MaxComputeдёӯodpscmdеҰӮдҪ•дҪҝз”Ё
иҝҷжңҹеҶ…е®№еҪ“дёӯе°Ҹзј–е°Ҷдјҡз»ҷеӨ§е®¶еёҰжқҘжңүе…іMaxComputeдёӯodpscmdеҰӮдҪ•дҪҝз”ЁпјҢж–Үз« еҶ…е®№дё°еҜҢдё”д»Ҙдё“дёҡзҡ„и§’еәҰдёәеӨ§е®¶еҲҶжһҗе’ҢеҸҷиҝ°пјҢйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еёҢжңӣеӨ§е®¶еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
дёҖгҖҒе‘Ҫд»ӨиЎҢе·Ҙе…·odpscmdеңЁMaxComputeз”ҹжҖҒдёӯзҡ„е®ҡдҪҚ
odpscmdе…¶е®һе°ұжҳҜMaxComputeзҡ„е‘Ҫд»ӨиЎҢе·Ҙе…·зҡ„еҗҚз§°пјҢе…¶еңЁж•ҙдёӘMaxComputeдёӯзҡ„дҪҚзҪ®жҳҜдҪҚдәҺжңҖдёҠз«Ҝзҡ„гҖӮеҰӮдёӢеӣҫжүҖзӨәпјҢж•ҙдёӘMaxComputeз”ҹжҖҒиҮӘдёӢиҖҢдёҠжҳҜж”Ҝж’‘зҡ„е…ізі»пјҢиҖҢзңҹжӯЈжҡҙйңІз»ҷз”ЁжҲ·зҡ„жҳҜдёҖеҘ—Rest APIпјҢиҝҷеҘ—APIд№ҹжҳҜжңҖж ёеҝғзҡ„жҺҘеҸЈпјҢж— и®әжҳҜJavaиҝҳжҳҜPythonзҡ„SDKйғҪйңҖиҰҒи°ғз”Ёиҝҷдәӣж ёеҝғAPIгҖӮиҖҢе‘Ҫд»ӨиЎҢе·Ҙе…·е°ұжҳҜеҜ№дәҺMaxComputeејҖж”ҫзҡ„Rest APIеҒҡдәҶж·ұеәҰзҡ„еҢ…иЈ…пјҢеңЁе®ўжҲ·з«ҜдҪҝеҫ—з”ЁжҲ·еҸҜд»ҘдҪҝз”Ёе‘Ҫд»Өзҡ„ж–№ејҸжқҘжҸҗдәӨдҪңдёҡпјҢиҝҷдәӣдҪңдёҡеҸҲе°ҶдјҡйҖҡиҝҮжҺҘеҸЈжҸҗдәӨз»ҷMaxComputeйӣҶзҫӨиҝӣиЎҢзӣёе…ізҡ„з®ЎзҗҶе’ҢејҖеҸ‘гҖӮеҸҜиғҪеӨ§е®¶еҜ№дәҺMaxComputeд»ҘеҸҠDataWorksиҝҷдёӘз»„еҗҲжҜ”иҫғзҶҹжӮүпјҢиҝҷжҳҜеӣ дёәдҪҝз”ЁMaxComputeд№ӢеүҚйңҖиҰҒеңЁDataWorksдёҠйқўиҝӣиЎҢејҖйҖҡгҖӮе®һйҷ…дёҠпјҢMaxComputeиҮӘиә«д№ҹжңүдёҖдәӣз”ҹжҖҒе·Ҙе…·пјҢжҜ”еҰӮodpscmdд»ҘеҸҠMaxCompute StudioзӯүгҖӮ
 cdn.com/b03edb54aee0bb5188a4fa4d570fbd0e85b11b28.png">
cdn.com/b03edb54aee0bb5188a4fa4d570fbd0e85b11b28.png">
дәҢгҖҒеҝ«йҖҹејҖе§ӢпјҡдёҖдёӘе®Ңж•ҙз®ҖеҚ•зҡ„е°ҸдҫӢеӯҗ
еңЁжң¬йғЁеҲҶдёӯпјҢе°ҶйҖҡиҝҮдёҖдёӘз®ҖеҚ•иҖҢе®Ңж•ҙзҡ„дҫӢеӯҗеҜ№дҪҝз”Ёodpscmdе®ўжҲ·з«ҜиҝӣиЎҢж•°жҚ®еӨ„зҗҶзҡ„еҗ„дёӘйҳ¶ж®өиҝӣиЎҢд»Ӣз»ҚгҖӮеңЁж–Үдёӯд»…еҜ№дәҺеҗ„дёӘжӯҘйӘӨиҝӣиЎҢз®Җз•ҘжҸҸиҝ°пјҢе…·дҪ“зҡ„е®һи·өж“ҚдҪңиҜҰи§Ғи§Ҷйў‘еҲҶдә«гҖӮ

