MapReduceи®Ўз®—жЎҶжһ¶
2019/2/18 жҳҹжңҹдёҖ
MapReduceи®Ўз®—жЎҶжһ¶
Mapreduce жҳҜдёҖдёӘеҲҶеёғејҸзҡ„иҝҗз®—зј–зЁӢжЎҶжһ¶пјҢж ёеҝғеҠҹиғҪжҳҜе°Ҷз”ЁжҲ·зј–еҶҷзҡ„ж ёеҝғйҖ»иҫ‘д»Јз ҒеҲҶеёғејҸең°
иҝҗиЎҢеңЁдёҖдёӘйӣҶзҫӨзҡ„еҫҲеӨҡжңҚеҠЎеҷЁдёҠпјӣ
дёәд»Җд№ҲиҰҒMAPREDUCE
пјҲ1пјүжө·йҮҸж•°жҚ®еңЁеҚ•жңәдёҠеӨ„зҗҶеӣ дёә硬件иө„жәҗйҷҗеҲ¶пјҢж— жі•иғңд»»пјҢеӣ дёәйңҖиҰҒйҮҮз”ЁеҲҶеёғејҸйӣҶзҫӨзҡ„ж–№ејҸжқҘеӨ„зҗҶгҖӮ
пјҲ2пјүиҖҢдёҖж—Ұе°ҶеҚ•жңәзүҲзЁӢеәҸжү©еұ•еҲ°йӣҶзҫӨжқҘеҲҶеёғејҸиҝҗиЎҢпјҢе°ҶжһҒеӨ§ең°еўһеҠ зЁӢеәҸзҡ„еӨҚжқӮеәҰе’ҢејҖеҸ‘йҡҫеәҰ
пјҲ3пјүеј•е…Ҙmapreduce жЎҶжһ¶еҗҺпјҢејҖеҸ‘дәәе‘ҳеҸҜд»Ҙе°Ҷз»қеӨ§йғЁеҲҶе·ҘдҪңйӣҶдёӯеңЁдёҡеҠЎйҖ»иҫ‘зҡ„ејҖеҸ‘дёҠпјҢиҖҢе°ҶеҲҶеёғејҸи®Ўз®—дёӯзҡ„еӨҚжқӮГ—Г—Г—з”ұжЎҶжһ¶жқҘеӨ„зҗҶ
MAPREDUCE зЁӢеәҸиҝҗиЎҢжј”зӨә
Hadoop зҡ„еҸ‘еёғеҢ…дёӯеҶ…зҪ®дәҶдёҖдёӘhadoop-mapreduce-example-2.4.1.jarпјҢиҝҷдёӘjar еҢ…дёӯжңүеҗ„з§ҚMR
