәmysqlеӯҳеӮЁиҝҮзЁӢdistanceпјҢд№ӢеҗҺжҲ‘们жү§иЎҢжҹҘиҜўж“ҚдҪңпјҲеӣҫ3пјүпјҢеҸ‘зҺ°иҠұиҙ№дәҶ4.66з§’гҖӮ
ж–№жі•дәҢпјҡзҹ©еҪўиҝҮж»Өж–№жі•
иҜҘж–№жі•йҮҮз”ЁйҖҗжӯҘз»ҶеҢ–зҡ„ж–№ејҸпјҢдёҖиҲ¬еҲҶдёәдёӨйғЁпјҡ
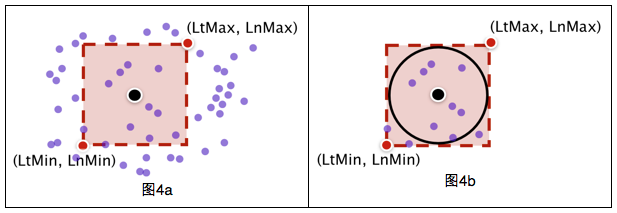
е…Ҳз”Ёзҹ©еҪўжЎҶиҝҮж»ӨпјҲеӣҫ4aпјүпјҢеҲӨж–ӯдёҖдёӘзӮ№еңЁзҹ©еҪўжЎҶеҶ…еҫҲз®ҖеҚ•пјҢеҸӘиҰҒиҝӣиЎҢдёӨж¬ЎеҲӨж–ӯпјҲLtMin<lat<LtMax; LnMin<lng<LnMaxпјүпјҢиҗҪеңЁзҹ©еҪўжЎҶеҶ…зҡ„POIдёӘж•°дёәnпјҲn<<40дёҮпјүпјӣ
з”Ёзҗғйқўи·қзҰ»е…¬ејҸи®Ўз®—дҪҚзҪ®дёҺзҹ©еҪўжЎҶеҶ…nдёӘPOIзҡ„и·қзҰ»пјҲеӣҫ4bпјүпјҢ并дҝқз•ҷи·қзҰ»е°ҸдәҺ50зұізҡ„POI
зҹ©еҪўиҝҮж»Өж–№жі•зҡ„еӨҚжқӮеәҰпјҡ40дёҮзҹ©еҪўиҝҮж»ӨеҮҪж•° + nи·қзҰ»еҮҪж•°пјҲn<<40дёҮпјүгҖӮ
гҖҖж №жҚ®иҝҷдёӘжҖқи·ҜжҲ‘们жү§иЎҢSQlжҹҘиҜўпјҲеӣҫ5пјүпјҲжіЁпјҡ з»ҸеәҰжҲ–зә¬еәҰжҜҸйҡ”0.001еәҰпјҢи·қзҰ»зӣёе·®зәҰ100зұіпјҢз”ұжӯӨжҺЁз®—еҮәзҹ©еҪўе·ҰдёӢи§’е’ҢеҸідёҠи§’еқҗж ҮпјүпјҢеҸ‘зҺ°иҝҮж»ӨеҗҺжӯЈеҘҪеү©дёӢдёӨдёӘPOIгҖӮ
жӯӨжҹҘиҜўиҠұиҙ№дәҶ0.36з§’пјҢзӣёжҜ”дәҺж–№жі•дёҖжҹҘиҜўж—¶й—ҙеӨ§еӨ§йҷҚдҪҺпјҢдҪҶжҳҜеҜ№дәҺдёҖж¬ЎжҹҘиҜўжқҘиҜҙиҝҳжҳҜеҫҲй•ҝгҖӮж—¶й—ҙй•ҝзҡ„еҺҹеӣ еңЁдәҺйҒҚеҺҶдәҶ40дёҮж¬ЎгҖӮ

ж–№жі•дёүпјҡBж ‘еҜ№з»ҸеәҰжҲ–зә¬еәҰе»әз«Ӣзҙўеј•
ж–№жі•дәҢиҖ—ж—¶зҡ„еҺҹеӣ еңЁдәҺжү§иЎҢдәҶйҒҚеҺҶж“ҚдҪңпјҢдёәдәҶдёҚиҝӣиЎҢйҒҚеҺҶпјҢжҲ‘们иҮӘ然жғіеҲ°дәҶзҙўеј•гҖӮжҲ‘们еҜ№зә¬еәҰиҝӣиЎҢдәҶBж ‘зҙўеј•гҖӮ
alter table poi_spatial add index latindex(lat);alter table poi_spatial add index lngindex(lng);
