本篇内容介绍了“logstash的安装教程和使用方法”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
# 下载,不同的操作系统下载不同的包
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.12.0-darwin-x86_64.tar.gz
# 解压
tar -zxvf logstash-7.12.0-darwin-x86_64.tar.gz
# 重命名
mv logstash-7.12.0 logstash
cd logstash
bin/logstash -hbin/logstash -f 文件路径
注意⚠️: -f 后面跟的文件路径可以是一个文件的路径,也可以是一个文件夹的路径,如果是文件夹的路径,则会加载该文件夹下的文件,组成一个大的 pipeline 文件。
bin/logstash -t
bin/logstash -r
bin/logstash --http.host 127.0.0.1 --http.port 9210注意⚠️:
更多配置项参考 bin/logstash -h 的输出。
vim config/jvm.options 修改 -Xms 和 -Xmx 等其余参数的值。
> vim config/logstash.yml
# 设置节点的名字
node.name: logstash-01
# 设置 pipeline 的id
pipeline.id: main
pipeline.ordered: auto
# 设置pipeline 的线程数(filter+output),默认是cpu的核数
# pipeline.workers: 2
# 设置main pipeline文件所在的位置
# path.config:
# 自动重新加载pipeline配置文件
config.reload.automatic: true
# 设置http api 绑定的ip和端口
http.host: 127.0.0.1
http.port: 9201