зӨәдҫӢзЁӢеәҸпјҢеҸҜд»ҘйҖҡиҝҮд»ҘдёӢжӯҘйӘӨиҝҗиЎҢпјҡ
еҗҜеҠЁhdfsпјҢyarn
然еҗҺеңЁйӣҶзҫӨдёӯзҡ„д»»ж„ҸдёҖеҸ°жңҚеҠЎеҷЁдёҠжү§иЎҢпјҢпјҲжҜ”еҰӮиҝҗиЎҢwordcountпјүпјҡ
hadoop jar hadoop-mapreduce-example-2.4.1.jar wordcount /wordcount/data /wordcount/out
MapReduceеј•е…Ҙзҡ„й—®йўҳ
1гҖҒеҲҶеҸ‘зЁӢеәҸпјҢ并еҗҜеҠЁеҲҶеҸ‘зҡ„зЁӢеәҸ
2гҖҒдёӯй—ҙж•°жҚ®зҡ„зј“еӯҳе’Ңи°ғеәҰ
3гҖҒд»»еҠЎзӣ‘жҺ§еҸҠеӨұиҙҘеӨ„зҗҶ
MapReduceжЎҶжһ¶иҝҗиЎҢжңәеҲ¶
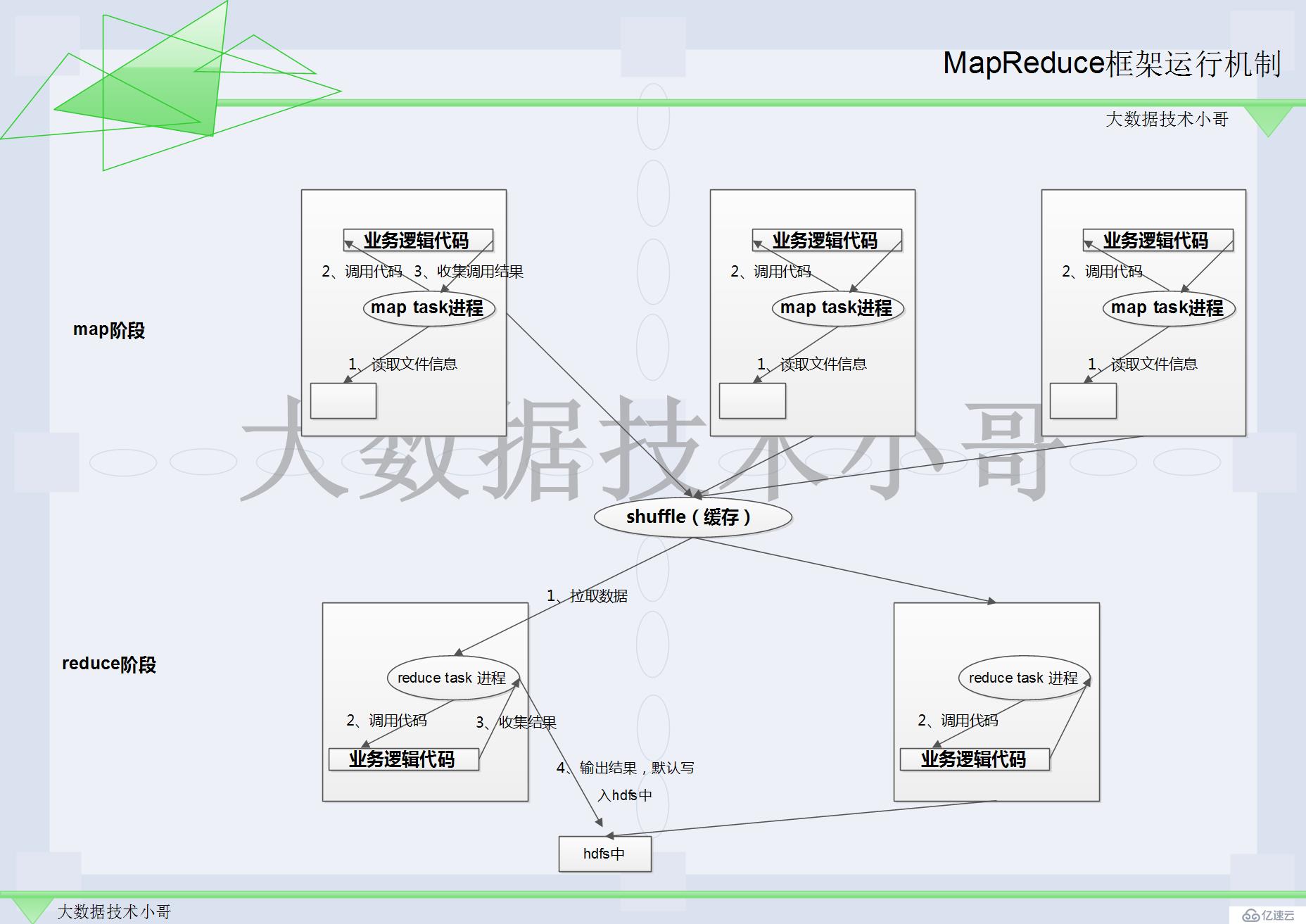
MapReduceеҲҶдёә3дёӘиҝҮзЁӢпјҡ
1гҖҒmap //AиҜ»еҸ–ж–Ү件 Bи°ғз”ЁдёҡеҠЎйҖ»иҫ‘д»Јз ҒпјҲзЁӢеәҸе‘ҳеҸӘе…ізі»иҝҷдёӘйғЁеҲҶпјү C收йӣҶи°ғз”Ёз»“жһң
2гҖҒshuffleжңәеҲ¶ //зј“еӯҳдёҖдёӢ
3гҖҒreduce //AжӢүеҸ–зј“еӯҳдёӯзҡ„ж•°жҚ® Bи°ғз”ЁдёҡеҠЎйҖ»иҫ‘д»Јз ҒпјҲзЁӢеәҸе‘ҳеҸӘе…ізі»иҝҷдёӘйғЁеҲҶпјү C收йӣҶз»“жһңиҫ“еҮәпјҲжңҖз»Ҳз»“жһңпјүй»ҳи®ӨжҠҠжңҖз»Ҳз»“жһңеҶҷеҲ°hdfsдёӯ
