怎样从PPI网络进一步挖掘信息,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
从数据库中得到蛋白质的相互作用信息之后,我们可以构建蛋白质间的相互作用网络,但是这个网络是非常复杂的,节点和连线的个数很多,如果从整体上看,很难挖掘出任何有生物学价值的信息,所以我们需要借助一些算法来深入挖掘。
随着各个数据库中信息通量的不断提高,基于网络的分析方法越来越受欢迎,比如我们常见的蛋白质相互网络,基因共表达网络,转录因子调控网络,pathway网络等等,为了更好的理解后续的数据挖掘算法,首选要对网路的属性有一些基本了解。
从数据结构上看,我们所说的网络network是属于图Graph这一数据结构的,网络是一种比较直观的描述,就是点和点之间的连线,在算法上,为了准确描述一个网络,通常借助于邻接矩阵,示意如下
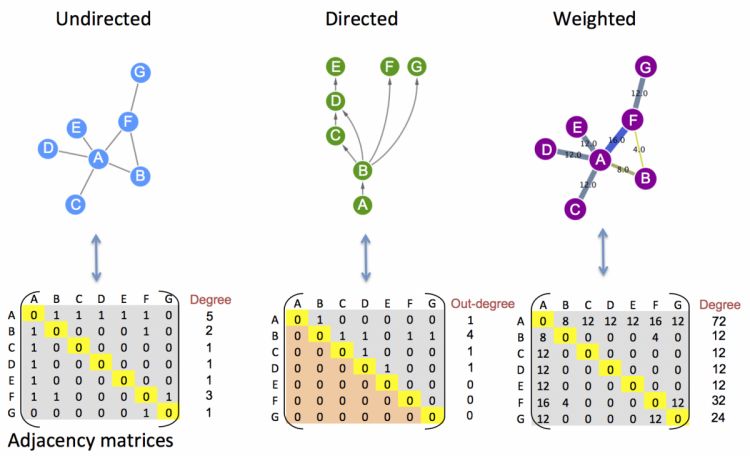
在网络中,根据节点的连线是否具有方向,可以划分为有向图和无向图两类,无向图中被一条线连接的两个节点其作用是相互的,比如基因共表达网络,两个基因间互为共表达基因,而有向图中,连线是有方向性的,比如转录因子调控网络,转录因子调控基因,所以连线由转录因子指向某个基因。
无向图的描述为undirected graph, 有向图的描述为directed graph。PPI网络由于蛋白的作用是相互的,所以通常归类为无向图。
除了连线的方向性,根据连线对应的值,可以将网络图分为加权和非加权两种, 以基因共表达网络为例,非加权图中连线是一个定性描述,两个基因具有共表达的趋势,就可以用连线连接,而加权图是一个定量描述,两个基因间共表达系数的大小对应边的值,在可视化时,值不同,对应边的粗细也不同。
邻接矩阵可以方便的描述任意一种类别的网络,如上图所示,邻接矩阵是一个二维矩阵,而且是一个方阵,行和列代表的都是图中的节点,在非加权图中,0代表两个节点没有连线,1代表两个节点间存在连线;在加权图中,每个单元格数值对应每条边的数值。
对于网络而言,需要了解以下几个基本概念
网络由节点和边构成,对于一个节点而言, 该节点连线的多少,即为该节点的degree, 称之度,对于有向图,根据连线的防线,度又划分为入度和出度, 示意如下
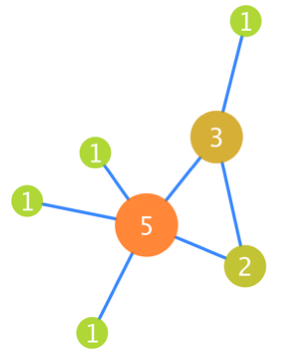
图中每个节点上标记的数字就是该节点的度数。
最短路径表示两个节点间的最短距离,在网络中,从一个节点到另外一个节点,可以有很多个路径,其中经过的节点数最少的称之为最短路径,示意如下
