这篇文章主要为大家展示了“dbCoRC数据库怎么用”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“dbCoRC数据库怎么用”这篇文章吧。
在人和小鼠中,已经识别到的转录因子有几百种之多。众所众知,转录因子的调控作用是具有细胞或者组织特异性的,在某种特定的组织或细胞中,发挥调控功能的只是一小部分转录因子。
科学家通过研究发现,即使是在特定的细胞或组织中,发挥作用的转录因子在调控网络中的地位也是不同的。其中有一部分转录因子被称之为核心转录因子,这部分转录因子不仅仅可以调节自身的靶基因,而且可以相互调节,从而构成一条交叉调节的回路,最典型的就是胚胎干细胞中,NANOG,SOX2,POU5F1/OCT4 这几种转录因子构成的调控回路。
将某种细胞或者组织中的核心转录因子及其调控回路称之为core transcription regulatory circuitry, 简称CRC。超级增强子SE区域内包含许多转录因子结合位点,有科学家发明了CRC Mapper这种算法,通过超级增强子关联的转录因子来识别细胞或组织中的CRC。
dbCoRC是一个核心启动因子数据库,通过超级增强子关联的转录因子来鉴定不同组织或者细胞中的CRC。以H3K27ac作为增强子的mark, 从GEO数据库中下载chip_seq原始数据,首先通过MACS软件识别增强子区,然后通过ROSE软件识别超级增强子。
识别到超级增强子之后,首先利用TRANSFAC/MEME数据库下载转录因子motif信息,通过FIMO软件进行motif scan分析,在超级增强子区域内寻找转录因子结结合位点。利用这种策略寻找超级增强子想关联的转录因子,在此基础上识别CRC, 完整的pipieline如下图所示
