什么是轻量级?抛开技术术语,从效果上看就是为了实现操作目的,使用更轻便、更省时的方法;那么什么是高性能呢?最直接的说法就是比常用方法更加高效、更快。
下面就来介绍润乾提供的这一套轻量级、高性能的多维分析套件。
轻量级的准确含义,是相对于重量级框架而言的一种程序设计模式。轻量级的优点在于对容器没有依赖性,易于配置,更加通用,启动时间较短,并能充分减少开发复杂度;而高性能,则是指相比于常用方法而言,获取期望结果更加快速、准确的实现方法。具体到润乾报表,这里将给大家介绍通过多维分析页面对简单SQL进行查询。
这个过程其实很简单:我们在多维分析页面输入简单 SQL语句,通过集算器 JDBC 提交,然后对组表执行 SQL 查询,将结果返回给多维分析前端。结构图如下:
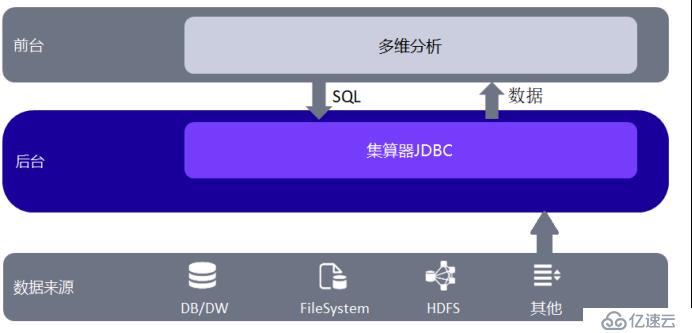
其中,组表文件由集算器从各种异构数据源采集数据并计算而来,具体做法可以参考《集算器教程 - 组表》。
由于组表文件具备独立计算的能力,可以脱离数据库为前端提供数据源服务,因此非常适合作为中间件,并以此为基础实现这套olap套件。下面我们就使用集算器做一个测试,进一步了解和使用组表文件,并与oracle做对比,更加直观的了解这个套件的轻量级、高性能特点。
| 处理器 | Inter(R) Core(TM) i5-6200U CPU @ 2.30GHz 2.40GHz |
| 内存 | 8G |
| 硬盘 | 1TB |
| 操作系统 | Windows10 家庭中文版(64 位) |
测试使用的设备不算高端,但因为测试的目的是对组表以及oracle进行对比,因此在相同环境下的数据之间作对比,设备影响因素不大,性能对比仍然是有效的参考。
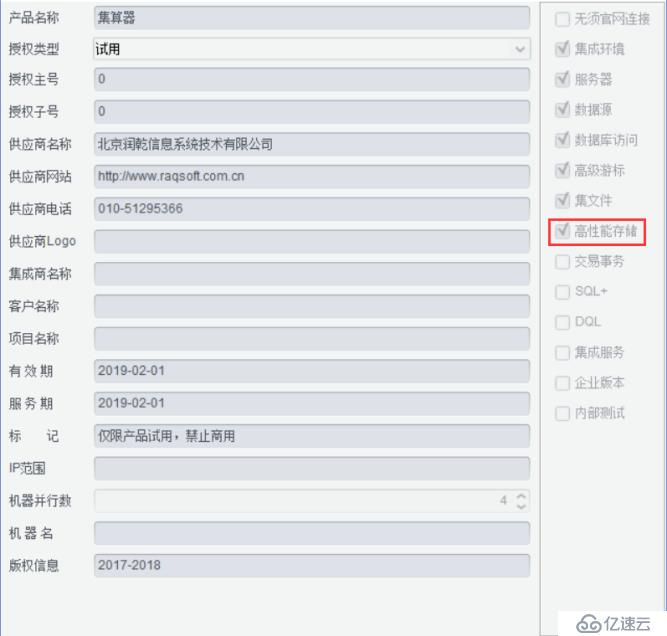
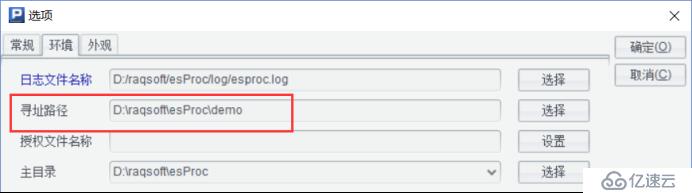
我们使用集算器对数据进行查询比对,为此我们需要在官网或乾学院中下载含高性能存储的集算器试用授权到本地,然后在【工具-选项-环境】中选择授权文件,设置后的结果如下:
为了充分体现测试效果,测试用例的数据必须足够大。我们将创建一个5000万条数据、至少十个字段的数据表。
首先,在集算器中生成测试数据的txt格式文件:
| A | B | |
| 1 | =create(ID,产品编号,颜色,内存,扩展容量,核心数,主屏尺寸,电池容量,后置摄像头,前置摄像头,机身重量,质保时间,双卡双待,上市时间,单价,库存量) | |
| 2 | [黑,白,银,玫瑰金,土豪金] | [0,0.5,0.75,0.9,0.95,1] |
| 3 | [32,128,64,16,8] | |
| 4 | [64,16,8,128,32] | |
| 5 | [2,8,4] | [0,0.5,0.9,1] |
| 6 | 2018-01-01 | =workdays(A6,A6+364) |
| 7 | for 500 | =100000.new((A7-1)*100000+#:ID,rands("abcdefghijklmnopqrstuvwxyz0123456789",36): 产品编号,A2(B2.pseg(rand())): 颜色,A3(B2.pseg(rand())): 内存,A4(B2.pseg(rand())): 扩展容量,A5(B5.pseg(rand())): 核心数,(string(round((rand()*(6-5)+5),1))+"寸"): 主屏尺寸,(string(int(round((rand()*(4-3)+3),1)*1000))+"mAh"): 电池容量,(string(int(round((rand()*(3-2)+2),1)*1000))+"万 / 像素"): 后置摄像头,(string(int(round((rand()*(2-1)+1),1)*1000))+"万 / 像素"): 前置摄像头,(string(int(round((rand()*(2-1)+1),2)*100))+"克"): 机身重量,(string(int(rand()*3+1))+"年"): 质保时间,if(rand()<0.5,"支持","不支持"): 双卡双待,string(elapse(A6,-rand(100))): 上市时间,int(rand()*(4999-1999)): 单价,int(rand()*(999-9)): 库存量 ) |
| 8 | >file("D:\\test.txt").export@ta(B7) |
生成的txt文件大小为6284M。

然后我们要将这个txt中的手机产品表数据,用 SPL 语言脚本转储到集算器组表文件 test.ctx 中。SPL 脚本如下:
| A | |
| 1 | =file("D:\\test.ctx") |
| 2 | =A1.create(ID,产品编号,颜色,内存,扩展容量,核心数,主屏尺寸,电池容量,后置摄像头,前置摄像头,机身重量,质保时间,双卡双待,上市时间,单价,库存量) |
| 3 | =file("D:\\test.txt").cursor@t() |
| 4 | =A2.append(A3) |
test.ctx 是组表文件,默认采用列式存储的,支持任意分段的并行计算,从而可以有效提升查询速度。要注意在生成组表时,数据需要预先排序并合理定义维字段。
组表文件的大小大约为3312M,而将txt中的数据转储到组表中所需的时间为968s。

与之对应,我们使用sqlloader将txt中的数据导入到oracle中,所需时间为18小时左右,并且相同字段及数据量的oracle表所占空间为6683M。
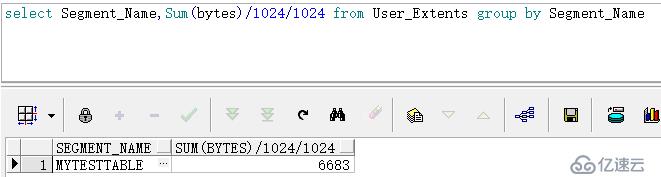
可以看出,将txt数据分别导入组表文件和oracle表中的时间真的是相差很大,而且,将数据导入oracle后所占空间的大小与txt文件的大小所差无几,相比之下,组表文件所占空间只有一半,这得益于组表文件的压缩效果。后面我们还会进一步讨论分析与高性能相关的特性。
下面我们来对比一下用SQL查询oracle表以及组表文件所需的时间,直接用效果说话:
查询指定字段:
查询组表:select ID,产品编号,库存量 from test.ctx limit 5000 查询oracle:select ID,产品编号,库存量 from myTestTable where rownum <= 5000 |
查询ID、产品编号以及库存量:查询组表用时1s;查询oracle表用时33s;
添加where查询条件:
查询组表:select ID,产品编号,库存量 from test.ctx where 颜色=’土豪金’ limit 5000 查询oracle:select ID,产品编号,库存量 from myTestTable where 颜色=’土豪金’ and rownum <= 5000 |
查询表中产品颜色为土豪金的数据:查询组表用时1s;查询oracle表用时58s;
| select ID,产品编号,单价,库存量 from myTestTable/test.ctx where 颜色=’黑’ and 库存量 > 500 and 单价 > 2000 |
查询颜色为黑且库存量大于500、单价大于2000的数据:查询组表用时92s;查询oracle表用时2353s;
此时我们还可以尝试并行查询:
| select /*+ parallel(4) */ID,产品编号,单价,库存量 from myTestTable/test.ctx where 颜色=’黑’ and 库存量 > 500 and 单价 > 2000 |
查询组表用时84s;查询oracle表用时2105s;
执行以上查询语句后我们可以发现,查询组表的速度要比直接查询oracle表快很多。当然,多维分析中很少用到明细查询,对明细查询的性能要求也不高,我们更关注汇总统计的性能,也就是有GROUP BY的情况,下面来试一下。:
| 查询组表/oracle:select 颜色,max(库存量) from test.ctx/myTestTable group by 颜色 |
查询产品每个颜色的最大库存量:查询组表用时12s;查询oracle表用时297s;
| 查询组表/oracle:select 颜色,内存,max(库存量) from test.ctx/myTestTable group by 颜色,内存 |
查询产品每个颜色中,各内存的最大库存量:查询组表用时17s;查询oracle表用时334s;
| 查询组表/oracle:select /*+ parallel(4) */颜色,内存,max(库存量) from test.ctx/myTestTable group by 颜色,内存 |
尝试并行查询产品每个颜色中,各内存的最大库存量:查询组表用时13s;查询oracle表用时308s;
查询组表:select 内存,sum(库存量) from test.ctx where 上市时间 between date('2018-01-01') and date('2018-12-31') group by 内存 查询oracle:select 内存,sum(库存量) from myTestTable where 上市时间 between to_date('2018-01-01',’yyyy-mm-dd’) and to_date('2018-12-31',’yyyy-mm-dd’) group by 内存 |
查询2018年上市的产品中各种内存的总库存量:查询组表用时5s;查询oracle表用时10s;
查询组表:select 内存,min(机身重量),avg(单价) from test.ctx where 上市时间 between date('2018-01-01') and date('2018-12-31') group by 内存 查询oracle:select 内存,min(机身重量),avg(单价) from myTestTable where 上市时间 between to_date('2018-01-01',’yyyy-mm-dd’) and to_date('2018-12-31',’yyyy-mm-dd’) group by 内存 |
查询2018年上市产品的最小机身重量和平均单价:查询组表用时6s;查询oracle表用时11s;
查询组表:select 内存,min(机身重量),avg(单价) from test.ctx where 上市时间 between date('2018-01-01') and date('2018-12-31') group by 内存 having avg(单价)>=1500 查询oracle:select 内存,min(机身重量),avg(单价) from myTestTable where 上市时间 between to_date('2018-01-01',’yyyy-mm-dd’) and to_date('2018-12-31',’yyyy-mm-dd’) group by 内存 having avg(单价)>=1500 |
查询2018年上市产品中,单价不小于1500的最小机身重量和平均单价:查询组表用时14s;查询oracle表用时38s;
毫无悬念,对于汇总统计,查询组表的速度也要显著快于查询oracle。
根据上面对大数据量的组表以及数据库的查询速度比较,可以发现查询条件越少,两者之间的效率对比也就越明显,查询组表数据始终快于查询数据库,这就清晰地体现除了组表高性能的特点。由此我们推断,在多维分析页面下,对组表进行查询要比对数据库进行查询更加高效。
下面我们就将组表与分析界面结合起来进行查询。
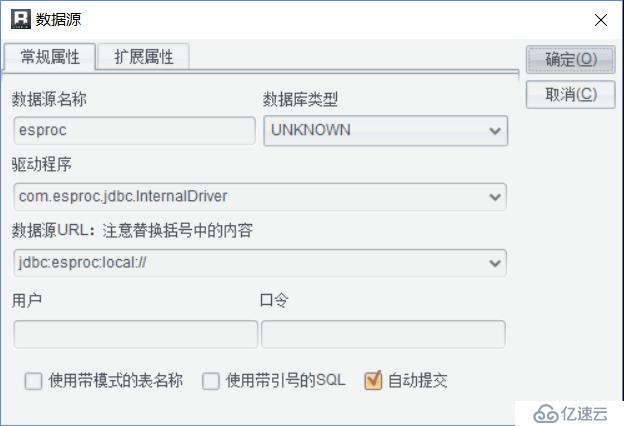
(1)在报表中添加集算器JDBC并连接数据源:
(2)集算器raqsoftConfig.xml复制到报表WEB-INF的类路径下:
将[集算器目录]\esProc\config下的raqsoftConfig.xml复制到[报表目录]\report\web\webapps\demo\WEB-INF\classes中;
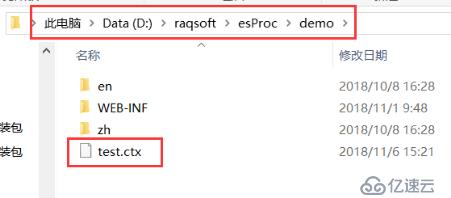
(3)将组表文件放到集算器寻址路径路径下:
本例中,我们将使用组表文件test.ctx。
(4)修改多维分析页面
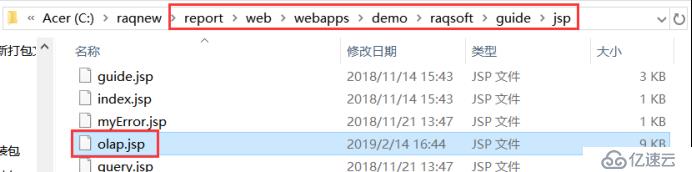
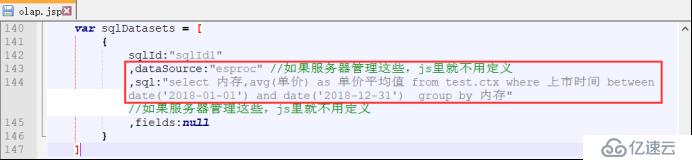
打开[报表目录]\report\web\webapps\demo\raqsoft\guide\jsp\olap.jsp,将jsp中的DataSource修改为(1)中设置的数据源名称“esproc”;依旧使用上述的示例,sql语句这里我们用“select 内存,avg(单价) as 单价平均值 from test.ctx where 上市时间 between date('2018-01-01') and date('2018-12-31') group by 内存”;
(5)访问页面
我们通过双击[报表目录]\report\bin下的startdemo.bat启动服务器,或者在报表IDE中点击 启动Tomcat服务器。
启动Tomcat服务器。
在浏览器地址栏输入“http://localhost:6868/demo/raqsoft/guide/jsp/olap.jsp?sqlId=sqlId1”对页面进行访问,这时页面中就可以展现从集算器JDBC中所返回的数据,并且可以在页面中进行拖拽等操作。
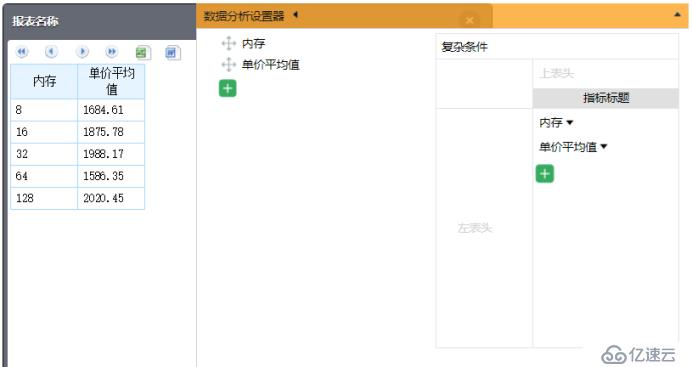
当然,这里还是要对比一下查询组表文件与查询oracle的时间:查询组表文件用时7s,查询oracle用时22s,组表明显更胜一筹。
将组表与多维分析界面进行结合,从组表而不是从数据库中取数,用户可以更方便的制作数据量大的报表,大大缩短了等待数据显示的时间;对比昂贵的专业数据库和相对封闭的 BI 自带数据源,集算器可以提供更加经济、简便的解决方案,并能够从各种异构数据源采集数据生成组表文件以供使用。同时整个配置过程非常简单,这些都体现了这个套件的轻量级、高性能的特点。
和普通数据库方案相比,集算器列存的二进制文件,也就是组表文件,能够直接提升性能。在生成组表时,指定了维字段,数据本身将按照维字段有序存放,这样,常用的条件过滤计算不依赖索引也能保证高性能。另外,更加轻量的一点是,组表文件采用压缩存储,显著减少了所占用的硬盘空间,读取也就更快了。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





