小编给大家分享一下flink为什么会成为最火计算引擎,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
我是在两年前随公司参加一个会议上知道的Flink,那是一家做大数据安全的公司,利用大数据分析安全威胁预警。当时会议上他们展示了三种流计算技术,大家应该都知道,也就是最常见的Storm、SparkStreaming与Flink。Storm的标记是‘过去’,SparkStreaming的标记是‘现在’,而Flink上的标记是‘未来’。当时我们的业务没有实时处理,所以对这方面不了解。但是我就记住了‘未来’这两个字。
后来业务中增加了实时计算相关的处理,那么开始之前就对实时计算的三种技术做了一些调研。Storm,SparkStreaming,FLink。其实本身也没做什么相关的调研,只是基于当时的那场会议,直接排除了Storm。仅在SparkStreaming与Flink之间做了选型。而最终选择了FLink。
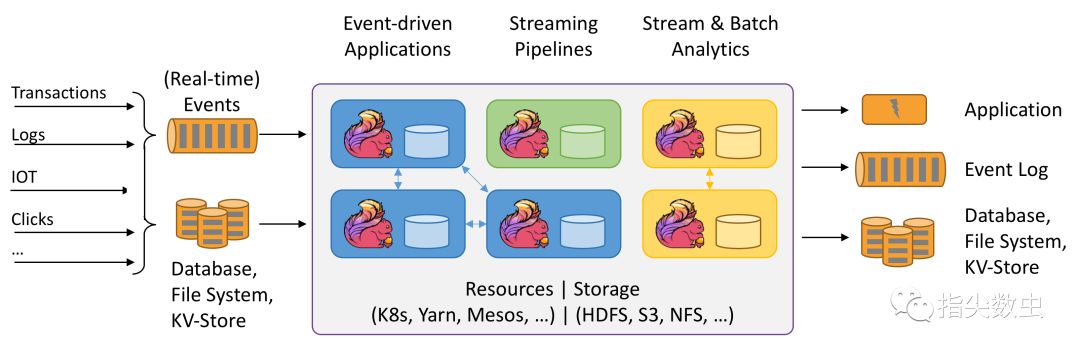
高吞吐,低延迟,高性能
针对于这三个特性,Flink在社区内属于唯一,也就是唯一一个能够同时支持三种特性的实时处理框架。而其他的SparkStreaming,Storm等均无法同时支持三个特性,SparkStreaming是micro batch处理的特性,所以本身无法做到低延迟的保障,仅能做到高性能,高吞吐。Storm只能支持高性能与低延迟。
所以在实际业务使用中,同时保证三个特性的框架对于选型来说是至关重要的。
支持event time,process time,igest time
FLink支持事件时间,也就是数据本身的时间,事件时间对于计算、处理等至关重要,能够防止对于出现乱序到达而造成的数据计算错误。保持数据原本的时序性,避免由于网络、硬件等造成的计算结果的误差。
而其他系统采用的处理时间,系统时间等可能就会由于网络、硬件、甚至是系统启动问题都会造成数据的计算错误。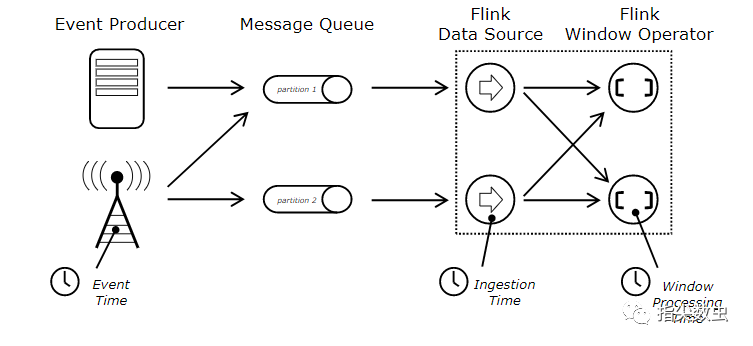
有状态计算
Flink中包含状态管理,能够通过数据计算的中间结果状态存储到内存或文件中,等下一批事件到来的时候即可获取到状态信息接续统计结果。这样由于无需再次重新计算将会极大的提升系统的性能。
灵活的窗口机制
在实时处理的场景中,数据是连续不断的。实时处理的场景中同样包含对于一段范围数据的处理,例如一分钟,100条等场景。那么Flink中提供窗口机制实现灵活的数据切割办法,对100条数据或一分钟等计算提供简单的实现方案。
Flink提供的窗口如上有数据驱动,时间驱动。窗口可以划分为滚动窗口,翻滚窗口,会话窗口等。窗口自由组合实现不同的数据场景。
高容错性
Flink提供了容错机制,对于数据处理过程中由于硬件、网络等问题造成的集群异常均可以通过容错机制进行恢复。容错性保证了数据的exactly-once
其实当时选择Flink是非常的不合理的,当时主流的实时处理框架还是SparkStreaming,Flink在当时占比还是很低,相关的书籍,文档完全不足。对于前方有多少的坑多大的坑完全不了解。最终磕磕碰碰的把相关的需求实现。
调研本身对于技术的是市场占比还是很需要关注的,毕竟是小公司很难有阿里云那种能够专门的抽取一个小团队对于新技术进行跟进,甚至是拉分支进行开发。调研技术本身可能对于该技术前方有多少坑了解清楚更重要。对于公司,业务来讲没有完美的技术,只有最合适的技术。而对于创业公司来讲,能够实现快速迭代,快速学习,快速掌握,有人给趟平了坑更加重要。
以上是“flink为什么会成为最火计算引擎”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





