多维分析(BI)系统后台数据源通常有三种选择。一、普通数据库;二、专业数据仓库;三、BI 系统自带的数据源。
但是,这三种选择都有各自的问题。普通数据库一般都是行式存储,很难获得多维分析希望的高性能,只适用较小数据量。专业数据仓库有不少是列式存储的,性能问题不大,但是价格都比较昂贵,建设、扩展和维护成本也都非常高。BI 系统自带的数据源都比较封闭,只能为自家的 BI 前端提供支持,无法为多个不同厂家的前端提供数据服务。
集算器可以独立承担轻量级多维分析后台的作用,相当于中小型数据仓库或者数据集市。结构图如下: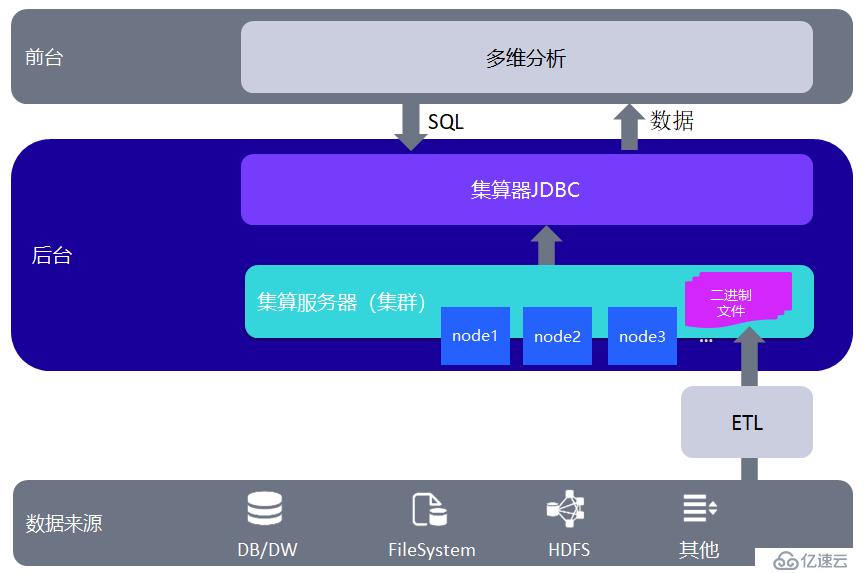
集算器可以将多维分析的数据事先以列存形式存储到二进制文件中,称为组表。多维分析前端应用拖拽生成 SQL,通过集算器 JDBC 提交。集算器对组表执行 SQL 查询,将结果返回给多维分析前端。组表文件也可由集算器从各种异构数据源采集数据并计算而来。
和普通数据库方案相比,集算器列存的二进制文件能够直接提升性能。而对于昂贵的专业数据库和相对封闭的 BI 自带数据源,集算器可以提供更加经济、简便的解决方案,并能够从各种异构数据源采集数据。
集算器有三种部署方式:1、集成在前端应用中;2、独立服务器;3、集群热备。下面介绍具体方法。
在下面的案例中,多维分析系统要针对订单数据做自助分析。为了简化起见,多维分析系统前台用 tomcat 服务器中的 jdbc.jsp 来模拟。Tomcat 安装在 windows 操作系统的 C:\tomcat6。
集算器 JDBC 集成在多维分析应用中。jdbc.jsp 模仿多维分析应用系统,产生符合集算器规范的 SQL,通过集算器 JDBC 提交给集算器 SPL 脚本处理。
多维分析系统的数据来自于生产数据库 demo 中的 ORDERS 表,生产库是 ORACLE 数据库。多维分析系统不能直接连 demo 数据库实现分析,以免给生产数据库带来过多的压力。ORDERS 订单表是全量数据,集算器 ETL 每天将当天的最新数据同步到组表文件中。日期以订购日期 ORDERDATE 为准,假设当前的日期是 2015-07-18。
用下面的 ordersAll.sql 文件在 ORACLE 数据库中完成 ORDERS 表的建表和数据初始化。
ordersAll
数据截止到 2017 年 7 月 17 日。
多维分析系统后台上线初始化的时候,要将 ORDERS 表中的历史数据同步到集算器的二进制文件中。这是上线前一次性执行的准备工作,上线运行后就不需要执行了。
在集算器中,新建一个数据源 orcl,连接 ORACLE 数据库。用 SPL 语言脚本 etlAll.dfx 将全部数据读取到集算器组表文件 orders.ctx 中。SPL 脚本如下:
| A | B | |
|---|---|---|
| 1 | =connect(“orcl”) | =A1.cursor@d(“select ORDERDATE,CUSTOMERID,EMPLOYEEID,ORDERID,AMOUNT from ORDERS order by ORDERDATE,CUSTOMERID,EMPLOYEEID,ORDERID”) |
| 2 | =file(“C:/tomcat6/webapps/DW/WEB-INF/data/orders.ctx”) | |
| 3 | =A2.create(#ORDERDATE,#CUSTOMERID,#EMPLOYEEID,#ORDERID,AMOUNT) | |
