这篇文章将为大家详细讲解有关HDFS如何实现读写,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
一、写操作
前提:File大小为200M,block.size为128M,block分为两块block1和block2(块小于block.size的不会占用一个真个block大小,而是实际的大小)。
写操作的流程图
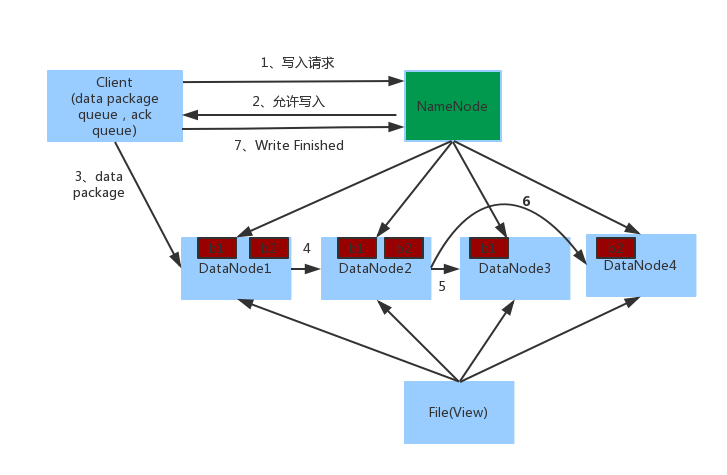
1. Client向NameNode发起写入请求。
2. NameNode返回可用的DataNode列表。
若client为DataNode节点,那存储block时,规则为:副本1,当前client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。
若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。
3. client向DataNode发送block1,数据首先被写入FSDataOutputStream对象内部的Buffer中,然后数据被分割成一个个data package,每个Packet大小为64k字节,每个Packet又由一组chunk和这组chunk对应的checksum数据组成,默认chunk大小为512字节,每个checksum是对512字节数据计算的校验和数据。
当Client写入的字节流数据达到一个Packet的大小,这个Packet会被构建出来,然后会被放到队列dataQueue中,接着DataStreamer线程会不断地从dataQueue队列中取出Packet,发送到复制Pipeline中的第一个DataNode上,并将该Packet从dataQueue队列中移到ackQueue队列中。ResponseProcessor线程接收从Datanode发送过来的ack,如果是一个成功的ack,表示复制Pipeline中的所有Datanode都已经接收到这个Packet,ResponseProcessor线程将packet从队列ackQueue中删除。
在发送过程中,如果发生错误,所有未完成的Packet都会从ackQueue队列中移除掉,然后重新创建一个新的Pipeline,排除掉出错的那些DataNode节点,接着DataStreamer线程继续从dataQueue队列中发送Packet。
我们从下面3个方面来描述内部流程:
创建Packet
Client写数据时,会将字节流数据缓存到内部的缓冲区中,当长度满足一个Chunk大小(512B)时,便会创建一个Packet对象,然后向该Packet对象中写Chunk Checksum校验和数据,以及实际数据块Chunk Data,校验和数据是基于实际数据块计算得到的。每次满足一个Chunk大小时,都会向Packet中写上述数据内容,直到达到一个Packet对象大小(64K),就会将该Packet对象放入到dataQueue队列中,等待DataStreamer线程取出并发送到DataNode节点。
发送Packet
DataStreamer线程从dataQueue队列中取出Packet对象,放到ackQueue队列中,然后向DataNode节点发送这个Packet对象所对应的数据。
接收ack
发送一个Packet数据包以后,会有一个用来接收ack的ResponseProcessor线程,如果收到成功的ack,则表示一个Packet发送成功。如果成功,则ResponseProcessor线程会将ackQueue队列中对应的Packet删除。
4. 当第一个DataNode1接收到data package并写入成功后,会发送到DataNode2,同时接受第二个data package,以此类推。
5. 当block1发送完成以后再发送第二个block,第二个block也发送完成时DataNode向Client发送通知,client会向NameNode发送消息,说我写完了。然后关闭close。
一、读操作
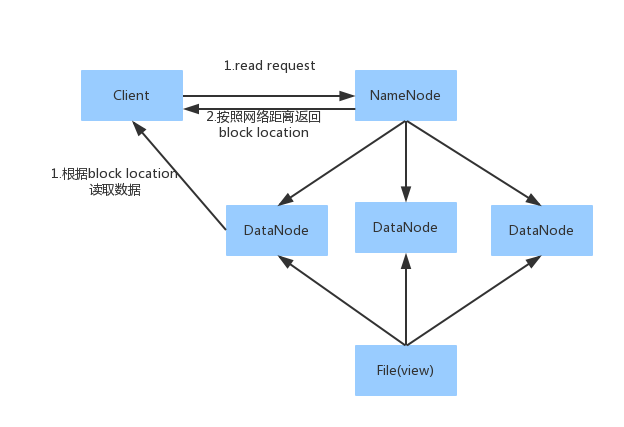
1. Client向NameNode发送读请求。
2.NameNode根据网络距离返回block位置列表(列表是是根据网络距离排好顺序的)。
网络距离:
若client为DataNode节点,那读取block时优先读取当前节点的数据。
若client不为DataNode节点,那读取block时,根据:同一节点上的进程--->同一个机架上的不同节点--->同一个数据中心不同机架上的节点--->不同数据中心的节点。
3. 根据block位置读取数据。
关于“HDFS如何实现读写”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/2500254/blog/809212



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