дҪңдёәMaxComputeзҡ„е®ўжҲ·з«Ҝе·Ҙе…·пјҢodpscmdдёҺHive CLIд»ҘеҸҠPSQLиҝҷж ·е®ўжҲ·з«Ҝе·Ҙе…·жҳҜжҜ”иҫғзұ»дјјзҡ„пјҢйғҪжҳҜдёҖдёӘй»‘еұҸзҡ„ж“ҚдҪңз®ЎзҗҶе·Ҙе…·гҖӮжҺҘдёӢжқҘдёәеӨ§е®¶еҲҶдә«дёҖдёӘе®Ңж•ҙиҖҢз®ҖеҚ•зҡ„е°ҸдҫӢеӯҗпјҢиҝҷдёӘдҫӢеӯҗиғҪеӨҹе®Ңж•ҙең°иҰҶзӣ–еӨ§ж•°жҚ®еӨ„зҗҶзҡ„еҗ„дёӘзҺҜиҠӮпјҢеҢ…жӢ¬дәҶзҺҜеўғеҮҶеӨҮгҖҒж•°жҚ®жҺҘе…ҘгҖҒж•°жҚ®еӨ„зҗҶеҠ е·Ҙд»ҘеҸҠж•°жҚ®ж¶Ҳиҙ№гҖӮеңЁеӨ§е®¶еёёи§Ғзҡ„еӨ§ж•°жҚ®еңәжҷҜдёӯпјҢдёҡеҠЎж•°жҚ®еҫҖеҫҖеҲҶж•ЈеңЁж•°жҚ®еә“д»ҘеҸҠе…¶д»–зҡ„з”ҹдә§зҺҜеўғдёӯпјҢиҖҢе®ҡжңҹдјҡиҝӣиЎҢж•°жҚ®йҮҮйӣҶжҲ–иҖ…еҗҢжӯҘпјҢе°Ҷз”ҹдә§зҺҜеўғдёӯзҡ„еўһйҮҸж•°жҚ®еҗҢжӯҘеҲ°ж•°жҚ®д»“еә“дёӯеҺ»пјҢиҝҷж ·е°ұдјҡж¶үеҸҠеҲ°ж•°жҚ®жҺҘе…ҘгҖӮд№ӢеҗҺеңЁж•°жҚ®д»“еә“дёӯе°ұдјҡе‘ЁжңҹжҖ§ең°еҒҡдёҖдәӣж•°жҚ®еӨ„зҗҶеҠ е·ҘпјҢиҝҷдәӣеҠ е·Ҙжңүж—¶еҖҷдјҡз”Ёеёёи§Ғзҡ„SQLеҒҡпјҢеҜ№дәҺMySQLиҖҢиЁҖжҸҗдҫӣдәҶMRиҝҷж ·зҡ„зј–зЁӢжЎҶжһ¶пјҢиҖҢдёҖдәӣе…·жңүж·ұеәҰйңҖжұӮзҡ„з”ЁжҲ·еҲҷдјҡйҖҡиҝҮUDFжқҘе®һзҺ°дёҖдәӣжҜ”иҫғеӨҚжқӮзҡ„дёҡеҠЎйҖ»иҫ‘пјҢеҗҢж—¶еңЁж•°жҚ®еҠ е·Ҙзҡ„ж—¶еҖҷдјҡйңҖиҰҒзӣ‘жҺ§дҪңдёҡзҡ„жү§иЎҢжғ…еҶөпјҢжүҖд»Ҙд№ҹдјҡжңүеҜ№дәҺиҝӣеәҰд»ҘеҸҠжҲҗеҠҹзҠ¶жҖҒзӯүзҡ„дҪңдёҡжҹҘзңӢе’Ңз®ЎзҗҶзҡ„йңҖжұӮгҖӮдҪңдёҡеӨ„зҗҶе®ҢжҜ•д№ӢеҗҺпјҢиҝҷж—¶еҖҷеҹәжң¬дёҠе®ҢжҲҗдәҶж•°жҚ®зҡ„жё…жҙ—е’ҢиҒҡеҗҲпјҢиҝҷж—¶еҖҷе°ұеҸҜд»ҘжҸҗдҫӣз»ҷж•°жҚ®ж¶Ҳиҙ№ж–№дҪҝз”ЁгҖӮеҜ№дәҺж•°жҚ®дҪҝз”Ёж¶Ҳиҙ№ж–№иҖҢиЁҖпјҢеҫҖеҫҖйңҖиҰҒе°ҶеҠ е·ҘеҘҪзҡ„еҸҜж¶Ҳиҙ№ж•°жҚ®еӣһжөҒеҲ°дёҡеҠЎзі»з»ҹжқҘж”Ҝж’‘еңЁзәҝеә”з”ЁпјҢжҲ–иҖ…йҖҡиҝҮJDBCжҺҘеҸЈиҝһжҺҘBIе·Ҙе…·иҝӣиЎҢеҸҜи§ҶеҢ–еҲҶжһҗпјҢиҖҢдёҡеҠЎеҲҶжһҗеёҲд№ҹеҫҖеҫҖеёҢжңӣдёӢиҪҪдёҖдәӣж•°жҚ®иҝӣиЎҢдәҢж¬ЎеҠ е·Ҙе’ҢеӨ„зҗҶгҖӮ
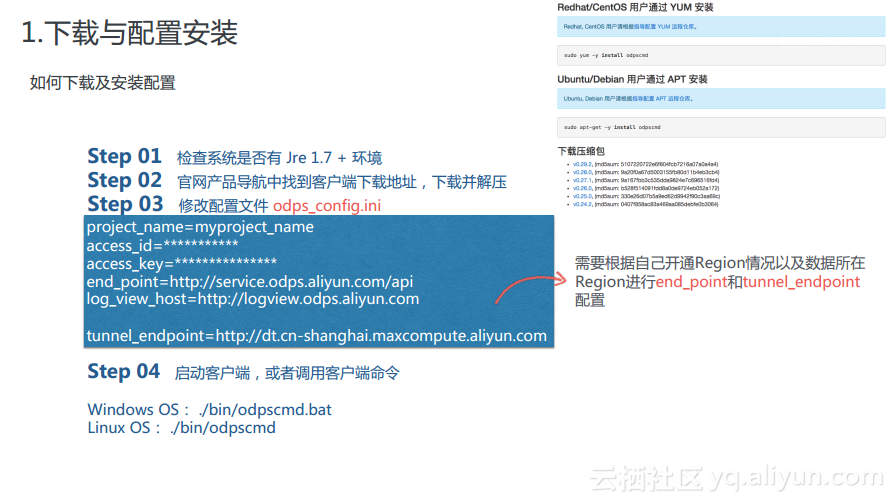
1.дёӢиҪҪдёҺй…ҚзҪ®е®үиЈ…
еҜ№дәҺodpscmdиҖҢиЁҖпјҢеӨ§е®¶еҸҜд»ҘеңЁе®ҳж–№зҪ‘з«ҷдёҠжүҫеҲ°е…¶дёӢиҪҪең°еқҖпјҢйҖҡиҝҮжөҸи§ҲеҷЁдёӢиҪҪеҲ°жң¬ең°зҡ„жҳҜдёҖдёӘZIPеҢ…пјҢи§ЈеҺӢд№ӢеҗҺе°ұеҸҜд»ҘзңӢеҲ°odpscmdдёҖдәӣзӣёе…ізӣ®еҪ•гҖӮиҖҢеҜ№дәҺLinuxз”ЁжҲ·иҖҢиЁҖпјҢд№ҹеҸҜд»ҘйҖҡиҝҮyarnжәҗеҺ»дёӢиҪҪ并е®үиЈ…зӣёеә”зҡ„еҢ…гҖӮдёӢиҪҪе®ҢжҲҗд№ӢеҗҺпјҢйңҖиҰҒдҝ®ж”№odps_config.iniй…ҚзҪ®ж–Ү件пјҢеҰӮдёӢеӣҫи“қжЎҶдёӯжүҖзӨәпјҢйңҖиҰҒеҪ•е…ҘйЎ№зӣ®