| 4 | =A3.append(B1) | >A1.close() |
Orders.ctx 是组表文件,默认是采用列式存储的,支持任意分段的并行计算,可以有效提升查询速度。生成组表的时候,要注意数据预先排序和合理定义维字段。本例中,按照经常过滤、分组的字段,将维字段确定为:ORDERDATE,CUSTOMERID,EMPLOYEEID, ORDERID。
从 ORACLE 中取得数据的时候,要按照维字段排序。因为 ORDERDATE,CUSTOMERID,EMPLOYEEID 对应的重复数据多,所以放在前面排序;ORDERID 对应的重复数据少,所以放在后面排序。
B1 单元格中数据库游标的 @d 选项,表示从 ORACLE 数据库中取数的时候将 numeric 型数据转换成 double 型,精度对于金额这样的常见数值完全足够了。如果没有这个选项就会默认转换成 big decimal 型数据,计算性能会受到较大影响。
多维分析系统上线之后,要每天晚上定时同步当天最新的数据。我们假设当天日期是 2015-07-18。用下面的 ordersUpdate.sql 文件在 ORACLE 数据库给 ORDERS 表增加当天的数据,模拟数据的增量。
ordersUpdate
用 SPL 语言脚本 etlUpdate1.dfx 将当天数据增量补充到集算器组表文件 orders.ctx 中。SPL 脚本如下:
| A | B | C | |
|---|---|---|---|
| 1 | =connect(“orcl”) | ||
| 2 | =A1.cursor@d(“select ORDERDATE,CUSTOMERID,EMPLOYEEID,ORDERID,AMOUNT from ORDERS where ORDERDATE=? order by ORDERDATE,CUSTOMERID,EMPLOYEEID,ORDERID”,etlDate) | ||
| 3 | =file(“C:/tomcat6/webapps/DW/WEB-INF/data/orders.ctx”) | ||
| 4 | =A3.create() | =A4.append(A2) | =A3.rollback() |
| 5 | >A1.close() |
etlUpdate.dfx 的输入参数是 etlDate,也就是需要新增的当天日期。
B4 单元格直接将新数据追加到组表文件中。因为第一个排序字段是 orderdate,所以追加新数据不会影响排序。如果第一个排序字段不是 orderdate,就要重新排序。
C4 中的 rollback 是回滚函数,若 B4 执行 append 过程中,出现错误,那么将执行回滚操作,恢复到 append 操作之前的组表状态。正常执行完毕,则不会回滚。
etlUpdate1.dfx 脚本可以用 windows 或者 linux 命令行的方式执行,结合定时任务,可以定时执行。也可以用 ETL 工具来定时调用。
windows 命令行的调用方式是:
C:\\Program Files\\raqsoft\\esProc\\bin>esprocx.exe C: \\etlUpdate1.dfx
linux 命令是:
/raqsoft/esProc/bin/esprocx.sh /esproc/ etlUpdate1.dfx
集算器 JDBC 集成在多维分析的应用中,接收到 SQL 后查本地文件 orders.ctx 返回结果。
1、下面压缩文件中的 DW 目录复制到 tomcat 的应用目录。
DW
