еҰӮдҪ•иҝӣиЎҢspark2.0.1е®үиЈ…йғЁзҪІеҸҠдҪҝз”ЁjdbcиҝһжҺҘеҹәдәҺhiveзҡ„sparksql
еҰӮдҪ•иҝӣиЎҢspark2.0.1е®үиЈ…йғЁзҪІеҸҠдҪҝз”ЁjdbcиҝһжҺҘеҹәдәҺhiveзҡ„sparksqlпјҢзӣёдҝЎеҫҲеӨҡжІЎжңүз»ҸйӘҢзҡ„дәәеҜ№жӯӨжқҹжүӢж— зӯ–пјҢдёәжӯӨжң¬ж–ҮжҖ»з»“дәҶй—®йўҳеҮәзҺ°зҡ„еҺҹеӣ е’Ңи§ЈеҶіж–№жі•пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« еёҢжңӣдҪ иғҪи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
1гҖҒе®үиЈ…
еҰӮдёӢй…ҚзҪ®пјҢйҷӨдәҶй…ҚзҪ®sparkиҝҳй…ҚзҪ®дәҶspark historyжңҚеҠЎ
#е…ҲеҲ°http://spark.apache.org/ж №жҚ®иҮӘе·ұзҡ„зҺҜеўғйҖүжӢ©зј–иҜ‘еҘҪзҡ„еҢ…пјҢ然еҗҺиҺ·еҸ–дёӢиҪҪиҝһжҺҘ
cd /opt
mkdir spark
wget http://d3kbcqa49mib13.cloudfront.net/spark-2.0.1-bin-hadoop2.6.tgz
tar -xvzf spark-2.0.1-bin-hadoop2.6.tgz
cd spark-2.0.1-bin-hadoop2.6/conf
еӨҚеҲ¶дёҖд»Ҫspark-env.sh.templateпјҢж”№еҗҚдёәspark-env.shгҖӮ然еҗҺзј–иҫ‘spark-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_111
export SPARK_MASTER_HOST=hadoop-n
еӨҚеҲ¶дёҖд»Ҫspark-defaults.conf.templateпјҢж”№жҲҗдёәspark-defaults.confпјҢ然еҗҺзј–иҫ‘spark-defaults.conf
#жҢҮе®ҡmasterең°еқҖпјҢд»ҘдҫҝеңЁеҗҜеҠЁзҡ„ж—¶еҖҷдёҚз”ЁеҶҚж·»еҠ --masterеҸӮж•°жқҘеҗҜеҠЁйӣҶзҫӨ
spark.master spark://hadoop-n:7077
#еҜ№sqlжҹҘиҜўиҝӣиЎҢеӯ—иҠӮз Ғзј–иҜ‘пјҢе°Ҹж•°жҚ®йҮҸжҹҘиҜўе»әи®®е…ій—ӯ
spark.sql.codegen true
#ејҖеҗҜд»»еҠЎйў„жөӢжү§иЎҢжңәеҲ¶пјҢеҪ“еҮәзҺ°жҜ”иҫғж…ўзҡ„д»»еҠЎж—¶пјҢе°қиҜ•еңЁе…¶д»–иҠӮзӮ№жү§иЎҢиҜҘд»»еҠЎзҡ„дёҖдёӘеүҜжң¬пјҢеё®еҠ©еҮҸе°‘еӨ§и§„жЁЎйӣҶзҫӨдёӯдёӘеҲ«ж…ўд»»еҠЎзҡ„еҪұе“Қ
spark.speculation true
#й»ҳи®ӨеәҸеҲ—еҢ–жҜ”иҫғж…ўпјҢиҝҷдёӘжҳҜе®ҳж–№жҺЁиҚҗзҡ„
spark.serializer org.apache.spark.serializer.KryoSerializer
#иҮӘеҠЁеҜ№еҶ…еӯҳдёӯзҡ„еҲ—ејҸеӯҳеӮЁиҝӣиЎҢеҺӢзј©
spark.sql.inMemoryColumnarStorage.compressed true
#жҳҜеҗҰејҖеҗҜeventж—Ҙеҝ—
