这篇文章主要介绍“flume的功能是什么”,在日常操作中,相信很多人在flume的功能是什么问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”flume的功能是什么”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
flume自带写hdfs的组建 hdfs sink,功能和性能都不错,就是有些缺点不好克服。
1,收集的日志一直在写hadoop,虽然可以订一个规则间断写hadoop,例如设置batchSize等,但在大压力下,几乎可以认为是每时每刻都在写hafs.
2,容错性差,日志收集的过程中,hadoop出现错误(例如,hdfs丢块)等问题,就会崩溃。
3,还有4,5等等,就是hdfs sink 有些问题了,不写了。
这里写一个先收集日志到本地,形成文件,然后把这个文件上载到远程的hadoop上。
这样做有好处,
1,日志收聚到本地文件。在收集日志过程中出现的hadoop错误、异常等等文件,在收集日志成文件的工程中不存在。
2,上传到hadoop采用文件的方式,使用hadoop自己的fs API,可以有很好的效率。
3,很好的容错机制,上传文件的工程中出现hadoop问题,导致文件上传失败,没关系,下一个工作任务再上传就好了,只有上传成功才删除本地文件。
4,还有好多了,这里不写了。
大致的架构
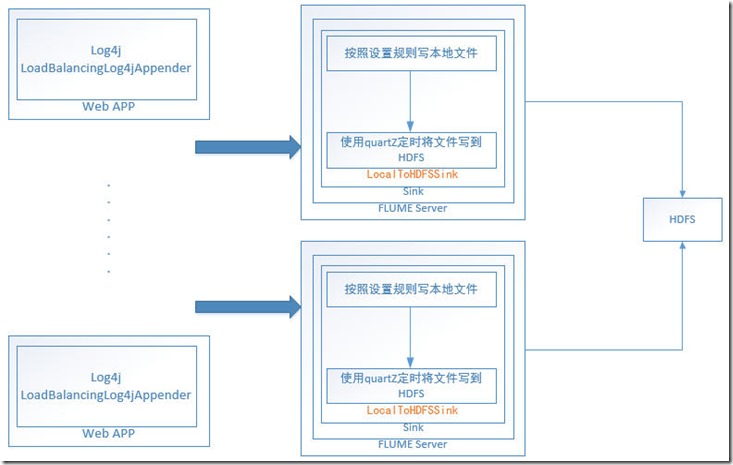
这里做假单的解释:
LocalToHDFSSink.java 就是flume sink的启动类,在配置文件中要做配置的,a1.sinks.k1.type = com.fone.flume.sink.localFile.LocalToHDFSSink
其中如下代码:
@Overridepublic void start() {
......
CronTriggerFileHDFS cronTriggerFileHDFS = new CronTriggerFileHDFS();
LOG.info("定时器设置,cron expression :{} .", cronExpression);try {
cronTriggerFileHDFS.run(filePath, hdfsPath, cronExpression, isKeep);
} catch (Exception e) {
LOG.warn("向hdfs写文件的定时器错误,错误:{}.", e);
}
sinkCounter.start();
......
}@Overridepublic void stop() {
......if (cronTriggerFileHDFS != null) {try {
cronTriggerFileHDFS.shutdown();
} catch (Exception e) {// TODO Auto-generated catch block e.printStackTrace();
}
}
......
}开关定时器。
定时器设定:a1.sinks.k1.local.cronExpression = 0 */15  * * * ? 按照quartZ的设置要求进行设置,不了解者去看quartZ cronTigger设置。
LocalToHDFSSink的文件存储是这样的,本地文件给定一个初始的目录a1.sinks.k1.local.directory,日志在这个初始的目录存储,动态的目录结构通过a1.sinks.k1.local.middleDir 设置。
远程的hadoop给定一个初始的目录a1.sinks.k1.hdfs.directory ,其它的目录结构和文件与本地的设置完全相同,也就是把a1.sinks.k1.local.directory目录下的所有内容,复制到a1.sinks.k1.hdfs.directory 完成工作。
日志收集文件在本地产生,没有完成的时候,带文件名后缀.tmp,完成后去掉.tmp,以此作为是否现在执行复制到hadoop的标志。
其余的看代码吧。
到此,关于“flume的功能是什么”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





