本篇文章为大家展示了R语言分类算法中随机森林是什么意思,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
1.原理分析:
随机森林是通过自助法(boot-strap)重采样技术,从原始训练样本集N中有放回地重复随机抽取k个样本生成新的训练集样本集合,然后根据自助样本集生成k个决策树组成的随机森林,新数据的分类结果按照决策树投票多少形成的分数而定.
通俗的理解为由许多棵决策树组成的森林,而每个样本需要经过每棵树进行预测,然后根据所有决策树的预测结果最后来确定整个随机森林的预测结果.随机森林中的每一颗决策树都为二叉树,其生成遵循自顶向下的递归分裂原则,即从根节点开始依次对训练集进行划分.在二叉树中,根节点包含全部训练数据,按照节点不纯度最小原则,分裂为左节点和右节点,他们分别包含训数据的一个子集,按照同样的规则,节点继续分裂,直到满足分支停止规则,停止生长.
1.首先我们用N来表示原始训练集样本的个数,用M来表示变量的数目.
2.其次我们需要确定一个定值m,该值被用来决定当在一个节点上做决定时,会使用到多少个变量.m
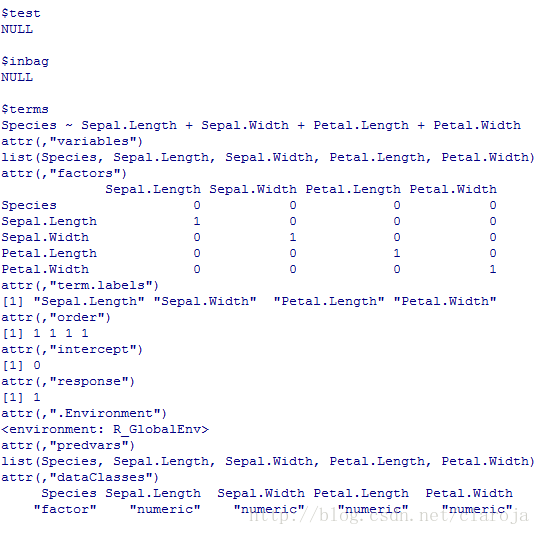
fit_rf=randomForest(Species~.,data=data_train,mtry=4,importance=TRUE,ntree=1000)fit_rf[1:length(fit_rf)]

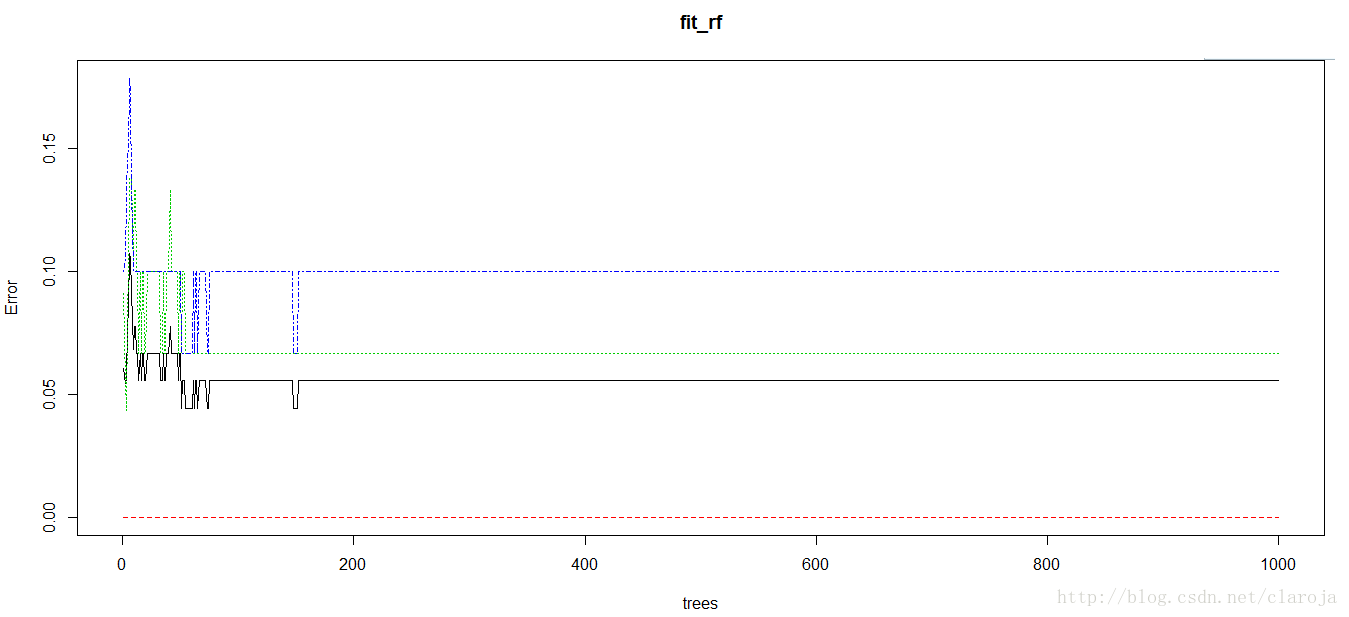
2)作图
上述内容就是R语言分类算法中随机森林是什么意思,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





