这篇文章主要讲解了“Spark Streaming编程方法是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Spark Streaming编程方法是什么”吧!
上一篇文章中介绍了常见的无状态的转换操作,比如在WordCount的例子中,输出的结果只与当前batch interval的数据有关,不会依赖于上一个batch interval的计算结果。spark Streaming也提供了有状态的操作:updateStateByKey,该算子会维护一个状态,同时进行信息更新 。该操作会读取上一个batch interval的计算结果,然后将其结果作用到当前的batch interval数据统计中。其源码如下:
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S]
): DStream[(K, S)] = ssc.withScope {
updateStateByKey(updateFunc, defaultPartitioner())
}
该算子只能在key–value对的DStream上使用,需要接收一个状态更新函数 updateFunc作为参数。使用案例如下:
object StateWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName(StateWordCount.getClass.getSimpleName)
val ssc = new StreamingContext(conf, Seconds(5))
// 必须开启checkpoint,否则会报错
ssc.checkpoint("file:///e:/checkpoint")
val lines = ssc.socketTextStream("localhost", 9999)
// 状态更新函数
def updateFunc(newValues: Seq[Int], stateValue: Option[Int]): Option[Int] = {
var oldvalue = stateValue.getOrElse(0) // 获取状态值
// 遍历当前数据,并更新状态
for (newValue <- newValues) {
oldvalue += newValue
}
// 返回最新的状态
Option(oldvalue)
}
val count = lines.flatMap(_.split(" "))
.map(w => (w, 1))
.updateStateByKey(updateFunc)
count.print()
ssc.start()
ssc.awaitTermination()
}
}
尖叫提示:上面的代码必须要开启checkpoint,否则会报错:
Exception in thread "main" java.lang.IllegalArgumentException: requirement failed: The checkpoint directory has not been set. Please set it by StreamingContext.checkpoint()
运行上面的代码会发现一个现象:即便没有数据源输入,Spark也会为新的batch interval更新状态,即如果没有数据源输入,则会不断地输出之前的计算状态结果。
updateStateByKey可以在指定的批次间隔内返回之前的全部历史数据,包括新增的,改变的和没有改变的。由于updateStateByKey在使用的时候一定要做checkpoint,当数据量过大的时候,checkpoint会占据庞大的数据量,会影响性能,效率不高。
mapwithState是Spark提供的另外一个有状态的算子,该操作克服了updateStateByKey的缺点,从Spark 1.5开始引入。源码如下:
def mapWithState[StateType: ClassTag, MappedType: ClassTag](
spec: StateSpec[K, V, StateType, MappedType]
): MapWithStateDStream[K, V, StateType, MappedType] = {
new MapWithStateDStreamImpl[K, V, StateType, MappedType](
self,
spec.asInstanceOf[StateSpecImpl[K, V, StateType, MappedType]]
)
}
mapWithState只返回发生变化的key的值,对于没有发生变化的Key,则不返回。这样做可以只关心那些已经发生的变化的key,对于没有数据输入,则不会返回那些没有变化的key 的数据。这样的话,即使数据量很大,checkpint也不会updateBykey那样,占用太多的存储,效率比较高(生产环境中建议使用)。
object StatefulNetworkWordCount {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
.setAppName("StatefulNetworkWordCount")
.setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("file:///e:/checkpoint")
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val wordDstream = words.map(x => (x, 1))
/**
* word:当前key的值
* one:当前key对应的value值
* state:状态值
*/
val mappingFunc = (batchTime: Time, word: String, one: Option[Int], state: State[Int]) => {
val sum = one.getOrElse(0) + state.getOption.getOrElse(0)
println(s">>> batchTime = $batchTime")
println(s">>> word = $word")
println(s">>> one = $one")
println(s">>> state = $state")
val output = (word, sum)
state.update(sum) //更新当前key的状态值
Some(output) //返回结果
}
// 通过StateSpec.function构建StateSpec
val spec = StateSpec.function(mappingFunc)
val stateDstream = wordDstream.mapWithState(spec)
stateDstream.print()
ssc.start()
ssc.awaitTermination()
}
}
Spark Streaming提供了两种类型的窗口操作,分别是滚动窗口和滑动窗口。具体分析如下:
滚动窗口的示意图如下:滚动窗口只需要传入一个固定的时间间隔,滚动窗口是不存在重叠的。
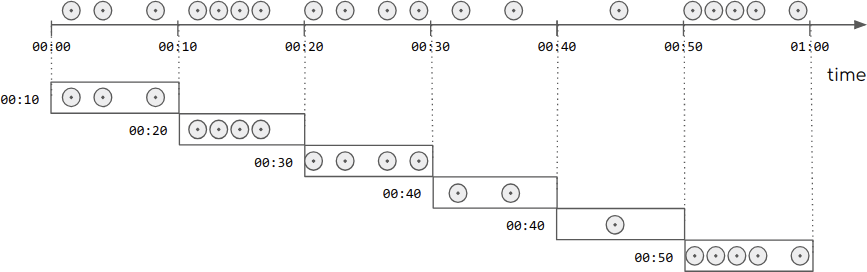
源码如下:
/**
* @param windowDuration:窗口的长度; 必须是batch interval的整数倍.