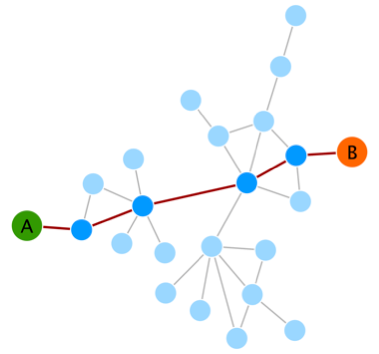
上述到A到B的最短路径为5。
该统计量用来衡量节点的重要程度,基于最短路径进行定义,公式如下
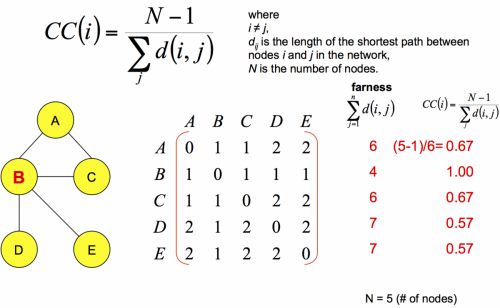
和closeness centrality类似,也是用来表征节点的重要程度,公式如下
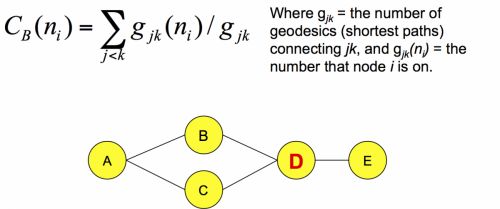
在上图中。删除B和C中的任意一个,A都可以连接到E, 但是删除了D就不行了,所以D就比较重要。
密度代表的是网络中实际的连线数与理论最大连线数的比值,对于包含n个节点的网络,其最大的变数为任意两个节点之间都相连,共 n(n-1)/2, 示意如下

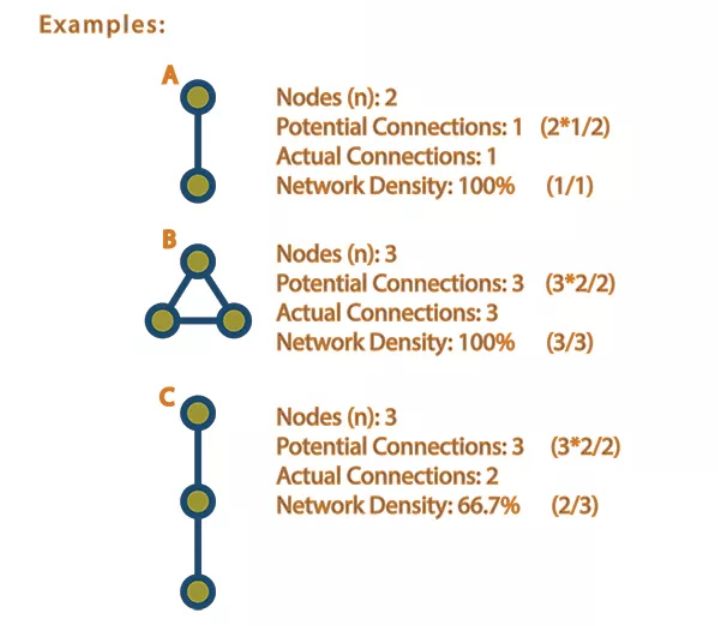
密度用来衡量一个网络的密集程度。
聚集系数,和密度类似,也叫做transitity,有两种定义,第一种称之为local clustering coefficient, 针对单个节点进行定义,对于某个节点而言,该统计量的值为与该节点直接相邻的邻近节点构成的网络的密度,示意如下
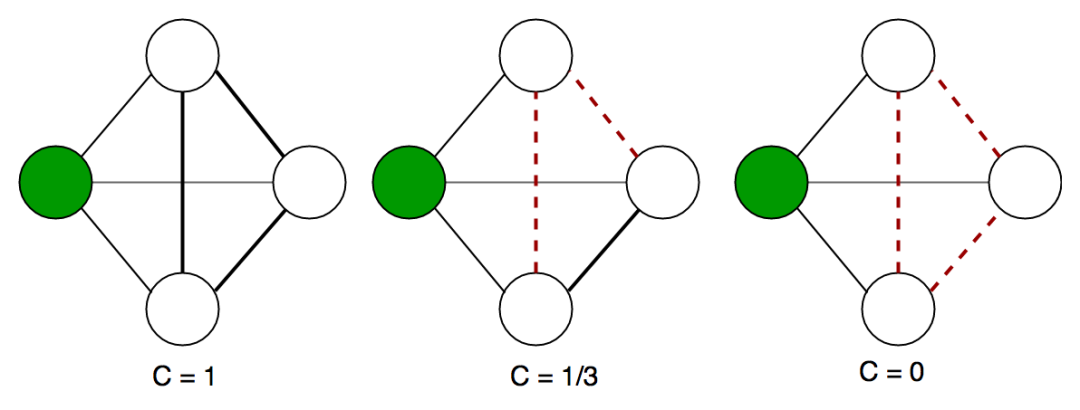
上图中的第一个网络,所有节点构成了一个clique, 即完全连通图,任意两个节点之间都存在了连线,local clustering coefficient 可以看做是衡量邻近节点组成的网络与完全联通图接近的程度,取值范围0到1,越接近于1,越接近一个完全连通图。
在此基础上,针对一个网络,还出现了average clustering coefficient的概念,就是计算每个节点的local clustering coefficient, 然后取平均值,公式如下
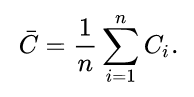
第二种是对于整个网络而言,称之为global clustering coefficient, 这个值的定义是在triangle graph的基础上,triangle graph直译过来就是三角形图,即3个节点构成的网络,示意如下
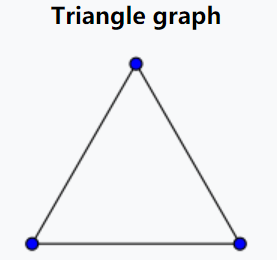
如上图所示,如果三个节点构成的网络是一个闭合的三角形,称之为closed triangle graph, 如果缺失了其中一条边,称之为open triangle graph。
global clustering coefficient 有以下两种定义方式

有文献研究发现真实世界的网络是一个scale-free network, 中文是无标度网络,意思是说在这个网络中,大部分的节点其度数都很低,只有部分节点有用很高的度数,示意如下
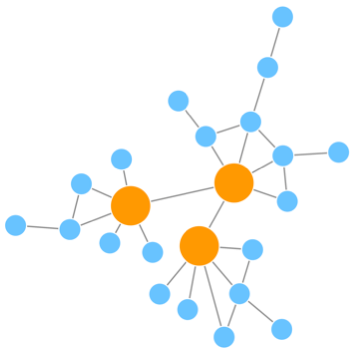
上图中的网络就是一个scale-free network, 只有黄色节点的度数较高,蓝色节点度数很低,在整个网络中,大部分都是蓝色节点,如果绘制该网络的节点度数分布图,应该是如下的一个趋势
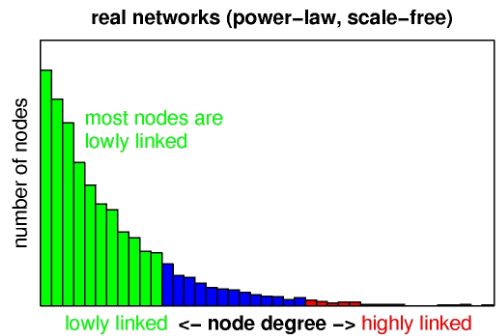
横坐标为度数,纵坐标为为节点数,度数很低的节点占大多数,度数高的节点只是少数,当然这种描述是一种定性描述,为了准确描述,提出了幂律分布的概念,即上述分布图对应的表达式为
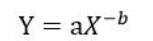
X代表度数,Y代表对应的节点数,有趣的是,将X和Y同时取对数,可以转换为一个线性方程, 推导如下

取对数之后的分布如下
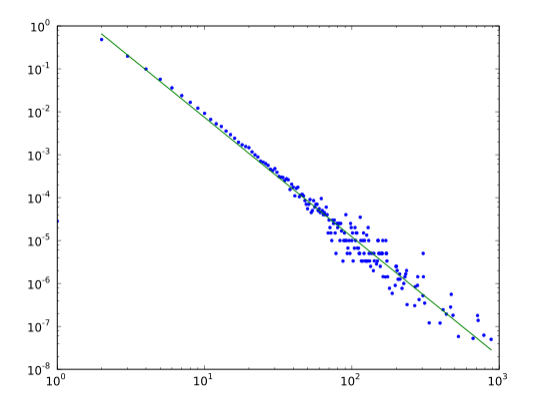
对数转换之后,可以通过线性拟合确定各个系数的值,在之前的WGCNA中,选择最佳的power其实就是这个原理,通过比较不同power值条件下,线性拟合的R2值的大小,选择一个拟合效果最好的值。
在复杂的网络中,会存在部分密度较高的区域,这样的区域称之为community, 也有module等叫法,示意如下
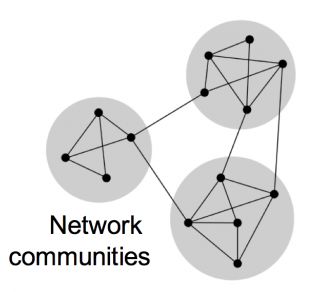
在community内部,连线的密度较高,而区域部分的连线就少。community被认为是具有生物学意义的集合。对于PPI网络而言,其modules通常有以下两种生物学含义
protein complex
蛋白质复合体,由多个蛋白质共同组成复合体,然后发挥生物学作用。
functional module
功能模块,比如位于同一个pathway中的蛋白,其相互作用肯定更加密切。
所以得到网络之后,我们需要去识别communities,目前的有多种算法可用选择,在PPI网络中,常用的有以下算法
MCODE
MCL
Nwewan-Girvan fast greedy algorithm
看完上述内容,你们掌握怎样从PPI网络进一步挖掘信息的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4580290/blog/4620597



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



