本篇文章给大家分享的是有关怎么进行Spark Streaming 原理剖析,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
Spark Streaming 通过分布在各个节点上的接收器,缓存接收到的数据,并将数据包装成Spark能够处理的RDD的格式,输入到Spark Streaming,之后由Spark Streaming将作业提交到Spark集群进行执行,如下图:
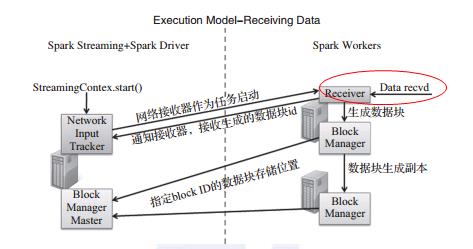
初始化的过程主要可以概括为两点。即:
1. 调度器的初始化。
调度器调度Spark Streaming的运行,用户可以通过配置相关参数进行调优。
2. 将输入流的接收器转化为Spark能够处理的RDD格式,并在集群进行分布式分配,然后启动接收器集合中的每个接收器。
针对不同的数据源,Spark Streaming提供了不同的数据接收器,分布在各个节点上的每个接收器可以认为是一个特定的进程,接收一部分流数据作为输入。
首先,先看看JavaStreamingContext的部分源码,说明能够接收一个Socket文本数据,也可以把文件当做输入流作为数据源,如下:
class JavaStreamingContext(val ssc: StreamingContext) extends Closeable {
def this(master: String, appName: String, batchDuration: Duration) =
this(new StreamingContext(master, appName, batchDuration, null, Nil, Map()))
def socketTextStream(hostname: String, port: Int): JavaReceiverInputDStream[String] = {
ssc.socketTextStream(hostname, port)
}
def textFileStream(directory: String): JavaDStream[String] = {
ssc.textFileStream(directory)
}
}eg:完成以下代码的时候:
val lines = ssc.socketTextStream("master", 9999)这样可以从socket接收文本数据,而其返回的是JavaReceiverInputDStream,它是ReceiverInputDStream的一个实现,内含Receiver,可接收数据,并转化为Spark能处理的RDD数据。
在来看看JavaReceiverInputDStream中的部分源码:
class JavaReceiverInputDStream[T](val receiverInputDStream: ReceiverInputDStream[T])
(implicit override val classTag: ClassTag[T]) extends JavaInputDStream[T](receiverInputDStream) {
}
object JavaReceiverInputDStream {
implicit def fromReceiverInputDStream[T: ClassTag](
receiverInputDStream: ReceiverInputDStream[T]): JavaReceiverInputDStream[T] = {
new JavaReceiverInputDStream[T](receiverInputDStream)
}
}通过源码了解JavaReceiverInputDStream是ReceiverInputDStream的一个实现,内含Receiver,可接收数据,并转化为RDD 数据,其部分源码如下:(注意英文注释)
abstract class ReceiverInputDStream[T: ClassTag](ssc_ : StreamingContext)
extends InputDStream[T](ssc_) {
/**
* Gets the receiver object that will be sent to the worker nodes
* to receive data. This method needs to defined by any specific implementation
* of a ReceiverInputDStream.
*/
def getReceiver(): Receiver[T]
// Nothing to start or stop as both taken care of by the ReceiverTracker.
def start() {}
/**
* Generates RDDs with blocks received by the receiver of this stream. */
override def compute(validTime: Time): Option[RDD[T]] = {
val blockRDD = {
if (validTime < graph.startTime) {
new BlockRDD[T](ssc.sc, Array.empty)
} else {
// Otherwise, ask the tracker for all the blocks that have been allocated to this stream
// for this batch
val receiverTracker = ssc.scheduler.receiverTracker
val blockInfos = receiverTracker.getBlocksOfBatch(validTime).getOrElse(id, Seq.empty)
// Register the input blocks information into InputInfoTracker
val inputInfo = StreamInputInfo(id, blockInfos.flatMap(_.numRecords).sum)
ssc.scheduler.inputInfoTracker.reportInfo(validTime, inputInfo)
// Create the BlockRDD
createBlockRDD(validTime, blockInfos)
}
}
Some(blockRDD)
}
}当调用 getReceiver()时候,过程如下:(SocketInputDStream的部分源码)
private[streaming]
class SocketInputDStream[T: ClassTag](
ssc_ : StreamingContext,
host: String,
port: Int,
bytesToObjects: InputStream => Iterator[T],
storageLevel: StorageLevel
) extends ReceiverInputDStream[T](ssc_) {
def getReceiver(): Receiver[T] = {
new SocketReceiver(host, port, bytesToObjects, storageLevel)
}
}而其实际上是 new 了一个SocketReceiver对象,并将之前的参数给传递进来,实现如下:
private[streaming]
class SocketReceiver[T: ClassTag](
host: String,
port: Int,
bytesToObjects: InputStream => Iterator[T],
storageLevel: StorageLevel
) extends Receiver[T](storageLevel) with Logging {
def onStart() {
// Start the thread that receives data over a connection
new Thread("Socket Receiver") {
setDaemon(true)
override def run() { receive() }
}.start()
}
/** Create a socket connection and receive data until receiver is stopped */
def receive() {
var socket: Socket = null
try {
logInfo("Connecting to " + host + ":" + port)
socket = new Socket(host, port)
logInfo("Connected to " + host + ":" + port)
val iterator = bytesToObjects(socket.getInputStream())
while(!isStopped && iterator.hasNext) {
store(iterator.next)
}
if (!isStopped()) {
restart("Socket data stream had no more data")
} else {
logInfo("Stopped receiving")
}
} catch {
//...
}
}
}对于子类实现这个方法,worker节点调用后能得到Receiver,使得数据接收的工作能分布到worker上。
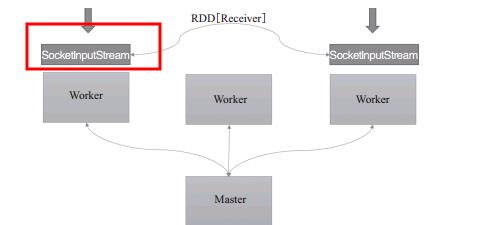
接收器分布在各个节点上,如下:
在上述“初始化与接收数据”步骤中,简单介绍了receiver集合转化为RDD,在集群上分布式地接收数据流,那么接下来将简单了解receiver是怎样接收并处理数据流。大致流程如下图:
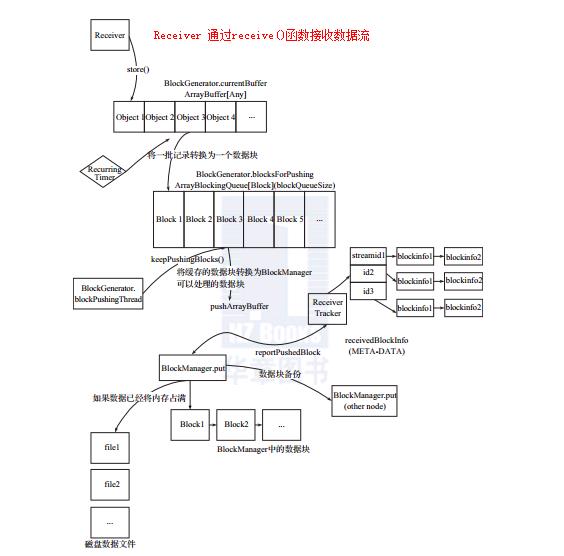
Receiver提供了一系列store()接口,eg:(更多请查看源码)
abstract class Receiver[T](val storageLevel: StorageLevel) extends Serializable {
def store(dataItem: T) {
supervisor.pushSingle(dataItem)
}
/** Store an ArrayBuffer of received data as a data block into Spark's memory. */
def store(dataBuffer: ArrayBuffer[T]) {
supervisor.pushArrayBuffer(dataBuffer, None, None)
}
}对于这些接口,已经是实现好了的,会由worker节点上初始化的ReceiverSupervisor来完成这些存储功能。ReceiverSupervisor还会对Receiver做监控,如监控是否启动了、是否停止了、是否要重启、汇报error等等。部分ReceiverSupervisor如下:
def createBlockGenerator(blockGeneratorListener: BlockGeneratorListener): BlockGenerator
private[streaming] abstract class ReceiverSupervisor(
receiver: Receiver[_],
conf: SparkConf
) extends Logging {
/** Push a single data item to backend data store. */
def pushSingle(data: Any)
/** Store an ArrayBuffer of received data as a data block into Spark's memory. */
def pushArrayBuffer(
arrayBuffer: ArrayBuffer[_],
optionalMetadata: Option[Any],
optionalBlockId: Option[StreamBlockId]
)
/**
* Create a custom [[BlockGenerator]] that the receiver implementation can directly control
* using their provided [[BlockGeneratorListener]].
*
* Note: Do not explicitly start or stop the `BlockGenerator`, the `ReceiverSupervisorImpl`
* will take care of it.
*/
def createBlockGenerator(blockGeneratorListener: BlockGeneratorListener): BlockGenerator
/** Start receiver */
def startReceiver(): Unit = synchronized {
//...
}
}ReceiverSupervisor的存储接口的实现,借助的是BlockManager,数据会以RDD的形式被存放,根据StorageLevel选择不同存放策略。默认是序列化后存内存,放不下的话写磁盘(executor)。被计算出来的RDD中间结果,默认存放策略是序列化后只存内存。
最根本原因是store函数内部的实现是调用了BlockGenerator的addData方法,最终是将数据存储在currentBuffer中,而currentBuffer其实就是一个ArrayBuffer[Any]。
BlockGenerator的 addData方法 源码如下: currentBuffer += data
/**
* Push a single data item into the buffer.
*/
def addData(data: Any): Unit = {
if (state == Active) {
waitToPush()
synchronized {
if (state == Active) {
currentBuffer += data
} else {
throw new SparkException(
"Cannot add data as BlockGenerator has not been started or has been stopped")
}
}
} else {
throw new SparkException(
"Cannot add data as BlockGenerator has not been started or has been stopped")
}
}而如何将缓冲数据转化为数据块呢?
其实在BlockGenerator内部存在两个线程:
(1)、定期地生成新的batch,然后再将之前生成的batch封装成block。这里的定期其实就是spark.streaming.blockInterval参数配置的,默认是200ms。源码如下:
private val blockIntervalMs = conf.getTimeAsMs("spark.streaming.blockInterval", "200ms")(2)、将生成的block发送到Block Manager中。
第一个线程:
第一个线程定期地调用updateCurrentBuffer函数将存储在currentBuffer中的数据封装成Block,至于块是如何产生的,即在 BlockGenerator中有一个定时器(RecurringTimer),将当前缓冲区中的数据以用户定义的时间间隔封装为一个数据块Block。源码如下:
private val blockIntervalTimer =
new RecurringTimer(clock, blockIntervalMs, updateCurrentBuffer, "BlockGenerator")然后将一批记录转化为的一个数据块放在blocksForPushing中,blocksForPushing是ArrayBlockingQueue[Block]类型的队列。源码如下:
private val blockQueueSize = conf.getInt("spark.streaming.blockQueueSize", 10)
private val blocksForPushing = new ArrayBlockingQueue[Block](blockQueueSize)其大小默认是10,我们可以通过spark.streaming.blockQueueSize参数配置(当然,在很多情况下这个值不需要我们去配置)。当blocksForPushing没有多余的空间,那么该线程就会阻塞,直到有剩余的空间可用于存储新生成的Block。如果你的数据量真的很大,大到blocksForPushing无法及时存储那些block,这时候你就得考虑加大spark.streaming.blockQueueSize的大小了。
updateCurrentBuffer函数实现如下源码:
/** Change the buffer to which single records are added to. */
private def updateCurrentBuffer(time: Long): Unit = {
try {
var newBlock: Block = null
synchronized {
if (currentBuffer.nonEmpty) {
val newBlockBuffer = currentBuffer
currentBuffer = new ArrayBuffer[Any]
val blockId = StreamBlockId(receiverId, time - blockIntervalMs)
listener.onGenerateBlock(blockId)
newBlock = new Block(blockId, newBlockBuffer)
}
}
if (newBlock != null) {
blocksForPushing.put(newBlock) // put is blocking when queue is full
}
} catch {
case ie: InterruptedException =>
logInfo("Block updating timer thread was interrupted")
case e: Exception =>
reportError("Error in block updating thread", e)
}
}第二个线程:
第二个线程不断地调用keepPushingBlocks函数从blocksForPushing阻塞队列中获取生成的Block,然后调用pushBlock方法将Block存储到BlockManager中。
private val blockPushingThread = new Thread() { override def run() { keepPushingBlocks() } }keepPushingBlocks实现源码如下:
/** Keep pushing blocks to the BlockManager. */
private def keepPushingBlocks() {
logInfo("Started block pushing thread")
def areBlocksBeingGenerated: Boolean = synchronized {
state != StoppedGeneratingBlocks
}
try {
// While blocks are being generated, keep polling for to-be-pushed blocks and push them.
while (areBlocksBeingGenerated) {
Option(blocksForPushing.poll(10, TimeUnit.MILLISECONDS)) match {
case Some(block) => pushBlock(block)
case None =>
}
}
// At this point, state is StoppedGeneratingBlock. So drain the queue of to-be-pushed blocks.
logInfo("Pushing out the last " + blocksForPushing.size() + " blocks")
while (!blocksForPushing.isEmpty) {
val block = blocksForPushing.take()
logDebug(s"Pushing block $block")
pushBlock(block)
logInfo("Blocks left to push " + blocksForPushing.size())
}
logInfo("Stopped block pushing thread")
} catch {
case ie: InterruptedException =>
logInfo("Block pushing thread was interrupted")
case e: Exception =>
reportError("Error in block pushing thread", e)
}
}pushBlock实现源码如下:
private def pushBlock(block: Block) {
listener.onPushBlock(block.id, block.buffer)
logInfo("Pushed block " + block.id)
}当存储到BlockManager中后,会返回一个BlcokStoreResult结果,这就是成功存储到BlockManager的StreamBlcokId。
然后下一步就是将BlcokStoreResult封装成ReceivedBlockInfo,这也就是最新的未处理过的数据,然后通过Akka告诉ReceiverTracker有新的块加入,ReceiverTracker 会调用addBlock方法将ReceivedBlockInfo存储到streamIdToUnallocatedBlockQueues队列中。
ReceiverTracker会将存储的blockId放到对应StreamId的队列中。(HashMap)
private val receiverTrackingInfos = new HashMap[Int, ReceiverTrackingInfo]receiverTrackingInfos.put(streamId, receiverTrackingInfo)ReceiverTracker中addBlock方法源码的实现如下:
private def addBlock(receivedBlockInfo: ReceivedBlockInfo): Boolean = {
receivedBlockTracker.addBlock(receivedBlockInfo)
}ReceivedBlockInfo源码实现如下:
def blockId: StreamBlockId = blockStoreResult.blockId
/** Information about blocks received by the receiver */
private[streaming] case class ReceivedBlockInfo(
streamId: Int,
numRecords: Option[Long],
metadataOption: Option[Any],
blockStoreResult: ReceivedBlockStoreResult
) {
require(numRecords.isEmpty || numRecords.get >= 0, "numRecords must not be negative")
@volatile private var _isBlockIdValid = true
def blockId: StreamBlockId = blockStoreResult.blockId
}最后看看 ReceivedBlockStoreResult 的部分源码:
private[streaming] trait ReceivedBlockStoreResult {
// Any implementation of this trait will store a block id
def blockId: StreamBlockId
// Any implementation of this trait will have to return the number of records
def numRecords: Option[Long]
} Spark Streaming 根据时间段,将数据切分为 RDD,然后触发 RDD 的 Action 提
交 Job, Job 被 提 交 到 Job Manager 中 的 Job Queue 中 由 JobScheduler 调 度, 之 后
Job Scheduler 将 Job 提交到 Spark 的 Job 调度器,然后将 Job 转换为大量的任务分
发给 Spark 集群执行,
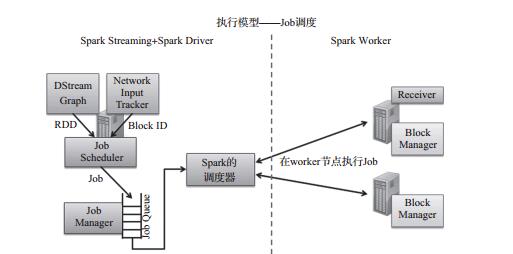
然后接下来了解下JobScheduler的源码:
JobScheduler是整个Spark Streaming调度的核心组件。
部分源码:
def submitJobSet(jobSet: JobSet) {
if (jobSet.jobs.isEmpty) {
logInfo("No jobs added for time " + jobSet.time)
} else {
listenerBus.post(StreamingListenerBatchSubmitted(jobSet.toBatchInfo))
jobSets.put(jobSet.time, jobSet)
jobSet.jobs.foreach(job => jobExecutor.execute(new JobHandler(job)))
logInfo("Added jobs for time " + jobSet.time)
}
}进入Graph生成job的方法,Graph本质是DStreamGraph类生成的对象,部分源码如下:
final private[streaming] class DStreamGraph extends Serializable with Logging {
private val inputStreams = new ArrayBuffer[InputDStream[_]]()
private val outputStreams = new ArrayBuffer[DStream[_]]()
def generateJobs(time: Time): Seq[Job] = {
logDebug("Generating jobs for time " + time)
val jobs = this.synchronized {
outputStreams.flatMap { outputStream =>
val jobOption = outputStream.generateJob(time)
jobOption.foreach(_.setCallSite(outputStream.creationSite))
jobOption
}
}
logDebug("Generated " + jobs.length + " jobs for time " + time)
jobs
}
}outputStreaming中的对象是DStream,看下DStream的generateJob:
此处相当于针对每个时间段生成一个RDD,会调用SparkContext的方法runJob提交Spark的一个Job。
private[streaming] def generateJob(time: Time): Option[Job] = {
getOrCompute(time) match {
case Some(rdd) => {
val jobFunc = () => {
val emptyFunc = { (iterator: Iterator[T]) => {} }
context.sparkContext.runJob(rdd, emptyFunc)
}
Some(new Job(time, jobFunc))
}
case None => None
}
}以上就是怎么进行Spark Streaming 原理剖析,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务