еҗҚз§°пјҢеЎ«еҶҷзҷ»еҪ•и®ҝй—®иҖ…жүҖжӢҘжңүзҡ„access_idе’Ңaccess_keyзӯүи®ӨиҜҒдҝЎжҒҜгҖӮеҗҢж—¶пјҢиҝҷйҮҢйңҖиҰҒжіЁж„ҸMaxComputeеңЁеӣҪеҶ…зҡ„RegionйҮҢйқўзҡ„end_pointеҹҹеҗҚжҳҜдёҖиҮҙзҡ„пјӣиҖҢеҜ№дәҺtunnel_endpointиҖҢиЁҖпјҢеҲҷжҳҜе’ҢRegionеҜҶеҲҮзӣёе…ізҡ„пјҢжүҖд»ҘеҜ№дәҺдёҚеҗҢзҡ„RegionиҖҢиЁҖпјҢжүҖеЎ«еҶҷзҡ„tunnel_endpointжҳҜдёҚеҗҢзҡ„гҖӮеңЁеЎ«еҶҷе®Ңй…ҚзҪ®ж–Ү件д№ӢеҗҺе°ұеҸҜд»ҘеҗҜеҠЁodpscmdе®ўжҲ·з«ҜдәҶгҖӮ
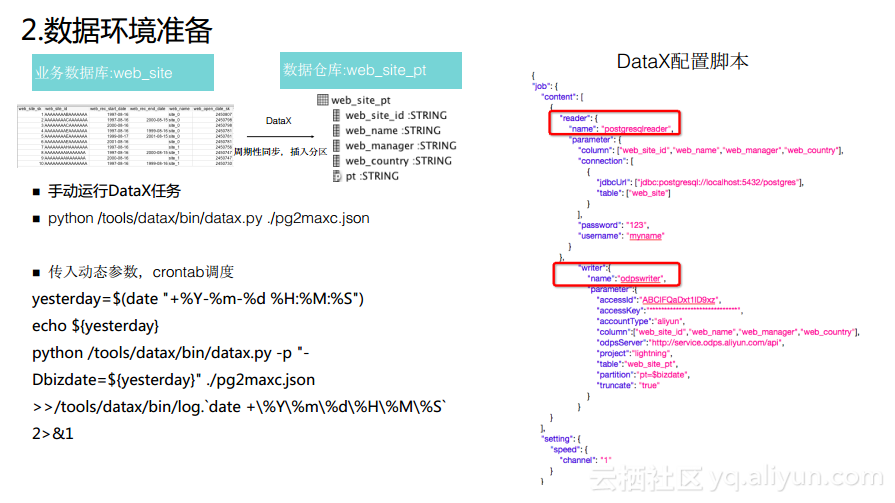
2.ж•°жҚ®зҺҜеўғеҮҶеӨҮ
еҜ№дәҺдҪҝз”Ёodpscmdе®ўжҲ·з«Ҝзҡ„еҗҢеӯҰиҖҢиЁҖпјҢеҫҖеҫҖдјҡж·ұеәҰең°дҪҝз”Ёshellд»ҘеҸҠдёҖдәӣејҖжәҗзҡ„е·Ҙе…·иҝӣиЎҢй…ҚеҗҲгҖӮиҝҷйҮҢдёҫдёӘдҫӢеӯҗпјҢеңЁдёҡеҠЎж•°жҚ®еә“дёӯжңүдёҖеј ж—Ҙеёёзҡ„дёҡеҠЎиЎЁпјҢеҸҜиғҪеӯҳеӮЁдәҶж—ҘеёёдёҡеҠЎзӮ№еҮ»зҡ„ж—Ҙеҝ—д»ҘеҸҠж–°еўһзҡ„и®ўеҚ•ж•°жҚ®пјҢйӮЈд№Ҳеёёи§ҒеңәжҷҜжҳҜйңҖиҰҒе°Ҷж•°жҚ®еҗҢжӯҘеҲ°ж•°жҚ®д»“еә“пјҢиҝҷдёӘиҝҮзЁӢйңҖиҰҒдёҖдәӣж•°жҚ®еҗҢжӯҘе·Ҙе…·е‘ЁжңҹжҖ§ең°е°Ҷж•°жҚ®еҠ иҪҪеҲ°ж•°жҚ®д»“еә“зҡ„иЎЁйҮҢйқўпјҢиҖҢдё”еҫҖеҫҖдјҡйңҖиҰҒе»әз«Ӣзӣёеә”зҡ„еҲҶеҢәиЎЁпјҢе°Ҷзӣёеә”зҡ„ж•°жҚ®ж”ҫе…ҘеҲ°зӣёеә”зҡ„еҲҶеҢәйҮҢйқўеҺ»гҖӮиҝҷдёҖдёӘд»»еҠЎеҸҜд»ҘйҖҡиҝҮејҖжәҗе·Ҙе…·DataXе®ҢжҲҗпјҢе®һзҺ°е°Ҷж•°жҚ®еҗҢжӯҘең°жҸ’е…ҘеҲ°ж•°жҚ®д»“еә“иЎЁйҮҢйқўеҺ»гҖӮиҖҢеҪ“жүӢе·Ҙй…ҚзҪ®DataXе‘Ҫд»Өж—¶пјҢжңүдёҖдәӣеғҸеҲҶеҢәеӯ—ж®өиҝҷж ·зҡ„еҸӮж•°еҫҖеҫҖжҳҜеҠЁжҖҒзҡ„пјҢжүҖд»Ҙд№ҹйңҖиҰҒеҠЁжҖҒең°ж”ҫе…ҘеҲ°DataXи„ҡжң¬зҡ„еҸӮж•°еҪ“дёӯгҖӮ
3.ж•°жҚ®еҠ е·ҘеӨ„зҗҶ
еҪ“ж•°жҚ®еҗҢжӯҘе®ҢжҲҗд№ӢеҗҺпјҢеңЁеҫҲеӨҡзҡ„еңәжҷҜдёӯйңҖиҰҒеҜ№дёҖдәӣеҲҶеҢәиЎЁеҒҡеҠ е·ҘеӨ„зҗҶпјҢеҰӮдёӢеӣҫжүҖзӨәзҡ„дҫӢеӯҗдёӯжҳҜж–°е»әдёҖеј иЎЁжҲ–иҖ…insert OVERWRITEдёҖеј иЎЁпјҢиҝҳдјҡеҜ№дәҺж•°жҚ®иЎЁдёӯз”ұдәҺеўһйҮҸеҗҢжӯҘиҖҢеј•е…Ҙзҡ„ж–°зҡ„еҲҶеҢәж•°жҚ®иҝӣиЎҢжұҮжҖ»иҒҡеҗҲи®Ўз®—пјҢ并е°Ҷз»“жһңз”ҹжҲҗеҲ°ж–°иЎЁдёӯгҖӮиҖҢеҪ“дҪңдёҡйқһеёёй•ҝзҡ„ж—¶еҖҷпјҢodpscmdе·Ҙе…·д№ҹжҸҗдҫӣдәҶдҪңдёҡзӣ‘жҺ§е‘Ҫд»ӨвҖңShow