目录结构如下图: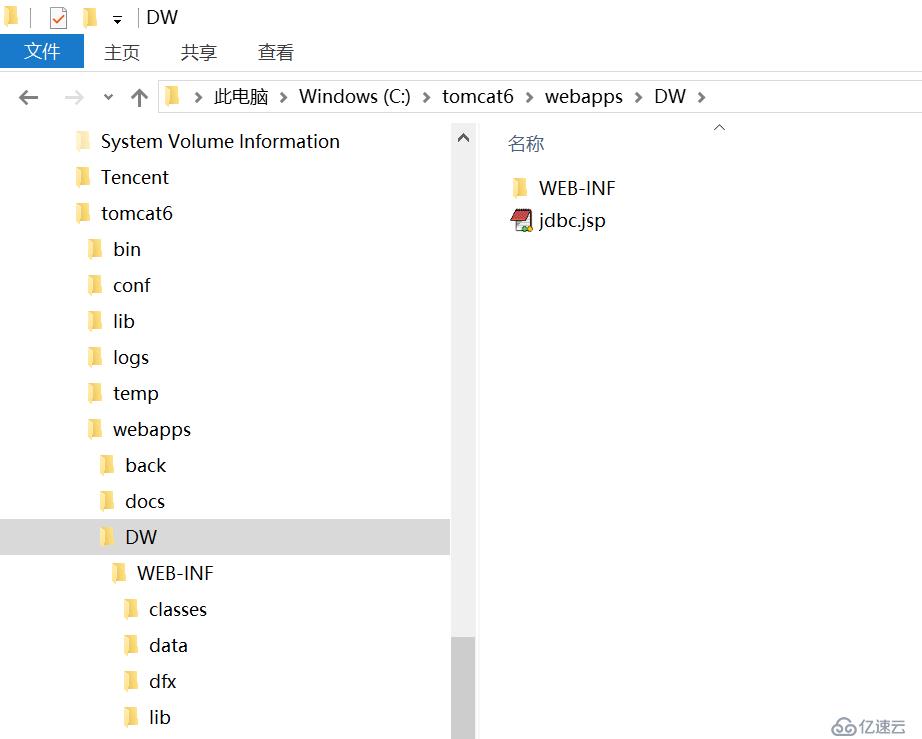
配置文件在 classes 中,在官网上获取的授权文件也要放在 classes 目录中。集算器的 Jar 包要放在 lib 目录中(需要哪些 jar 请参照集算器教程)。
修改 raqsoftConfig.xml 中的主目录配置:
<mainPath>C:\\tomcat6\\webapps\\DW\\WEB-INF\\data</mainPath>
配置好主目录后,orders.ctx 就可以不写全路径名,直接写 from orders.ctx 即可。
2、编辑 DW 目录中的 jdbc.jsp,模拟前台界面提交 sql 展现结果。
<%@ page language=”java” import=”java.util.*” pageEncoding=”utf-8″%>
<%@ page import=”java.sql.*” %>
<body>
<%
String driver = “com.esproc.jdbc.InternalDriver”;
String url = “jdbc:esproc:local://”;
try {
Class.forName(driver);
Connection conn = DriverManager.getConnection(url);
Statement statement = conn.createStatement();
String sql =”select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS.ctx where ORDERDATE=date(‘2015-07-18’) and AMOUNT>100″;
out.println(“Test page v1<br><br><br><pre>”);
out.println(“订单ID”+”\\t”+”客户ID”+”\\t”+”雇员ID”+”\\t”+”订购日期”+”\\t”+”订单金额”+”<br>”);
ResultSet rs = statement.executeQuery(sql);
int f1,f6;
String f2,f3,f4;
float f5;
while (rs.next()) {
f1 = rs.getInt(“ORDERID”);
f2 = rs.getString(“CUSTOMERID”);
f3 = rs.getString(“EMPLOYEEID”);
f4 = rs.getString(“ORDERDATE”);
f5 = rs.getFloat(“AMOUNT”);
out.println(f1+”\\t”+f2+”\\t”+f3+”\\t”+f4+”\\t”+f5+”\\t”+”<br>”);
}
out.println(“</pre>”);
rs.close();
conn.close();
} catch (ClassNotFoundException e) {
System.out.println(“Sorry,can`t find the Driver!”);
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
%>
</body><%@ page language=”java” import=”java.util.*” pageEncoding=”utf-8″%><%@ page import=”java.sql.*” %><body><%String driver = “com.e
sproc.jdbc.InternalDriver”;String url = “jdbc:esproc:local://”;try {Class.forName(driver);Connection conn = DriverManager.getConnection(url);S
tatement statement = conn.createStatement();String sql =”select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS.ctx where ORD
ERDATE=date(‘2015-07-18’) and AMOUNT>100″;
out.println(“Test page v1<br><br><br><pre>”);
out.println(“订单ID”+”\\t”+”客户ID”+”\\t”+”雇员ID”+”\\t”+”订购日期”+”\\t”+”订单金额”+”<br>”);
ResultSet rs = statement.executeQuery(sql);
int f1,f6;
String f2,f3,f4;
float f5;
while (rs.next()) {
f1 = rs.getInt(“ORDERID”);
f2 = rs.getString(“CUSTOMERID”);
f3 = rs.getString(“EMPLOYEEID”);
f4 = rs.getString(“ORDERDATE”);
f5 = rs.getFloat(“AMOUNT”);
out.println(f1+”\\t”+f2+”\\t”+f3+”\\t”+f4+”\\t”+f5+”\\t”+”<br>”);
}
out.println(“</pre>”);
rs.close();
conn.close();
} catch (ClassNotFoundException e) {
System.out.println(“Sorry,can`t find the Driver!”);
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
%></body>可以看到,jsp 中先连接集算器的 JDBC,然后提交执行 SQL。步骤和一般的数据库完全一样,具有很高的兼容性和通用性。对于多维分析工具来说,虽然是界面操作来连接 JDBC 和提交 SQL,但是基本原理和 jsp 完全一样。
3、启动 tomcat,在浏览器中访问 http://localhost:8080/DW/jdbc.jsp,查看结果。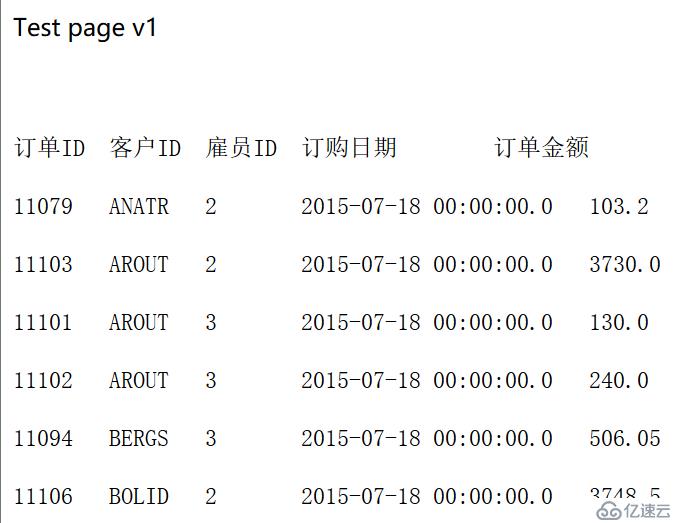
还可以继续测试如下情况:
1、分组汇总
sql ="select CUSTOMERID,EMPLOYEEID,sum(AMOUNT) 订单总额,count(1) 订单数量 from ORDERS.ctx where ORDERDATE=date(‘2015-07-18’) group by CUSTOMERID,EMPLOYEEID";
2、并行查询
