这篇文章将为大家详细讲解有关HBase如何管理以及性能调优,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
因为 HBase 运行在 JVM,JVM 的 Garbage Collection(GC) 设置对于 HBase 流畅的运行,更高的性能是非常重要的,除了配置 HBase 堆设置的指导方针之外。有 HBase 进程输出到它们的 GC 日志中是同样重要的,并且它们基于 GC 日志的输出调整 JVM 设置。
我将描述最重要的 HBase JVM 堆设置,也描述怎样是它生效以及理解 GC 日志,在这方面。我将覆盖一些指导方针来调整 HBase 的 Java GC 设置。
登陆你的 HBase region 服务器。
以下被建议用于 Java GC 和 HBase 堆设置:
通过编辑 hbase-env.sh 文件给 HBase 足够大的堆大小。比如,以下片段给 HBase 配置一个 8000-MB 的堆:
$ vi $HBASE_HOME/conf/hbase-env.shexport HBASE_HEAPSIZE=8000
通过以下命令使得 GC 日志生效:
export HBASE_OPTS="$HBASE_OPTS -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:/usr/local/hbase/logs/gc-hbase.log"
把以下代码加入来比默认更早的开始 Concurrent-Mark-Sweep GC(CMS):
$ vi $HBASE_HOME/conf/hbase-env.shexport HBASE_OPTS="$HBASE_OPTS -XX:CMSInitiatingOccupancyFraction=60"
在集群中同步变更并重启 HBase。
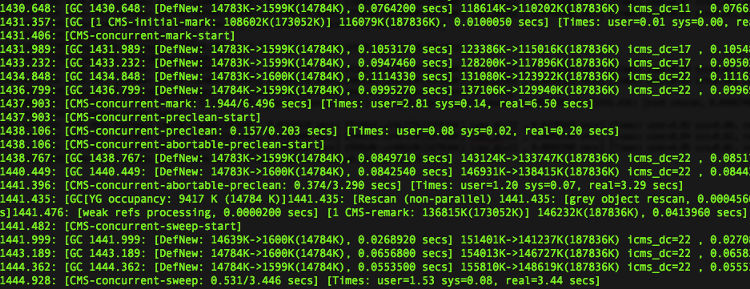
检查输出到指定日志文件中(/usr/local/hbase/logs/gc-hbase.log)的 GC 日志。GC 日志看起来像以下屏幕截图:
在步骤 1 中,我们配置 HBase 堆内存大小。默认,HBase 使用 1GB 的堆,这对于现代的机器来说太低了。对于 HBase 来说,比 4GB 更大是好的。我们建议 8GB 或更大,但是低于 16 GB。
在步骤 2 中,我们是 JVM 日志生效,使用这个设置,你可以获取 region 服务器的 JVM 日志,和我们在步骤 5 中展示的类似。关于 JVM 内存分配和垃圾回收的基础知识是被要求的,为了明白日志输出。以下是 JVM 分代垃圾收集系统的图表:
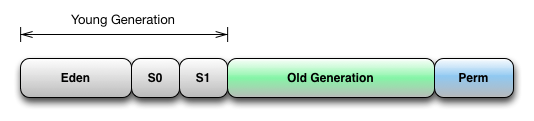
这里有 3 个堆分代:Perm(或是 Permanent)代【永久代】,Old Generation 代【老年代】,和 Young 代【年轻代】。年轻代由三个独立的空间组成,Eden 空间和两个 survivor 空间,S0 和 S1。
通常,对象被分配在年轻代的 Eden 空间,如果一个分配失败(Eden 满了),所有 java 线程停止,并且一个年轻代 GC(Minor GC)被调用。所有在年轻代存活的对象(Eden 和 S0 空间)被拷贝到 S1 空间。如果 S1 空间满了,对象被拷贝(提升)到老年代。当一个提升失败,老年代被收集(Major/Full GC)。永久代和老年代通常一起被收集。永久代被用于在存放类和对象中定义的方法。
回到我们示例的步骤 5,上述选项产出的 minor GC 输出为以下形式:
<timestamp>: [GC [<collector>: <starting occupancy1> -> <ending occupancy1>, <pause time1> secs] <starting occupancy3> -> <ending occupancy3>, <pause time3> secs] [Times: <user time> <system time>, <real time>]
在这个输出中:
timestamp 是 GC 发生的时间,相对于应用的启动时间。
collector 是 collector 用于 minor collection 的内部名字
starting occupancy1 是年轻代在垃圾回收前的占用
ending occupancy1 是年轻代在垃圾回收后的占用
pause time1 是 minor collection 中断的时间
starting occupancy3 是在垃圾回收前整个堆的占用
ending occupancy3 是在垃圾回收后整个堆的占用
pause time3 是整个垃圾回收的中断时间,这包括 major collection。
[Time:] 解释了花费在垃圾收集的时间,用户时间,系统时间,实际时间。
在步骤 5 中我们输出的第一行表明了是一个 minor GC,中断了 JVM 0.0764200 秒,它已经把年轻代的空间从 14.8MB 降低到 1.6MB。
