жҖҺд№ҲеңЁCDHдёӯеҗҜз”ЁSpark Thrift
иҝҷзҜҮж–Үз« дё»иҰҒдёәеӨ§е®¶еұ•зӨәдәҶвҖңжҖҺд№ҲеңЁCDHдёӯеҗҜз”ЁSpark ThriftвҖқпјҢеҶ…е®№з®ҖиҖҢжҳ“жҮӮпјҢжқЎзҗҶжё…жҷ°пјҢеёҢжңӣиғҪеӨҹеё®еҠ©еӨ§е®¶и§ЈеҶіз–‘жғ‘пјҢдёӢйқўи®©е°Ҹзј–еёҰйўҶеӨ§е®¶дёҖиө·з ”究并еӯҰд№ дёҖдёӢвҖңжҖҺд№ҲеңЁCDHдёӯеҗҜз”ЁSpark ThriftвҖқиҝҷзҜҮж–Үз« еҗ§гҖӮ
2.йғЁзҪІSpark-assembly JarеҢ…
1.дёӢиҪҪspark-1.6.3-bin-hadoop2.6.tgzпјҢдёӢиҪҪең°еқҖеҰӮдёӢпјҡ
https://www.apache.org/dyn/closer.lua/spark/spark-1.6.3/spark-1.6.3-bin-hadoop2.6.tgz
2.е°ҶдёӢиҪҪзҡ„spark-1.6.3-bin-hadoop2.6.tgzдёҠдј иҮійӣҶзҫӨзҡ„д»»ж„ҸиҠӮзӮ№е№¶и§ЈеҺӢпјҢиҝҷйҮҢд»Ҙcdh02иҠӮзӮ№дёәдҫӢ
[root@cdh02 ~]# tar -zxvf spark-1.6.3-bin-hadoop2.6.tgz
3.е°Ҷи§ЈеҺӢеҮәжқҘзҡ„spark-assembly-1.6.3-hadoop2.6.0.jarжӢ·иҙқиҮіCDHзҡ„jarsзӣ®еҪ•
[root@cdh02 spark-1.6.3-bin-hadoop2.6]# scp /root/spark-1.6.3-bin-hadoop2.6/lib/spark-assembly-1.6.3-hadoop2.6.0.jar /opt/cloudera/parcels/CDH/jars/
4.жӣҝжҚўCDHдёӯsparkй»ҳи®Өзҡ„spark-assembly jarеҢ…
[root@cdh02 lib]# cd /opt/cloudera/parcels/CDH/lib/spark/lib
[root@cdh02 lib]# rm -rf spark-assembly-1.6.0-cdh6.13.0-hadoop2.6.0-cdh6.13.0.jar
[root@cdh02 lib]# ln -s ../../../jars/spark-assembly-1.6.3-hadoop2.6.0.jar spark-assembly-1.6.0-cdh6.13.0-hadoop2.6.0-cdh6.13.0.jar
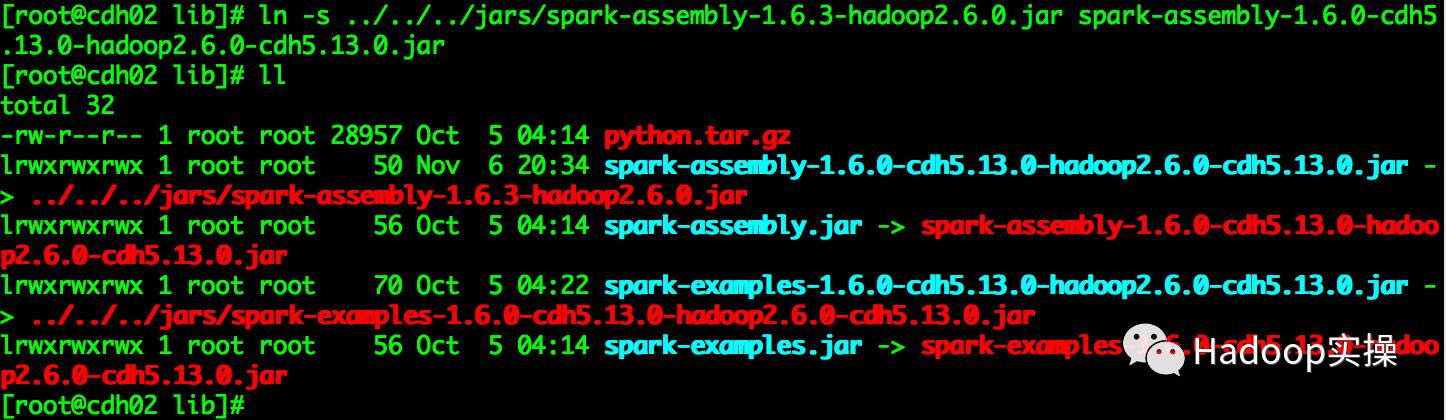
5.е°Ҷspark-assembly-1.6.3-hadoop2.6.0.jarеҢ…дёҠдј иҮіHDFSзӣ®еҪ•
[root@cdh02 lib]# sudo -u spark hadoop fs -mkdir -p /user/spark/share/lib
[root@cdh02 lib]# sudo -u spark hadoop fs -put /opt/cloudera/parcels/CDH/jars/spark-assembly-1.6.3-hadoop2.6.0.jar /user/spark/share/lib
[root@cdh02 lib]# sudo -u spark hadoop fs -chmod 755 /user/spark/share/lib/spark-assembly-1.6.3-hadoop2.6.0.jar
6.еңЁCMдёҠеҜ№SparkиҝӣиЎҢй…ҚзҪ®пјҢй…ҚзҪ®еҰӮдёӢпјҡ
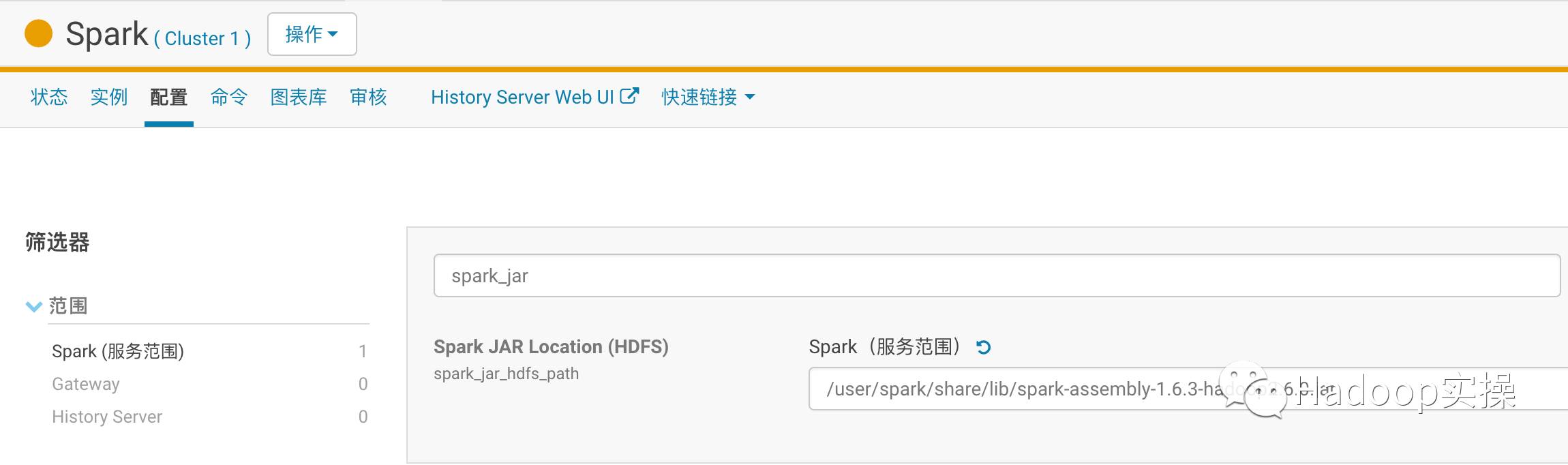
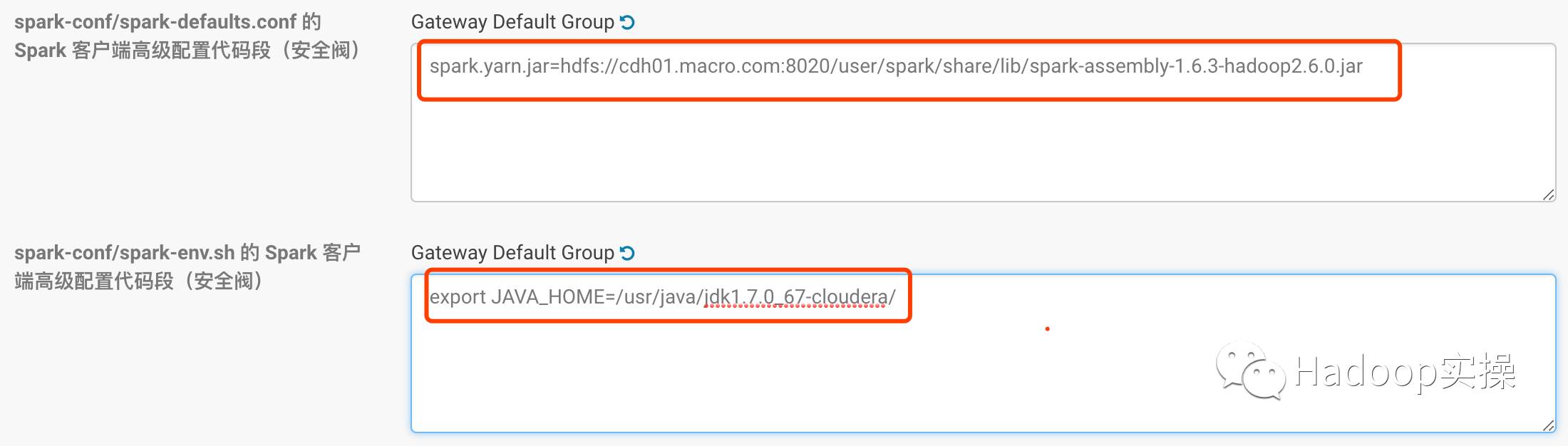
дҝқеӯҳй…ҚзҪ®е№¶йҮҚеҗҜSparkжңҚеҠЎгҖӮ
7.дҝ®ж”№/etc/spark/conf/ classpath.txtж–Ү件еңЁжң«е°ҫеўһеҠ еҰӮдёӢеҶ…е®№
/opt/cloudera/parcels/CDH-5.13.0-1.cdh6.13.0.p0.29/jars/spark-lineage_2.10-1.6.0-cdh6.13.0.jar

з”ұдәҺCDH5.11д»ҘеҗҺзүҲжң¬пјҢNavigator2.10еўһеҠ дәҶSparkзҡ„иЎҖзјҳеҲҶжһҗпјҢжүҖд»ҘиҝҷйҮҢйңҖиҰҒж·»еҠ spark-lineage_2.10-1.6.0-cdh6.13.0.jarеҢ…пјҢеҗҰеҲҷиҝһжҺҘSparkдјҡжҠҘй”ҷжүҫдёҚеҲ°com.cloudera.spark.lineage.ClouderaNavigatorListenerзұ»гҖӮ
3.йғЁзҪІSpark ThriftServerеҗҜеҠЁе’ҢеҒңжӯўи„ҡжң¬
1.жӢ·иҙқSpark ThriftServerеҗҜеҠЁе’ҢеҒңжӯўи„ҡжң¬
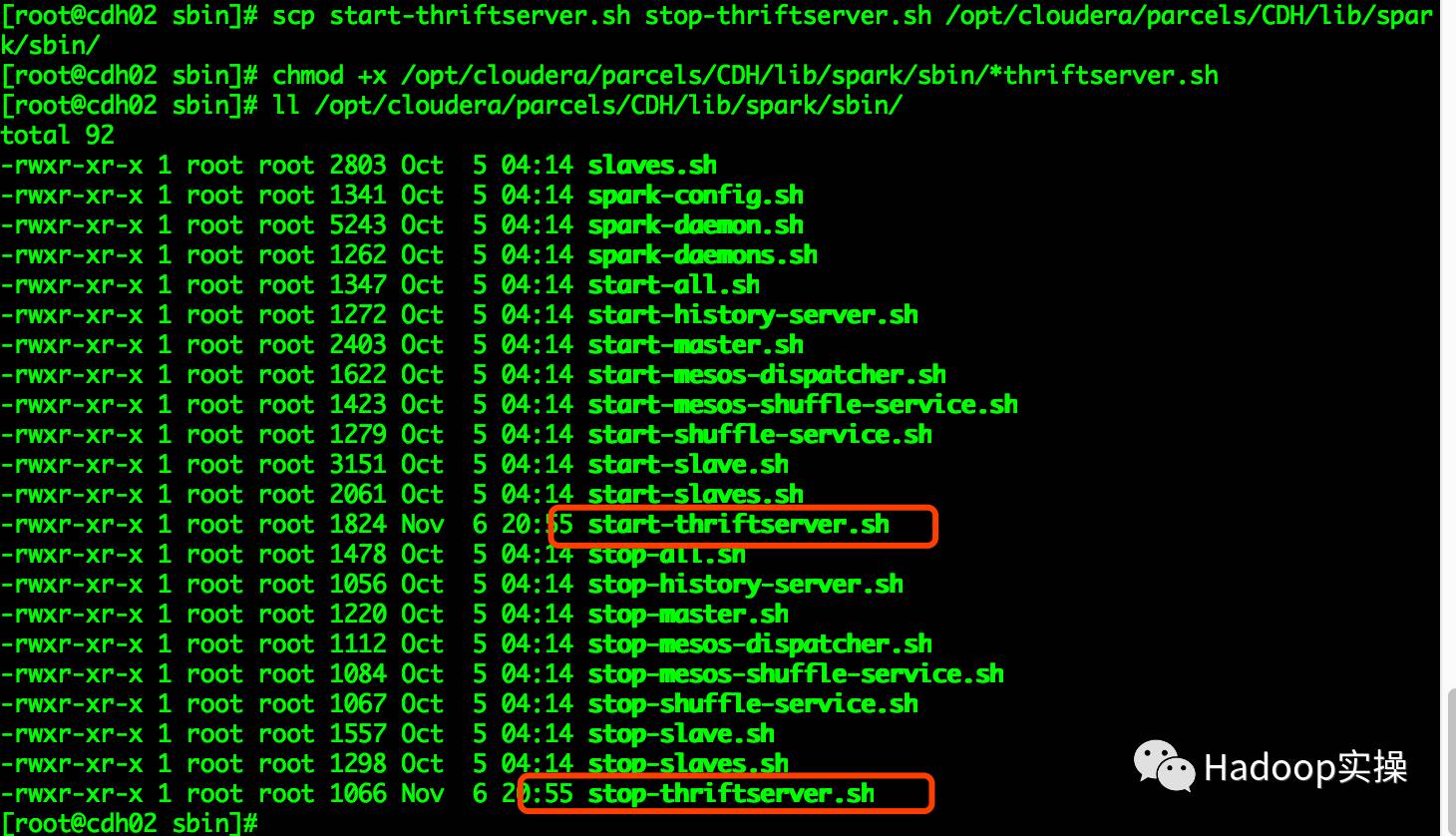
е°Ҷ spark-1.6.3-bin-hadoop2.6/sbin/зӣ®еҪ•дёӢзҡ„ start-thriftserver.sh е’Ң stop-thriftserver.sh и„ҡжң¬жӢ·иҙқеҲ°/opt/cloudera/parcels/CDH/lib/spark/sbinзӣ®еҪ•дёӢпјҢ并и®ҫзҪ®жү§иЎҢжқғйҷҗгҖӮ
[root@cdh02 sbin]# scp start-thriftserver.sh stop-thriftserver.sh /opt/cloudera/parcels/CDH/lib/spark/sbin/
[root@cdh02 sbin]# chmod +x /opt/cloudera/parcels/CDH/lib/spark/sbin/*thriftserver.sh
[root@cdh02 sbin]# ll /opt/cloudera/parcels/CDH/lib/spark/sbin/
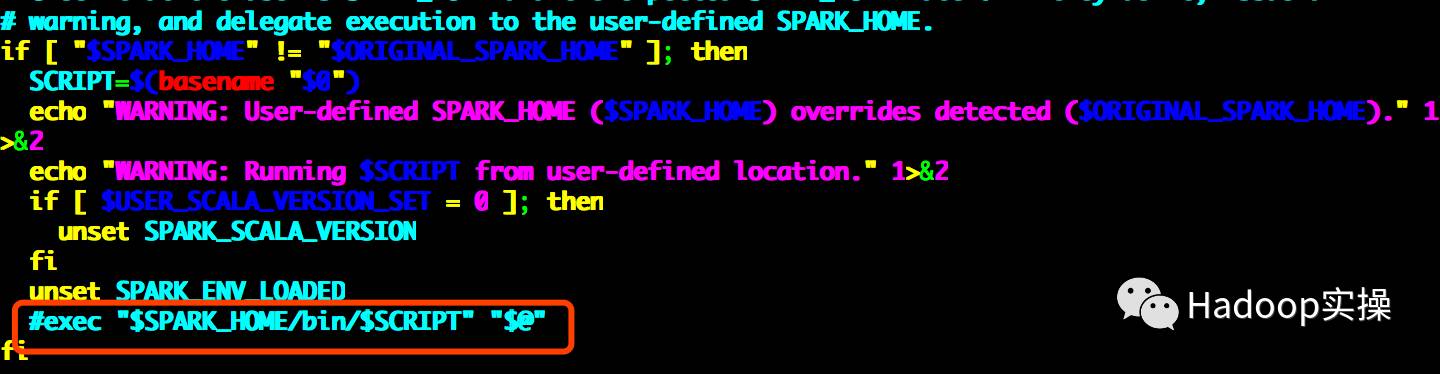
2.дҝ®ж”№ load-spark-env.sh и„ҡжң¬пјҢиҝҷдёӘи„ҡжң¬жҳҜеҗҜеҠЁ spark зӣёе…іжңҚеҠЎж—¶еҠ иҪҪзҺҜеўғеҸҳйҮҸдҝЎжҒҜзҡ„
[root@ip-172-31-5-190 sbin]# cd /opt/cloudera/parcels/CDH/lib/spark/bin
[root@ip-172-31-5-190 bin]# pwd
/opt/cloudera/parcels/CDH/lib/spark/bin
[root@ip-172-31-5-190 bin]#
е°ҶжіЁйҮҠжҺүexec "$SPARK_HOME/bin/$SCRIPT""$@"пјҢеӣ дёәеңЁstart-thriftserver.shи„ҡжң¬дёӯдјҡжү§иЎҢиҝҷдёӘе‘Ҫд»Ө
4.еҗҜеҠЁдёҺеҒңжӯўSpark ThriftServer
1.еҗҜеҠЁSpark ThriftServerжңҚеҠЎ
[root@ip-172-31-5-190 sbin]# ./start-thriftserver.sh

жЈҖжҹҘз«ҜеҸЈжҳҜеҗҰзӣ‘еҗ¬
[root@ip-172-31-5-190 sbin]# netstat -an |grep 10000

жіЁж„ҸпјҡдёәдәҶйҳІжӯўи·ҹHiveServer2зҡ„10000з«ҜеҸЈеҶІзӘҒпјҢеҸҜд»ҘиҮӘе·ұдҝ®ж”№Spark ThriftServerзҡ„еҗҜеҠЁз«ҜеҸЈгҖӮ
