电商大数据项目-推荐系统实战(一)环境搭建以及日志,人口,商品分析
https://blog.51cto.com/6989066/2325073
电商大数据项目-推荐系统实战之推荐算法
https://blog.51cto.com/6989066/2326209
电商大数据项目-推荐系统实战之实时分析以及离线分析
https://blog.51cto.com/6989066/2326214
(七)推荐系统常用算法
协同过滤算法
协同过滤算法(Collaborative Filtering:CF)是很常用的一种算法,在很多电商网站上都有用到。CF算法包括基于用户的CF(User-based CF)和基于物品的CF(Item-based CF)。
(八)Apache Mahout和Spark MLLib
① Apache Mahout简介
Apache Mahout是Apache Software Foundation (ASF)旗下的一个开源项目,提供了一些经典的机器学习的算法,皆在帮助开发人员更加方便快捷地创建智能应用程序。目前已经有了三个公共发型版本,通过ApacheMahout库,Mahout可以有效地扩展到云中。Mahout包括许多实现,包括聚类、分类、推荐引擎、频繁子项挖掘。
Apache Mahout的主要目标是建立可伸缩的机器学习算法。这种可伸缩性是针对大规模的数据集而言的。Apache Mahout的算法运行在ApacheHadoop平台下,他通过Mapreduce模式实现。但是,Apache Mahout并非严格要求算法的实现基于Hadoop平台,单个节点或非Hadoop平台也可以。Apache Mahout核心库的非分布式算法也具有良好的性能。
Mahout主要包含以下5部分
频繁挖掘模式:挖掘数据中频繁出现的项集。
聚类:将诸如文本、文档之类的数据分成局部相关的组。
分类:利用已经存在的分类文档训练分类器,对未分类的文档进行分类。
推荐引擎(协同过滤):获得用户的行为并从中发现用户可能喜欢的事物。
频繁子项挖掘:利用一个项集(查询记录或购物记录)去识别经常一起出现的项目。
② Spark MLLib简介
Spark MLlib(Machine Learnig lib) 是Spark对常用的机器学习算法的实现库,同时包括相关的测试和数据生成器。Spark的设计初衷就是为了支持一些迭代的Job, 这正好符合很多机器学习算法的特点。
Spark MLlib目前支持4种常见的机器学习问题: 分类、回归、聚类和协同过滤。Spark MLlib基于RDD,天生就可以与Spark SQL、GraphX、Spark Streaming无缝集成,以RDD为基石,4个子框架可联手构建大数据计算中心!
下图是MLlib算法库的核心内容:
九、基于用户兴趣的商品推荐
(一)基于用户的CF(User CF)和基于物品的CF(Item CF)
基于用户的CF(User CF)
基于用户的 CF 的基本思想相当简单,基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。计算上,就是将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到 K 邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。图 2 给出了一个例子,对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居 - 用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。
基于物品的CF(Item CF)
基于物品的 CF 的原理和基于用户的 CF 类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。从计算的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。图 3 给出了一个例子,对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户 C 可能也喜欢物品 C。
十、基于ALS协同过滤推荐
一)ALS的基本原理
(二)基于Spark MLLib的ALS
基本的过程是:
a.加载数据到rating RDD中
b.使用rating RDD训练ALS模型
c.使用ALS模型为用户进行物品推荐,将结果打印
d.评估模型的均方差
(三)基于Apache Mahout的ALS
1.将rating分为预测集(10%)和训练集(90%)
bin/mahout splitDataset -i /input/ratingdata.txt -o /output/ALS/dataset
2.使用并行ALS算法,对训练集来矩阵进行分解,之后会在/output/ALS/out生成两个矩阵U(用户特征矩阵)和M(物品特征矩阵),以及评分
bin/mahout parallelALS -i /output/ALS/dataset/trainingSet/ -o /output/ALS/out --numFeatures 20 --numIterations 5 --lambda 0.1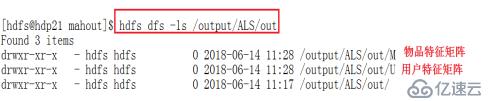
3.通过预测集来对模型进行评价,评价标准是RMSE。RMSE结果会输出在/output/ALS/rmse/rmse.txt
bin/mahout evaluateFactorization -i /output/ALS/dataset/probeSet/ -o /output/ALS/rmse --userFeatures /output/ALS/out/U --itemFeatures output/ALS/out/M
4.最后进行推荐
bin/mahout recommendfactorized -i /output/ALS/out/userRatings -o /output/ALS/recommendations --userFeatures /output/ALS/out/U --itemFeatures output/ALS/out/M --numRecommendations 6 --maxRating 5
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