pвҖқпјҢе°ұиғҪеӨҹжЈҖзҙўеҮәе…ЁйҮҸеҺҶеҸІдҪңдёҡгҖӮиҖҢжҜҸдёӘдҪңдёҡйғҪдјҡжңүиҮӘе·ұзҡ„instance_idпјҢиҖҢеҜ№дәҺMaxComputeиҖҢиЁҖпјҢжңҖеҹәжң¬зҡ„д»»еҠЎеҚ•е…ғе°ұжҳҜinstanceпјҢжҜҸдёӘinstanceе°ұжҳҜжҸҗдәӨдҪңдёҡзҡ„е®һдҫӢгҖӮж №жҚ®instance_idеңЁдәӢеҗҺиҝҳеҸҜд»ҘжЈҖзҙўеҲ°е…¶еҜ№еә”зҡ„LogviewгҖӮжҖ»д№ӢпјҢodpscmdжң¬иә«е°ұжҸҗдҫӣдәҶе®Ңж•ҙзҡ„дҪңдёҡжҸҗдәӨгҖҒдҪңдёҡдәӢеҗҺжҹҘзңӢд»ҘеҸҠеҜ№дәҺжҢҮе®ҡдҪңдёҡиҜҰжғ…зҡ„жҹҘзңӢиғҪеҠӣгҖӮеңЁжң¬ж¬ЎеҲҶдә«зҡ„дҫӢеӯҗдёӯпјҢдҪҝз”Ёзҡ„жҳҜTunnelеҜ№дәҺMaxComputeзҡ„з»“жһңж•°жҚ®йӣҶиҝӣиЎҢдёӢиҪҪпјҢ并йҖҡиҝҮExcelжҲ–иҖ…е…¶д»–зҡ„е·Ҙе…·иҝӣиЎҢеҲҶжһҗпјҢеӣ жӯӨжү§иЎҢtunnel downloadе°ұиғҪеӨҹе°Ҷз»“жһңж•°жҚ®иЎЁдёӢиҪҪеҲ°жң¬ең°ж–Ү件дёӯгҖӮ

дёүгҖҒе®ўжҲ·з«ҜжҸҗдҫӣзҡ„иғҪеҠӣжЎҶжһ¶
дёҠиҝ°зҡ„еҶ…е®№е…¶е®һжҳҜеёҢжңӣйҖҡиҝҮдёҖдёӘз®ҖеҚ•зҡ„дҫӢеӯҗе°Ҷж—ҘеёёиҫғдёәеӨҚжқӮзҡ„еӨ§ж•°жҚ®еӨ„зҗҶжөҒзЁӢе’ҢзҺҜиҠӮиҝӣиЎҢз®ҖеҚ•еӣһжәҜпјҢеҖҹжӯӨеёҢжңӣеҗ‘еӨ§е®¶дј иҫҫMaxComputeе®ўжҲ·з«Ҝе·Ҙе…·иғҪеӨҹж”ҜжҢҒж—Ҙеёёе·ҘдҪңзҡ„еҗ„дёӘзҺҜиҠӮгҖӮйӮЈд№ҲпјҢMaxComputeе®ўжҲ·з«Ҝе·Ҙ具究з«ҹжңүд»Җд№Ҳж ·зҡ„еҠҹиғҪиғҪеӨҹж”Ҝж’‘еҗ„дёӘзҺҜиҠӮзҡ„йңҖиҰҒе‘ўпјҹе…¶е®һпјҢodpscmdзҡ„еҠҹиғҪеҢ…еҗ«дәҶеҜ№дәҺйЎ№зӣ®з©әй—ҙзҡ„з®ЎзҗҶпјҢеҜ№иЎЁгҖҒи§Ҷеӣҫд»ҘеҸҠж“ҚдҪңеҲҶеҢәзҡ„ж“ҚдҪңз®ЎзҗҶпјҢеҜ№иө„жәҗгҖҒеҮҪж•°зҡ„з®ЎзҗҶпјҢеҜ№дҪңдёҡе®һдҫӢзҡ„з®ЎзҗҶпјҢ并且жҸҗдҫӣж•°жҚ®дёҠдј дёӢиҪҪзҡ„ж•°жҚ®йҖҡйҒ“пјҢеҗҢж—¶д№ҹжҸҗдҫӣе®үе…ЁдёҺжқғйҷҗз®ЎзҗҶзӯүе…¶д»–зҡ„ж“ҚдҪңгҖӮжҺҘдёӢжқҘе°ұдёәеӨ§е®¶дҫқж¬Ўд»Ӣз»ҚгҖӮ
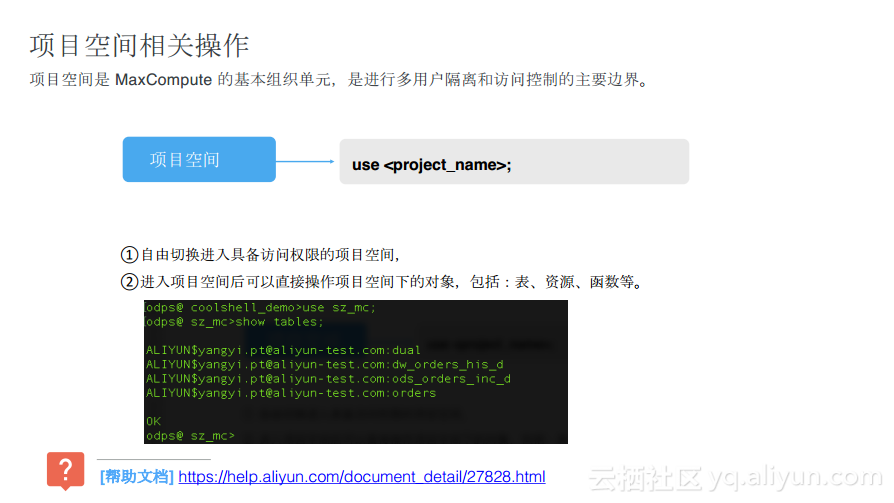
йЎ№зӣ®з©әй—ҙзӣёе…іж“ҚдҪң
еңЁиҝһжҺҘйЎ№зӣ®д№ӢеүҚйҰ–е…Ҳе·Із»ҸеҲӣе»әдәҶдёҖдёӘMaxComputeйЎ№зӣ®пјҢеңЁдҪҝз”ЁйЎ№зӣ®зҡ„ж—¶еҖҷеҸҜд»ҘдҪҝз”Ёзұ»дјјдәҺHiveж•°жҚ®еә“дёҖж ·вҖңuse <project_name>;вҖқиҝҷж ·зҡ„е‘Ҫд»ӨеҺ»и·Ёз©әй—ҙеҲҮжҚўпјҢйҖҡиҝҮиҝҷз§Қж–№ејҸеҸҜд»ҘдҪҝеҫ—з”ЁжҲ·еңЁеӨҡдёӘйЎ№зӣ®д№Ӣй—ҙиҝӣиЎҢеҝ«йҖҹеҲҮжҚўпјҢеҪ“дҪҝз”ЁдәҶвҖңuse <project_name>;вҖқд№ӢеҗҺпјҢеҗҺз»ӯзҡ„жүҖжңүе‘Ҫд»Өе°ҶдјҡзӣҙжҺҘеә”з”ЁеҲ°еҲ¶е®ҡзҡ„йЎ№зӣ®дёӯгҖӮ
иЎЁзӣёе…іж“ҚдҪң
