这篇文章给大家介绍Spark的HashPartitioner方式的Python实现是这样的,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
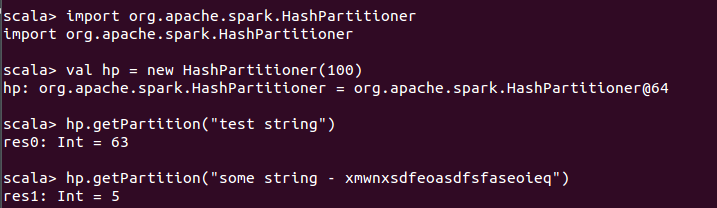
spark中的默认分区方式是org.apache.spark.HashPartitioner,具体代码如下所示:
class HashPartitioner(partitions: Int) extends Partitioner {
require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.")
def numPartitions: Int = partitions
def getPartition(key: Any): Int = key match {
case null => 0
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
override def equals(other: Any): Boolean = other match {
case h: HashPartitioner =>
h.numPartitions == numPartitions
case _ =>
false
}
override def hashCode: Int = numPartitions
}如果想要在Python中获取一个key的分区,只需要实现hashCode,然后取模。
hashCode的实现方式如下:
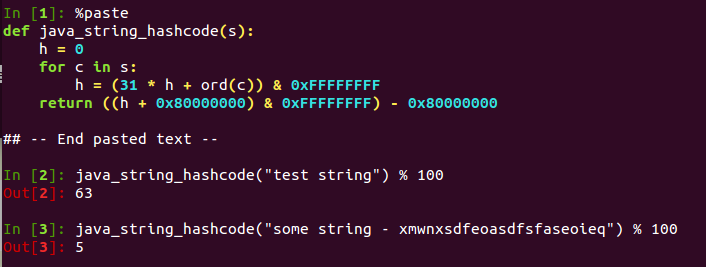
def java_string_hashcode(s): h = 0 for c in s: h = (31 * h + ord(c)) & 0xFFFFFFFF return ((h + 0x80000000) & 0xFFFFFFFF) - 0x80000000
验证
Scala实现
Python实现
关于Spark的HashPartitioner方式的Python实现是这样的就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