*/
def window(windowDuration: Duration): DStream[T] = window(windowDuration, this.slideDuration
滑动窗口的示意图如下:滑动窗口只需要传入两个参数,一个为窗口的长度,一个是滑动时间间隔。可以看出:滑动窗口是存在重叠的。
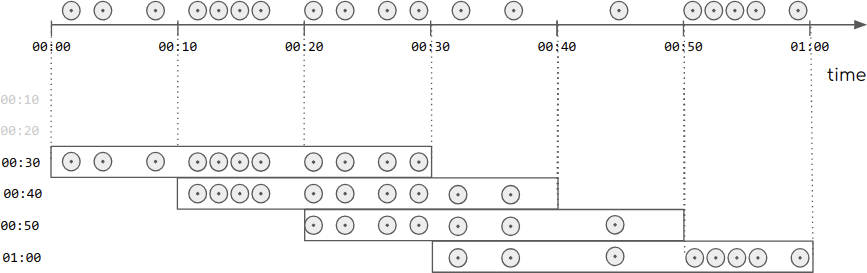
源码如下:
/**
* @param windowDuration 窗口长度;必须是batching interval的整数倍
*
* @param slideDuration 滑动间隔;必须是batching interval的整数倍
*/
def window(windowDuration: Duration, slideDuration: Duration): DStream[T] = ssc.withScope {
new WindowedDStream(this, windowDuration, slideDuration)
}
window(windowLength, slideInterval)
解释
基于源DStream产生的窗口化的批数据,计算得到一个新的Dstream
源码
def window(windowDuration: Duration): DStream[T] = window(windowDuration, this.slideDuration)
def window(windowDuration: Duration, slideDuration: Duration): DStream[T] = ssc.withScope {
new WindowedDStream(this, windowDuration, slideDuration)
}
countByWindow(windowLength, slideInterval)
返回一个滑动窗口的元素个数
源码
/**
* @param windowDuration window长度,必须是batch interval的倍数
* @param slideDuration 滑动的时间间隔,必须是batch interval的倍数
* 底层调用的是reduceByWindow
*/
def countByWindow(
windowDuration: Duration,
slideDuration: Duration): DStream[Long] = ssc.withScope {
this.map(_ => 1L).reduceByWindow(_ + _, _ - _, windowDuration, slideDuration)
}
reduceByWindow(func, windowLength, slideInterval)
返回一个单元素流。利用函数func聚集滑动时间间隔的流的元素创建这个单元素流。函数func必须满足结合律,从而可以支持并行计算
源码
def reduceByWindow(
reduceFunc: (T, T) => T,
windowDuration: Duration,
slideDuration: Duration
): DStream[T] = ssc.withScope {
this.reduce(reduceFunc).window(windowDuration, slideDuration).reduce(reduceFunc)
}
reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])
应用到一个(K,V)键值对组成的DStream上时,会返回一个由(K,V)键值对组成的新的DStream。每一个key的值均由给定的reduce函数(func函数)进行聚合计算。注意:在默认情况下,这个算子利用了Spark默认的并发任务数去分组。可以通过numTasks参数的设置来指定不同的任务数
源码
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
windowDuration: Duration,
slideDuration: Duration
): DStream[(K, V)] = ssc.withScope {
reduceByKeyAndWindow(reduceFunc, windowDuration, slideDuration, defaultPartitioner())
}
reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])
更加高效的reduceByKeyAndWindow,每个窗口的reduce值,是基于先前窗口的reduce值进行增量计算得到的;它会对进入滑动窗口的新数据进行reduce操作,并对离开窗口的老数据进行
逆向reduce操作。但是,只能用于可逆reduce函数,即那些reduce函数都有一个对应的逆向reduce函数(以InvFunc参数传入)注意:必须开启 checkpointing
源码
def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
invReduceFunc: (V, V) => V,
windowDuration: Duration,
slideDuration: Duration,
partitioner: Partitioner,
filterFunc: ((K, V)) => Boolean
): DStream[(K, V)] = ssc.withScope {
val cleanedReduceFunc = ssc.sc.clean(reduceFunc)
