这篇文章主要介绍了Hadoop中MapReduce的示例分析,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
MapReduce设计理念
移动计算,而不是移动数据。
MapReduce之Helloworld(Word Count)处理过程

MapReduce的Split大小 - max.split(200M) - min.split(50M) - block(128M) - max(min.split,min(max.split,block))=128M
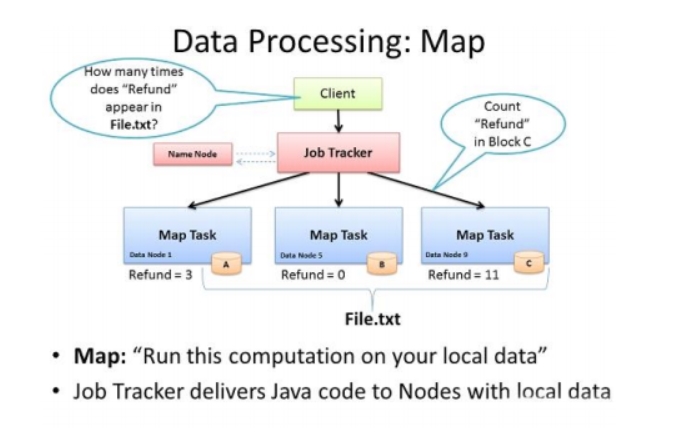
Mapper
Map-reducede 的 思想就是“分而治之”
Mapper负责“分”,即把发杂的任务分解为若干个“简单的任务”执行
“简单的任务”有几个含义:
数据或计算规模相对于原任务要大大缩小;
就近计算,即会被分配到存放了所需数据的节点进行计算;
这些小任务可以并行计算,彼此间几乎没有依赖关系。
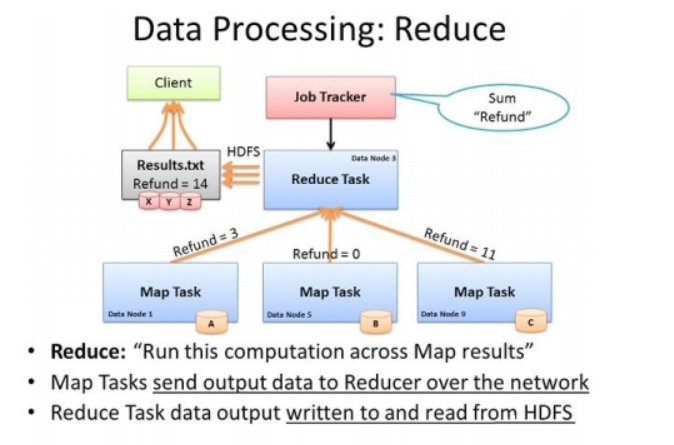
Reduce
对map阶段的结果进行汇总;
reducer的数目由mapred-site.xml配置文件里的项目mapred.reduce.tasks决定。缺省值为1,用户可以覆盖(一般在程序中调整,不修改xml默认值)
shuffler(最为复杂的一个环节)
参考:MapReduce:详解Shuffle过程
在mapper和reduce中间的一个步骤
可以把mapper的输出按照某种key值重新切分和组合成N份,把key值符合某种范围的组输送到特定的reduce那里去处理
可以简化reduce过程

附:Helloworld之WordCount
//WCJob.java
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.StringUtils;
/**
* MapReduce_Helloworld程序
*
* WCJob
* @since V1.0.0
* Created by SET on 2016-09-11 11:35:15
* @see
*/
public class WCJob {
public static void main(String[] args) throws Exception {
Configuration config = new Configuration();
config.set("fs.defaultFS", "hdfs://master:8020");
config.set("yarn-resourcemanager.hostname", "slave2");
FileSystem fs = FileSystem.newInstance(config);
Job job = new Job(config);
job.setJobName("word count");
job.setJarByClass(WCJob.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
job.setCombinerClass(WCReducer.class);
FileInputFormat.addInputPath(job, new Path("/user/wc/wc"));
Path outputpath = new Path("/user/wc/output");
if(fs.exists(outputpath)) {
fs.delete(outputpath, true);
}
FileOutputFormat.setOutputPath(job, outputpath);
boolean flag = job.waitForCompletion(true);
if(flag) {
System.out.println("Job success@!");
}
}
private static class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
/**
* 格式:hadoop hello world
* map 拿到每一行数据 切分
*/
String[] strs = StringUtils.split(value.toString(), ' ');
for(String word : strs) {
context.write(new Text(word), new IntWritable(1));
}
}
}
private static class WCReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable intWritable : values) {
sum += intWritable.get();
}
context.write(new Text(key), new IntWritable(sum));
}
}
}感谢你能够认真阅读完这篇文章,希望小编分享的“Hadoop中MapReduce的示例分析”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/rosetta/blog/745298



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