spark.eventLog.enabled true
#eventж—Ҙеҝ—и®°еҪ•зӣ®еҪ•пјҢеҝ…йЎ»жҳҜе…ЁеұҖеҸҜи§Ғзҡ„зӣ®еҪ•пјҢеҰӮжһңеңЁhdfsйңҖиҰҒе…Ҳе»әз«Ӣж–Ү件еӨ№
spark.eventLog.dir hdfs://hadoop-n:9000/spark_history_log/spark-events
#жҳҜеҗҰеҗҜеҠЁеҺӢзј©
spark.eventLog.compress true
еӨҚеҲ¶дёҖд»Ҫslaves.templateпјҢж”№жҲҗдёәslavesпјҢ然еҗҺзј–иҫ‘slaves
hadoop-d1
hadoop-d2
д»Һ$HIVE_HOME/confдёӢжӢ·иҙқдёҖд»Ҫhive-site.xmlеҲ°еҪ“еүҚзӣ®еҪ•дёӢгҖӮ
зј–иҫ‘/etc/дёӢзҡ„profileпјҢеңЁжң«е°ҫеӨ„ж·»еҠ
export SPARK_HOME=/opt/spark/spark-2.0.1-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://hadoop-n:9000/spark_history_log/spark-events"
дёәдәҶдҝқиҜҒз»қеҜ№з”ҹж•ҲпјҢ/etc/bashrcд№ҹеҒҡеҗҢж ·и®ҫзҪ®пјҢ然еҗҺеҲ·ж–°и®ҫзҪ®
source /etc/profile
source /etc/bashrc
2гҖҒеҗҜеҠЁ
aпјүйҰ–е…ҲеҗҜеҠЁhadoopпјӣ
cd $HADOOP_HOME/sbin
./start-dfs.sh
и®ҝй—®http://ip:portпјҡ50070жҹҘзңӢжҳҜеҗҰеҗҜеҠЁжҲҗеҠҹ
bпјү然еҗҺеҗҜеҠЁhive
cd $HIVE_HOME/bin
./hive --service metastore
жү§иЎҢbeelineжҲ–иҖ…hiveе‘Ҫд»ӨжҹҘзңӢжҳҜеҗҰеҗҜеҠЁжҲҗеҠҹпјҢй»ҳи®Өhiveж—Ҙеҝ—еңЁ/tmp/${username}/hive.log
cпјүжңҖеҗҺеҗҜеҠЁspark
cd $SPARK_HOME/sbin
./start-all.sh
sprark ui пјҡhttp://hadoop-n:8080
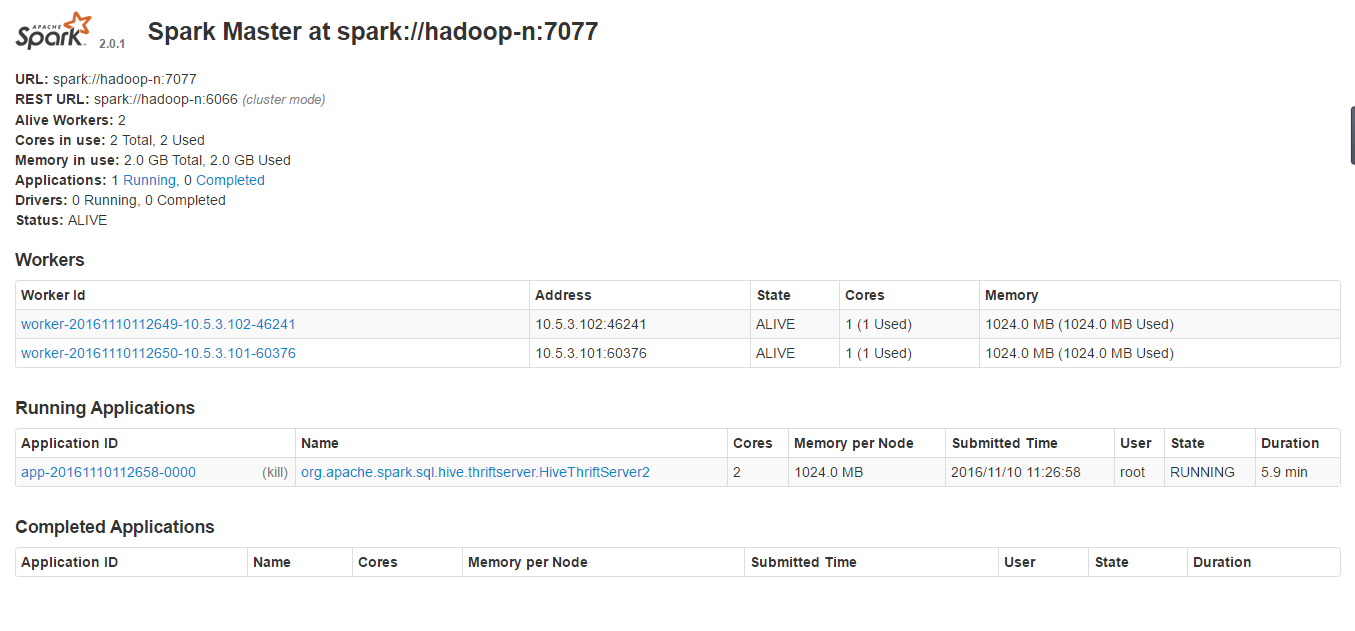
sparkе®ўжҲ·з«Ҝ
cd $SPARK_HOME/bin
./spark-shell
sparksqlе®ўжҲ·з«Ҝ
cd $SPARK_HOME/bin
./spark-sql
жіЁж„Ҹжү§иЎҢе‘Ҫд»ӨеҗҺжҸҗзӨәзҡ„webuiзҡ„з«ҜеҸЈеҸ·пјҢйҖҡиҝҮwebuiеҸҜд»ҘжҹҘиҜўеҜ№еә”зӣ‘жҺ§дҝЎжҒҜгҖӮ
еҗҜеҠЁthriftserver
cd $SPARK_HOME/sbin
./start-thriftserver.sh
spark thriftserver uiпјҡhttp://hadoop-n:4040
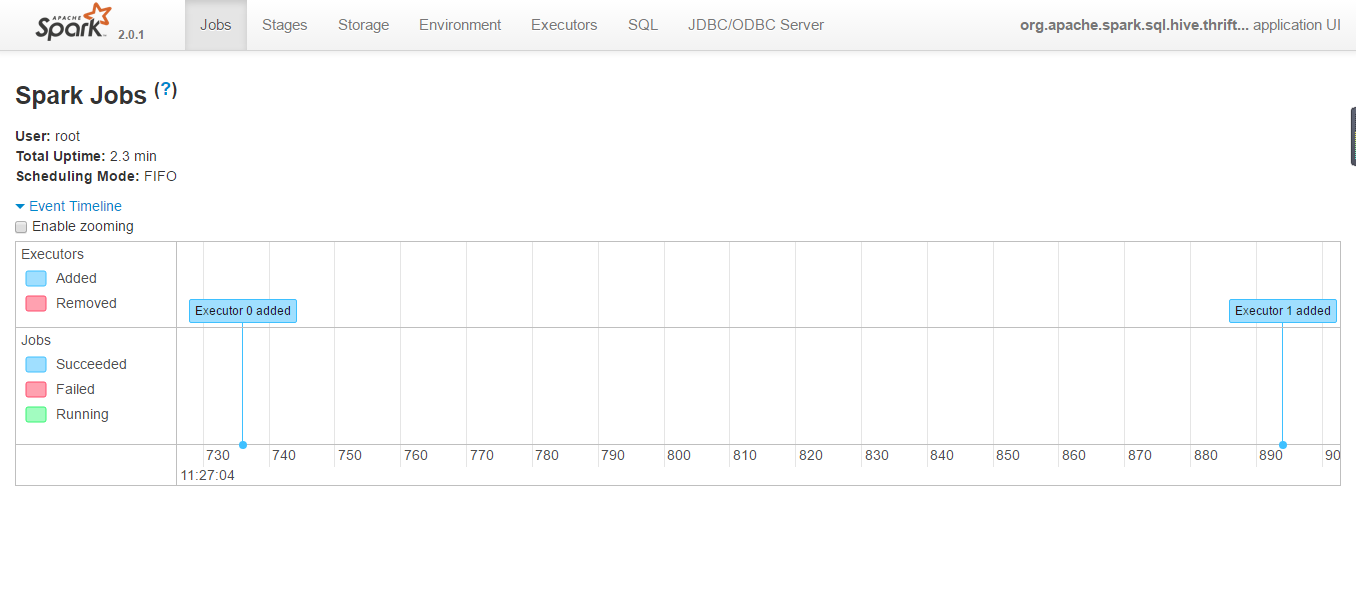
еҗҜеҠЁhistoryserver
cd $SPARK_HOME/sbin
./start-history-server.sh
spark histroy uiпјҡhttp://hadoop-n:18080
3гҖҒдҪҝз”ЁjdbcиҝһжҺҘеҹәдәҺhiveзҡ„sparksql
