这篇文章主要介绍“Flink实时计算大促压测的方法是什么”,在日常操作中,相信很多人在Flink实时计算大促压测的方法是什么问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Flink实时计算大促压测的方法是什么”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
一、背景:
临近双11大促,为避免流量峰值较高,电商公司都会对系统进行压测。一直做实时数据计算,应用是基于Flink做的,接收kafka消息,进行数据统计,包括:pv、uv、dau、单量、成交额等等。
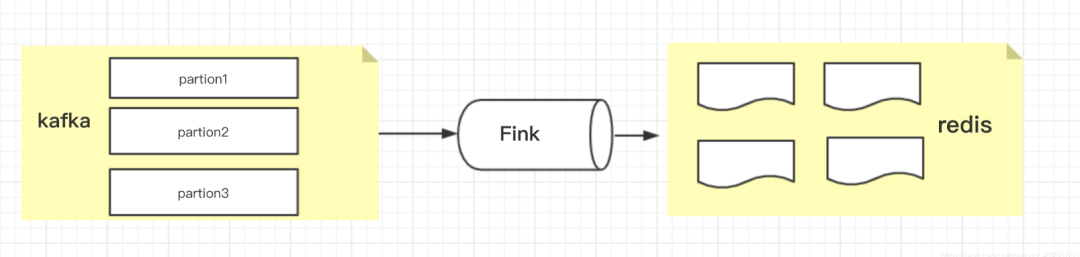
为了保证应用在大促期间不出问题,需要进行实时计算程序进行压测。由于统计的数据分为两类(流量数据、订单数据),对这两类数据进行不同方式的压测。
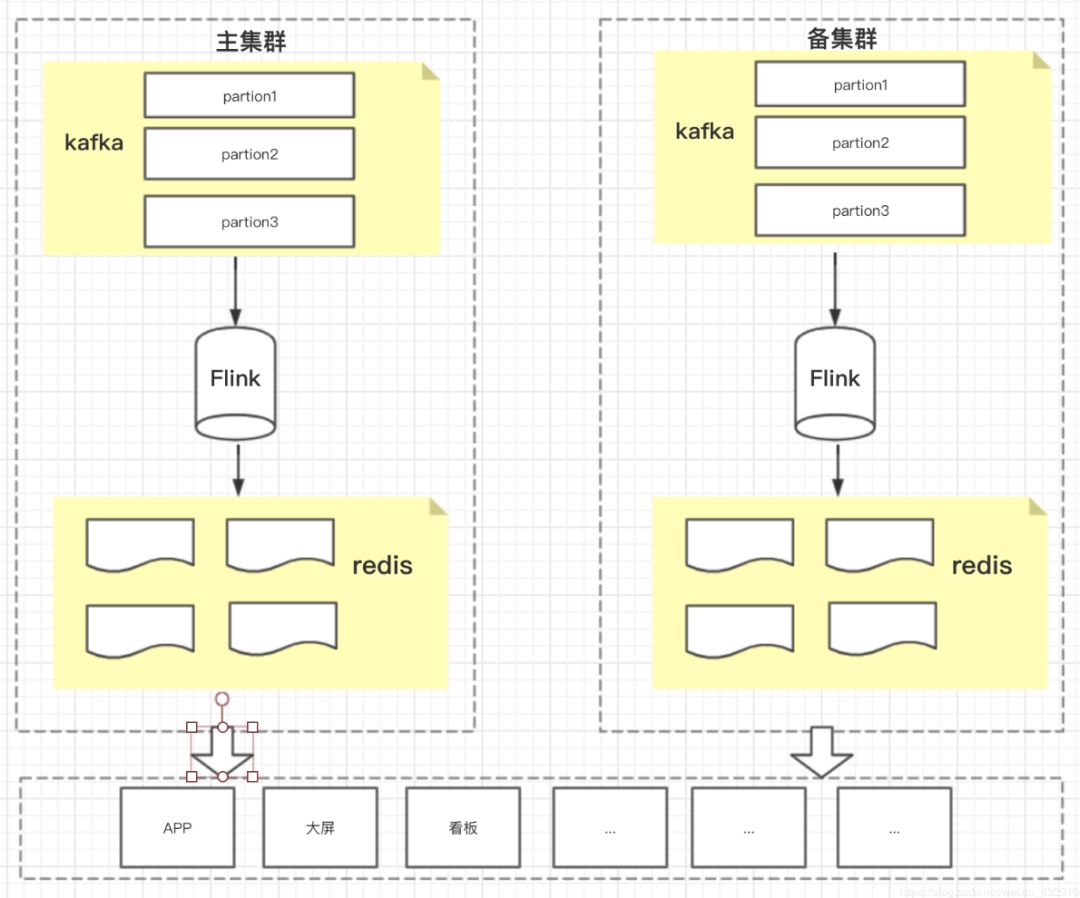
二、压测准备
(1)压测时间选择:一般选择在凌晨,对业务影响最小
(2)集群准备:搭建主备集群,将kafka集群、Flink集群、redis集群,分别搭建两套,在资源有充裕的情况下。(主备集群既能够做到容灾、高可用,也能在压测过程,轻松实现压测)
(3)如果资源有限,不能搭建主备集群,也能进行压测,但是在灾备和高可用方面就没办法保证了
三、压测实践
情况一:有主备集群的情况下(压测比较简单)
