本篇内容介绍了“非层次聚类k-means怎么使用”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
非层次聚类
非层次聚类(non- hierarchical clustering)是对一组对象进行简单分组的方法,其分类依据是尽量使得组内对象之间比组间对象之间的相似度更高,在分析之前需要预设小组的数目。非层次聚类需要首先有个预设的结构,比如假设有k个类群,那么将所有对象任意分为k组,然后在这个基础上不断进行替换迭代,来达到最优化的分组结果。
k-均值(k-means)算法是一种迭代求解的线性聚类算法,它需要给定起始的聚类簇数目,根据给定的聚类簇数目随机选取相同数目的对象作为初始聚类中心,根据所有对象与聚类中心的距离来划分聚类簇,直到所有对象划分完毕,然后根据目前归类情况计算目标函数值:
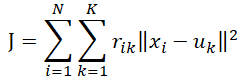
其中N为对象总数,K为给定的聚类簇数目,rik表示当样本xi划为聚类簇k时为1,否则为0,首次聚类uk为初始聚类中心坐标,初次迭代完则选择每个聚类簇坐标的均值作为下一次的聚类中心,这也是k-均值得名的由来。可以看出,这个公式实际上反映的是所有聚类簇的组内方差,组内方差总和越小,划分越理想。因此,k-means不断迭代上面过程,来最小化组内总方差。整个过程就是通过识别对象的高密度区域来建立分类。
#读取数据data=read.table(file="otu_table.txt", header=TRUE, check.names=FALSE)rownames(data)=data[, 1]data=as.matrix(data[, -1])#将每个样品的物种数据进行总和标准化(即求相对丰度)library(vegan)data=decostand(data, MARGIN=2, "total")*100otu=t(data)#层次聚类otu_dist=vegdist(otu, method="euclidean", diag=TRUE, upper=TRUE, p=2)hcl=hclust(otu_dist, method="ward.D")cluster1=cutree(hcl, 5)#k-means聚类,centers为预设聚类簇数目,nstart为迭代次数kms=kmeans(otu, centers=5, nstart=100)cluster2=kms$clustertable(cluster1, cluster2)
结果如下所示:
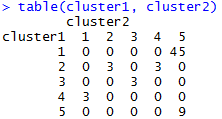
可以看出两种聚类其结果并不相同,其中只有两组是完全相同的。一般来说,k-means不适合含有很多0值的原始数据聚类。由于k-means只能对原始数据进行聚类,要想使用其他距离(bray-curtis等),只有将原始数据计算距离矩阵进行PCoA分析,然后根据提取的主坐标进行k-means聚类。
#筛选最佳聚类簇数目multikms=cascadeKM(otu, inf.gr=2, sup.gr=22, iter=100, criterion="ssi")plot(multikms, sortg=TRUE)
上例中聚类簇数目从2到22,sortg=TRUE表示根据聚类结果重排样品的顺序。"ssi"为简单结构指数(simplestructrre index),用于评价聚类结果的好坏,一般聚类簇数目越多,结构越复杂,则ssi指数越高。也可以选择"calinski"也即Calinski-Harabasz指数,该指数一般随着聚类簇数目增加而降低,其值越大表明聚类结果越好。分析结果如下所示:
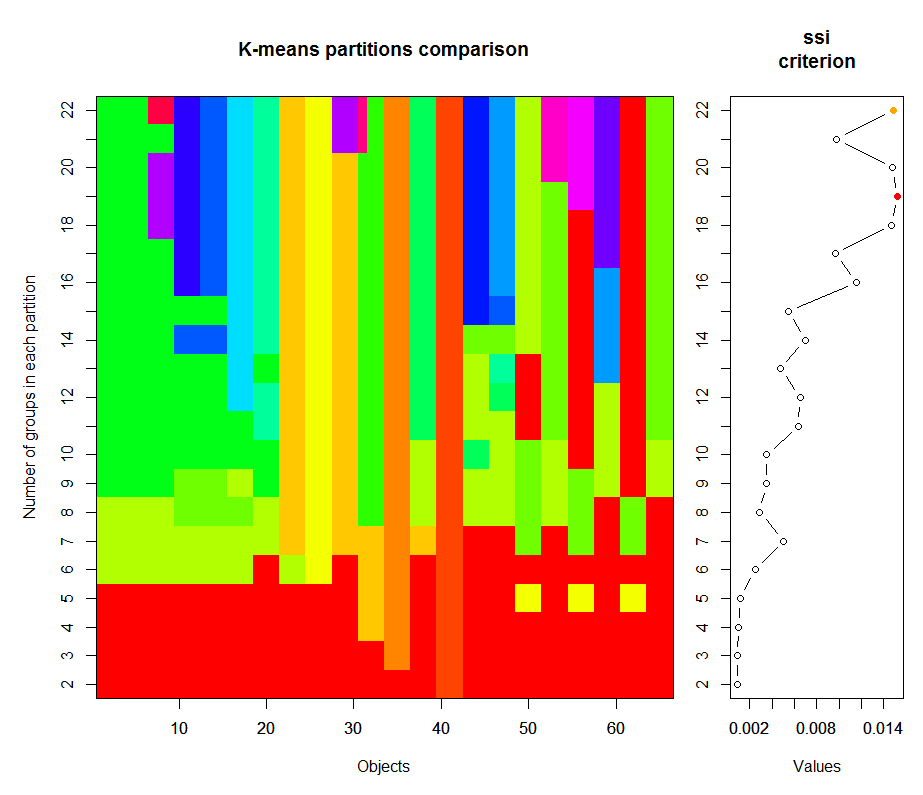
我们所使用数据中一共66个样品,其中左边彩图展示了每个对象(也即样品)在不同分类水平下的小组归属,每一行不同颜色的数目即分类簇的数目。右图为每一个分类水平下终止分类(也即迭代结束)时的统计量,这里以ssi值表示。由此我们可以看出,与层次聚类不同的是,非层次聚类不同聚类水平均是独立运行的。
“非层次聚类k-means怎么使用”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