иЎЁзӣёе…іж“ҚдҪңзҡ„е‘Ҫд»ӨеңЁodpscmdе®ўжҲ·з«Ҝе·Ҙе…·дёҠиғҪеӨҹеҫҲиҪ»жқҫең°иҝӣиЎҢж“ҚдҪңпјҢе…¶еҢ…еҗ«дәҶиЎЁзҡ„еҲӣе»әе’ҢеҲ йҷӨд»ҘеҸҠеҜ№дәҺиЎЁзҡ„дҝ®ж”№пјҢжҜ”еҰӮдҝ®ж”№еҲ—еҗҚгҖҒдҝ®ж”№еҲҶеҢәгҖҒдҝ®ж”№еұһдё»OwnerгҖҒйқһеҲҶеҢәж•°жҚ®зҡ„еҲ йҷӨзӯүгҖӮе…¶д»–зҡ„ж“ҚдҪңиҜёеҰӮshow tablesд№ҹйғҪе…је®№дәҶHiveзҡ„дҪҝз”Ёд№ жғҜгҖӮеңЁдёӢеӣҫдёӯдёәеӨ§е®¶еҲ—еҮәдәҶдёҺиЎЁзӣёе…ізҡ„ж“ҚдҪңе‘Ҫд»Өд»ҘеҸҠеё®еҠ©ж–ҮжЎЈгҖӮ
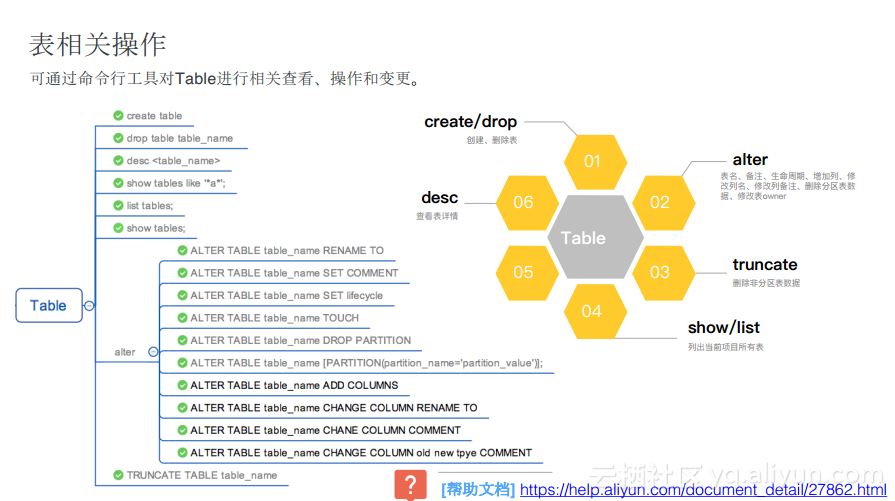
и§ҶеӣҫеҸҠеҲҶеҢәзӣёе…іж“ҚдҪң
еҜ№дәҺи§Ҷеӣҫе’ҢеҲҶеҢәиҖҢиЁҖпјҢodpscmdд№ҹеҸҜд»ҘйҖҡиҝҮviewж–№ејҸжҠҠдёҖдәӣеӨҚжқӮзҡ„еӨ„зҗҶйҖ»иҫ‘иҝӣиЎҢдәҢж¬Ўе°ҒиЈ…пјҢжӣҙе®№жҳ“ең°еҜ№еӨ–иҝӣиЎҢжҡҙйңІгҖӮеҜ№дәҺviewиҖҢиЁҖпјҢжҸҗдҫӣдәҶеҲӣе»әгҖҒдҝ®ж”№гҖҒеҲ йҷӨд»ҘеҸҠжҹҘзңӢзҡ„ж“ҚдҪңгҖӮеҜ№дәҺPartitionиҖҢиЁҖпјҢеӨ§е®¶е…іжіЁзҡ„д№ҹжҜ”иҫғеӨҡпјҢеёёи§Ғзҡ„е°ұжҳҜеҰӮдҪ•жҹҘзңӢиЎЁзҡ„еҲҶеҢәпјҢйҖҡиҝҮshow partition <иЎЁеҗҚ>зҡ„ж–№ејҸе°ұиғҪеӨҹеҲ—еҮәиҝҷеј иЎЁйҮҢйқўжңүеӨҡе°‘дёӘеҲҶеҢәпјҢеҗҢж—¶еҲҶеҢәзҡ„еҗҚз§°жҳҜд»Җд№ҲгҖӮеҗҢж—¶еҸҜд»ҘеҖҹеҠ©alter <иЎЁеҗҚ>зҡ„ж–№ејҸе°ҶжҹҗдёҖдёӘеҲҶеҢәеҲ йҷӨжҺүжҲ–иҖ…дҝ®ж”№е…¶е‘ҪеҗҚгҖӮ

иө„жәҗдёҺеҮҪж•°зӣёе…іж“ҚдҪң
ж·ұеәҰз”ЁжҲ·еңЁдҪҝз”Ёж—¶е°ұдјҡеҸ‘зҺ°пјҢеҫҲеӨҡеҶ…зҪ®еҮҪж•°дёҚиғҪеӨҹж»Ўи¶іиҮӘиә«йҖ»иҫ‘йңҖжұӮпјҢеҫҖеҫҖдјҡйңҖиҰҒдҪҝз”ЁдёҖдәӣUDFжқҘиҝӣиЎҢеӨҚжқӮи®Ўз®—пјҢд№ҹеҸҜд»ҘйҖҡиҝҮMRжқҘеҒҡжӣҙиҮӘз”ұзҡ„и®Ўз®—йҖ»иҫ‘пјҢиҝҷдәӣж—¶еҖҷз”ЁжҲ·йңҖиҰҒдёҠдј дёҖдёӘиҮӘе®ҡд№үејҖеҸ‘еҢ…пјҢиҝҷдәӣеҜ№дәҺMaxComputeиҖҢиЁҖе°ұжҳҜиө„жәҗResourceгҖӮйҖҡиҝҮodpscmdеҸҜд»ҘдёҠдј д№ҹеҸҜд»ҘжҹҘзңӢйЎ№зӣ®дёӯзҡ„иө„жәҗгҖӮеҜ№дәҺеҮҪж•°иҖҢиЁҖпјҢз”ЁжҲ·еҲӣе»әUDFзҡ„ж—¶еҖҷпјҢе°ұеҸҜд»ҘдҪҝз”Ёcreateж–№ејҸеҫҲе®№жҳ“ең°иҝӣиЎҢеҲӣе»әгҖӮ

е®һдҫӢзӣёе…іж“ҚдҪң
еҜ№дәҺе®һдҫӢиҖҢиЁҖпјҢеӨ§е®¶еҸҜиғҪдјҡеңЁе®ўжҲ·з«ҜиҝҗиЎҢеҫҲеӨҡдҪңдёҡпјҢеҸҜиғҪеңЁжҹҗдёӘж—¶й—ҙжғіиҰҒзңӢзңӢдҪңдёҡжҳҜеҗҰе·Із»ҸиҝҗиЎҢе®ҢжҲҗдәҶпјҢдҪҶжҳҜеҸҲи®°дёҚдҪҸдҪңдёҡзҡ„е…·дҪ“IDжҳҜд»Җд№ҲпјҢиҝҷж—¶еҖҷе°ұеҸҜд»ҘдҪҝз”Ёshow pе’Ңshow instanceе‘Ҫд»ӨжқҘеҲ—еҮәжҸҗдәӨиҝҮзҡ„еҺҶеҸІдҪңдёҡпјҢ并且иҝҳж”ҜжҢҒжҢүз…§ж—¶й—ҙзӯүжқЎд»¶иҝӣиЎҢиҝҮж»ӨгҖӮеҪ“instanceеҲ—иЎЁиҺ·еҸ–д№ӢеҗҺпјҢеҜ№зү№е®ҡзҡ„д»»еҠЎеҒҡж“ҚдҪңиҝҳеҸҜд»ҘдҪҝз”ЁвҖңwaitвҖқе‘Ҫд»ӨжҹҘзңӢе…¶иҜҰжғ…гҖӮ