MapReduceиҝҗиЎҢжңәеҲ¶зҡ„ж•°жҚ®жөҒзЁӢ
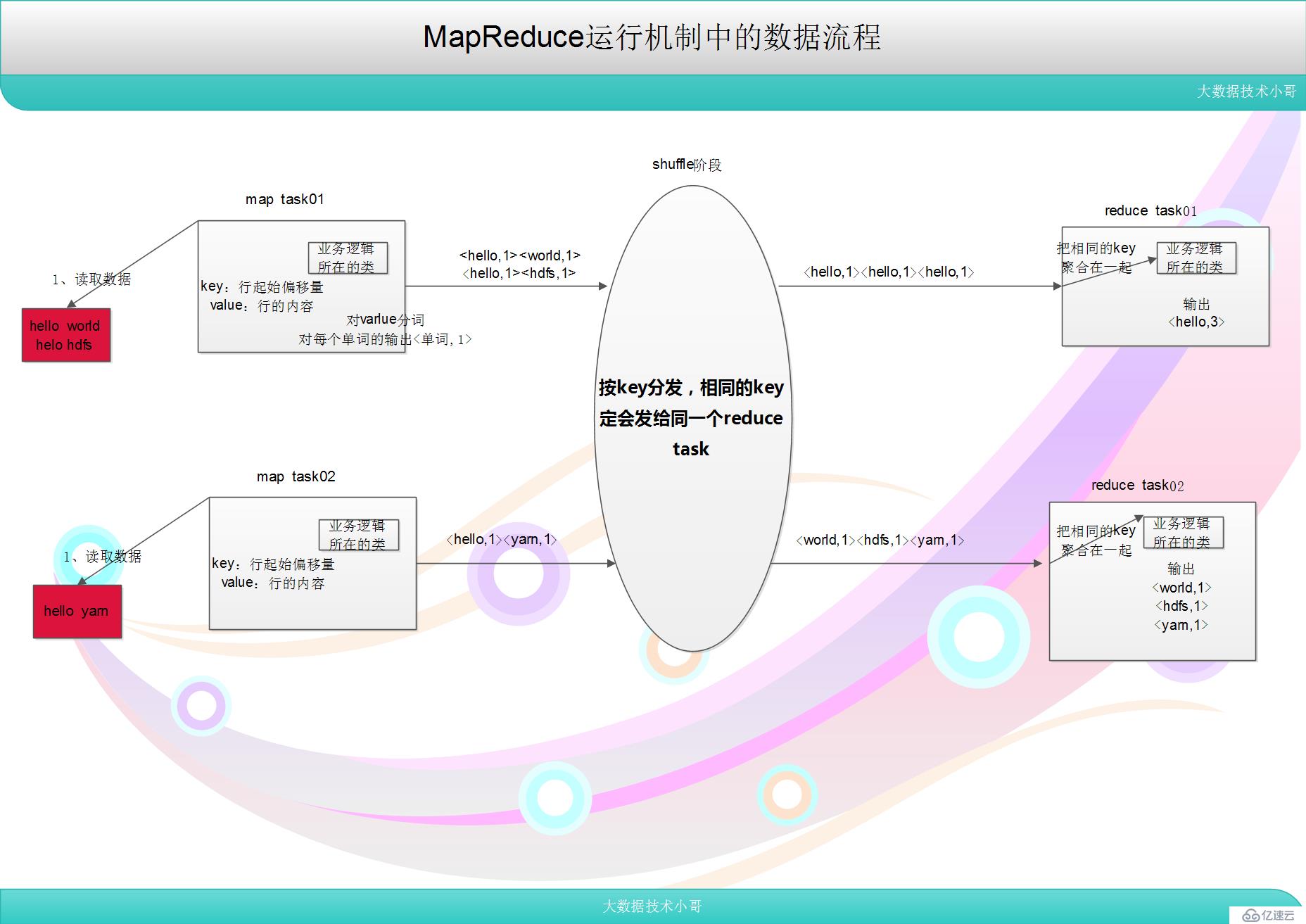
1гҖҒmap //keyпјҡиЎҢиө·е§ӢеҒҸ移йҮҸ valueпјҡиЎҢзҡ„еҶ…е®№
2гҖҒshuffle //жҙ—зүҢ жҢүkeyеҲҶеҸ‘пјҡзӣёеҗҢзҡ„keyзҡ„kvеҝ…е®ҡдјҡеҸ‘з»ҷзӣёеҗҢзҡ„reduce task
3гҖҒreduce //е°Ҷkeyзҡ„еҖјзӣёеҗҢзҡ„ж•ҙеҗҲжҲҗдёҖз»„
mapreduceжЎҶжһ¶дёӯзҡ„shuffleжңәеҲ¶иҜҰи§Ј
Shuffle зј“еӯҳжөҒзЁӢпјҡ
----shuffle жҳҜMR еӨ„зҗҶжөҒзЁӢдёӯзҡ„дёҖдёӘиҝҮзЁӢпјҢе®ғзҡ„жҜҸдёҖдёӘеӨ„зҗҶжӯҘйӘӨжҳҜеҲҶж•ЈеңЁеҗ„дёӘmaptask е’Ңreduce task иҠӮзӮ№дёҠе®ҢжҲҗзҡ„пјҢж•ҙдҪ“жқҘзңӢпјҢеҲҶдёә3 дёӘж“ҚдҪңпјҡ
1гҖҒеҲҶеҢәpartition
2гҖҒSort ж №жҚ®key жҺ’еәҸ
3гҖҒCombiner иҝӣиЎҢеұҖйғЁvalue зҡ„еҗҲ并
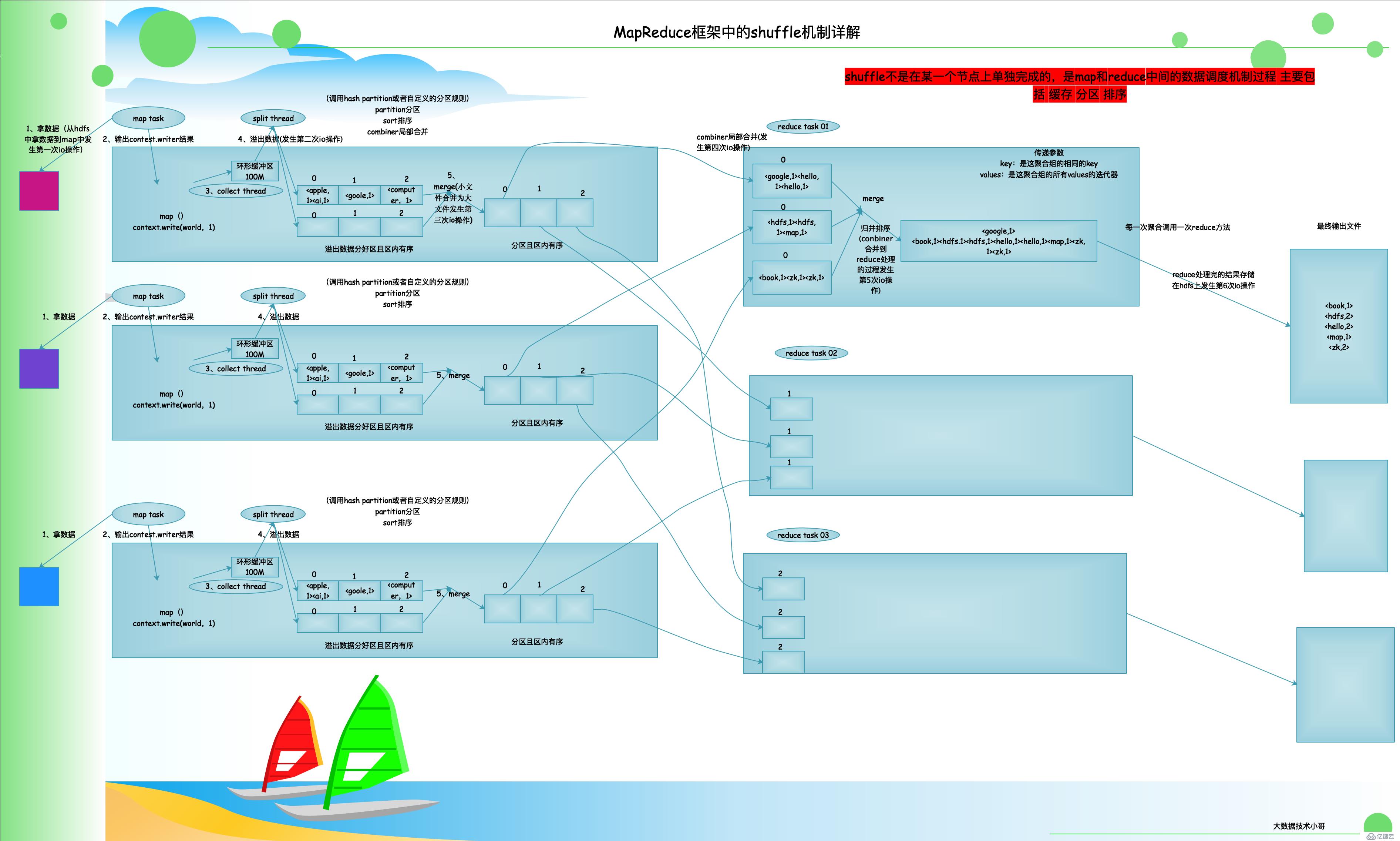
shuffleйҳ¶ж®өж–Үеӯ—иҜҰи§Ј
1гҖҒmapйҳ¶ж®өе…ҲжӢҝж•°жҚ®иҝҮжқҘд№ӢеҗҺпјҢдјҡе…Ҳи°ғз”Ёmapж–№жі•пјҲжҲ‘们иҮӘе®ҡд№үзҡ„пјү
