本篇内容介绍了“如何排查zuul版本升级产生的问题”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
事情的起因是由于早期的一些服务版本放到现在太低了,基本上都是SpringBoot1.5.x,因此准备统一对服务进行一次版本升级,升级到2.1.x,SpringCloud``版本升级到Greenwich。当然我们用的旧版本的zuul相关的都需要升级。
我们网关使用的是zuul,使用的是spring-cloud-netflix封装的包,此次版本升级同步升级了相关的包。但是意外的情况发生了,在测试环境上我们发现上传文件会出现异常。具体表现是这样的:当上传的文件超出一定大小后,在经过zuul网关并向其他服务转发的时候,之前上传的包就不见了。这个情况十分奇怪,因此马上开始排查。
出现这样的问题,第一反应是测试是不是根本没有上传包所以当然包没法转发到下一层,当然这种想法很快被否定了。好吧,那就认真的排查吧。
首先先去追踪了一下路由以及出现的具体日志,将问题定位到zuul服务,排除了上游nginx和下游业务服务出现问题的可能。但是zuul服务没有任何异常日志出现,所以非常困扰。检查过后发现文件确实有通过zuul,但是之后凭空消失没有留下一点痕迹。
明明当初考虑上传文件的问题给zuul分配了两个g的内存,怎么上传500m的文件就出问题了呢?不对!此时我灵光一闪,会不会和垃圾回收机制有关。我们的文件是非常大的,这样的大文件生成的大对象是会保存在java的堆上的,并且由于垃圾回收的机制,这样的对象不会经历年轻代,会直接分配到老年代,会不会是由于我们内存参数设置不合理导致老年代太小而放不下呢?想到做到,我们通过调整jvm参数,保证了老年代至少有一个G的空间,并且同步检测了java的堆内存的状态。然而让人失望的是居然没有奏效。不过此时事情和开始不同,我们有了线索。在刚才的堆的内存监控中发现了一些异常,随即合理怀疑是堆中内存不够导致了oom。随后加大内存尝试并且再次运行,发现居然上传成功了。果然是老年代内存不足导致的oom,不过虽然上传成功,但是老年代中的内存居然被占用了1.6G左右,明明是500M的文件,为什么会占用了这么大的内存呢?
虽然找到了原因,但是增加内存显然不是解决问题的方法,因此,我们在启动参数上新增了-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data准备查看oom的具体分析日志。
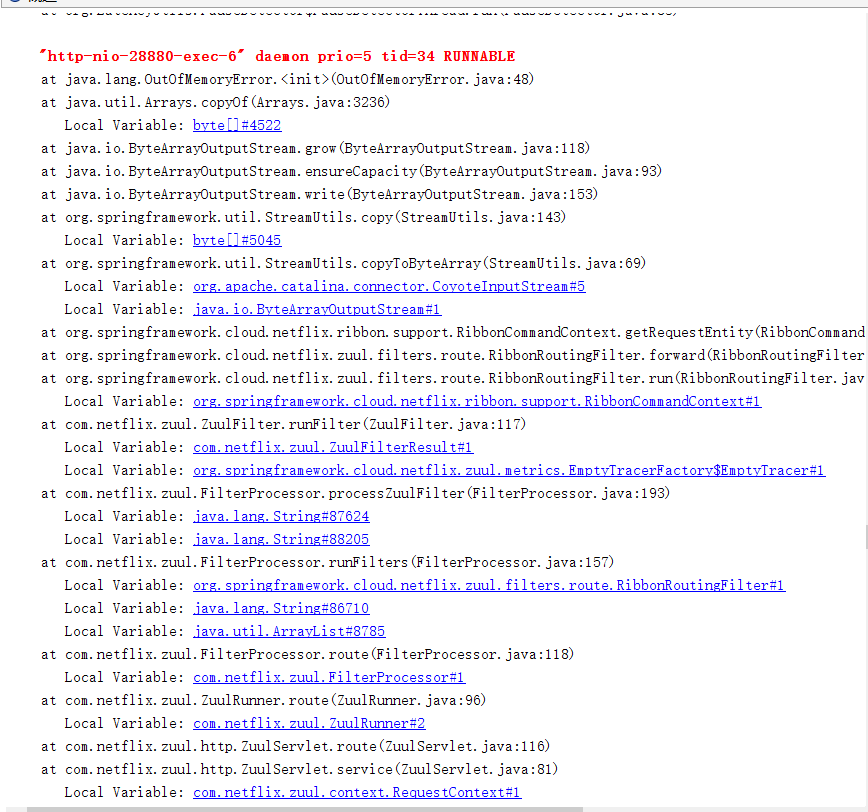
查看堆栈信息可以发现,溢出是发生在byte数组的拷贝上,我们迅速定位代码,可以找到如下的代码:
public InputStream getRequestEntity() {
if (requestEntity == null) {
return null;
}
if (!retryable) {
return requestEntity;
}
try {
if (!(requestEntity instanceof ResettableServletInputStreamWrapper)) {
requestEntity = new ResettableServletInputStreamWrapper(
StreamUtils.copyToByteArray(requestEntity));
}
requestEntity.reset();
}
finally {
return requestEntity;
}