Tunnelзӣёе…іж“ҚдҪң
жңүдёҖз§Қж“ҚдҪңе‘Ҫд»Өе®һйҷ…дёҠжҳҜжҸҗдәӨз»ҷжҺ§еҲ¶гҖҒз®ЎзҗҶгҖҒж•°жҚ®жҹҘиҜўдҪңдёҡзҡ„е‘Ҫд»ӨпјҢ并且иҝҳжңүдёҖйғЁеҲҶжҳҜеҒҡж•°жҚ®зҡ„дёҠдёӢиЎҢпјҢиҝҷжңүеҲ«дәҺеүҚйқўжҸҗеҲ°зҡ„д»»еҠЎжҸҗдәӨпјҢжӣҙеӨҡзҡ„жҳҜеҜ№дәҺж•°жҚ®зҡ„еҗһеҗҗйҮҸиҰҒжұӮжҜ”иҫғй«ҳпјҢеӣ жӯӨodpscmdйӣҶжҲҗдәҶTunnelе·Ҙе…·пјҢиғҪеӨҹеңЁе‘Ҫд»ӨиЎҢйҮҢйқўиҝӣиЎҢж•°жҚ®дёҠдј д»ҘеҸҠдёӢиҪҪзӯүгҖӮиҝҷйҮҢз»ҸеёёдјҡйҒҮеҲ°зҡ„й—®йўҳе°ұжҳҜеҫҲеӨҡејҖеҸ‘иҖ…еңЁиҮӘе·ұзҡ„з”ҹдә§зҺҜеўғйҮҢйқўйҖҡиҝҮTunnelеҒҡж•°жҚ®еҗҢжӯҘпјҢиҖҢиҝҷж—¶еҖҷеҜ№дәҺж–ӯзӮ№з»ӯдј зҡ„иғҪеҠӣиҰҒжұӮе°ұдјҡжҜ”иҫғй«ҳдәҶгҖӮ
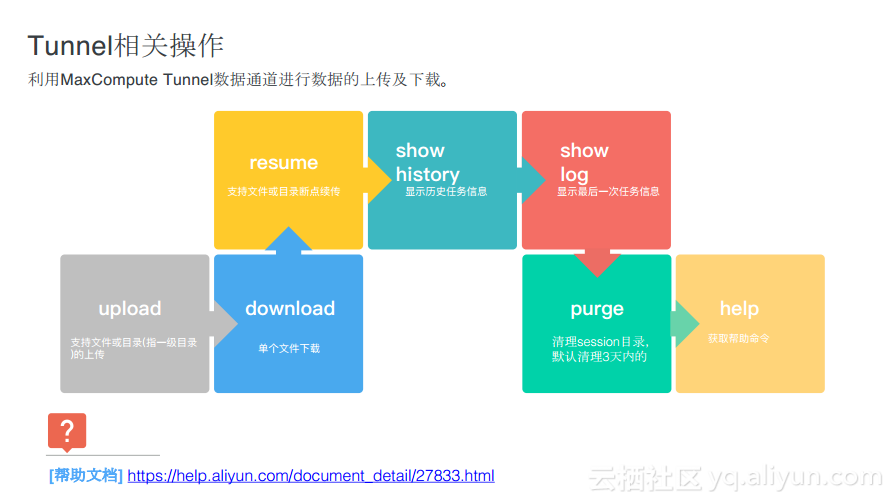
е®үе…ЁеҸҠжқғйҷҗзӣёе…іж“ҚдҪң
еҫҲеӨҡз”ЁжҲ·еҜ№дәҺDataWorksжҜ”иҫғзҶҹжӮүпјҢDataWorksйҮҢйқўжңүжҜ”иҫғз®ҖеҚ•жҳҺдәҶзҡ„з”ЁжҲ·и§’иүІжҺҲжқғз®ЎзҗҶзҡ„иғҪеҠӣгҖӮиҖҢеҒҡж•°жҚ®еә“зҡ„дёҖдәӣеҗҢеӯҰеҲҷжӣҙеҠ д№ жғҜдәҺй»‘еұҸзҡ„ж–№ејҸпјҢд№ҹе°ұжҳҜйҖҡиҝҮе‘Ҫд»Өж–№ејҸеҒҡе®үе…Ёе’Ңжқғйҷҗзҡ„з®ЎзҗҶгҖӮ

и§’иүІзӣёе…іжқғйҷҗз®ЎзҗҶ
жҜ”еҰӮеҜ№дәҺи§’иүІзӣёе…іжқғйҷҗзҡ„з®ЎзҗҶпјҢеҸҜд»ҘйҖҡиҝҮcreate roleеҸҜд»ҘеңЁеӨ§ж•°жҚ®йЎ№зӣ®дёӯеҲӣе»әи§’иүІпјҢ并еҜ№и§’иүІиөӢжқғпјҢе°ҶжҹҗдёҖдёӘз”ЁжҲ·еҠ е…ҘеҲ°и§’иүІеҪ“дёӯеҺ»пјҢжҲ–иҖ…移йҷӨзӣёе…ізҡ„и§’иүІгҖӮеҗҢж—¶д№ҹиғҪеӨҹжҹҘзңӢ究з«ҹжңүе“Әдәӣи§’иүІгҖӮ

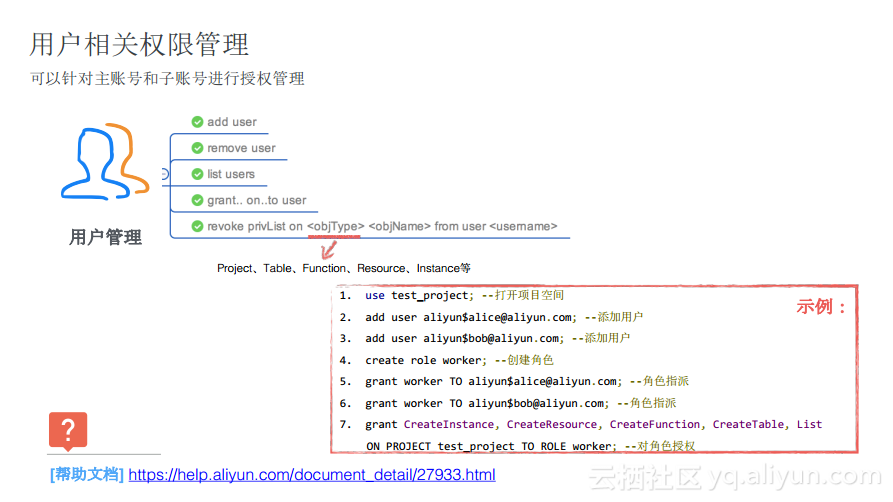
з”ЁжҲ·зӣёе…іжқғйҷҗз®ЎзҗҶ
еҜ№дәҺз”ЁжҲ·зӣёе…іжқғйҷҗз®ЎзҗҶиҖҢиЁҖпјҢжңҖеёёи§Ғе°ұжҳҜе°ҶдёҖдёӘйҳҝйҮҢдә‘зҡ„иҙҰеҸ·еҠ иҝӣйЎ№зӣ®дёӯеҺ»пјҢ并дёәз”ЁжҲ·жҢҮе®ҡе…·дҪ“зҡ„и§’иүІпјҢ并иҺ·еҸ–еҜ№еә”зҡ„жқғйҷҗгҖӮ
йЎ№зӣ®з©әй—ҙзҡ„ж•°жҚ®дҝқжҠӨ
дёҖдәӣз®ЎзҗҶе‘ҳеҜ№дәҺйЎ№зӣ®з©әй—ҙзҡ„дҝқжҠӨиҰҒжұӮжҜ”иҫғй«ҳпјҢиҖҢеңЁMaxComputeеҪ“дёӯеӨ©з„¶еҜ№дәҺеӨҡз§ҹжҲ·ж”ҜжҢҒж–№йқўеҒҡдәҶеҫҲеӨҡе·ҘдҪңгҖӮжҜ”еҰӮеҸҜд»Ҙи®ҫзҪ®зҰҒжӯўйЎ№зӣ®ж•°жҚ®иў«дёӢиҪҪпјҢд»…е…Ғи®ёеҮ дёӘжҺҲдҝЎзҡ„йЎ№зӣ®д№Ӣй—ҙе…ұдә«ж•°жҚ®пјҢиҝҷж ·е°ұеҸҜд»Ҙе°ҶдёҺйЎ№зӣ®з©әй—ҙзӣёе…ізҡ„жқғйҷҗдҝқжҠӨиғҪеҠӣйғҪж”ҫеңЁodpscmdдёӯгҖӮ