2гҖҒжӢҝеҲ°д№ӢеҗҺпјҢmapдёӯдјҡжңүдёҖдёӘcontext.writeзҡ„иҫ“еҮәз»“жһң mapз«Ҝзҡ„иҫ“еҮәз»“жһңе°ұз»ҷеҲ°дәҶshuffleйҳ¶ж®өдәҶ
3гҖҒеңЁmapз«ҜжңүдёҖдёӘзҺҜеҪўзј“еҶІеҢәпјҲй»ҳи®ӨеҶ…еӯҳеӨ§е°Ҹ100MпјүгҖҗе®һзҺ°зҡ„еҠҹиғҪе°ұжҳҜжҠҠиҝҷдәӣkv收йӣҶиө·жқҘгҖ‘collect thread 收йӣҶзәҝзЁӢ
4гҖҒеңЁдёҚж–ӯиҫ“еҮәпјҢдёҚж–ӯ收йӣҶзҡ„иҝҮзЁӢдёӯзҺҜеҪўзҡ„зј“еӯҳеҢәдјҡдёҚж–ӯзҡ„еҶҷпјҢдјҡеҶҷж»ЎпјҢйӮЈд№ҲеҶ…йғЁзҡ„жңәеҲ¶жҳҜдёҚдјҡи®©д»–еҶҷж»ЎпјҢеҶҷеҲ°80%е°ұдјҡжәўеҮәпјҢиҝҳжҳҜеңЁmapз«ҜдјҡжҠҠжәўеҮәжқҘзҡ„ж•°жҚ®иў« пјҲзәҝзЁӢsplit threadпјүз®ЎзҗҶ еңЁиҝҷйҮҢиҝҳдјҡжҠҠжәўеҮәжқҘзҡ„ж•°жҚ®иҝӣиЎҢpartitionпјҲеҲҶеҢәпјү sortпјҲжҺ’еәҸпјүжҺҘдёӢйҮҢsplit threadдјҡжҠҠжәўеҮәжқҘзҡ„ж•°жҚ®еӯҳж”ҫеҲ°зЈҒзӣҳдёҠйқўгҖҗиҝҷйҮҢеӯҳж”ҫеңЁзЈҒзӣҳдёӯзҡ„ж•°жҚ®жҳҜеҲҶеҘҪеҢә жҺ’еәҸеҘҪдәҶзҡ„гҖ‘гҖӮжәўеҮәж–Ү件еҲҶеҘҪеҢәпјҢдё”еҢәеҶ…жңүеәҸгҖӮ