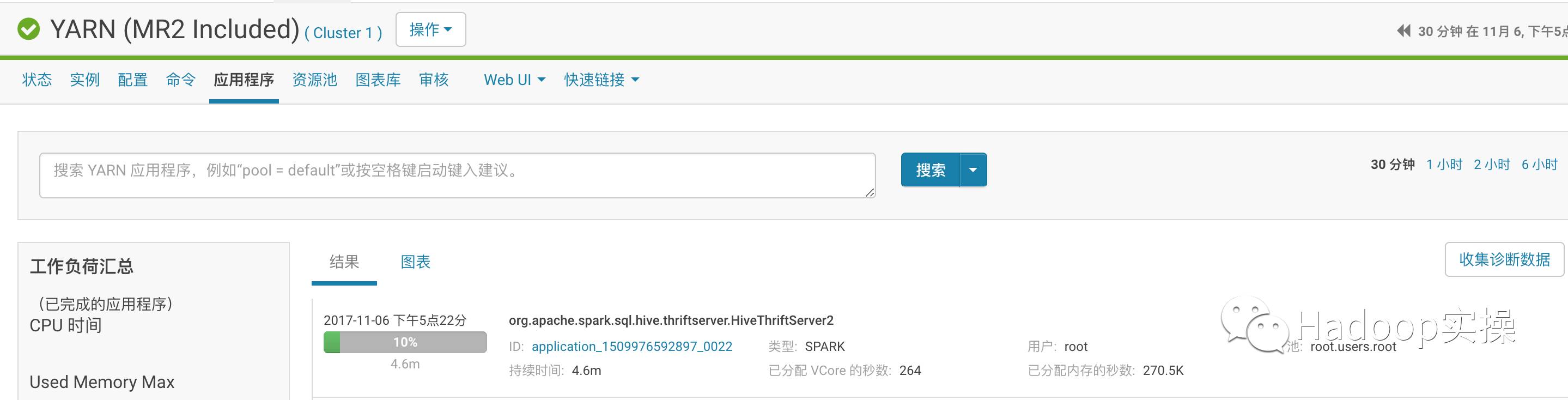
йҖҡиҝҮYarnжҹҘзңӢ
2.еҒңжӯўжңҚеҠЎ
[root@ip-172-31-5-190 sbin]# ./stop-thriftserver.sh

жЈҖжҹҘз«ҜеҸЈжҳҜеҗҰе·ІеҒңжӯў

5.жөӢиҜ•Spark Thrift
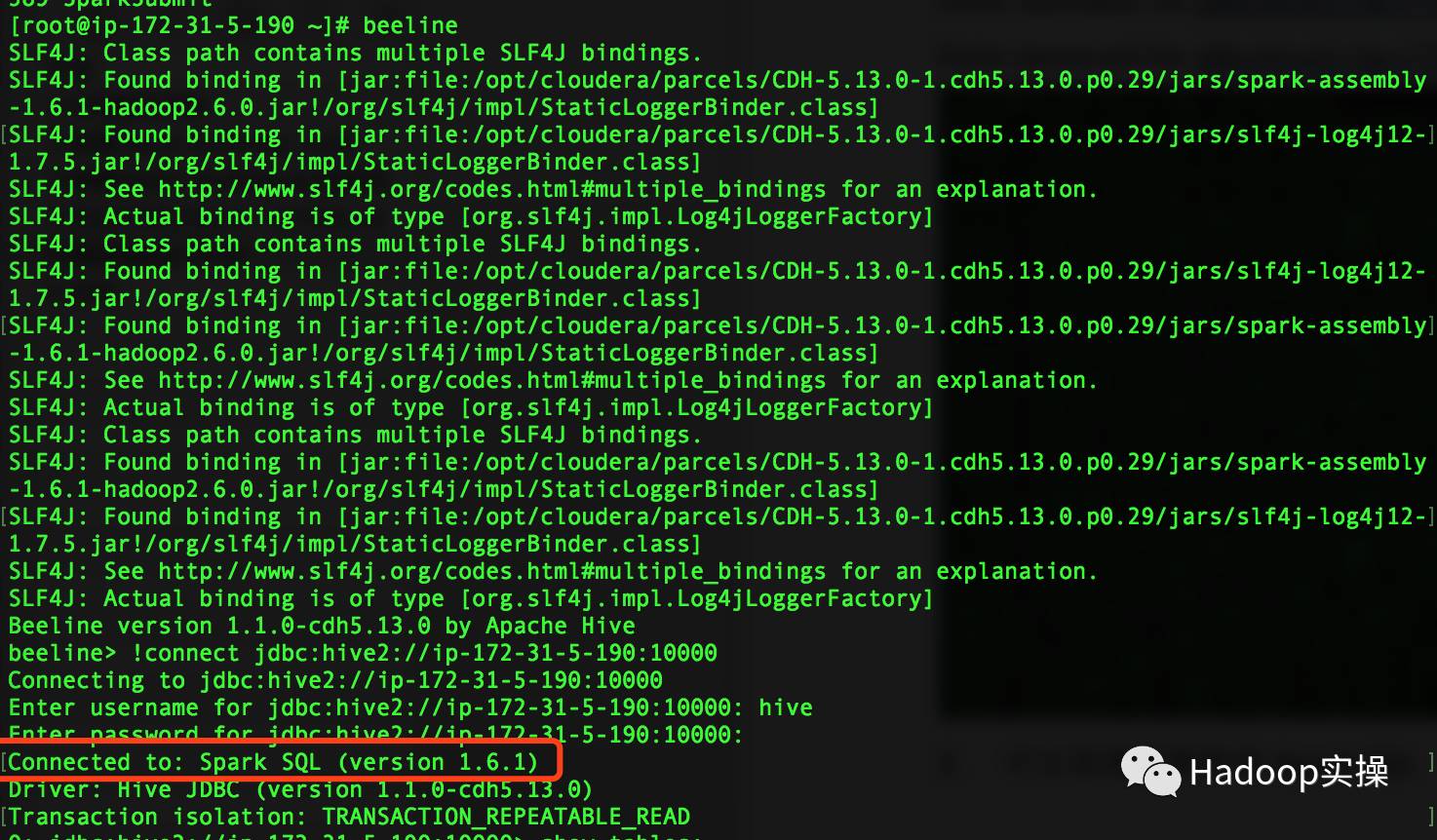
1.дҪҝз”ЁbeelineйҖҡиҝҮJDBCиҝһжҺҘSparkпјҢеҸҜд»ҘеҸ‘зҺ°иҝһжҺҘзҡ„жҳҜSpark SQL
[root@ip-172-31-5-190 ~]# beeline
beeline> !connect jdbc:hive2://ip-172-31-5-190:10000
Enter username for jdbc:hive2://ip-172-31-5-190:10000: hive
Enter password for jdbc:hive2://ip-172-31-5-190:10000:
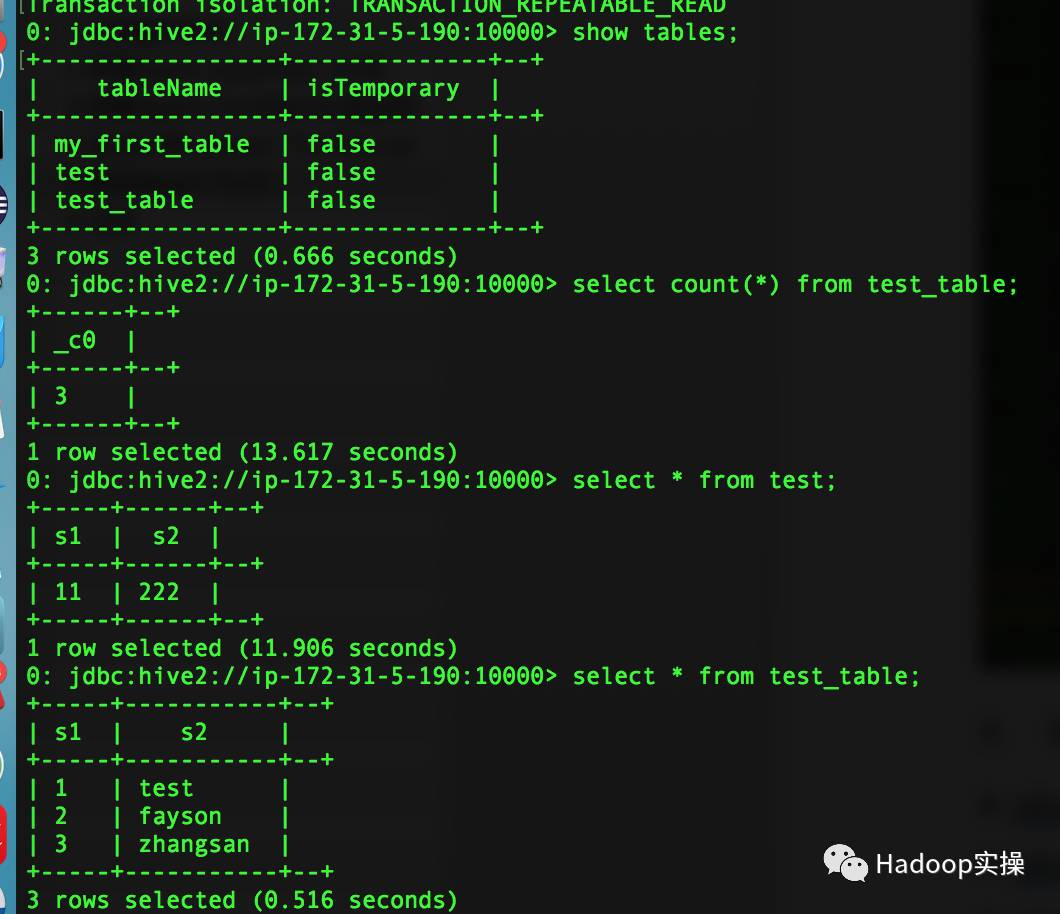
2.иҝҗиЎҢSQLжөӢиҜ•
0: jdbc:hive2://ip-172-31-5-190:10000> show tables;
0: jdbc:hive2://ip-172-31-5-190:10000> select count(*) from test_table;
0: jdbc:hive2://ip-172-31-5-190:10000> select * from test;
0: jdbc:hive2://ip-172-31-5-190:10000> select * from test_table;
0: jdbc:hive2://ip-172-31-5-190:10000> select count(test_table.s2) from test_table join test on test_table.s1=test.s1;

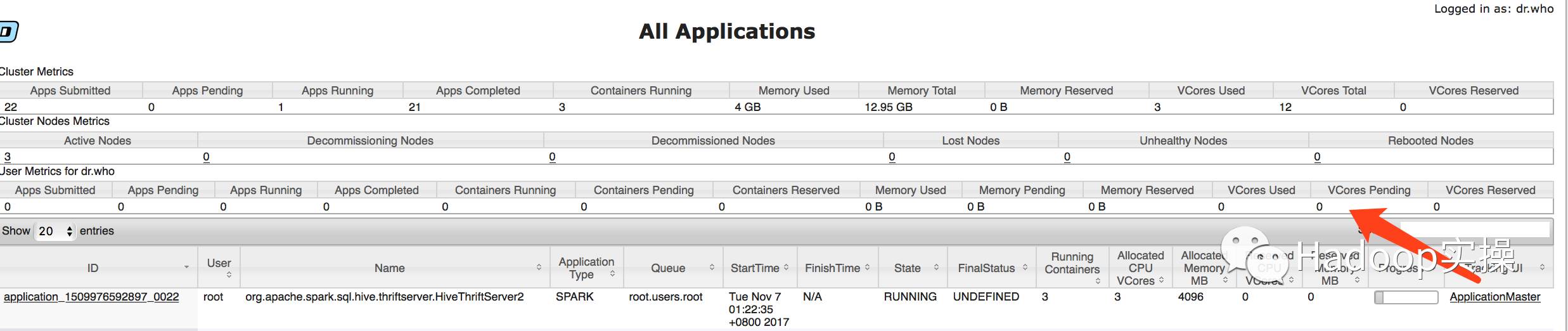
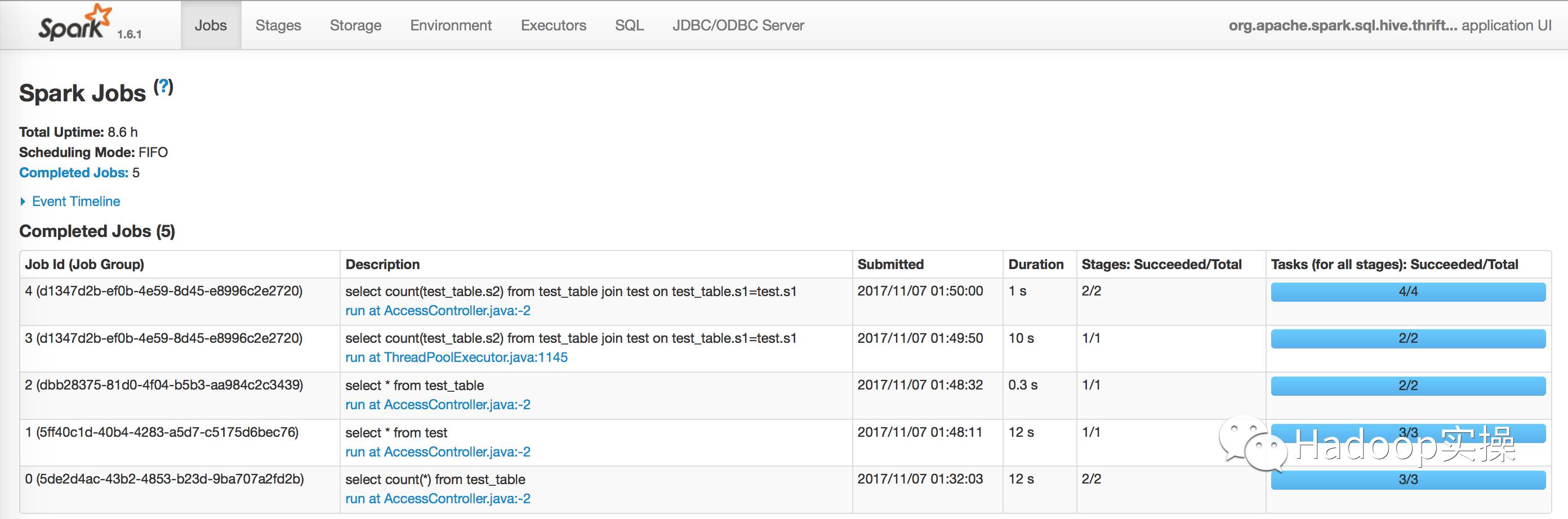
3.еңЁYarnзҡ„8088дёӯжҹҘзңӢSparkд»»еҠЎпјҢеҸҜд»ҘеҸ‘зҺ°йғҪжҳҜйҖҡиҝҮSparkжү§иЎҢзҡ„гҖӮ
д»ҘдёҠжҳҜвҖңжҖҺд№ҲеңЁCDHдёӯеҗҜз”ЁSpark ThriftвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ





