这篇文章主要介绍了Sklearn广义线性模型实例分析的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇Sklearn广义线性模型实例分析文章都会有所收获,下面我们一起来看看吧。
广义线性模型:主要讲述一些用于回归的方法,其中目标值y是输入变量x的线性组合。数据概念表示为:如果y(w,x)=w0+w1x1+...+wpxp,在整个模块中,我们定义向量w=(w1,...,wp)作为coef_,定义w0作为intercept_。
1.1.1.普通最小二乘法
LinearRegression拟合一个带有系数w=(w1,...,wp)的线性模型,使得数据集实际观测数据和预测数据(估计值)之间的残差平方和最小。其数学表达式为:
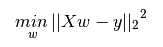
LinearRegression会调用fit方法来拟合数组 X,y,并且将线性模型的系数w存储在其成员变量coef_中:
>>> from sklearn import linear_model
>>> reg = linear_model.LinearRegression()
>>> reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
>>> reg.coef_
array([ 0.5, 0.5])
然而,对于普通最小二乘的系数估计问题,其依赖于模型各项的相互独立性。当各项是相关的,且设计矩阵X的各列近似线性相关,那么,设计矩阵会趋向于奇异矩阵,这种特性导致最小二乘估计对于随机误差非常敏感,可能产生很大的方差。例如,在没有实验设计的情况下收集到的数据,这种多重共线性(multicollinearity)的情况可能真的会出现。
线性回归示例:
本示例仅使用糖尿病数据集的第一个特征,以说明此回归技术的二维图。 可以在图中看到直线,该直线显示了线性回归如何尝试绘制一条直线,该直线将最大程度地减少数据集中观察到的响应与线性近似预测的响应之间的残差平方和。还计算输出了系数,残差平方和和方差得分。
import matplotlib.pyplot as pltimport numpy as npfrom sklearn import datasets, linear_modelfrom sklearn.metrics import mean_squared_error, r2_scoreimport pandas as pd#加载数据diabetes = datasets.load_diabetes()# 取一个特征列维度diabetes_X = diabetes.data[:, np.newaxis, 2]#np.newaxis将矩阵转换成一列# 划分训练和测试数据集diabetes_X_train = diabetes_X[:-20]diabetes_X_test = diabetes_X[-20:]# 划分训练和测试目标集diabetes_y_train = diabetes.target[:-20]diabetes_y_test = diabetes.target[-20:]# 创建线性回归模型regr = linear_model.LinearRegression()# 使用数据集训练模型regr.fit(diabetes_X_train, diabetes_y_train)# 使用测试集训练函数diabetes_y_pred = regr.predict(diabetes_X_test)# 系数print('Coefficients: \n', regr.coef_)# 平均误差print("Mean squared error: %.2f"% mean_squared_error(diabetes_y_test, diabetes_y_pred))# 变量预测分数print('Variance score: %.2f' % r2_score(diabetes_y_test, diabetes_y_pred))# 可视化输出plt.scatter(diabetes_X_test, diabetes_y_test, color='black')plt.plot(diabetes_X_test, diabetes_y_pred, color='red', linewidth=3)#横纵坐标plt.xticks(())plt.yticks(())plt.show()
输出:
Coefficients:
[938.23786125]
Mean squared error: 2548.07
Variance score: 0.47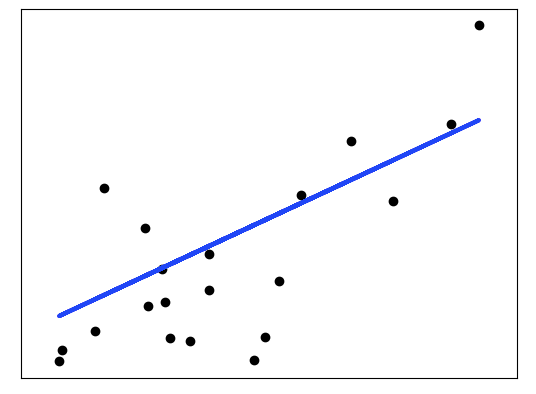
关于“Sklearn广义线性模型实例分析”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“Sklearn广义线性模型实例分析”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





