如何理解KEGG Orthology数据库,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
我们经常会使用KEGG数据库来研究基因的功能,而在KEGG 数据库中,直接存储分子功能的就是KEGG Orthology 数据库。
KEGG Orthology 简称KO,该数据库中的每一条记录用K number 唯一标识。基于同源基因具有相似功能的假设,把基因的功能进行了扩充。对于某个物种中功能研究的很清楚的基因,在不同的物种间搜寻该基因的同源基因,将这些同源基因定义为一个orthology, 用该基因的功能作为该orthology 的功能;这样就将对于不同物种基因功能的研究都利用起来,提供了一个全面的研究基因功能的数据库。
pathway,module 等数据库都是建立在KO数据库的基础上的,KO可以说是KEGG中处于核心地位的一个数据库,所以理解KO数据库就特别的重要。
对于一个具体的KO来说,在这个KO下是一系列基因,这些基因可以来源于不同的物种,但是具有相同的功能。以K00161为例,对应的同源基因的列表可以从KEGG的官网查询得到,
打开这个链接 http://www.genome.jp/kegg/ko.html , 在查询的文本框中输入K number, 如下图所示:
点击Orthology table按钮,在跳转的页面可以看到具体的基因列表,如下图所示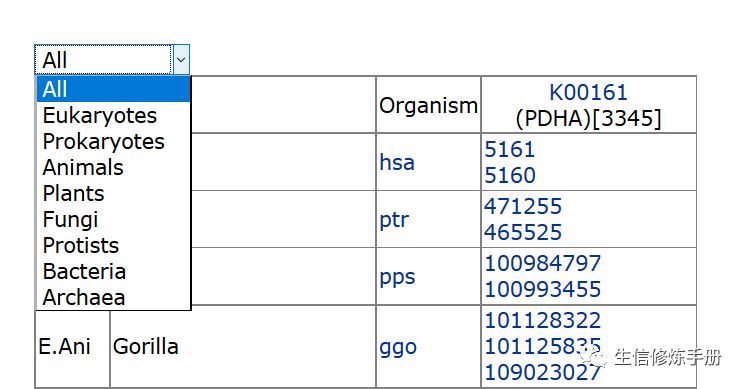
在下拉列表中,还可以对物种进行筛选,比如只显示Animals的基因。
对于已知的基因,可以直接在数据库中检索得到对应的功能,那么对于新发现的基因,如何利用KO数据库来研究其功能呢?
根据同源基因的定义,序列相似度在80%以上的就定义为同源基因。对于功能未知的基因,我们只需要根据序列比对查找对应的功能已知的同源基因就可以了。
KEGG官网提供了一个在线的工具,BlastKOALA。这个工具基于blast 比对,将输入的基因序列和KEGG Gene 数据库中的序列去比对,查找最佳匹配的一个gene, 将该基因对应的K number 赋予查询的基因。
1.首先在文本框中输入带查询的基因的序列

2.设置对应的物种信息,减少查询的物种范围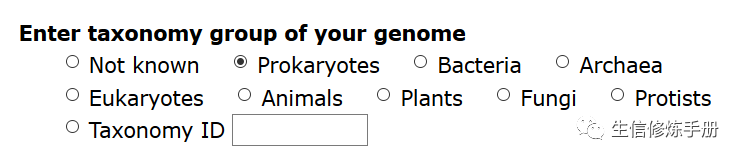
3. 根据实际情况选择用于检索的基因集数据库
4. 最后输入邮箱地址,提交任务就可以了
首先会给你的邮箱发一封邮件,你必须点击这个邮件中的链接才能开始工作,当结束后,会再发一封邮件给你,通过邮件中的链接就可以看到最终的分析结果。
KO 数据库是研究基因功能的基础数据库,每个KO下对应的是一系列具有相同功能的基因,这些基因可以来源于不同的物种。
基于序列比对的原理,我们可以利用KO 数据库来研究新基因的功能。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