aпјүеҰӮжһңhiveеҗҜеҠЁдәҶhiveserver2пјҢе…ій—ӯ
bпјүжү§иЎҢеҰӮдёӢе‘Ҫд»ӨеҗҜеҠЁжңҚеҠЎ
cd $SPARK_HOME/sbin
./start-thriftserver.sh
жү§иЎҢеҰӮдёӢе‘Ҫд»ӨжөӢиҜ•жҳҜеҗҰеҗҜеҠЁжҲҗеҠҹ
cd $SPARK_HOME/bin
./beeline -u jdbc:hive2://ip:10000
#еҰӮдёӢжҳҜе®һйҷ…иҫ“еҮә
[root@hadoop-n bin]# ./beeline -u jdbc:hive2://hadoop-n:10000
Connecting to jdbc:hive2://hadoop-n:10000
16/11/08 21:03:05 INFO jdbc.Utils: Supplied authorities: hadoop-n:10000
16/11/08 21:03:05 INFO jdbc.Utils: Resolved authority: hadoop-n:10000
16/11/08 21:03:05 INFO jdbc.HiveConnection: Will try to open client transport with JDBC Uri: jdbc:hive2://hadoop-n:10000
Connected to: Spark SQL (version 2.0.1)
Driver: Hive JDBC (version 1.2.1.spark2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 1.2.1.spark2 by Apache Hive
0: jdbc:hive2://hadoop-n:10000> show databases;
+---------------+--+
| databaseName |
+---------------+--+
| default |
| test |
+---------------+--+
2 rows selected (0.829 seconds)
0: jdbc:hive2://hadoop-n:10000>
зј–еҶҷд»Јз ҒиҝһжҺҘsparksql
жҢүз…§иҮӘе·ұзҡ„зҺҜеўғж·»еҠ дҫқиө–
<dependencies>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.6</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
</dependencies>然еҗҺзј–еҶҷзұ»
/**
*
* @Title: HiveJdbcTest.java
* @Package com.scc.hive
* @Description: TODO(з”ЁдёҖеҸҘиҜқжҸҸиҝ°иҜҘж–Ү件еҒҡд»Җд№Ҳ)
* @author scc
* @date 2016е№ҙ11жңҲ9ж—Ҙ дёҠеҚҲ10:16:32
*/
package com.scc.hive;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
/**
*
* @ClassName: HiveJdbcTest
* @Description: TODO(иҝҷйҮҢз”ЁдёҖеҸҘиҜқжҸҸиҝ°иҝҷдёӘзұ»зҡ„дҪңз”Ё)
* @author scc
* @date 2016е№ҙ11жңҲ9ж—Ҙ дёҠеҚҲ10:16:32
*
*/
public class HiveJdbcTest {
