这篇文章主要介绍“分布式数据库的基本概念”,在日常操作中,相信很多人在分布式数据库的基本概念问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”分布式数据库的基本概念”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
1.单库,就是一个库

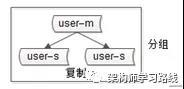
3.分组(group),分组解决可用性问题,分组通常通过主从复制(replication)的方式实现。(各种可用级别方案单独介绍)
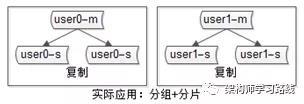
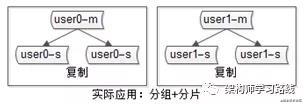
4.互联网公司数据库实际软件架构是(大数据量下):又分片,又分组(如下图)
数据分片是按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。
数据分片的拆分方式分为垂直分片和水平分片
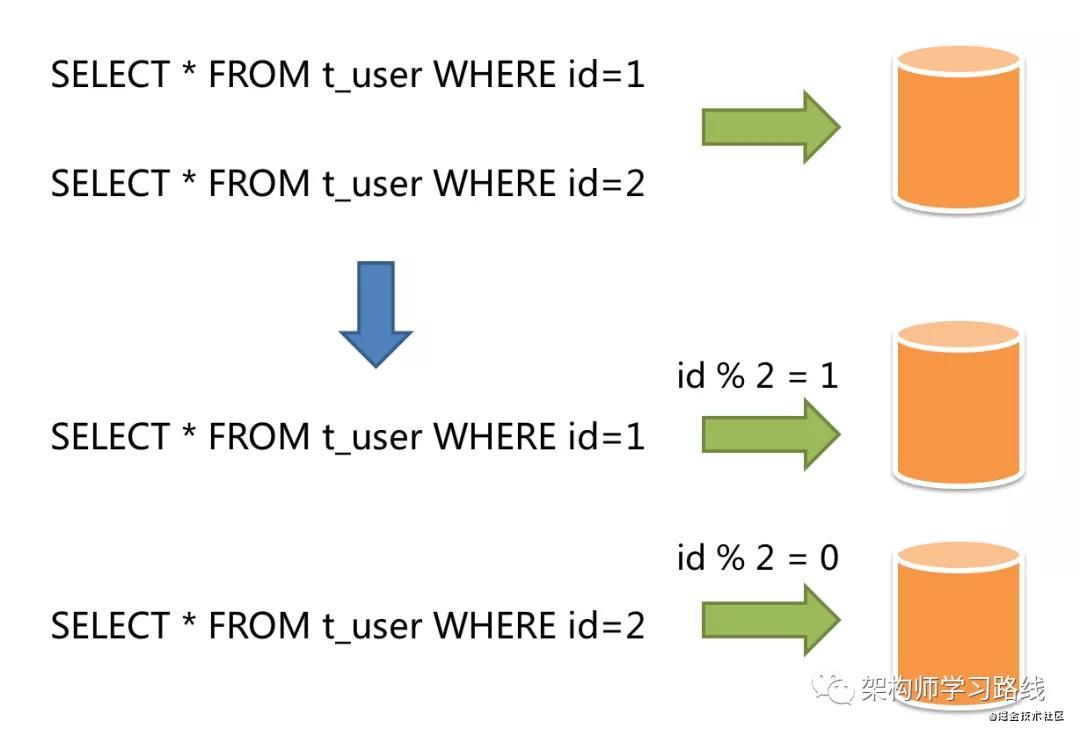
水平分片:是对于单表数据进行拆分.拆分标准也不再基于业务逻辑,而是将字段根据某种规则将数据分散到不同的表或库中.每个分片只存储一部分数据.常见的是根据主键分片.如:奇数放0库,偶数放1库.
优点:水平分片理论上突破了单机数据量处理的瓶颈,可以无限横向扩展.是解决单机数据量和访问量限制的终极方案.
缺点:
数据库操作更繁重,数据定位繁琐.
关联操作(分组,聚合,分页,排序等跨单元操作)需要特殊处理.
表名称
因为数据库切分是将整体数据,切分为多份存储,这样就产生了逻辑表和真实表的概念.
真实表:就是实际进行数据存储的表.
逻辑表:就是原本数据单个数据库中的表.即真实表的总和.如:真实表可能分为order_0,order_1,那么逻辑表就是order表,它表示了order表未被切分时的状态.
分布式事务,跨库join(查询).
分表操作,如果要动态增加表时,如果采取hash的方式就存在rehash导致的数据迁移
垂直,水平分片是分布式数据库架构方案.分库,分表是实现方式,分库既可以是垂直也可以是水平切分,分表也同样可以有垂直,水平两种切分方式.
读写分离
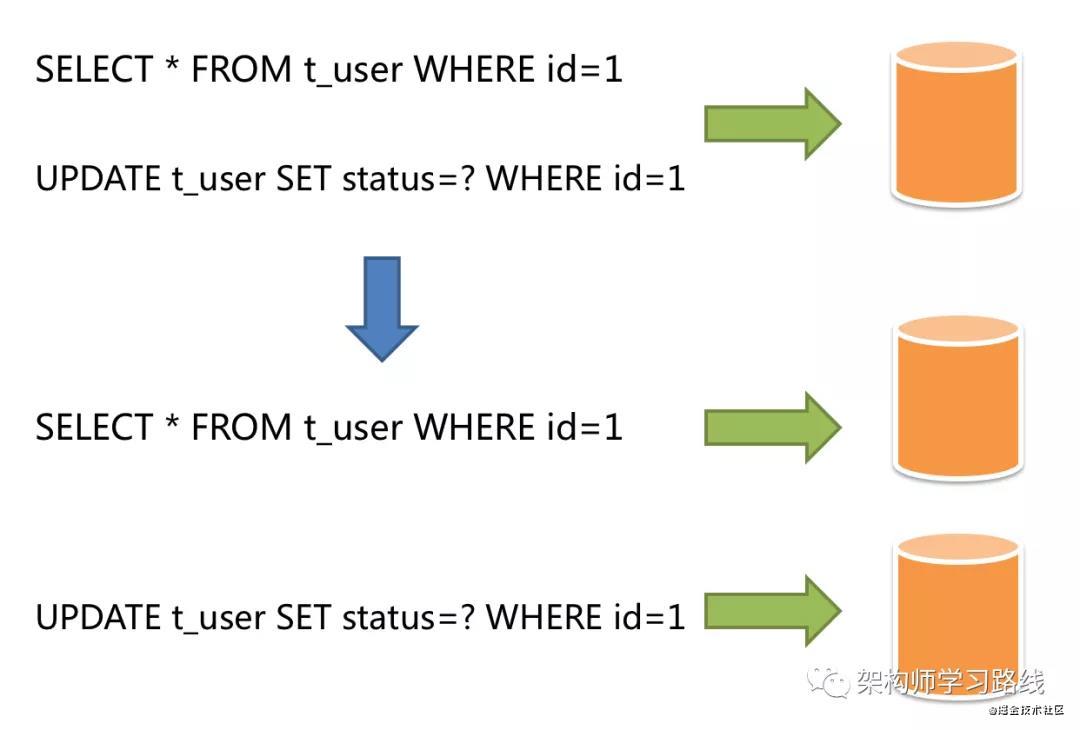
主从数据库是解决数据库单点问题的简单方案,即根据读写操作上区分数据库职责,以降低单一数据库的访问压力.
应用场景:针对于读多写少的系统,通过拆分更新操作和查询操作,来避免数据更新导致的行锁,提高整个系统的查询性能.
一主多从:分散查询请求,进一步提高查询性能.存在单点问题.
多主多从:提升系统吞吐量,可用性
存在问题:数据不一致.主库之间,主库和从库之间.
如:主键一致性问题.为了高可用,会进行多主部署,如果表主键采取auto_increment,且主库双向同步,a库入库数据后,与b库同步数据如果出现问题,b库入库数据后,再进行ab库数据同步就可能存在主键冲突的问题.