жӯӨж–№жі•еҢ…жӢ¬дёүдёӘжӯҘйӘӨпјҡ
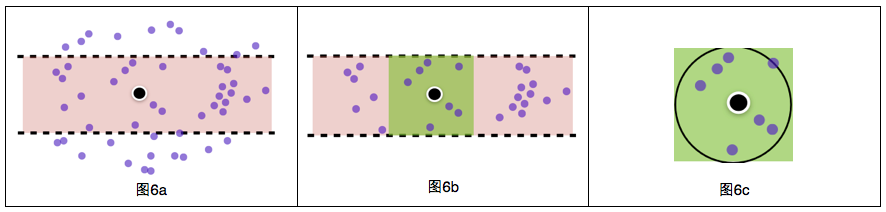
йҖҡиҝҮBж ‘еҝ«йҖҹжүҫеҲ°жҹҗзә¬еәҰиҢғеӣҙзҡ„POIпјҲеӣҫ6aпјүпјҢдёӘж•°дёәmпјҲm<40дёҮпјүпјҢеӨҚжқӮеәҰдёәLog(40дёҮ)*иҝҮж»ӨеҮҪж•°;
еңЁжӯҘйӘӨaиҝҮж»Өеҫ—еҲ°зҡ„mдёӘPOIдёӯжҹҘжүҫжҹҗз»ҸеәҰиҢғеӣҙзҡ„POIпјҲеӣҫ6bпјүпјҢдёӘж•°дёәn(n<m)пјҢеӨҚжқӮеәҰдёәm*иҝҮж»ӨеҮҪж•°пјӣ
з”Ёзҗғйқўи·қзҰ»е…¬ејҸи®Ўз®—дҪҚзҪ®дёҺжӯҘйӘӨbеҫ—еҲ°зҡ„nдёӘPOIзҡ„и·қзҰ»пјҲеӣҫ6cпјүпјҢ并дҝқз•ҷи·қзҰ»е°ҸдәҺ50зұізҡ„POI
жү§иЎҢSQLжҹҘиҜўпјҲеӣҫ7пјүпјҢеҸ‘зҺ°ж—¶й—ҙе·Із»ҸеӨ§еӨ§йҷҚдҪҺпјҢд»Һж–№жі•2зҡ„0.36з§’дёӢйҷҚеҲ°0.01з§’

дёүгҖҒBж ‘иғҪзҙўеј•з©әй—ҙж•°жҚ®еҗ—пјҹ
иҝҷж—¶еҖҷжңүдәәдјҡиҜҙдәҶпјҡж–№жі•дёүж•ҲжһңеҰӮжӯӨеҘҪпјҢиғҪеӨҹж»Ўи¶іжҲ‘们йҷ„иҝ‘POIжҹҘиҜўй—®йўҳе•ҠпјҢзңӢжқҘBж ‘з”ЁжқҘзҙўеј•з©әй—ҙж•°жҚ®д№ҹжҳҜеҸҜд»Ҙзҡ„еҳӣпјҒ
йӮЈд№ҲBж ‘зңҹзҡ„иғҪеӨҹзҙўеј•з©әй—ҙж•°жҚ®еҗ—пјҹ
еҸӘиғҪеҜ№з»ҸеәҰжҲ–зә¬еәҰзҙўеј•пјҲдёҖз»ҙзҙўеј•пјүпјҢдёҺжңҹжңӣзҡ„дёҚз¬Ұ
жҲ‘们жңҹеҫ…зҡ„жҳҜеҝ«йҖҹжүҫеҮәиҗҪеңЁжҹҗдёҖз©әй—ҙиҢғеӣҙзҡ„POIпјҲеҰӮзҹ©еҪўпјүпјҲеӣҫ8aпјүпјҢиҖҢдёҚжҳҜеҝ«йҖҹжүҫеҮәиҗҪеңЁжҹҗзә¬еәҰжҲ–з»ҸеәҰиҢғеӣҙзҡ„POIпјҲеӣҫ8bпјүпјҢжғіиұЎдёҖдёӢпјҢжҲ‘иҰҒжҹҘиҜўеҢ—дә¬жҹҗеҢәзҡ„POIпјҢдҪҶжҳҜBж ‘зҙўеј•дёҚд»…з»ҷжҲ‘жүҫеҮәдәҶеҢ—дә¬зҡ„пјҢиҝҳжңүдёҺеҢ—дә¬еҗҢдёҖз»ҙеәҰзҡ„еӨ©жҙҘгҖҒеӨ§еҗҢгҖҒз”ҡиҮіеӣҪеӨ–еҹҺеёӮзҡ„POIпјҢеҪ“ж•°жҚ®йҮҸеҫҲеӨ§ж—¶пјҢж•ҲзҺҮеҫҲдҪҺгҖӮ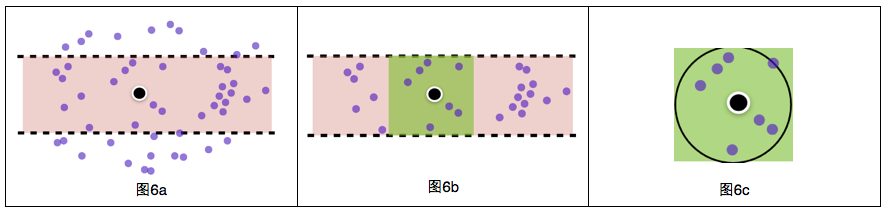