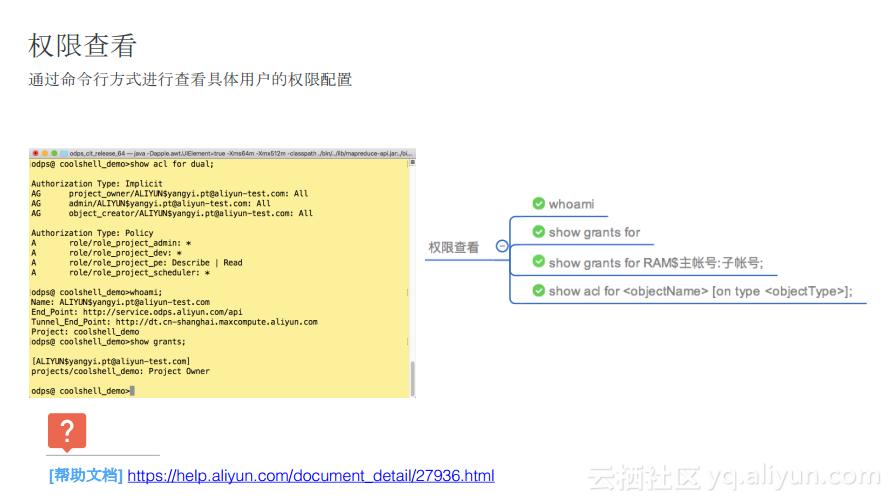
жқғйҷҗжҹҘзңӢ
еҗҢж—¶пјҢodpscmdд№ҹз»ҷеҮәдәҶжқғйҷҗжҹҘзңӢзӣёе…ізҡ„е‘Ҫд»ӨгҖӮ
е…¶д»–ж“ҚдҪң
odpscmdиҝҳжҸҗдҫӣдёҖдәӣе…¶д»–еёёз”Ёзҡ„ж“ҚдҪңгҖӮеӨ§е®¶еҸҜиғҪз»ҸеёёдјҡйҒҮеҲ°дёҖдәӣжҖ§иғҪдјҳеҢ–зҡ„еңәжҷҜпјҢжҜ”еҰӮеҜ№дәҺдёҖеј жҜ”иҫғеӨ§зҡ„ж•°жҚ®иЎЁеҒҡжү«жҸҸеҲҶеҢәзҡ„еҲҮеҲҶпјҢиҝҷж ·еҸҜд»ҘеўһеҠ дҪңдёҡд»»еҠЎзҡ„并иЎҢеәҰпјҢиҝҷдәӣдјҳеҢ–жүӢж®өзҡ„ејҖе…ійғҪеҸҜд»ҘйҖҡиҝҮе‘Ҫд»ӨиЎҢиҝӣиЎҢеҝ«йҖҹи®ҫзҪ®пјҢеҗҢж—¶д№ҹеҸҜд»ҘеҜ№дәҺдёҖдәӣSQLиҝӣиЎҢжҲҗжң¬йў„дј°пјҢ并且д№ҹеҸҜд»ҘиҪ»жқҫең°иҺ·еҸ–её®еҠ©дҝЎжҒҜгҖӮз»јдёҠжүҖиҝ°пјҢodpscmdжҳҜдёҖдёӘжҜ”иҫғејәеӨ§е№¶дё”е®Ңж•ҙзҡ„е®ўжҲ·з«Ҝе·Ҙе…·гҖӮ

еӣӣгҖҒе®ўжҲ·з«ҜйҮҚзӮ№еңәжҷҜиҜҙжҳҺ
жҺҘдёӢжқҘйҮҚзӮ№еҲҶдә«еҮ дёӘе®ўжҲ·з«ҜдҪҝз”Ёзҡ„йҮҚзӮ№еңәжҷҜгҖӮ
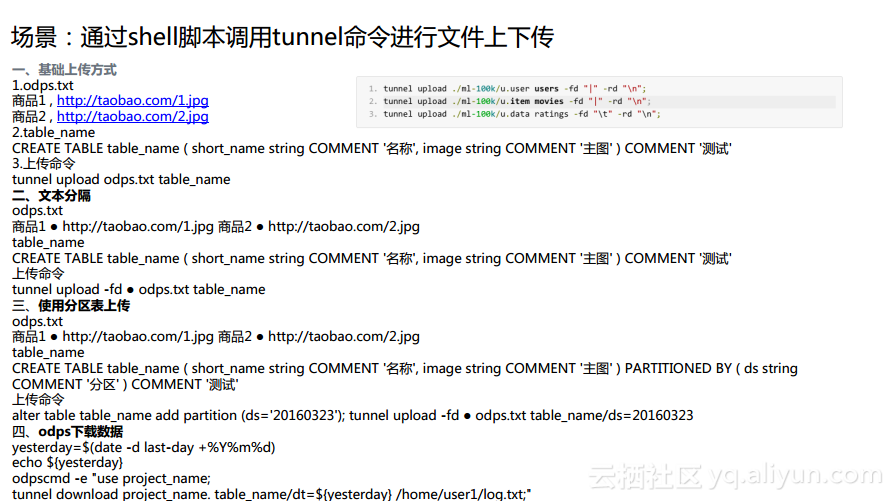
еңәжҷҜ1пјҡйҖҡиҝҮshellи„ҡжң¬и°ғз”Ёtunnelе‘Ҫд»ӨиҝӣиЎҢж–Ү件дёҠдёӢдј
еңЁиҝҷз§ҚеңәжҷҜдёӢпјҢй»ҳи®ӨдјҡйҖҡиҝҮеҲҶйҡ”з¬Ұзҡ„ж–№ејҸиҝӣиЎҢдёҠдј гҖӮиҖҢеҪ“з”ЁжҲ·йҒҮеҲ°дәҶдёҖдәӣйқһж ҮеҮҶеҢ–зҡ„еҲҶйҡ”з¬Ұж—¶пјҢйҖҡиҝҮ-fdж–№ејҸе°ұиғҪеӨҹеҝ«йҖҹйҖӮй…ҚеҜ№еә”зҡ„еҲ—еҲҶйҡ”з¬ҰгҖӮиҖҢеҫҲеӨҡеҗҢеӯҰд№ҹеёҢжңӣйҖҡиҝҮshellи„ҡжң¬зҡ„ж–№ејҸиғҪеӨҹеҠЁжҖҒең°иҝӣиЎҢи°ғеәҰпјҢиҝҷйҮҢд№ҹдјҡж¶үеҸҠеҲ°еҠЁжҖҒеҸӮж•°дј е…Ҙзҡ„й—®йўҳгҖӮеҰӮдёӢеӣҫдёӯзӨәдҫӢжүҖзӨәпјҢеҸҜд»Ҙе°Ҷж—ҘжңҹеҠЁжҖҒең°дј е…ҘеҲ°Tunnelе‘Ҫд»ӨеҪ“дёӯеҺ»пјҢе‘ЁжңҹжҖ§ең°е°Ҷж–°еўһзҡ„ж—Ҙеҝ—ж–Ү件дёҠдј жҲ–иҖ…дёӢиҪҪеҲ°еҜ№еә”зҡ„зӣ®еҪ•дёӯеҺ»гҖӮ
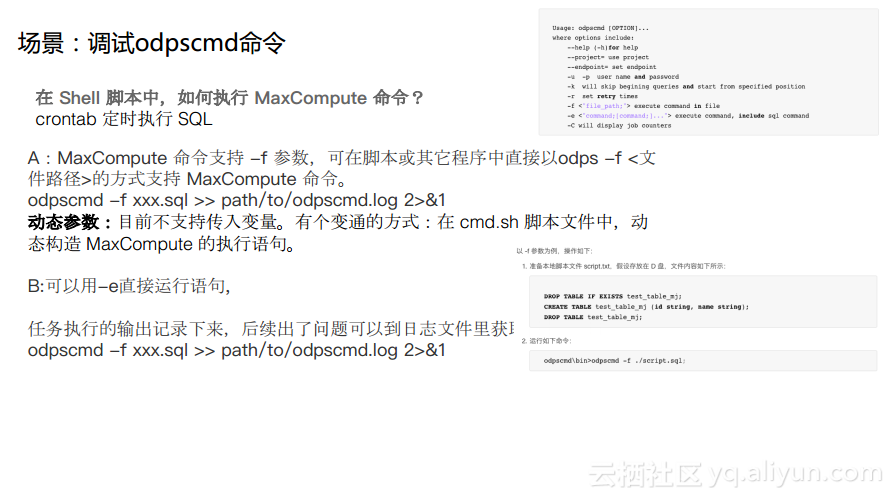
еңәжҷҜ2пјҡи°ғиҜ•odpscmdе‘Ҫд»Ө
еңЁйқһдәӨдә’ејҸзҡ„еңәжҷҜдёӢпјҢMaxComputeе‘Ҫд»Өж”ҜжҢҒ-fеҸӮж•°пјҢеҸҜеңЁи„ҡжң¬жҲ–е…¶е®ғзЁӢеәҸдёӯзӣҙжҺҘд»Ҙodps -f <ж–Ү件и·Ҝеҫ„>зҡ„ж–№ејҸж”ҜжҢҒMaxComputeе‘Ҫд»ӨгҖӮжӯӨеӨ–MaxComputeе‘Ҫд»Өиҝҳж”ҜжҢҒ-eеҸӮж•°пјҢеңЁиҝҷз§Қж–№ејҸдёӢйңҖиҰҒйҖҡиҝҮжӢ¬еҸ·зҡ„ж–№ејҸе°ҶSQLе‘Ҫд»ӨеөҢе…ҘиҝӣеҺ»гҖӮ