sql="select /*+ parallel (4) */ top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS.ctx where ORDERDATE=date(‘2015-07-18’) and AMOUNT>100"sql="select /*+ parall el (4) */top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS.ctx where ORDERDATE=date(‘2015-07-18’) and AMOUNT>100"
和 ORACLE 类似,集算器简单 SQL 也支持 /*+ parallel (4) */ 这样的并行查询。
第一种解决办法是利用应用服务器的资源。在并发量很大,或者数据量很大的情况下,应用服务器会出现较大压力。这种情况下,推荐用独立的节点服务器进行数据计算。
集算器 JDBC 接收到 SQL 后,转给 DW.dfx 程序处理。DW.dfx 调用节点服务器上的 DWServer.dfx 进行计算。DWServer.dfx 把表名换成文件名,查本地文件 orders.ctx 返回结果。
下面的 DWServer 目录复制到需要的目录。集算器的节点服务器具备跨平台的特性,可以运行在任何支持 Java 的操作系统上,部署方法参见集算器教程。这里假设放到 windows 操作系统的 C 盘根目录。
DWServer
1、系统上线之前执行初始化 dfx,将 orders.ctx 文件放到 C:/DWServer/data 目录中。测试的时候可以直接将已经生成好的 orders.ctx 复制过去。
2、修改前面的 dfx,将 A1 改为 =file(“C:/DWServer/data/orders.ctx”),另存为 etlUpdate2.dfx。修改好的 etlUpdate2.dfx 在 c:\DWServer 目录。
3、打开应用服务器中的 C:\\tomcat6\\webapps\\DW\\WEB-INF\\dfx\\DW.dfx,观察理解 SPL 代码。参数 sql 是传入的 SQL 语句。
| A | B | |
|---|---|---|
| 1 | =callx(“DWServer.dfx”,[sql];[“127.0.0.1:8281”]) | |
| 2 | return A1.ifn() |
A1:调用节点机上的 DWServer.dfx。参数是 [sql],中括号表示序列,此时是只有一个成员的序列。[“127.0.0.1:8281”] 是节点机的序列,采用 IP: 端口号的方式。
A2:返回 A1 调用的结果。因为调用结果是序列,所以要用 ifn 函数找到序列中第一个不为空的成员,就是 SQL 对应的返回结果。
修改 C:\\tomcat6\\webapps\\DW\\WEB-INF\\classes\\raqsoftConfig.xml 中的如下配置:
<mainPath>C:\\tomcat6\\webapps\\DW\\WEB-INF\\dfx</mainPath> <JDBC> <load>Runtime,Server</load> <gateway>DW.dfx</gateway> </JDBC><mainPath>C:\\tomcat6\\webapps\\DW\\WEB-INF\\dfx</mainPath><JDBC><load>Runtime,Server</load><gateway>DW.dfx</gateway></JDBC>
这里标签的内容就是 JDBC 网关 dfx 文件。在 BI 系统中调用集算器 JDBC 时,所执行的 SQL 都将交由网关文件处理。如果不配置这个标签,JDBC 提交的语句会被集算器当作脚本直接解析运算。
4、启动节点服务器。
运行 esprocs.exe, 如下图: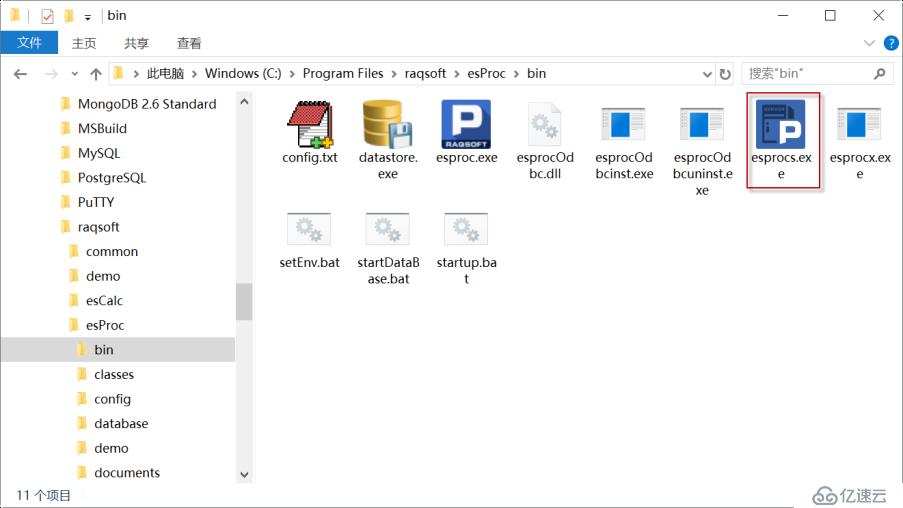
点击配置按钮,配置相关参数: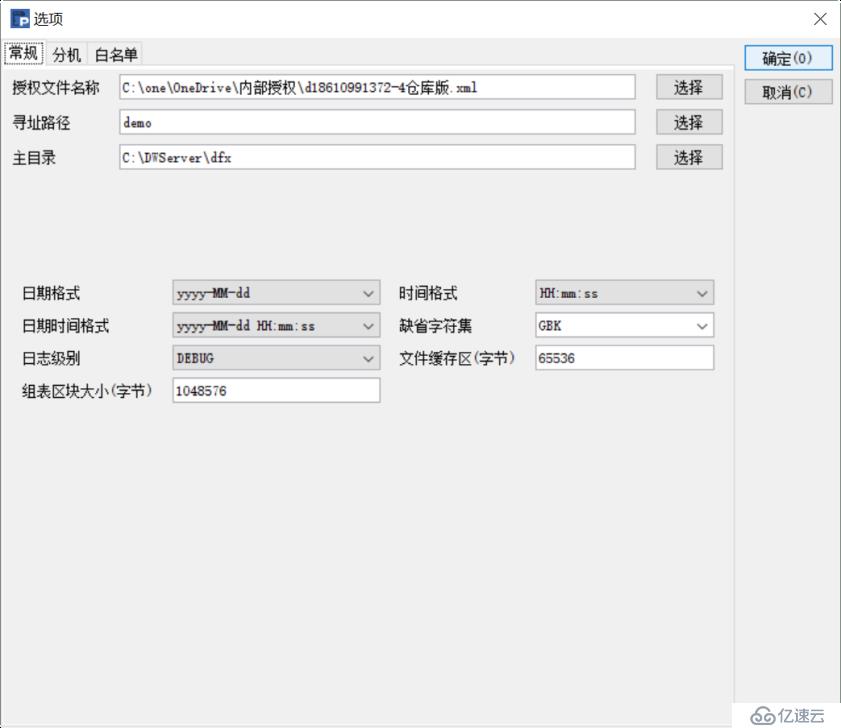
点击确定后,返回主界面,点击启动按钮。
5、打开 C:\DWServer\dfx\DWServer.dfx,观察理解 SPL 代码。
| A | B | C | |
|---|---|---|---|
| 1 | =filename=”C:/DWServer/data/orders.ctx” | ||
| 2 | =sql=replace(sql,”from ORDERS.ctx”,”from “+filename) | ||
| 3 | =connect() | =A3.cursor@x(A2) | return B3 |
A1:定义集算器集文件的绝对路径。
A2:将文件名替换为绝对路径。
A3-C3:连接文件系统。执行 SQL 得到游标并返回。
服务器方式也可以和“应用结构一”中一样配置主目录,A2 就不用写绝对路径了。路径写在这里的 SPL 中,好处是同一个服务器可以给多套数据表(文件)提供服务。如果很多文件都在主目录下,会不方便管理。
6、重启 tomcat,在浏览器中访问 http://localhost:8080/DW/jdbc.jsp,查看结果。
在并发量不断增大,或者数据量不断增加的情况下,节点服务器可以进行横向扩展,应对大并发或大数据量计算的压力。
1、在另一台 window 的机器上再部署一套集算器节点,部署方法和解决方法二略有不同,需要配置一下数据分区。两台服务器的 IP 地址是 168.0.122 和 192.168.0.176。方法二中的 c:\\DWServer 目录也要复制到另一台服务器上。
图中数据分区名称配置为 0,路径是 c:/DWServer/data。注意,两个服务器都要配置。
2、改写 168.0.122 上的 c:/DWServer/dfx/etlUpdate2.dfx,另存为 etlUpdate3.dfx。
| A | B | C | |
|---|---|---|---|
| 1 | =connect(“orcl”) | ||
| 2 | =A1.cursor@d(“select ORDERDATE,CUSTOMERID,EMPLOYEEID,ORDERID,AMOUNT from ORDERS where ORDERDATE=? order by ORDERDATE,CUSTOMERID,EMPLOYEEID,ORDERID”,etlDate) | ||
| 3 | =file(“C:/ DWServer/data/orders.ctx”) | ||
| 4 | =A3.create() | =A4.append(A2) | =A3.rollback() |
| 5 | >A1.close() | ||
| 6 | =sync([“192.168.0.176:8281″]:”192.168.0.122:8281”;0) |
A6 单元格是将更新之后的 orders.ctx 同步到 192.168.0.176 的 0 分区,也就是 C:/ DWServer/data 目录。[“192.168.0.176:8281”] 是指需要同步的节点机列表,如果有更多的节点机需要同步,可以写作:[“IP1:PORT1″,”IP2:PORT2″,”IP3:PORT3”]。
因为这里有同步的代码,所以只需要在 192.168.0.122 上执行定时任务 etlUpdate3.dfx 就可以了。
3、打开应用服务器中的 C:\tomcat6\webapps\DW\WEB-INF\dfx\DW.dfx,修改如下:
| A | B | |
|---|---|---|
| 1 | =callx(“DWServer.dfx”,[sql];[“192.168.0.122:8281″,”192.168.0.176:8281”]) | |
| 2 | return A1.ifn() |
A1:调用节点机上的 DWServer.dfx。参数是 [sql],中括号表示序列,此时是只有一个成员的序列。因为节点机是集群,所以有两个 IP 地址。在多并发时 callx 会随机访问两个节点。
4、重启 tomcat,在浏览器中访问 http://localhost:8080/DW/jdbc.jsp,查看结果。
集算器是专业的数据计算中间件(DCM),具备独立计算的能力,可以脱离数据库、数据仓库为多维分析系统前端提供数据源服务。
集算器采用列存数据,具备专业数据仓库的查询性能,千万级别的数据量,可以达到秒级的明细查询速度。普通数据库一般都是行存,无法达到多维分析的性能要求。同时,和专业数据仓库不同,集算器价格都较低,建设、扩展和维护成本都比较小。
集算器是开放的,对多维分析系统前端提供标准的 JDBC 服务。可以形成平台式的后台数据源,为多个不同厂家的前端同时提供数据服务。
先进的数据存储方式,是数据计算中间件(DCM)成功实施的重要保障。
集算器组表采用列存方式存储数据,对于字段特别多的宽表查询,性能提升特别明显。组表采用的列存机制和常规列存是不同的。常规列存(比如 parquet 格式),只能分块之后,再在块内列存,在做并行计算的时候是受限的。组表的可并行压缩列存机制,采用倍增分段技术,允许任意分段的并行计算,可以利用多 CPU 核的计算能力把硬盘的 IO 发挥到极致。
组表生成的时候,要指定维字段,数据本身是按照维字段有序存放的,常用的条件过滤计算不依赖索引也能保证高性能。文件采用压缩存储,减小在硬盘上占用的空间,读取更快。由于采用了合适的压缩比,解压缩占用的 CPU 时间可以忽略不计。
组表也可以采取行存和全内存存储数据,支持内存数据库方式运行。
敏捷的集群能力可以保证数据计算中间件(DCM)的高性能和高可用性。
集算器节点服务器是独立进程,可以接受集算器 JDBC 的计算请求并返回结果。对于并发访问的情况,可以发给多个服务器同时计算,提高并发容量。对于单个大计算任务的情况,可以分成多个小任务,发给多个服务器同时计算,起到大数据并行计算的作用。
集算器集群计算方案,具备敏捷的横向扩展能力,并发量或者数据量大时可以通过快速增加节点来解决。集算器集群也具备容错能力,即有个别节点失效时还能确保整个集群能工作,计算任务能继续执行完毕,起到多机热备和保证高可用性的作用。
作为数据计算中间件(DCM),集算器提供的后台数据源可以支持各种前端应用,不仅仅限于前端是多维分析的情况。例如:大屏展示、管理驾驶舱、实时报表、大数据量清单报表、报表批量订阅等等。
集算器形成的后台数据源也可以和数据库、数据仓库配合使用。集算器实现的数据计算网关和路由,可以在集算器缓存数据和数据仓库之间智能切换,解决数据仓库无法满足性能要求的问题。例如:冷热数据分开计算的场景。具体做法参见《集算器实现计算路由优化 BI 后台性能》。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





