“个数”是“个推”旗下面向 APP 开发者提供数据统计分析的产品。“个数”通过可视化埋点技术及大数据分析能力从用户属性、渠道质量、行业对比等维度对 APP 进行全面的统计分析。
“个数”不仅可以及时统计用户的活跃、新增等,还可以分析卸载用户的成分、流向,此外还能实现流失、付费等用户关键行为的预测,从而帮助 APP 开发者实现用户精细化运营和全生命周期管理。其中很值得一提的是,“个数”在“可视化埋点”及“行为预测”方面的创新,为 APP 开发者在实际运营中带来了极大便利,所以,在下文中,我们也将围绕这两点做详细的分析。
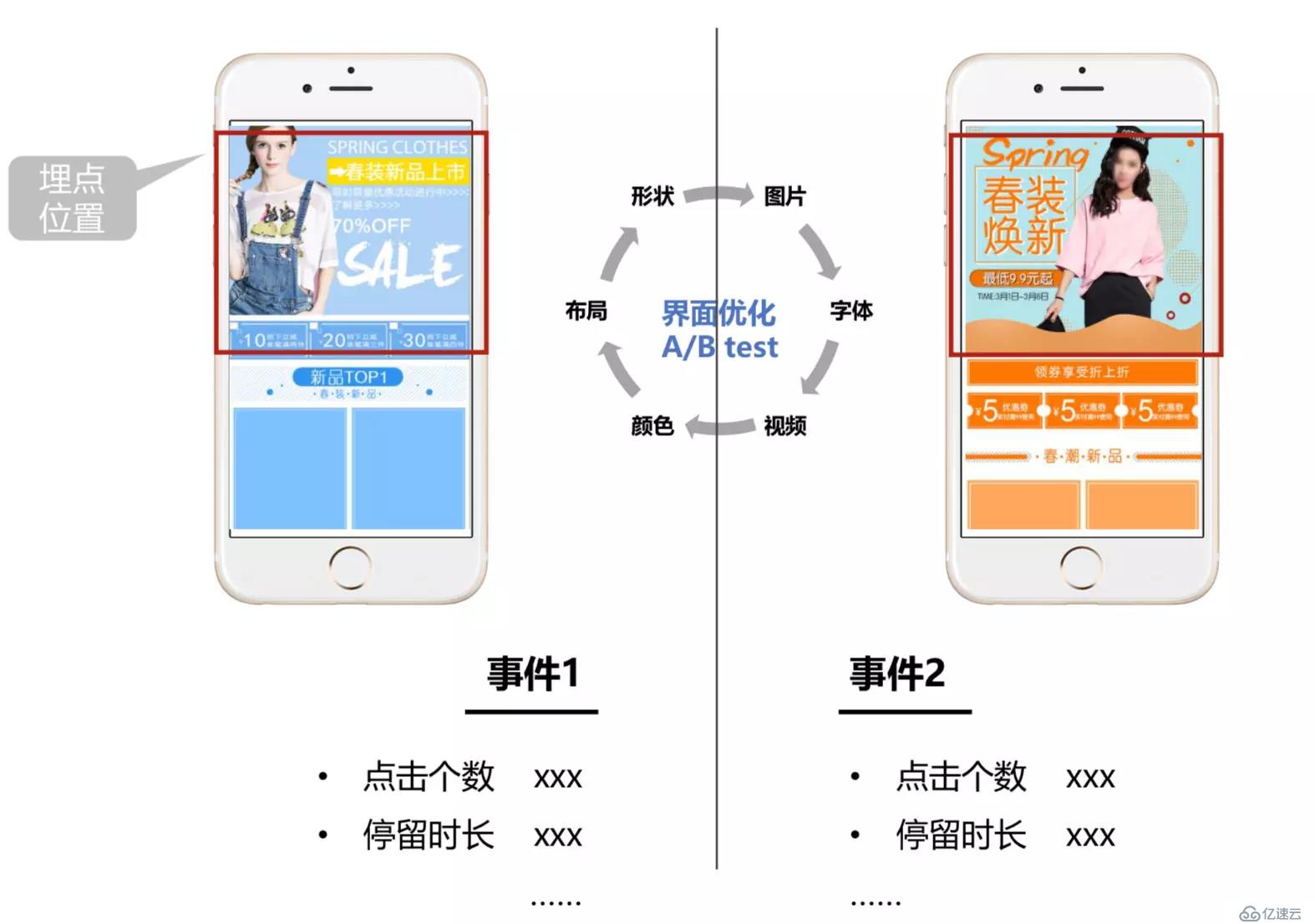
埋点是指在产品流程的关键部位植入相关统计代码,以追踪用户行为,统计关键流程的使用程度,并将数据以日志的方式上报至服务器的过程。
目前,数据埋点采集模式主要有代码埋点、无埋点、可视化埋点等方式。
“代码埋点”是指在监控页面上加入基础 js,根据需求添加监控代码,它的优点是灵活,可以自定义设置,可以选择自己需要的数据来分析,但对复杂网站来说,每次修改一个页面就得重新出一份埋点方案,成本较大。目前,采用这种埋点方案的代表产品有百度统计、友盟、腾讯云分析、Google Analytics 等。
“可视化埋点”通常是指开发者通过设备连接用户行为分析工具,直接在数据接入管理界面上对可交互且交互后有效果的页面元素(如:图片、按钮、链接等)进行操作实现数据埋点,下发采集代码生效回数的埋点方式。目前,可视化埋点的代表产品有个数、Mixpanel、神策数据等。
“无埋点”与“全埋点”相似,它的原理是“全部采集,按需选取”,也就是说它可以对页面中所有交互元素的用户行为进行采集,它是先尽可能多收集检测页面的内容,然后再通过界面配置决定分析哪些数据,但它是标准化采集,如果需要设置自定义的采集方式仍需要代码埋点助力。这种方案的代表产品有 GrowingIO、数极客、百度统计等。
当下移动互联网正处于高速发展且发展形势瞬息万变的阶段中,开发者需要及时根据大数据的分析、反馈,对业务功能等做出调整,在传统的操作模式中,如果想要了解不同节点的数据,就要修改相应代码里面的埋点,然后测试发布,之后再在应用商店审核、上线,整个周期可能长达几个星期,这显然无法满足业务的需求。所以,“个数”采用的“可视化埋点”技术就是为了帮助开发者解决这个问题的。
“个数”的可视化埋点灵活、方便,不需对数据追踪点添加任何代码,使用者只需要通过设备连接管理台,对页面可埋点的元素圈圈点点,即可添加随时生效的界面追踪点,同时在数据采集模式及数据分析能力上,“个数”能够提供给开发者们准确的、有效的数据。
可视化埋点主要具有以下特性:
1、零代码,无需代码,节省成本
2、免更新,新增便捷,无需升级
3、易测试,圈选测试,实时呈现
换而言之,可视化埋点不仅可以节约企业成本,还可以提高开发人员和运营人员的工作效率。
“个数”的行为预测主要包括流失预测、卸载预测、付费预测等,它的原理是基于 App 历史行为数据构建算法模型预测用户关键行为,从而帮助开发者达到用户精细化运营和全生命周期管理的目的。
在这里需要注意的是,“个数”的行为预测与电商平台常用的个性化推荐不同,后者主要是基于用户近期的行为,如浏览记录、购买记录而分析出用户可能需要的东西,而“个数”是基于 App 各渠道卸载数、卸载趋势等指标的综合分析,更多的是对人群的聚类分析,而非仅仅基于个人的行为。
据“个推”大数据科学家朱金星介绍,“个数”的行为预测主要分为以下几个步骤:
1、找样本,主要从历史数据库中抽取;
2、特征抽取,将用户与数据库打通,做匹配;
3、特征筛选,保留相关性高的或有价值的特征;
4、模型训练,将保留下来的特征放到模型中训练,在模型的选用上,“个数”主要用了逻辑回归,逻辑回归的模型相对深度学习等其他模型来说,简单一些,而且在特征筛选上相对好处理,得到的结果好解释,也相对稳定。
5、参数优化,根据效果进行调整,如果结果不理想,即可返回调整参数重新走一次以上流程。
下面我们以付费预测为例,为大家梳理一下具体的实现过程。
个数付费预测的流程主要包括以下几点:
1、目标问题分解
明确需要进行预测的问题即付费预测,以及未来一段时间的跨度。
2、分析样本数据
(1)提取出所有用户的历史付费记录;
(2)分析付费记录,了解付费用户的构成,比如年龄层次、性别、购买力和消费的产品类别等;
(3)提取非付费用户的历史数据,这里可以根据产品的需求,添加条件、或无条件地进行提取,比如提取活跃并且非付费用户,或者不加条件地直接进行提取;
(4)分析非付费用户的构成。
3、构建模型的特征
(1)原始的数据可能能够直接作为特征使用;
(2)有些数据在变换后,才会有更好的使用效果,比如年龄,可以变换成少年、中年、老年等特征;
(3)交叉特征的生成,比如“中年”和“女性”两种特征,就可以合并为一个特征进行使用。
4、计算特征的相关性
(1)计算特征饱和度,进行饱和度过滤;
(2)计算特征 IV、卡方等指标,用以进行特征相关性的过滤。
5、选用逻辑回归进行建模
(1)选择适当的参数进行建模;
(2)模型训练好后,统计模型的精确度、召回率、AUC 等指标,来评价模型;
(3)如果觉得模型的表现可以接受,就可以在验证集上做验证,验证通过后,进行模型保存和预测。
6、预测
加载上述保存的模型,并加载预测数据,进行预测。
7、监控
最后,运营人员还需要对每次预测的结果进行关键指标监控,及时发现并解决出现的问题,防止出现意外情况,导致预测无效或预测结果出现偏差。
其他场景如流失预测、卸载预测等,在流程上与付费预测类似,所以在这里就不再一一介绍了。
有了精准的行为预测,运营者则可以将运营目标进行拆分、细化,具体到每个场景、每个流程,针对不同用户采取不同的推广渠道、运营策略。例如基于流失预测,运营者能够提前洞察到用户流失行为,提早进行干预,通过个性化内容推荐、消息推送等运营手段对即将流失的用户进行挽留,从而降低流失率。总的来说,在大数据行为预测的帮助下,运营者能够更及时、更全面地了解用户,从而达到精细化运营的目的。
接下来“个数”还将在商品推荐等领域做更多的探索,例如开发精准的推荐技术等,也会不断挖掘大数据的潜力,结合反馈的数据做进一步的优化,围绕客户提供的样本数据做更深入的训练学习等,为开发者提供更全面的大数据服务,大家敬请期待。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