}这段代码源自RibbonCommandContext是在zuul中进行请求转发的时候调用到的,具体的OOM是发生在调用StreamUtils.copyToByteArray(requestEntity));的时候。继续进入方法查找源头。最终经过排查找到了溢出的源头。ribbon转发中的用到了ByteArrayOutputStream的拷贝,代码如下:
public synchronized void write(byte b[], int off, int len) {
if ((off < 0) || (off > b.length) || (len < 0) ||
((off + len) - b.length > 0)) {
throw new IndexOutOfBoundsException();
}
ensureCapacity(count + len);
System.arraycopy(b, off, buf, count, len);
count += len;
}可以看到这边有一个ensureCapacity,查看源码:
private void ensureCapacity(int minCapacity) {
// overflow-conscious code
if (minCapacity - buf.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = buf.length;
int newCapacity = oldCapacity << 1;
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
buf = Arrays.copyOf(buf, newCapacity);
}可以看到ensureCapacity做了一件事,就是当流拷贝的时候byte数组的大小不够了,那就调用grow进行扩容,而grow的扩容和ArrayList不同,他的扩容是每一次将数组扩大两倍。
至此溢出的原因就很清楚了,500m文件占用1.6g是因为刚好触发扩容,导致用了多一倍的空间来容纳拷贝的文件,再加上源文件,所以占用了文件的3倍空间。
至于解决方案,调整内存占用或者是老年代的占比显然不是合理的解决方案。我们再回头查看源代码,可以看到这个部分
if (!retryable) {
return requestEntity;
}如果设置的不重试的话,那么body中的信息就不会被保存。所以,我们决定临时先去除上传文件涉及到的服务的重试,之后再修改上传机制,在以后的上传文件时绕过zuul。
虽然找到的原因,并且也有了解决方案,但是我们仍然不知道为什么旧版本是ok的,因此本着追根究底的态度,找到了旧版的zuul的源码。
新版的ribbon代码集成spring-cloud-netflix-ribbon,而旧版的ribbon的代码集成在spring-cloud-netflix-core中,所以稍稍花费点时间才找到对应的代码,检查不同,发现旧版的getRequestEntity没有任何的处理,直接返回了requestEntity
public InputStream getRequestEntity() {
return requestEntity;
}而在之后的版本中马上就加上了拷贝机制。于是我们去github上找到了当初的那个commit
之后我们顺着commit中给出的信息找到了最初的issue
查看过issue之后发现这原来是旧版的一个bug,这个bug会导致旧版的post请求在retry的时候有body丢失的情况,因此在新版本中进行了修复,当请求为post的时候会对于body进行缓存以便于重试。
“如何排查zuul版本升级产生的问题”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