еҪ“ж•°жҚ®жҳҜеӨҡз»ҙпјҢжҜ”еҰӮдёүз»ҙпјҲxпјҢyпјҢzпјүпјҢBж ‘жҖҺд№Ҳзҙўеј•пјҹ
жҜ”еҰӮzеҸҜиғҪжҳҜй«ҳзЁӢеҖјпјҢд№ҹеҸҜиғҪжҳҜж—¶й—ҙгҖӮжңүдәәдјҡиҜҙBж ‘е…¶е®һеҸҜд»ҘеҜ№еӨҡдёӘеӯ—ж®өиҝӣиЎҢзҙўеј•пјҢдҪҶиҝҷж—¶йңҖиҰҒжҢҮе®ҡдјҳе…Ҳзә§пјҢеҪўжҲҗдёҖдёӘз»„еҗҲеӯ—ж®өпјҢиҖҢз©әй—ҙж•°жҚ®еңЁеҗ„дёӘз»ҙеәҰж–№еҗ‘дёҠдёҚеӯҳеңЁдјҳе…Ҳзә§пјҢжҲ‘们дёҚиғҪиҜҙзә¬еәҰжҜ”з»ҸеәҰжӣҙйҮҚиҰҒпјҢд№ҹдёҚиғҪиҜҙзә¬еәҰжҜ”й«ҳзЁӢжӣҙйҮҚиҰҒгҖӮ
еҪ“з©әй—ҙж•°жҚ®дёҚжҳҜзӮ№пјҢиҖҢжҳҜзәҝпјҲйҒ“и·ҜгҖҒең°й“ҒгҖҒжІіжөҒзӯүпјүпјҢйқўпјҲиЎҢж”ҝеҢәиҫ№з•ҢгҖҒе»әзӯ‘зү©зӯүпјүпјҢBж ‘жҖҺд№Ҳзҙўеј•пјҹ
еҜ№дәҺйқўжқҘиҜҙпјҢе®ғз”ұдёҖзі»еҲ—йҰ–е°ҫзӣёиҝһзҡ„з»Ҹзә¬еәҰеқҗж ҮзӮ№з»„жҲҗпјҢдёҖдёӘйқўеҸҜиғҪжңүжҲҗзҷҫдёҠеҚғдёӘеқҗж ҮпјҢиҝҷж—¶ж•°жҚ®еә“жҖҺд№ҲеӯҳеӮЁпјҢBж ‘жҖҺд№Ҳзҙўеј•пјҢиҝҷдәӣйғҪжҳҜй—®йўҳгҖӮ
ж—ўз„¶дј з»ҹзҡ„зҙўеј•дёҚиғҪеҫҲеҘҪзҡ„зҙўеј•з©әй—ҙж•°жҚ®пјҢжҲ‘们иҮӘ然йңҖиҰҒдёҖз§Қж–№жі•иғҪеҜ№з©әй—ҙж•°жҚ®иҝӣиЎҢзҙўеј•пјҢеҚіз©әй—ҙзҙўеј•гҖӮ
9.е®һжҲҳ
SpringBoot + Redis е®һзҺ°geoж“ҚдҪңгҖӮ
и°ғз”ЁJavaдёүж–№дҫқиө–еҲӨж–ӯдёӨзӮ№и·қзҰ»
еҲӨж–ӯ дёҖдёӘIPеқҗж ҮжҳҜеҗҰеңЁдёӯеӣҪең°еӣҫеҶ…пјҢж ёеҝғжҖқжғіе°ұжҳҜзңӢзӮ№еҲ°зәҝдёҠзҡ„дәӨзӮ№зңӢжҳҜеҗҰеңЁеҸіиҫ№гҖӮе…·дҪ“зңӢеҸӮиҖғж–ҮжЎЈе®һжҲҳд»Јз ҒгҖӮ
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们жҺҢжҸЎеҰӮдҪ•иҝӣиЎҢRedis GeoHashж ёеҝғеҺҹзҗҶи§Јжһҗзҡ„ж–№жі•дәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–жғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ