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
try {
Class.forName(driverName);
} catch (ClassNotFoundException e) {
e.printStackTrace();
System.exit(1);
}
Connection con = DriverManager.getConnection("jdbc:hive2://10.5.3.100:10000", "", "");
Statement stmt = con.createStatement();
String tableName = "l_access";
String sql = "";
ResultSet res = null;
sql = "describe " + tableName;
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + "\t" + res.getString(2));
}
sql = "select * from " + tableName + " limit 10;";
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getObject("id"));
}
sql = "select count(1) from " + tableName;
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println("count:" + res.getString(1));
}
}
}дёӢйқўжҳҜжҺ§еҲ¶еҸ°иҫ“еҮә
log4j:WARN No appenders could be found for logger (org.apache.hive.jdbc.Utils).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
id int
req_name string
req_version string
req_param string
req_no string
req_status string
req_desc string
ret string
excute_time int
req_time date
create_time date
212
213
214
215
216
217
218
219
220
221
count:932
4гҖҒжіЁж„ҸдәӢйЎ№
йӣҶзҫӨиҰҒй…ҚзҪ®sshе…ҚеҜҶз Ғзҷ»еҪ•
дёҚиҰҒеҝҳи®°жӢ·иҙқhiveзҡ„й…ҚзҪ®ж–Ү件пјҢдёҚ然sparkдјҡеңЁжң¬ең°еҲӣе»әзү©зҗҶж•°жҚ®еә“ж–Ү件
hiveеҗҜеҠЁж—¶жҸҗзӨәls: cannot access /opt/spark/spark-2.0.1-bin-hadoop2.6/lib/spark-assembly-*.jar: No such file or directoryпјҢдёҚеҪұе“ҚзЁӢеәҸиҝҗиЎҢгҖӮ
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们жҺҢжҸЎеҰӮдҪ•иҝӣиЎҢspark2.0.1е®үиЈ…йғЁзҪІеҸҠдҪҝз”ЁjdbcиҝһжҺҘеҹәдәҺhiveзҡ„sparksqlзҡ„ж–№жі•дәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–жғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ





