这期内容当中小编将会给大家带来有关spark shuffle如何理解,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
一个spark的RDD有一组固定的分区组成,每个分区有一系列的记录组成。对于由窄依赖变换(例如map和filter)返回的RDD,会延续父RDD的分区信息,以pipeline的形式计算。每个对象仅依赖于父RDD中的单个对象。诸如coalesce之类的操作可能导致任务处理多个输入分区,但转换仍然被认为是窄依赖的,因为一个父RDD的分区只会被一个子RDD分区继承。
Spark还支持宽依赖的转换,例如groupByKey和reduceByKey。在这些依赖项中,计算单个分区中的记录所需的数据可以来自于父数据集的许多分区中。要执行这些转换,具有相同key的所有元组必须最终位于同一分区中,由同一任务处理。为了满足这一要求,Spark产生一个shuffle,它在集群内部传输数据,并产生一个带有一组新分区的新stage。
可以看下面的代码片段:
sc.textFile("someFile.txt").map(mapFunc).flatMap(flatMapFunc).filter(filterFunc).count()
上面的代码片段只有一个action操作,count,从输入textfile到action经过了三个转换操作。这段代码只会在一个stage中运行,因为,三个转换操作没有shuffle,也即是三个转换操作的每个分区都是只依赖于它的父RDD的单个分区。
但是,下面的单词统计就跟上面有很大区别:
val tokenized = sc.textFile(args(0)).flatMap(_.split(' '))
val wordCounts = tokenized.map((_, 1)).reduceByKey(_ + _)
val filtered = wordCounts.filter(_._2 >= 1000)
val charCounts = filtered.flatMap(_._1.toCharArray).map((_, 1)).reduceByKey(_ + _)
charCounts.collect()这段代码里有两个reducebykey操作,三个stage。
下面图更复杂,因为有一个join操作:
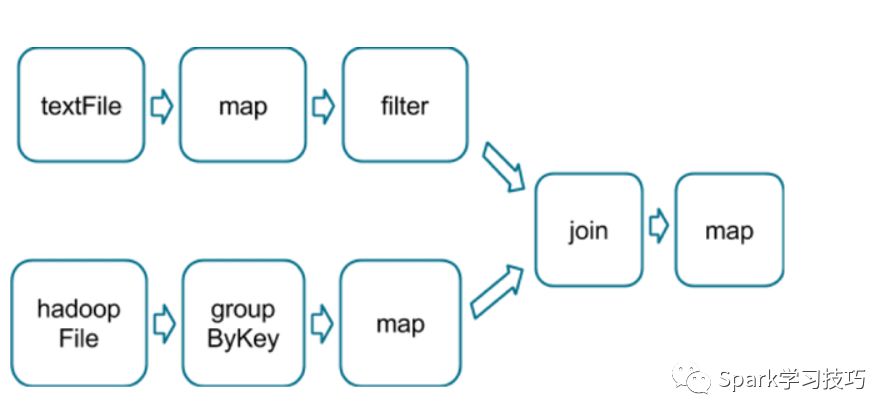
粉框圈住的就是整个DAG的stage划分。
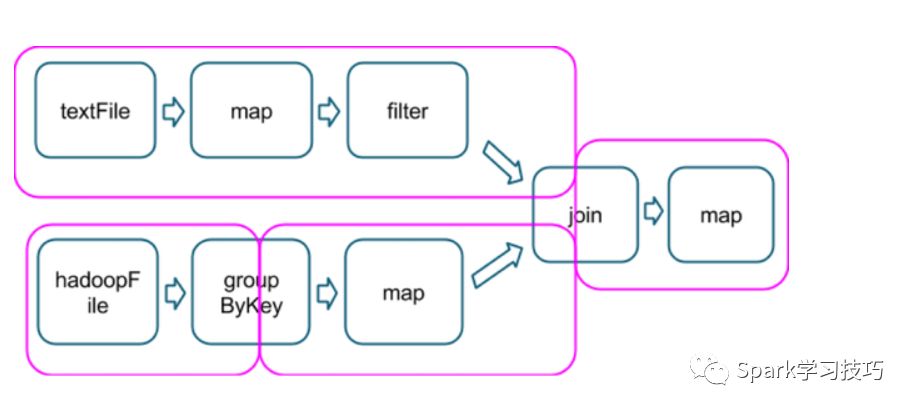
在每个stage的边界,父stage的task会将数据写入磁盘,子stage的task会将数据通过网络读取。由于它们会导致很高的磁盘和网络IO,所以shuffle代价相当高,应该尽量避免。父stage的数据分区往往和子stage的分区数不同。触发shuffle的操作算子往往可以指定分区数的,也即是numPartitions代表下个stage会有多少个分区。就像mr任务中reducer的数据是非常重要的一个参数一样,shuffle的时候指定分区数也将在很大程度上决定一个应用程序的性能。
通常情况可以选择使用产生相同结果的action和transform相互替换。但是并不是产生相同结果的算子就会有相同的性能。通常避免常见的陷阱并选择正确的算子可以显著提高应用程序的性能。
当选择转换操作的时候,应最小化shuffle次数和shuffle的数据量。shuffle是非常消耗性能的操作。所有的shuffle数据都会被写入磁盘,然后通过网络传输。repartition , join, cogroup, 和 *By 或者 *ByKey 类型的操作都会产生shuffle。我们可以对一下几个操作算子进行优化:
1. groupByKey某些情况下可以被reducebykey代替。
2. reduceByKey某些情况下可以被 aggregatebykey代替。
3. flatMap-join-groupBy某些情况下可以被cgroup代替。
在某些情况下,前面描述的转换操作不会导致shuffle。当先前的转换操作已经使用了和shuffle相同的分区器分区数据的时候,spark就不会产生shuffle。
举个例子:
rdd1 = someRdd.reduceByKey(...)
rdd2 = someOtherRdd.reduceByKey(...)
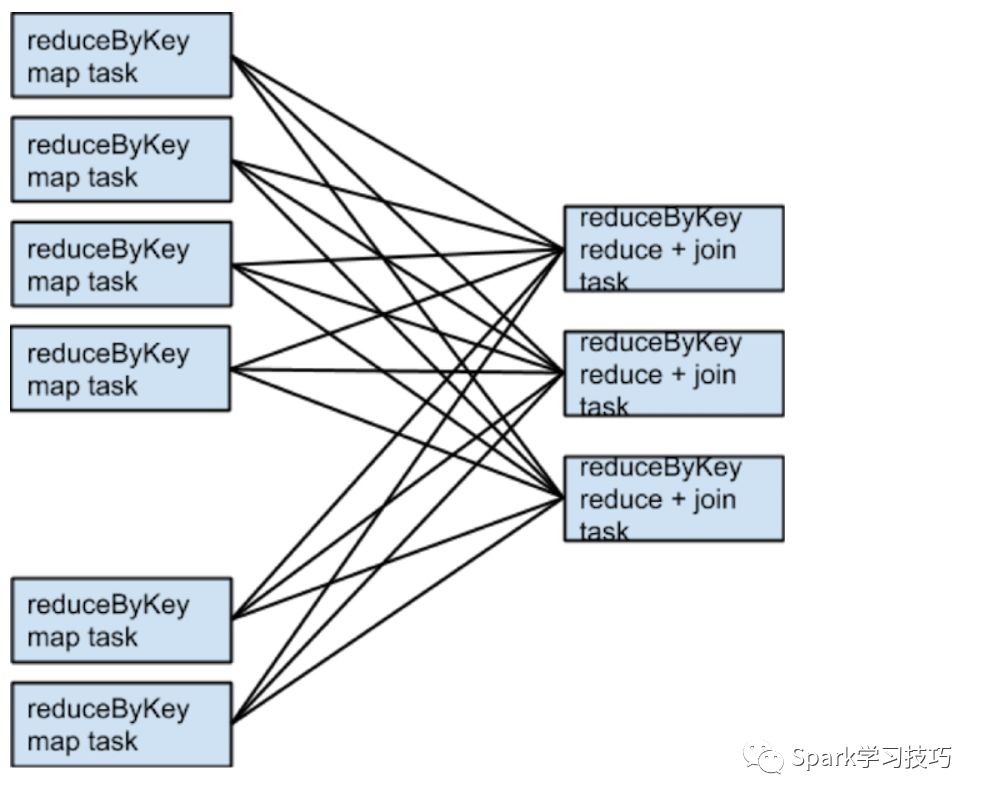
rdd3 = rdd1.join(rdd2)由于使用redcuebykey的时候没有指定分区器,所以都是使用的默认分区器,会导致rdd1和rdd2都采用的是hash分区器。两个reducebykey操作会产生两个shuffle过程。如果,数据集有相同的分区数,执行join操作的时候就不需要进行额外的shuffle。由于数据集的分区相同,因此rdd1的任何单个分区中的key集合只能出现在rdd2的单个分区中。 因此,rdd3的任何单个输出分区的内容仅取决于rdd1中单个分区的内容和rdd2中的单个分区,并且不需要第三个shuffle。
例如,如果someRdd有四个分区,someOtherRdd有两个分区,而reduceByKeys都使用三个分区,运行的任务集如下所示:
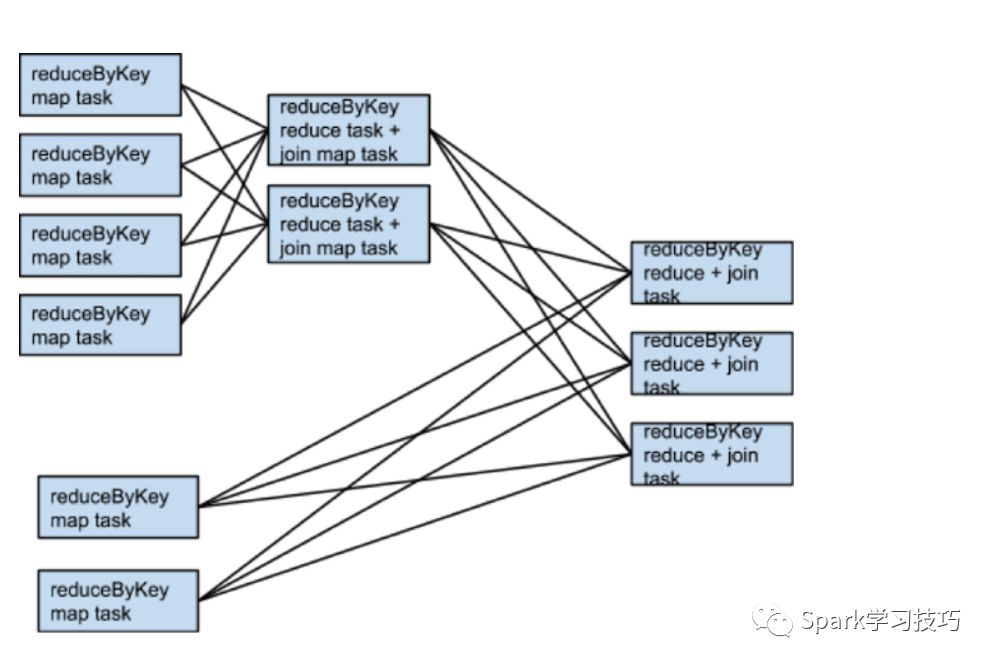
如果rdd1和rdd2使用不同的分区器或者相同的分区器不同的分区数,仅仅一个数据集在join的过程中需要重新shuffle
在join的过程中为了避免shuffle,可以使用广播变量。当executor内存可以存储数据集,在driver端可以将其加载到一个hash表中,然后广播到executor。然后,map转换可以引用哈希表来执行查找。
有时候需要打破最小化shuffle次数的规则。
当增加并行度的时候,额外的shuffle是有利的。例如,数据中有一些文件是不可分割的,那么该大文件对应的分区就会有大量的记录,而不是说将数据分散到尽可能多的分区内部来使用所有已经申请cpu。在这种情况下,使用reparition重新产生更多的分区数,以满足后面转换算子所需的并行度,这会提升很大性能。
使用reduce和aggregate操作将数据聚合到driver端,也是修改区数的很好的例子。
在对大量分区执行聚合的时候,在driver的单线程中聚合会成为瓶颈。要减driver的负载,可以首先使用reducebykey或者aggregatebykey执行一轮分布式聚合,同时将结果数据集分区数减少。实际思路是首先在每个分区内部进行初步聚合,同时减少分区数,然后再将聚合的结果发到driver端实现最终聚合。典型的操作是treeReduce 和 treeAggregate。
当聚合已经按照key进行分组时,此方法特别适用。例如,假如一个程序计算语料库中每个单词出现的次数,并将结果使用map返回到driver。一种方法是可以使用聚合操作完成在每个分区计算局部map,然后在driver中合并map。可以用aggregateByKey以完全分布的方式进行统计,然后简单的用collectAsMap将结果返回到driver。
上述就是小编为大家分享的spark shuffle如何理解了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





