今天就跟大家聊聊有关如何理解R语言聚类算法中的密度聚类,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
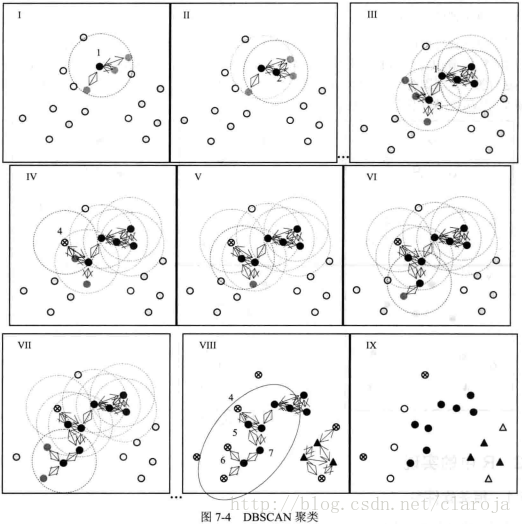
1.原理解析:
1.从数据集中选择一个未处理的样本点
2.以1为圆心,做半径为E的圆,由于圆内圈入点的个数为3,满足密度阈值Minpts,因此称点1为核心对象(黑色实心圆点),且将圈内的4个点形成一个簇,其中点1直接密度可达周围的3个灰色实心原点;
3.重复步骤2若干次,其中点1直接密度可达核心对象3,且点2密度可达点3.
4.当该过程进行到图Ⅳ,4的E邻域内仅有2个点,小雨阈值MinPts,因此点4为边缘点(非核心对象),记为ⓧ,继续考察其他点.
5.当所有对象都被考察,该过程结束,得到图Ⅷ.椭圆形内有若干核心对象和边缘点,这些点都是密度相连的.
6.为个点归类,如图Ⅸ:点集黑圈相互密度可达,属于类别1:点集黑三角相互密度可达,属于新的一类,记为类别2;点集白圈与类别1样本点密度相连,属于类别3;点集白三角与类别2样本点密度相连,属于类别4;点 ⓧ既非核心对象,也不密度相连,为噪声点.
2.在R语言中的应用
密度聚类(Density-based Methods)主要应用到了fpc包中的dbscan函数。
dbscan(data,eps,MinPts=5,scale=FALSE,method=c(“hybird”,”raw”,”dist”),seeds=TRUE,showplot=FALSE,countmode=NULL)
3.以iris数据集为例进行分析
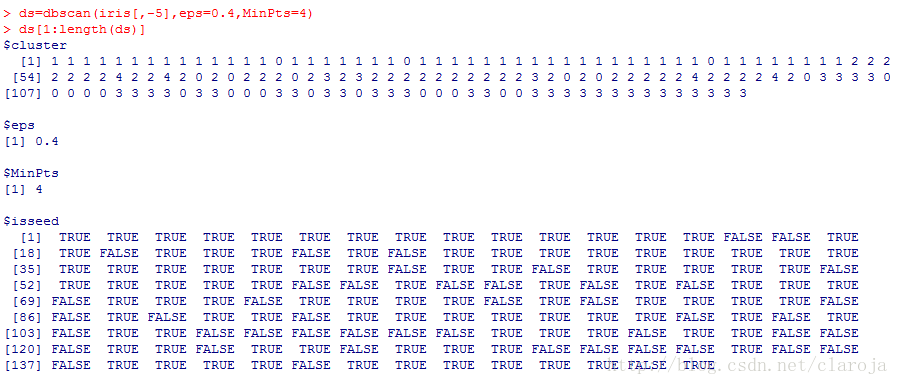
1)应用模型并查看模型的相应参数
ds=dbscan(iris[,-5],eps=0.3,MinPts=4)
ds[1:length(ds)]
看完上述内容,你们对如何理解R语言聚类算法中的密度聚类有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