5гҖҒеңЁmapз«ҜпјҢжңҖеҗҺдёҖж¬ЎпјҢдјҡжҠҠж•°жҚ®е…ЁйғЁзҡ„жәўеҮәжқҘпјҢд№ҹжҳҜеҲҶеҘҪеҢәдё”еҢәеҶ…жңүеәҸзҡ„гҖӮ然еҗҺдјҡеҪўжҲҗеҫҲеӨҡдёҖзі»еҲ—еҲҶеҘҪеҢәзҡ„е°Ҹж–Ү件пјҢжҺҘдёӢжқҘдјҡиҝӣиЎҢmergeпјҲеҗҲ并пјүе°Ҹж–Ү件еҗҲ并еҗҺеҪўжҲҗеӨ§ж–Ү件гҖӮиҝҷз§ҚеҗҲ并жҳҜжҠҠеҲҶеҢәеҶ…зҡ„ж•°жҚ®дёҖдёҖеҜ№еә”зҡ„еҗҲ并 жүҖжңү1еҸ·еҢәеҗҲ并еҪўжҲҗ1еҸ·еҢә ... иҝҷйҮҢеҗҢж ·жҳҜеҲҶеҢәдё”еҢәеҶ…жңүеәҸпјҲиҝҷжҳҜжңҖеҗҺеңЁmapз«ҜеҪўжҲҗзҡ„жңҖеҗҺж–Ү件еҪўејҸпјүгҖӮ
6гҖҒshuffleдёҚжҳҜеңЁжҹҗдёҖдёӘиҠӮзӮ№дёҠе®ҢжҲҗзҡ„гҖӮshuffleжҳҜmapе’Ңreduceдёӯй—ҙзҡ„ж•°жҚ®и°ғеәҰжңәеҲ¶иҝҮзЁӢ дё»иҰҒеҢ…жӢ¬пјҡзј“еӯҳ еҲҶеҢә жҺ’еәҸ
7гҖҒreduce з«Ҝ reduceдё»еҠЁдёӢиҪҪmapз«Ҝзҡ„жңҖеҗҺеҪўжҲҗзҡ„ж–Ү件пјҲе…Ҳдё»еҠЁдёӢиҪҪжүҖжңүmapз«Ҝзҡ„1еҸ·еҢәзҡ„еҶ…е®№пјүгҖӮиҝҷйҮҢ1еҸ·еҢә 2еҸ·еҢә 0еҸ·еҢәдјҡиў«еҲҶеҲ«еңЁдёҚеҗҢзҡ„reduce taskдёӯ
8гҖҒжҺҘдёӢжқҘпјҢдјҡжҠҠд»Һmapз«Ҝзҡ„1еҸ·еҢәдёӯйғҪжӢҝдёӘиҝҮжқҘзҡ„ж•°жҚ®иҝӣиЎҢдёҖж¬Ўreduceз«Ҝзҡ„mergeпјҲеҗҲ并пјү并жҺ’еәҸ //еҪ’并жҺ’еәҸ
9гҖҒжҜҸдёӘиҒҡеҗҲи°ғз”ЁдёҖж¬Ўreduceж–№жі• дј йҖ’зҡ„зҡ„еҸӮж•° keyпјҡжҳҜиҝҷиҒҡеҗҲз»„зҡ„зӣёеҗҢзҡ„keyпјҢvaluesпјҡжҳҜиҝҷдёҖиҒҡеҗҲз»„зҡ„жүҖжңүvalueзҡ„иҝӯд»ЈеҷЁ
//дә§з”ҹиҒҡеҗҲvalues иҝӯд»ЈеҷЁжқҘдј йҖ’з»ҷreduce ж–№жі•пјҢ并жҠҠиҝҷз»„иҒҡеҗҲkvпјҲиҒҡеҗҲзҡ„дҫқжҚ®жҳҜGroupingComparatorпјүдёӯжҺ’еәҸжңҖеүҚзҡ„kv зҡ„key дј з»ҷreduce ж–№жі•зҡ„е…ҘеҸӮkey гҖӮ жңҖз»ҲдјҡеҪўжҲҗдёҖдёӘжңүеәҸзҡ„дё”еҪ’жЎЈзҡ„ж–Ү件
жҸҗзӨә:е…¶д»–зҡ„reduceд№ҹжҳҜеҒҡзӣёеҗҢзҡ„дәӢжғ…пјҢеҸӘдёҚиҝҮе…¶д»–зҡ„reduceжӢҝеҲ°зҡ„ж•°жҚ®еҸҜиғҪжҳҜ1еҸ·еҢә 2еҸ·еҢәзҡ„еҶ…е®№пјҢеӨ„зҗҶзҡ„иҝҮзЁӢеҗҢдёҠгҖӮжҜҸдёӘreduce taskдјҡеҪўжҲҗдёҖдёӘжңҖз»Ҳзҡ„жңүеәҸз»“жһңж–Ү件
10гҖҒreduceз«ҜжңҖеҗҺеҪўжҲҗзҡ„ж–Ү件пјҢеңЁеҶ…йғЁжңүеәҸпјҢдҪҶжҳҜеңЁе…ЁйғЁдёҚдёҖе®ҡжңүеәҸпјҢиҝҷдёӘйңҖиҰҒжҲ‘们зЁӢеәҸеҺ»е№Ійў„ еҰӮжһңжҳҜе…ЁеұҖжҺ’еәҸзҡ„иҜқпјҢйңҖиҰҒеҠ дёҠеҲҶеҢәзҡ„жҺ§еҲ¶пјҢи®©иҝҷдёӘеҲҶеҢәжҢүз…§дёҖе®ҡзҡ„еҢәж®өеҲҶеҢәпјҢжңҖз»ҲеҪўжҲҗreduceзҡ„е…ЁеұҖжңүеәҸгҖӮеңЁжҹҗдёҖдёӘеҲҶз•ҢзӮ№ еүҚйқўзҡ„дёҖдёӘkeyдёҖдёӘеҢәпјҢдёӯй—ҙзҡ„дёҖдёӘkeyдёҖдёӘеҢәпјҢжңҖеҗҺзҡ„keyдёҖдёӘеҢәзӯүгҖӮ
е°Ҹз»“пјҡж•ҙдёӘshuffle зҡ„еӨ§жөҒзЁӢеҰӮдёӢпјҡ
пғј map task иҫ“еҮәз»“жһңеҲ°дёҖдёӘеҶ…еӯҳзј“еӯҳпјҢ并жәўеҮәдёәзЈҒзӣҳж–Ү件
пғј combiner и°ғз”Ё
пғј еҲҶеҢә/жҺ’еәҸ
пғј reduce task жӢүеҸ–map иҫ“еҮәж–Ү件дёӯеҜ№еә”зҡ„еҲҶеҢәж•°жҚ®
пғј reduce з«ҜеҪ’并жҺ’еәҸ
дә§з”ҹиҒҡеҗҲvalues иҝӯд»ЈеҷЁжқҘдј йҖ’з»ҷreduce ж–№жі•пјҢ并жҠҠиҝҷз»„иҒҡеҗҲkvпјҲиҒҡеҗҲзҡ„дҫқжҚ®жҳҜGroupingComparatorпјүдёӯжҺ’еәҸжңҖеүҚзҡ„kv зҡ„key дј з»ҷreduce ж–№жі•зҡ„е…ҘеҸӮkey
shuffleдёҚжҳҜеңЁжҹҗдёҖдёӘиҠӮзӮ№дёҠе®ҢжҲҗзҡ„гҖӮshuffleжҳҜmapе’Ңreduceдёӯй—ҙзҡ„ж•°жҚ®и°ғеәҰжңәеҲ¶иҝҮзЁӢ дё»иҰҒеҢ…жӢ¬пјҡзј“еӯҳ еҲҶеҢә жҺ’еәҸ
еңЁ MapReduceдёӯзҡ„ж•ҙдёӘиҝҮзЁӢдёӯжңү6ж¬ЎжҳҜйңҖиҰҒиҝӣиЎҢioж“ҚдҪңзҡ„пјҢеҲҶеҲ«дёәпјҡ
1гҖҒеңЁз¬¬дёҖж¬ЎжӢҝж•°жҚ®пјҲд»ҺhdfsдёӯжӢҝж•°жҚ®еҲ°mapдёӯеҸ‘з”ҹ第дёҖж¬Ўioж“ҚдҪңпјү
2гҖҒжәўеҮәж•°жҚ®(еҸ‘з”ҹ第дәҢж¬Ўioж“ҚдҪң)
3гҖҒmerge(е°Ҹж–Ү件еҗҲ并дёәеӨ§ж–Ү件еҸ‘з”ҹ第дёүж¬Ўioж“ҚдҪң)
4гҖҒcombinerеұҖйғЁеҗҲ并(еҸ‘з”ҹ第еӣӣж¬Ўioж“ҚдҪң)
5гҖҒеҪ’并жҺ’еәҸ(conbinerеҗҲ并еҲ°reduceеӨ„зҗҶзҡ„иҝҮзЁӢеҸ‘з”ҹ第5ж¬Ўioж“ҚдҪң)
6гҖҒreduceеӨ„зҗҶе®Ңзҡ„з»“жһңеӯҳеӮЁеңЁhdfsдёҠеҸ‘з”ҹ第6ж¬Ўioж“ҚдҪң
иҝҷд№ҹжҳҜMapReduceдёҺsparkеҜ№жҜ”зҡ„жңҖеӨ§зҡ„瓶йўҲ sparkеҸӘжңү еңЁз¬¬дёҖж¬Ўд»ҺhdfsдёҠжӢҝж•°жҚ®еҸ‘з”ҹioж“ҚдҪңпјҢе’ҢеӨ„зҗҶе®Ңд»»еҠЎд№ӢеҗҺпјҢжҠҠж–Ү件еӯҳеӮЁеңЁhdfsдёҠд№ҹеҸ‘з”ҹдёҖж¬Ўioж“ҚдҪңпјҢе…¶дёӯй—ҙзҡ„жүҖжңүзҡ„еӨ„зҗҶиҝҮзЁӢйғҪжҳҜеңЁеҶ…еӯҳдёӯпјҢжүҖжңүдёҚеӯҳеңЁ еӨ§йҮҸзҡ„ioж“ҚдҪңпјҢйҖҹеәҰеҝ«пјҢжүҖжңүsparkдёәдё»жөҒи®Ўз®—еј•ж“ҺгҖӮ