(1)通知下游,将查询的数据切换另外一套集群上(不进行压测的集群)
(2)将kafka消息位点进行调整,将消息挤压量调整至去年大促的峰值的几倍左右
(3)重启Flink应用
(4)查看监控:kafka监控、Flink监控
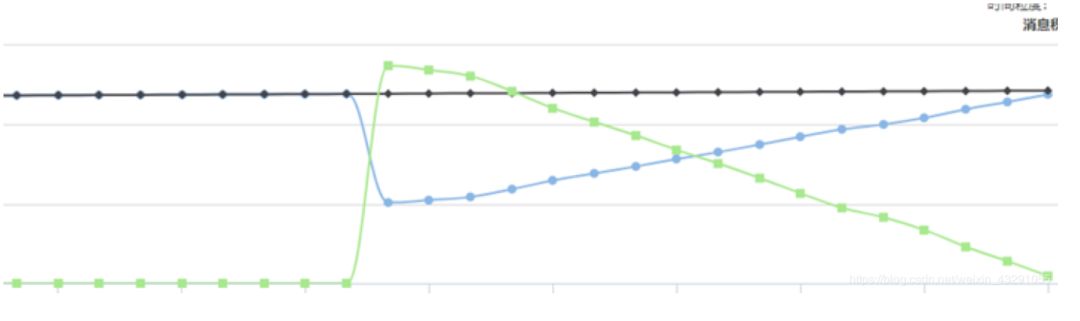
kafka消息挤压监控
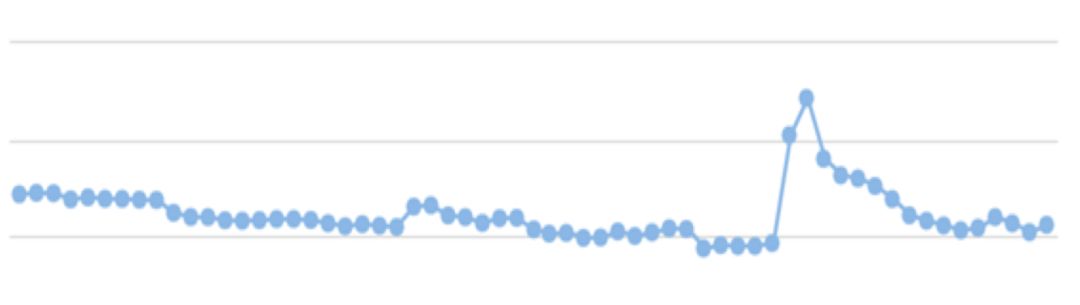
Flink数据处理监控
情况二:没有主备集群的情况下(由于没有主备集群,压测可能会对下游统计数据存在影响,需要通知下游)
1.流量数据压测(由于数据量较大不好做幂等处理,对下游影响较大)
(1)通知下游,将压测安排在凌晨进行
(2)停止Flink应用,造成消息挤压,达到挤压数量
(3)启动Flink应用,开始消费,查看各项监控指标
注:没有采用回置kafka消息位点,而是进行憋数,只造成短时间下游数据指标短时间不可用,整体影响不大
2.订单数据压测
没有幂等处理,同样可以采用流量的方法进行压测
有幂等处理
(1)通知下游,进行压测
(2)回置kafka消息位点
(3)重启Flink应用,开始消费,查看各项监控指标
注:由于幂等处理,回置位点,不会对下游统计数据造成影响
到此,关于“Flink实时计算大促压测的方法是什么”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





