本篇内容主要讲解“Lucene索引过程是怎样的”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Lucene索引过程是怎样的”吧!
Lucene 总的来说是:
一个高效的,可扩展的,全文检索库。
全部用 Java 实现,无须配置。
仅支持纯文本文件的索引(Indexing)和搜索(Search)。
不负责由其他格式的文件抽取纯文本文件,或从网络中抓取文件的过程。
在 Lucene in action 中,Lucene 的构架和过程如下图,
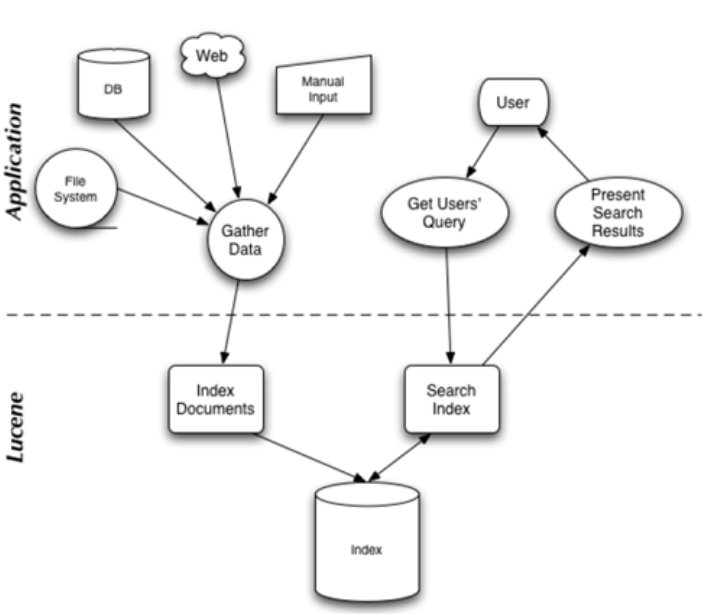
说明 Lucene 是有索引和搜索的两个过程,包含索引创建,索引,搜索三个要点。
让我们更细一些看 Lucene 的各组件:
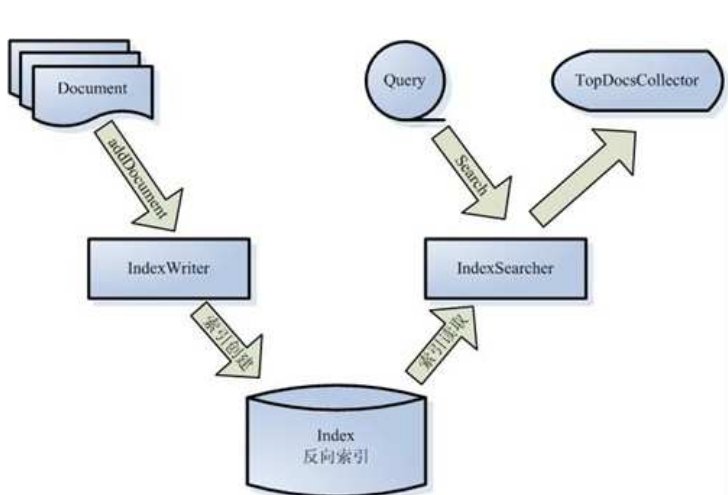
被索引的文档用 Document 对象表示。
IndexWriter 通过函数 addDocument 将文档添加到索引中,实现创建索引的过程。
将文档添加到索引中,实现创建索引的过程。
Lucene 的索引是应用反向索引。
当用户有请求时,Query 代表用户的查询语句。
IndexSearcher 通过函数 search 搜索 Lucene Index。
IndexSearcher 计算 term weight 和 score 并且将结果返回给用户。
返回给用户的文档集合用 TopDocsCollector 表示。
那么如何应用这些组件呢?
让我们再详细到对 Lucene API 的调用实现索引和搜索过程。
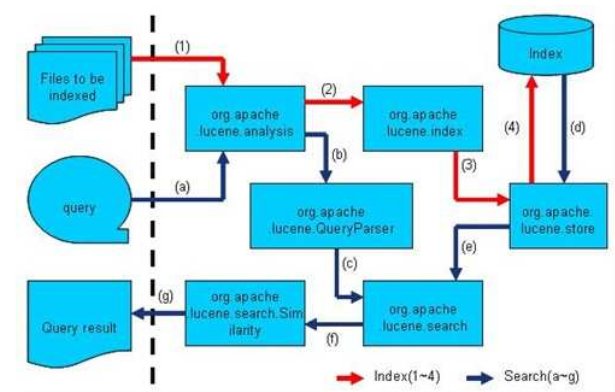
Lucene 的 analysis 模块主要负责词法分析及语言处理而形成 Term。。
Lucene 的 index 模块主要负责索引的创建,里面有 IndexWriter。
Lucene 的 store 模块主要负责索引的读写。
Lucene 的 QueryParser 主要负责语法分析。
Lucene 的 search 模块主要负责对索引的搜索。
Lucene 的 similarity 模块主要负责对相关性打分的实现。
到此,相信大家对“Lucene索引过程是怎样的”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/sunzy/blog/193785



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