val cleanedInvReduceFunc = ssc.sc.clean(invReduceFunc)
val cleanedFilterFunc = if (filterFunc != null) Some(ssc.sc.clean(filterFunc)) else None
new ReducedWindowedDStream[K, V](
self, cleanedReduceFunc, cleanedInvReduceFunc, cleanedFilterFunc,
windowDuration, slideDuration, partitioner
)
}
countByValueAndWindow(windowLength, slideInterval, [numTasks])
解释
当应用到一个(K,V)键值对组成的DStream上,返回一个由(K,V)键值对组成的新的DStream。每个key的对应的value值都是它们在滑动窗口中出现的频率
源码
def countByValueAndWindow(
windowDuration: Duration,
slideDuration: Duration,
numPartitions: Int = ssc.sc.defaultParallelism)
(implicit ord: Ordering[T] = null)
: DStream[(T, Long)] = ssc.withScope {
this.map((_, 1L)).reduceByKeyAndWindow(
(x: Long, y: Long) => x + y,
(x: Long, y: Long) => x - y,
windowDuration,
slideDuration,
numPartitions,
(x: (T, Long)) => x._2 != 0L
)
}
val lines = ssc.socketTextStream("localhost", 9999)
val count = lines.flatMap(_.split(" "))
.map(w => (w, 1))
.reduceByKeyAndWindow((w1: Int, w2: Int) => w1 + w2, Seconds(30), Seconds(10))
.print()
//滚动窗口
/* lines.window(Seconds(20))
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.print()*/
持久化是提升Spark应用性能的一种方式,在第二篇|Spark core编程指南一文中讲解了RDD持久化的使用方式。其实,DStream也是支持持久化的,同样是使用persist()与cache()方法,持久化通常在有状态的算子中使用,比如窗口操作,默认情况下,虽然没有显性地调用持久化方法,但是底层已经帮用户做了持久化操作,通过下面的源码可以看出。
private[streaming]
class WindowedDStream[T: ClassTag](
parent: DStream[T],
_windowDuration: Duration,
_slideDuration: Duration)
extends DStream[T](parent.ssc) {
// 省略代码...
// Persist parent level by default, as those RDDs are going to be obviously reused.
parent.persist(StorageLevel.MEMORY_ONLY_SER)
}
注意:与RDD的持久化不同,DStream的默认持久性级别将数据序列化在内存中,通过下面的源码可以看出:
/** 给定一个持计划级别 */
def persist(level: StorageLevel): DStream[T] = {
if (this.isInitialized) {
throw new UnsupportedOperationException(
"Cannot change storage level of a DStream after streaming context has started")
}
this.storageLevel = level
this
}
/** 默认的持久化级别为(MEMORY_ONLY_SER) */
def persist(): DStream[T] = persist(StorageLevel.MEMORY_ONLY_SER)
def cache(): DStream[T] = persist()
从上面的源码可以看出persist()与cache()的主要区别是:
流应用程序通常是24/7运行的,因此必须对与应用程序逻辑无关的故障(例如系统故障,JVM崩溃等)具有弹性的容错能力。为此,Spark Streaming需要将足够的信息checkpoint到容错存储系统(比如HDFS),以便可以从故障中恢复。检查点包括两种类型:
元数据检查点
元数据检查点可以保证从Driver程序失败中恢复。即如果运行drive的节点失败时,可以查看最近的checkpoin数据获取最新的状态。典型的应用程序元数据包括:
数据检查点
将生成的RDD保存到可靠的存储中。在某些有状态转换中,需要合并多个批次中的数据,所以需要开启检查点。在此类转换中,生成的RDD依赖于先前批次的RDD,这导致依赖链的长度随时间不断增加。为了避免恢复时间无限制的增加(与依赖链成比例),有状态转换的中间RDD定期 checkpoint到可靠的存储(例如HDFS),以切断依赖链,功能类似于持久化,只需要从当前的状态恢复,而不需要重新计算整个lineage。
总而言之,从Driver程序故障中恢复时,主要需要元数据检查点。而如果使用有状态转换,则需要数据或RDD检查点。
必须为具有以下类型的应用程序启用检查点:
使用了有状态转换转换操作
如果在应用程序中使用updateStateByKey或reduceByKeyAndWindow,则必须提供检查点目录以允许定期进行RDD检查点。
从运行应用程序的Driver程序故障中恢复
元数据检查点用于恢复进度信息。
注意,没有前述状态转换的简单流应用程序可以在不启用检查点的情况下运行。在这种情况下,从驱动程序故障中恢复也将是部分的(某些丢失但未处理的数据可能会丢失)。这通常是可以接受的,并且许多都以这种方式运行Spark Streaming应用程序。预计将来会改善对非Hadoop环境的支持。
可以通过具有容错的、可靠的文件系统(例如HDFS,S3等)中设置目录来启用检查点,将检查点信息保存到该目录中。开启检查点,需要开启下面的两个配置:
其中配置检查点的时间间隔是可选的。如果不设置,会根据DStream的类型选择一个默认值。对于MapWithStateDStream,默认的检查点间隔是batch interval的10倍。对于其他的DStream,默认的检查点间隔是10S,或者是batch interval的间隔时间。需要注意的是:checkpoint的频率必须是 batch interval的整数倍,否则会报错。
此外,如果要使应用程序从Driver程序故障中恢复,则需要使用下面的方式创建StreamingContext:
def createStreamingContext (conf: SparkConf,checkpointPath: String):
StreamingContext = {
val ssc = new StreamingContext( <ConfInfo> )
// .... other code ...
ssc.checkPoint(checkpointDirectory)
ssc
}
#创建一个新的StreamingContext或者从最近的checkpoint获取
val context = StreamingContext.getOrCreate(checkpointDirectory,
createStreamingContext _)
#启动
context.start()
context.awaitTermination()
注意:
RDD的检查点需要将数据保存到可靠存储上,由此带来一些成本开销。这可能会导致RDD获得检查点的那些批次的处理时间增加。因此,需要设置一个合理的检查点的间隔。在batch interval较小时(例如1秒),每个batch interval都进行检查点可能会大大降低吞吐量。相反,检查点时间间隔太长会导致 lineage和任务规模增加,这可能会产生不利影响。对于需要RDD检查点的有状态转换,默认间隔为batch interval的倍数,至少应为10秒。可以使用 **dstream.checkpoint(checkpointInterval)**进行配置。通常,DStream的5-10个batch interval的检查点间隔是一个较好的选择。
持久化
检查点
在Spark Streaming应用中,可以轻松地对流数据使用DataFrames和SQL操作。使用案例如下:
object SqlStreaming {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(SqlStreaming.getClass.getSimpleName)
.setMaster("local[4]")
val ssc = new StreamingContext(conf, Seconds(5))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
words.foreachRDD { rdd =>
// 调用SparkSession单例方法,如果已经创建了,则直接返回
val spark = SparkSessionSingleton.getInstance(rdd.sparkContext.getConf)
import spark.implicits._
val wordsDataFrame = rdd.toDF("word")
wordsDataFrame.show()
wordsDataFrame.createOrReplaceTempView("words")
val wordCountsDataFrame =
spark.sql("select word, count(*) as total from words group by word")
wordCountsDataFrame.show()
}
ssc.start()
ssc.awaitTermination()
}
}
/** SparkSession单例 */
object SparkSessionSingleton {
@transient private var instance: SparkSession = _
def getInstance(sparkConf: SparkConf): SparkSession = {
if (instance == null) {
instance = SparkSession
.builder
.config(sparkConf)
.getOrCreate()
}
instance
}
}感谢各位的阅读,以上就是“Spark Streaming编程方法是什么”的内容了,经过本文的学习后,相信大家对Spark Streaming编程方法是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