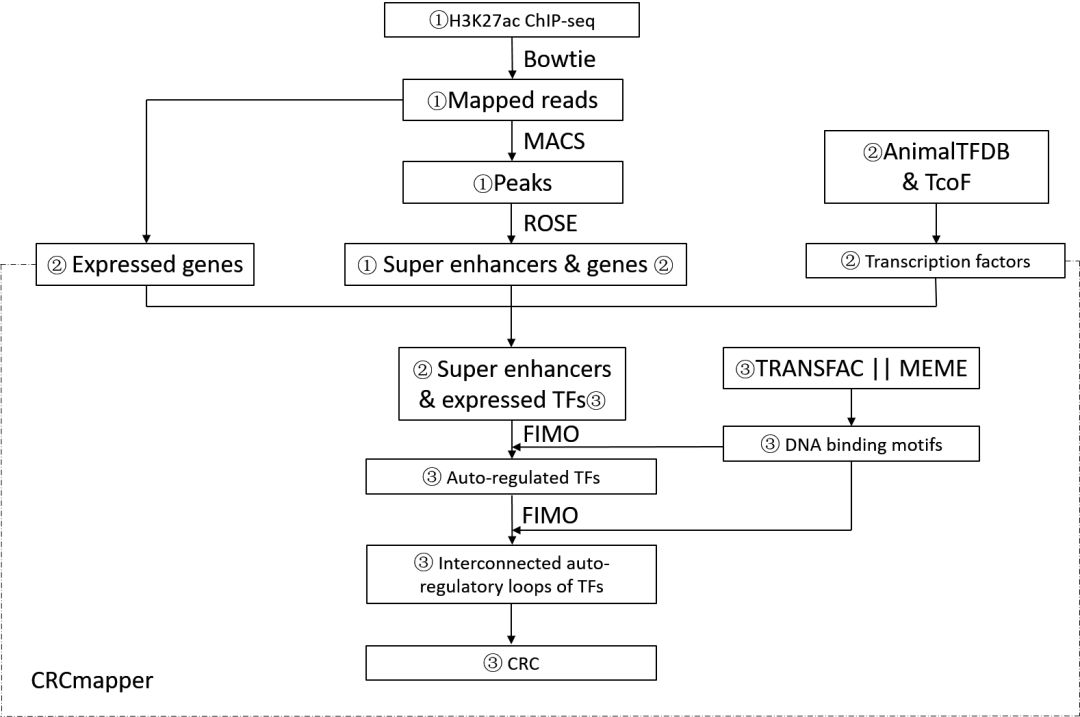
对应的文章发表在Nucleic Acids Research上,链接如下
https://academic.oup.com/nar/article/46/D1/D71/4103600
数据库的网址如下
http://dbcorc.cam-su.org/
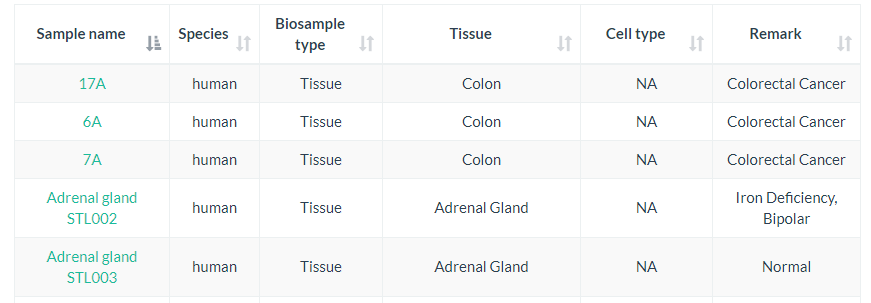
通过Browser菜单,可以浏览每个样本中的CRC信息,示意如下
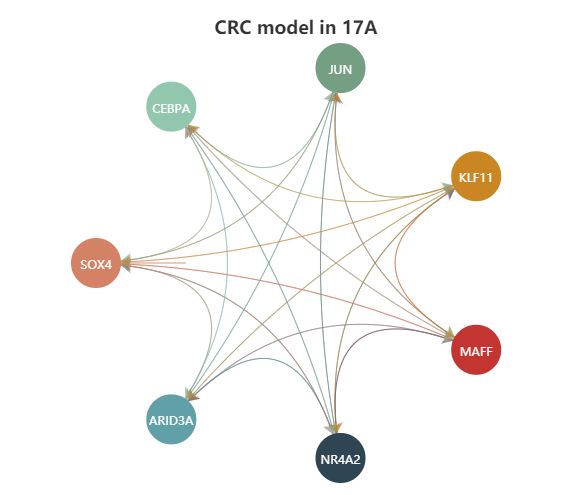
点击样本名称,可以查看详细信息,首先是给样本中的核心转录因子构成的调控网络,示意如下
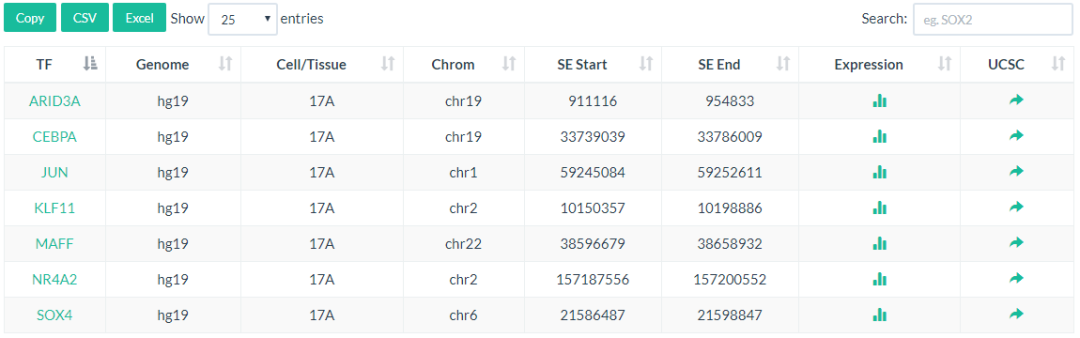
其次是核心转录因子对应的超级增强子区域,示意如下
点击转录因子的ID, 可以查看该转因子在其他转录因子SE区域的结合位点,示意如下
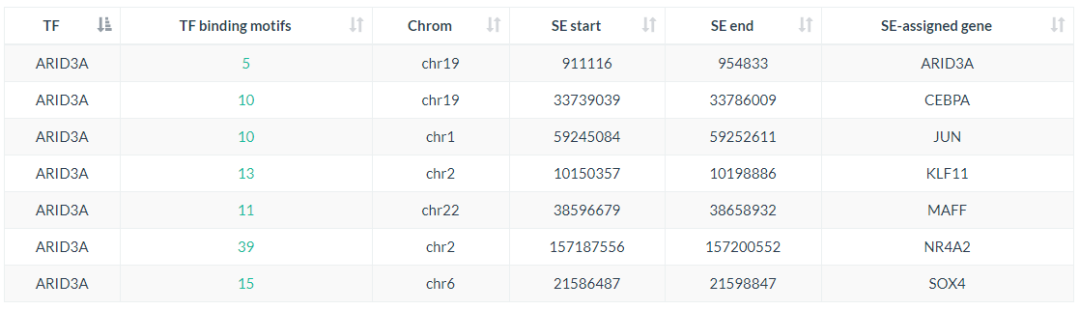
同时还提供了该转录因子在TCGA等不同数据库中的表达量信息,示意如下
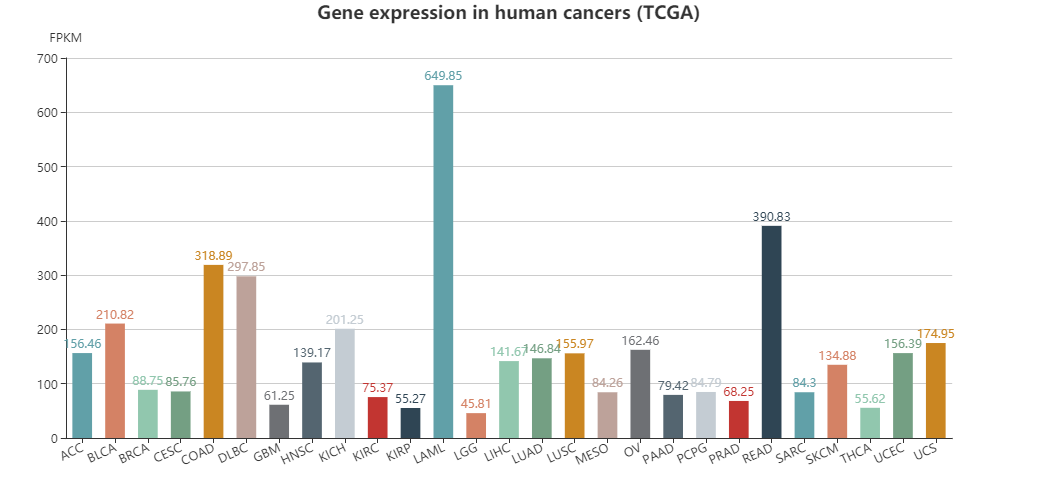
dbCoRC侧重于分析超级增强子区域关联的转录因子间的调控关系,如果只是单纯的分析超级增强子,更加推荐SEdb数据库。
以上是“dbCoRC数据库怎么用”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4580290/blog/4570644



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