# 设置logstash队列的类型 为持久化,默认是 memory
queue.type: persisted实现功能,接口从控制台输入的数据然后输出到控制台上。
文件名: pipeline.conf/demo-std.conf
# 输入, stdin 表示标准输入
input {
stdin {
codec => plain {
charset => "UTF-8"
}
# type 的值随便给,就一个标识,后期方便查询
type => "console input"
# 添加一个 tag
tags => ["console"]
}
}
# 数据过滤
filter {
}
# 输出 stdout 表示输出
output {
stdout {
codec => rubydebug {
}
}
}启动的时候,直接某个pipeline文件
# -f 指定 pipeline 文件的路径
bin/logstash -f pipeline.conf/demo-std.conf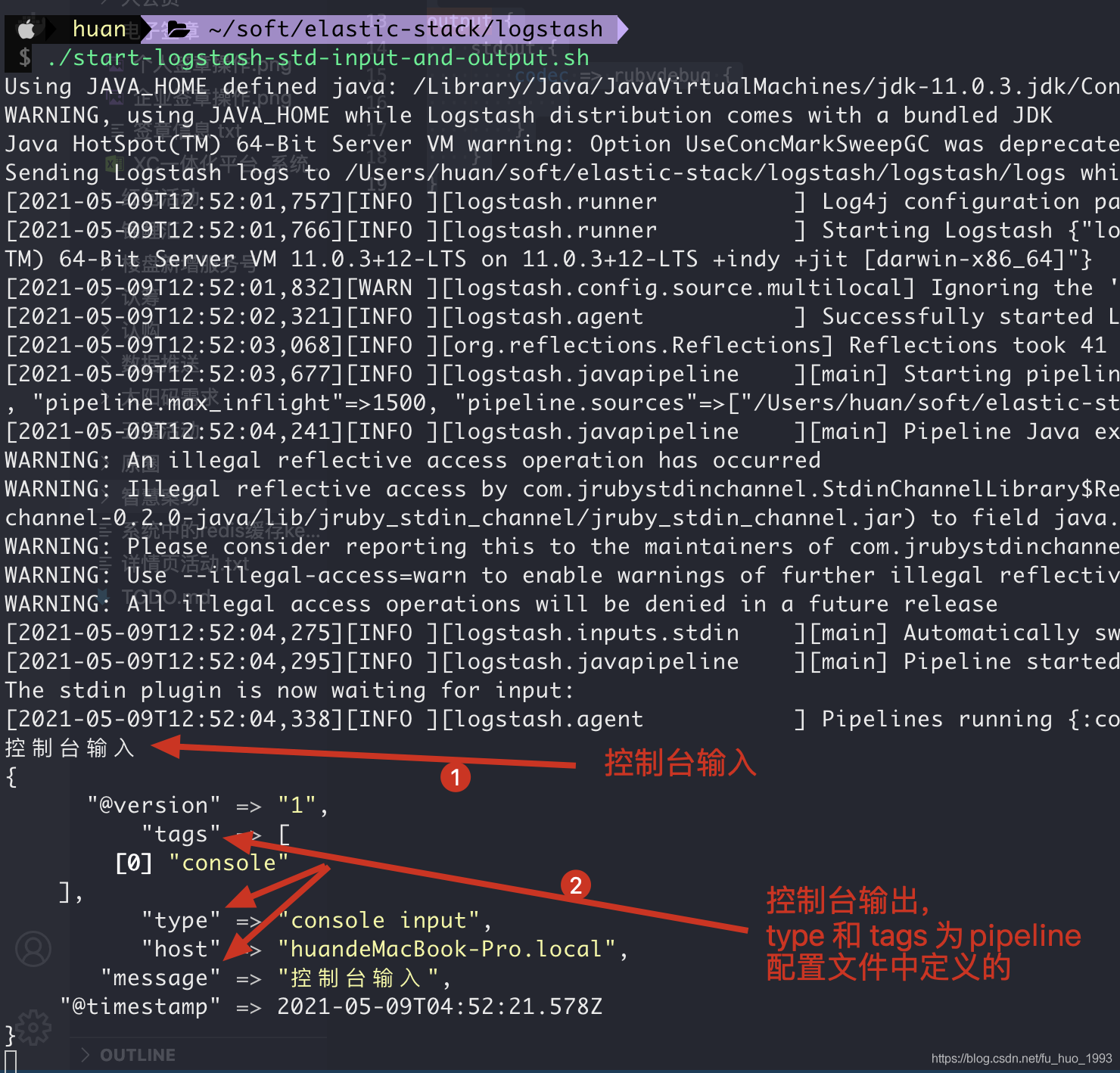
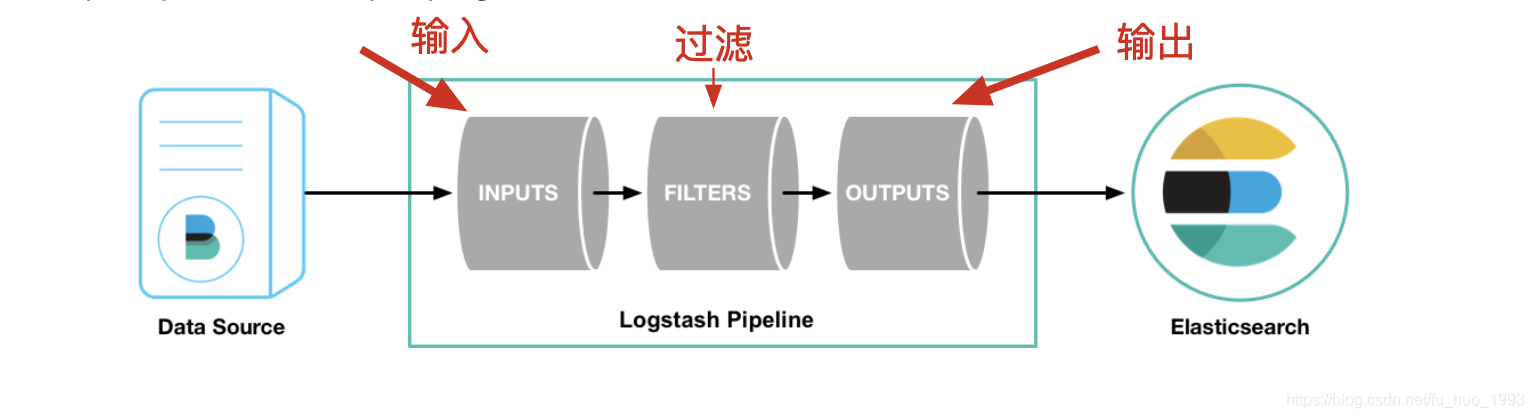 由上图可知,一个pipeline有三个元素组成
由上图可知,一个pipeline有三个元素组成input、filter和output。其中 input和output是必须的。filter是可选的。
input:指定了从那个地方抓取数据,比如:文件(file)、beats、tcp等等。 filter:是我们可以修改input的数据,比如增加字段、重命名字段、修改字段类型等等。 output:决定了我们处理好的数据输出到哪里,比如:es、file、等等。
“logstash的安装教程和使用方法”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/huanoschina/blog/5044525



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