接着,我们看看 CMS GC 日志,HBase 使用 CMS GC 作为它默认的老年代垃圾回收器。
CMS GC 执行以下步骤:
初始化标记
并发标记
重复标记
并发休眠
CMS 仅仅在它初始化标记和重复标记的阶段中断应用进程。在并发标记和睡眠阶段,CMS 线程随着应用线程一起运行。
在该示例的第二行表明了 CMS 初始化标记花费了 0.0100050 秒,并发标记花费了 6.496 秒。注意,并发标记,Java 不会被中断。
在 GC 日志的早期屏幕截图中,在行开始于 1441.435: [GC[YG occupancy:…] 的地方有一个中断。这里的中断是 0.0413960 秒,用于重复标记堆。之后,你可以看到睡眠开始了。CMS 睡眠花费了 3.446 秒,但是堆大小在这里没有变化太多(它继续占据大约 150MB)。
这里的调整点是使得所有的中断时间更低。为了保持中断时间更低,你需要使用 -XX:NewSize 和 -XX:MaxNewSize JVM 参数调整年轻代空间大小,为了将它们设置为相对较小的值(比如,调高几百 MB)。如果服务器有更多的 CPU 资源,我们建议通过设置 -XX:+UseParNewGC 选项使用 Parallel New Collector。你或许也想为你的年轻代调整 parallel GC 线程数量,通过 -XX:ParallelGCThreads JVM 参数。
我们建议加入上述设置到 HBASE_REGIONSERVER_OPTS 变量中,代替 hbase-env.sh 文件中的 HBASE_OPTS 变量。HBASE_REGIONSERVER_OPTS 仅仅影响 region 服务器的进程,这非常好,因为 HBase master 既不处理重型任务也不参与数据处理。
对于老年代来说, concurrent collection (CMS) 通常不能被加速,但是它可以更早的开始。当分配在老年代的空间比率超过了一个阀值,CMS 开始运行。这个阀值是被收集器自动计算的。对于有些情况,特别是在加载期间,如果 CMS 开始的太晚,HBase 或许会直接进行 full garbage collection。为了避免这个,我们建议设置 -XX:CMSInitiatingOccupancyFraction JVM 参数来精确指定在多少百分比 CMS 应该被开始,正如我们在步骤 3 中做的那样。在 百分之 60 或 70 开始是一个好的实践。当老年代使用 CMS,默认的年轻代 GC 将被设置成 Parallel New Collector。
如果你之前使用的是 HBase 0.92 版本,考虑使用 MemStore-Local 分配 Buffer 来预防老年代堆碎片,在频繁写的负载下:
$ vi $HBASE_HOME/conf/hbase-site.xml <property> <name>hbase.hregion.memstore.mslab.enabled</name> <value>true</value> </property>
这个特性在 HBase 0.92 中是默认开启的。
HBase 另外一个最重要的特性就是使用压缩。它是非常重要的,因为:
压缩降低从 HDFS 读写的字节数
节约磁盘空间
当从一个远程服务器获取数据的时候,提升了网络带宽的效率
HBase 支持 GZip 和 LZO 格式,我的建议是使用 LZO 压缩算法,因为它解压数据快并且 CPU 使用率低。更好的压缩比是系统的首选,你应该考虑 GZip。
不幸的是,HBase 不能使用 LZO,因为 license 问题。HBase 是 Apache-licensed,然而 LZO 是 GPL-licensed。因此,我们需要自己安装 LZO。我们将使用 hadoop-lzo 库,给 Hadoop 带来了变形的 LZO 算法。
在这方面,我们将描述怎样安装 LZO 和怎样配置 HBase 使用 LZO 压缩。
确保在 hadoop-lzo 被构建的机器上 Java 安装了。Apache Ant 被要求用来从源码构建 hadoop-lzo。通过运行一下命令来安装 Ant:
$ sudo apt-get -y install ant
集群中的所有节点需要有原生的 LZO 库被安装。你可以通过使用以下命令安装:
$ sudo apt-get -y install liblzo2-dev
我们将使用 hadoop-lzo 库来给 HBase 添加 LZO 压缩支持:
从 https://github.com/toddlipcon/hadoop-lzo 获取最新的 hadoop-lzo 源码
从源码构建原生的 hadoop-lzo 库。依赖于你的 OS,你应该选择构建 32-bit 或 64-bit 的二进制包。比如,为了构建 32-bit 二进制包,运行以下命令:
$ export JAVA_HOME="/usr/local/jdk1.6"$ export CFLAGS="-m32"$ export CXXFLAGS="-m32"$ cd hadoop-lzo$ ant compile-native$ ant jar