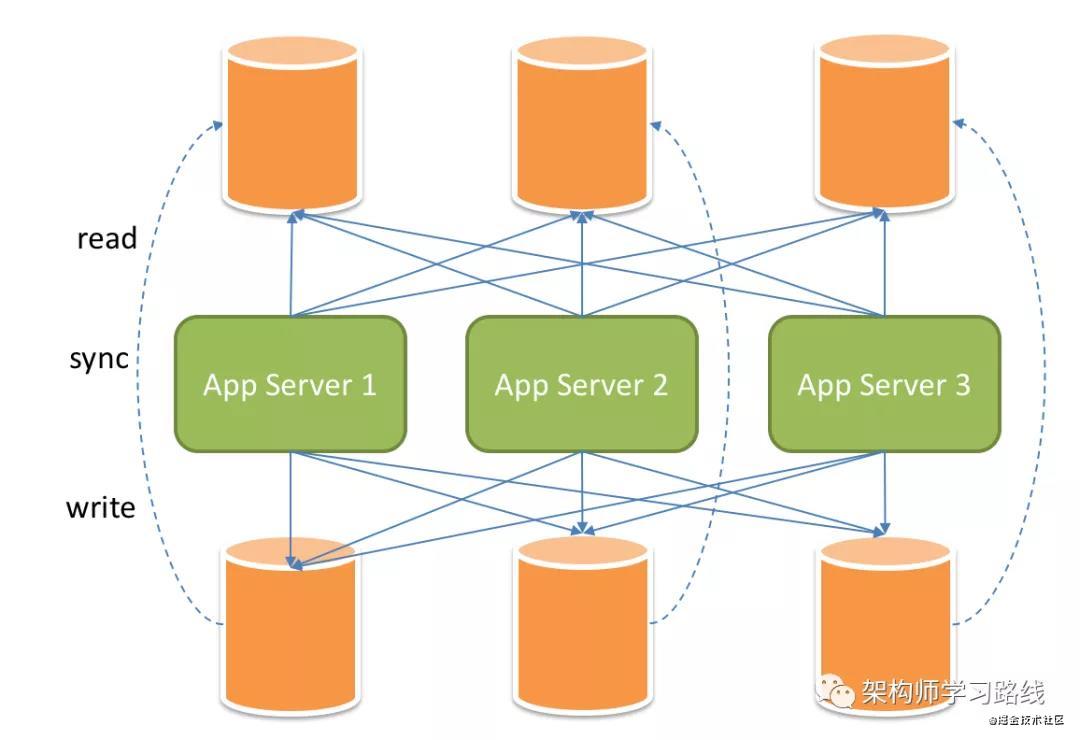
主从数据一致性原理:
主库用于写,更新操作;从库用于数据读取操作.当主从数据库数据同步存在延迟时,就会造成主从数据库的一致性问题.
主库->写->binlog->IO线程->从库
延迟原因:从库读取binlog时,会串行执行sql,而主库是并行执行sql;主库故障造成未写入binlog
解决方案:
1 降低从库读取压力.做法:分库,增加从库机器配置,增加从库机器(一主多从),增加服务缓存
2 直连主库.会造成主存数据库失去意义.
ShardingSphere在同一个线程且同一个数据库连接进行写操作时,会采取直连主库的方式,避免数据不一致的问题.
主要处理方式如下:
忽略
实际写少读多的应用,看你的业务是否允许一定程度的数据不一致.感觉像招投标这种行业,对于数据没有这么强的一致性要求.实际的技术选型总会对于准确和便捷做出一些妥协.
强制读主库
对于数据实时性要求较高的根本做法还是去读主库,因为主库的数据才会没有延迟的问题.从库数据读取
选择性读主
通过缓存来记录数据库,表,主键,消息有效期(主从同步时延)
增加集中式缓存
数据入库时先将数据存入缓存.这个时候pc端存入数据,移动端登陆时去缓存中可以取到对应的订单数据.这种做法存在热点数据问题.
到此,关于“分布式数据库的基本概念”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4479011/blog/5037180



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务