еңәжҷҜ3пјҡиҝҗиЎҢж•°жҚ®жҹҘиҜў/ж•°жҚ®еҠ е·ҘдҪңдёҡUDF
еңЁodpscmdйҮҢйқўиғҪеӨҹеҺҹз”ҹең°ж”ҜжҢҒUDFе’ҢMRпјҢеҰӮдёӢеӣҫжүҖзӨәзҡ„жҳҜUDFдҪңдёҡзҡ„дҪҝз”ЁжөҒзЁӢгҖӮ

еңЁеүҚдёӨдёӘзҺҜиҠӮйңҖиҰҒеңЁзәҝдёӢе°ҶеҶҷеҘҪзҡ„UDFзј–еҶҷеҘҪзҡ„зЁӢеәҸжү“жҲҗJarеҢ…пјҢеңЁе‘Ҫд»ӨиЎҢеҪ“дёӯйҖҡиҝҮвҖңadd jarвҖқзҡ„ж–№ејҸжҠҠе…¶дј е…ҘеҲ°жҢҮе®ҡзҡ„йЎ№зӣ®дёӯдҪңдёәдёҖдёӘиө„жәҗгҖӮиҖҢйҖҡиҝҮcreatefunctionе‘Ҫд»ӨеҸҜд»Ҙе‘ҪеҗҚдёҖдёӘиҮӘе®ҡд№үеҮҪ数并дәҺдёҠдј зҡ„дё»еҮҪж•°иҝӣиЎҢе…іиҒ”пјҢиҝҷж ·е°ұзңҹжӯЈең°е»әз«ӢдәҶиҝҷж ·зҡ„дёҖдёӘеҮҪж•°гҖӮд№ӢеҗҺеңЁжөӢиҜ•жҲ–иҖ…дҪҝз”Ёзҡ„ж—¶еҖҷйҖҡиҝҮи°ғз”ЁеҲҡжүҚеҲӣе»әзҡ„UDFиҝӣиЎҢдҪҝз”ЁгҖӮиҝҷж ·е°ұжҳҜйҖҡиҝҮodpscmdе®һзҺ°UDFзҡ„е®Ңж•ҙеҲӣе»әгҖӮ
еңәжҷҜ4пјҡиҝҗиЎҢж•°жҚ®жҹҘиҜў/ж•°жҚ®еҠ е·ҘдҪңдёҡMR
еҜ№дәҺMRдҪңдёҡиҖҢиЁҖпјҢйҰ–е…ҲйңҖиҰҒеңЁзј–иҜ‘зҺҜеўғдёӯзј–еҶҷ并жү“еҢ…MRзЁӢеәҸпјҢжү“еҢ…е®ҢжҲҗд№ӢеҗҺе°Ҷе…¶дҪңдёәдёҖдёӘиө„жәҗжіЁеҶҢеҲ°йЎ№зӣ®д№ӢдёӯпјҢеңЁodpscmdйҮҢйқўжү§иЎҢвҖңadd jarвҖқпјҢд№ӢеҗҺеңЁе‘Ҫд»ӨиЎҢйҮҢйқўиҝҗиЎҢMRдҪңдёҡпјҢд№ӢеҗҺе°ұеҸҜд»ҘиҺ·еҫ—зӣёеә”зҡ„з»“жһңгҖӮ

дә”гҖҒе®№жҳ“зў°еҲ°зҡ„й—®йўҳ
жҺҘдёӢжқҘдёәеӨ§е®¶жҖ»з»“дәҶеҮ дёӘеёёи§Ғзҡ„й—®йўҳгҖӮйҰ–е…ҲжҳҜеҠЁжҖҒеҸӮж•°зҡ„дј е…ҘпјҢеӣ дёәodpscmdжҳҜдёҖз§Қе‘Ҫд»ӨиЎҢзҡ„ж–№ејҸпјҢйӮЈд№ҲеӨ§е®¶йҖҡиҝҮshellи°ғз”Ёзҡ„жҜ”иҫғеӨҡпјҢиҝҷж—¶еҖҷе°ұж¶үеҸҠеҲ°еҰӮдҪ•е°ҶдёҖдәӣеҠЁжҖҒзҡ„еҸӮж•°и°ғе…ҘиҝӣеҺ»пјҢе…¶е®һеҸҜд»ҘйҖҡиҝҮshellзҡ„ж–№ејҸеҸҳзӣёең°е°ҶдёҖдәӣеҠЁжҖҒдҝЎжҒҜдј йҖ’иҝӣжқҘгҖӮиҝҳжңүдёҖдёӘеёёи§Ғзҡ„й—®йўҳе°ұжҳҜвҖңжүӢе·Ҙжү§иЎҢodpscmdе‘Ҫд»ӨжӯЈеёёпјҢйҖҡиҝҮshellи„ҡжң¬и°ғз”Ёж—¶жҠҘй”ҷвҖқпјҢжӯӨж—¶е°ұйңҖиҰҒжЈҖжҹҘshellи„ҡжң¬дёӢжңүжІЎжңүи®ҫзҪ®JAVAзҡ„зҺҜеўғеҸҳйҮҸгҖӮ

дёҠиҝ°е°ұжҳҜе°Ҹзј–дёәеӨ§е®¶еҲҶдә«зҡ„MaxComputeдёӯodpscmdеҰӮдҪ•дҪҝз”ЁдәҶпјҢеҰӮжһңеҲҡеҘҪжңүзұ»дјјзҡ„з–‘жғ‘пјҢдёҚеҰЁеҸӮз…§дёҠиҝ°еҲҶжһҗиҝӣиЎҢзҗҶи§ЈгҖӮеҰӮжһңжғізҹҘйҒ“жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