这些命令将创建 hadoop-lzo/build/native 目录和 hadoop-lzo/build/hadoop-lzo-x.y.z.jar 文件。为了构建 64-bit 二进制包,你需要改变 CFLAGS 和 CXXFLAGS 成 m64。
拷贝构建的包到你master 节点的 $HBASE_HOME/lib 和 $HBASE_HOME/lib/native 目录:
hadoop@master1$ cp hadoop-lzo/build/hadoop-lzo-x.y.z.jar $HBASE_HOME/lib hadoop@master1$ mkdir $HBASE_HOME/lib/native/Linux-i386-32hadoop@master1$ cp hadoop-lzo/build/native/Linux-i386-32/lib/* $HBASE_HOME/lib/native/Linux-i386-32/
对于一个 64-bit OS,把 Linux-i386-32 改变成(在前面步骤中) Linux-amd64-64。
添加 hbase.regionserver.codecs 的配置到你的 hbase-site.xml 文件:
hadoop@master1$ vi $HBASE_HOME/conf/hbase-site.xml<property><name>hbase.regionserver.codecs</name><value>lzo,gz</value></property>
在集群中同步 $HBASE_HOME/conf 和 $HBASE_HOME/lib 目录。
HBase ships 使用一个工具来测试压缩是否被正确设置了。使用这个工具来在集群中的每个节点上测试 LZO 设置。如果一切都正确无误的配置了,你将得到成功的输出:
hadoop@client1$ $HBASE_HOME/bin/hbase org.apache.hadoop.hbase.util.CompressionTest /tmp/lzotest lzo12/03/11 11:01:08 INFO hfile.CacheConfig: Allocating LruBlockCache with maximum size 249.6m12/03/11 11:01:08 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library12/03/11 11:01:08 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev Unknown build revision]12/03/11 11:01:08 INFO compress.CodecPool: Got brand-new compressor12/03/11 11:01:18 INFO compress.CodecPool: Got brand-new decompressor SUCCESS
通过使用 LZO 压缩创建一个表来测试配置,并在 HBase Shell 中验证它:
$ hbase> create 't1', {NAME => 'cf1', COMPRESSION => 'LZO'}
$ hbase> describe 't1'DESCRIPTION
ENABLED
{NAME => 't1', FAMILIES => [{NAME => 'cf1', BLOOMFILTER =>
'NONE', true REPLICATION_SCOPE => '0', VERSIONS => '3', COMPRESSION => 'LZO',
MIN_VERSIONS => '0', TTL => '2147483647', BLOCKSIZE => '65536',
IN _MEMORY => 'false', BLOCKCACHE => 'true'}]}
1 row(s) in 0.0790 secondshbase.hregion.majorcompaction 属性指定了在 region 上所有存储文件之间的 major compactions 时间。默认是时间是 86400000,即一天。我们在步骤 1 中把它设置为 0,是禁止自动的 major compaction。这将预防 major compaction 在繁忙加载时间运行,比如当 MapReduce 任务正运行在 HBase 集群上。
换句话说, major compaction 被要求来帮助提升性能。在步骤 4 中,我们已经展示了通过 HBase Shell 怎样在一个特别的 region 上手动触发 major compaction 的示例。在这个示例中,我们已经传递了一个 region 名字给 major_compact 命令来仅仅在一台单独的 region 上调用 major compaction。它也可能在一张表中的所有 region 上运行 major compaction,通过传递表名给该命令。major_compact 命令为 major compaction 给指定的表或 region 排队;但是通过 region 服务器托管它们,这些将在后台执行。
正如我们在早前提到的,你或许仅仅想在一个低负载时期手动执行 major compaction。这可以很容易的通过一个定时任务调用 major_compact 来实现。
另外一个调用 major compaction 的方法就是使用 org.apache.hadoop.hbase.client.HBaseAdmin 类提供的 majorCompact API。在 Java 中非常容易调用这个 API。因此你可以从 Java 中管理复杂的 major compaction 调度。
通常一个 HBase 表从一个单独的 region 开始。尽管如此,因为数据保持增长和 region 达到了它配置的最大值,它自动分成两份,以至于它们能处理更多的数据。以下图表展示了一个 HBase region 拆分:
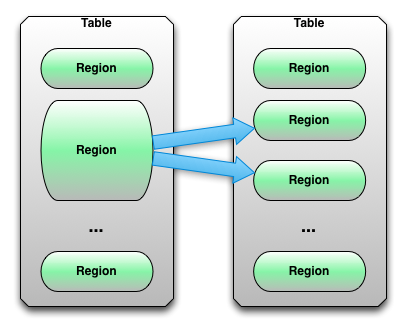
这是 HBase region 拆分的默认行为。这个原理在大多数情况下工作的很好,然而有遇到问题的情况,比如 split/ compaction 风暴问题。
随着统一的数据分布和增长,最后在表中的所有 region 都需要在同一时间拆分。紧接着一个拆分,压缩将在子 region 运行以重写他们的数据到独立的文件中。这会引起大量的磁盘 I/O 读写和网络流量。
为了避免这样的情况,你可以关闭自动拆分和手动调用它。因为你可以控制在何时调用拆分,它可以帮助扩展 I/O 负载。另一个优势是,手动拆分可以让你有更好的 regions 控制,帮助你跟踪和解决 region 相关的问题。
在这方面,我将描述怎样关闭自动 region 拆分和手动调用它。
使用你启动集群的用户登录进你的 HBase master 服务器。
为了关闭自动 region 拆分和手动调用它,遵循以下步骤:
在 hbase-site.xml 文件中加入以下代码:
$ vi $HBASE_HOME/conf/hbase-site.xml<property><name>hbase.hregion.max.filesize</name><value>107374182400</value></property>
在集群中同步这些变更并重启 HBase。
使用上述设置,region 拆分将不会发生直到 region 的大小到达了配置的 100GB 阀值。你将需要在选择的 region 上明确调用它。
为了通过 HBase Shell 运行一个 region 拆分,使用以下命令:
$ echo "split 'hly_temp,,1327118470453.5ef67f6d2a792fb0bd737863dc00b6a7.'" | $HBASE_HOME/bin/hbase shell HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 0.92.0, r1231986, Tue Jan 17 02:30:24 UTC 2012split 'hly_temp,,1327118470453.5ef67f6d2a792fb0bd737863dc00b6a7.'0 row(s) in 1.6810 seconds
hbase.hregion.max.filesize 属性指定了最大的 region 大小(bytes)。默认,值是 1GB( HBase 0.92 之前的版本是 256MB)。这意味着当一个 region 超过这个大小,它将拆分成两个。在步骤 1 中我们设置 region 最大值为 100GB,这是一个非常高的数字。
因为拆分不会发生直到超过了 100GB 的边界,我们需要明确的调用它。在步骤 4,我们在一个指定的 region 上使用 split 命令通过 HBase Shell 调用拆分。
不要忘记拆分大的 region。一个 region 在 HBase 是基础的数据分布和负载单元。Region 应该在低负载时期被拆分成合适的大小。
换句话说;太多的拆分不好,在一台 region 服务器上有太多的拆分会降低它的性能。
在手动拆分 region 之后,你或许想触发 major compaction 和负载均衡。
我们在前面的设置会引起整个集群有一个默认的 100GB 的region 最大值。除了改变整个集群,当在创建一张表的时候,也可以在一个列簇的基础上指定 MAX_FILESIZE 属性。
$ hbase> create 't1', {NAME => 'cf1', MAX_FILESIZE => '107374182400'}像 major compaction,你也可以使用 org.apache.hadoop.hbase.client.HBaseAdmin 类提供的 split API。
关于“HBase如何管理以及性能调优”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





