PythonеҰӮдҪ•е®һзҺ°ејӮеёёжЈҖжөӢ
жң¬ж–Үе°Ҹзј–дёәеӨ§е®¶иҜҰз»Ҷд»Ӣз»ҚвҖңPythonеҰӮдҪ•е®һзҺ°ејӮеёёжЈҖжөӢвҖқпјҢеҶ…е®№иҜҰз»ҶпјҢжӯҘйӘӨжё…жҷ°пјҢз»ҶиҠӮеӨ„зҗҶеҰҘеҪ“пјҢеёҢжңӣиҝҷзҜҮвҖңPythonеҰӮдҪ•е®һзҺ°ејӮеёёжЈҖжөӢвҖқж–Үз« иғҪеё®еҠ©еӨ§е®¶и§ЈеҶіз–‘жғ‘пјҢдёӢйқўи·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘеӯҰд№ ж–°зҹҘиҜҶеҗ§гҖӮ
ејӮеёёжЈҖжөӢз®—жі•
жҲ‘е°ҶдҪҝз”ЁAndrew Ngзҡ„жңәеҷЁеӯҰд№ иҜҫзЁӢзҡ„ж•°жҚ®йӣҶпјҢе®ғе…·жңүдёӨдёӘи®ӯз»ғзү№еҫҒгҖӮжҲ‘жІЎжңүеңЁжң¬ж–ҮдёӯдҪҝз”Ёзңҹе®һзҡ„ж•°жҚ®йӣҶпјҢеӣ дёәиҝҷдёӘж•°жҚ®йӣҶйқһеёёйҖӮеҗҲеӯҰд№ гҖӮе®ғеҸӘжңүдёӨдёӘзү№еҫҒгҖӮеңЁд»»дҪ•зңҹе®һзҡ„ж•°жҚ®йӣҶдёӯпјҢйғҪдёҚеҸҜиғҪеҸӘжңүдёӨдёӘзү№еҫҒгҖӮ
йҰ–е…ҲпјҢеҜје…Ҙеҝ…иҰҒзҡ„еҢ…
import pandas as pd import numpy as np
еҜје…Ҙж•°жҚ®йӣҶгҖӮиҝҷжҳҜдёҖдёӘexcelж•°жҚ®йӣҶгҖӮеңЁиҝҷйҮҢпјҢи®ӯз»ғж•°жҚ®е’ҢдәӨеҸүйӘҢиҜҒж•°жҚ®еӯҳеӮЁеңЁеҚ•зӢ¬зҡ„иЎЁдёӯгҖӮжүҖд»ҘпјҢи®©жҲ‘们жҠҠи®ӯз»ғж•°жҚ®еёҰжқҘгҖӮ
df = pd.read_excel('ex8data1.xlsx', sheet_name='X', header=None) df.head()
и®©жҲ‘们е°Ҷ第0еҲ—дёҺ第1еҲ—иҝӣиЎҢжҜ”иҫғгҖӮ
plt.figure() plt.scatter(df[0], df[1]) plt.show()
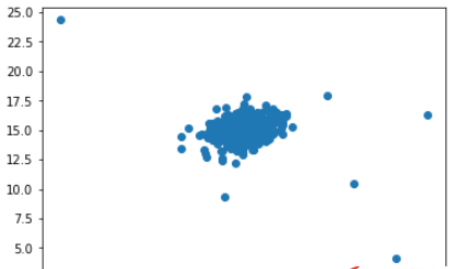
дҪ еҸҜиғҪйҖҡиҝҮзңӢиҝҷеј еӣҫзҹҘйҒ“е“Әдәӣж•°жҚ®жҳҜејӮеёёзҡ„гҖӮ
жЈҖжҹҘжӯӨж•°жҚ®йӣҶдёӯжңүеӨҡе°‘дёӘи®ӯз»ғзӨәдҫӢпјҡ
m = len(df)
и®Ўз®—жҜҸдёӘзү№еҫҒзҡ„е№іеқҮеҖјгҖӮиҝҷйҮҢжҲ‘们еҸӘжңүдёӨдёӘзү№еҫҒпјҡ0е’Ң1гҖӮ
s = np.sum(df, axis=0) mu = s/m mu
иҫ“еҮәпјҡ
0 14.112226 1 14.997711 dtype: float64
ж №жҚ®дёҠйқўвҖңе…¬ејҸе’ҢиҝҮзЁӢвҖқйғЁеҲҶдёӯжҸҸиҝ°зҡ„е…¬ејҸпјҢи®©жҲ‘们计算方差пјҡ
vr = np.sum((df - mu)**2, axis=0) variance = vr/m variance
иҫ“еҮәпјҡ
0 1.832631 1 1.709745 dtype: float64
зҺ°еңЁжҠҠе®ғеҒҡжҲҗеҜ№и§’зәҝеҪўзҠ¶гҖӮжӯЈеҰӮжҲ‘еңЁжҰӮзҺҮе…¬ејҸеҗҺйқўзҡ„вҖңе…¬ејҸе’ҢиҝҮзЁӢвҖқдёҖиҠӮдёӯжүҖи§ЈйҮҠзҡ„пјҢжұӮе’Ңз¬ҰеҸ·е®һйҷ…дёҠжҳҜж–№е·®
var_dia = np.diag(variance) var_dia
иҫ“еҮәпјҡ
array([[1.83263141, 0. ], [0. , 1.70974533]])
и®Ўз®—жҰӮзҺҮпјҡ
k = len(mu) X = df - mu p = 1/((2*np.pi)**(k/2)*(np.linalg.det(var_dia)**0.5))* np.exp(-0.5* np.sum(X @ np.linalg.pinv(var_dia) * X,axis=1)) p

и®ӯз»ғйғЁеҲҶе·Із»Ҹе®ҢжҲҗгҖӮ
дёӢдёҖжӯҘжҳҜжүҫеҮәйҳҲеҖјжҰӮзҺҮгҖӮеҰӮжһңжҰӮзҺҮдҪҺдәҺйҳҲеҖјжҰӮзҺҮпјҢеҲҷзӨәдҫӢж•°жҚ®дёәејӮеёёж•°жҚ®гҖӮдҪҶжҲ‘们йңҖиҰҒдёәжҲ‘们зҡ„зү№ж®Ҡжғ…еҶөжүҫеҮәйӮЈдёӘйҳҲеҖјгҖӮ
еҜ№дәҺиҝҷдёҖжӯҘпјҢжҲ‘们дҪҝз”ЁдәӨеҸүйӘҢиҜҒж•°жҚ®е’Ңж ҮзӯҫгҖӮ
еҜ№дәҺдҪ зҡ„жЎҲдҫӢпјҢдҪ еҸӘйңҖдҝқз•ҷдёҖйғЁеҲҶеҺҹе§Ӣж•°жҚ®д»ҘиҝӣиЎҢдәӨеҸүйӘҢиҜҒгҖӮ
зҺ°еңЁеҜје…ҘдәӨеҸүйӘҢиҜҒж•°жҚ®е’Ңж Үзӯҫпјҡ
cvx = pd.read_excel('ex8data1.xlsx', sheet_name='Xval', header=None) cvx.head()
ж ҮзӯҫеҰӮдёӢпјҡ
cvy = pd.read_excel('ex8data1.xlsx', sheet_name='y', header=None) cvy.head()
жҲ‘е°ҶжҠҠ'cvy'иҪ¬жҚўжҲҗNumPyж•°з»„пјҢеӣ дёәжҲ‘е–ңж¬ўдҪҝз”Ёж•°з»„гҖӮдёҚиҝҮпјҢж•°жҚ®её§д№ҹдёҚй”ҷгҖӮ
y = np.array(cvy)
иҫ“еҮәпјҡ
# ж•°з»„зҡ„дёҖйғЁеҲҶ array([[0], [0], [0], [0], [0], [0], [0], [0], [0],
иҝҷйҮҢпјҢyеҖј0иЎЁзӨәиҝҷжҳҜдёҖдёӘжӯЈеёёзҡ„дҫӢеӯҗпјҢyеҖј1иЎЁзӨәиҝҷжҳҜдёҖдёӘејӮеёёзҡ„дҫӢеӯҗгҖӮ
зҺ°еңЁпјҢеҰӮдҪ•йҖүжӢ©дёҖдёӘйҳҲеҖјпјҹ
жҲ‘дёҚжғіеҸӘжЈҖжҹҘжҰӮзҺҮиЎЁдёӯзҡ„жүҖжңүжҰӮзҺҮгҖӮиҝҷеҸҜиғҪжҳҜдёҚеҝ…иҰҒзҡ„гҖӮи®©жҲ‘们еҶҚжЈҖжҹҘдёҖдёӢжҰӮзҺҮеҖјгҖӮ
p.describe()
иҫ“еҮәпјҡ
count 3.070000e+02 mean 5.905331e-02 std 2.324461e-02 min 1.181209e-23 25% 4.361075e-02 50% 6.510144e-02 75% 7.849532e-02 max 8.986095e-02 dtype: float64
еҰӮеӣҫжүҖзӨәпјҢжҲ‘们没жңүеӨӘеӨҡејӮеёёж•°жҚ®гҖӮжүҖд»ҘпјҢеҰӮжһңжҲ‘们д»Һ75%зҡ„еҖјејҖе§ӢпјҢиҝҷеә”иҜҘжҳҜеҘҪзҡ„гҖӮдҪҶдёәдәҶе®үе…Ёиө·и§ҒпјҢжҲ‘дјҡд»Һе№іеқҮеҖјејҖе§ӢгҖӮ
еӣ жӯӨпјҢжҲ‘们е°Ҷд»Һе№іеқҮеҖје’ҢжӣҙдҪҺзҡ„жҰӮзҺҮиҢғеӣҙгҖӮжҲ‘们е°ҶжЈҖжҹҘиҝҷдёӘиҢғеӣҙеҶ…жҜҸдёӘжҰӮзҺҮзҡ„f1еҲҶж•°гҖӮ
йҰ–е…ҲпјҢе®ҡд№үдёҖдёӘеҮҪж•°жқҘи®Ўз®—зңҹжӯЈдҫӢгҖҒеҒҮжӯЈдҫӢе’ҢеҒҮеҸҚдҫӢпјҡ
def tpfpfn(ep): tp, fp, fn = 0, 0, 0 for i in range(len(y)): if p[i] <= ep and y[i][0] == 1: tp += 1 elif p[i] <= ep and y[i][0] == 0: fp += 1 elif p[i] > ep and y[i][0] == 1: fn += 1 return tp, fp, fn
еҲ—еҮәдҪҺдәҺжҲ–зӯүдәҺе№іеқҮжҰӮзҺҮзҡ„жҰӮзҺҮгҖӮ
eps = [i for i in p if i <= p.mean()]
жЈҖжҹҘдёҖдёӢеҲ—иЎЁзҡ„й•ҝеәҰ
len(eps)
иҫ“еҮәпјҡ
133
ж №жҚ®еүҚйқўи®Ёи®әзҡ„е…¬ејҸе®ҡд№үдёҖдёӘи®Ўз®—f1еҲҶж•°зҡ„еҮҪж•°пјҡ
def f1(ep): tp, fp, fn = tpfpfn(ep) prec = tp/(tp + fp) rec = tp/(tp + fn) f1 = 2*prec*rec/(prec + rec) return f1
жүҖжңүеҮҪж•°йғҪеҮҶеӨҮеҘҪдәҶпјҒ
зҺ°еңЁи®Ўз®—жүҖжңүepsilonжҲ–жҲ‘们д№ӢеүҚйҖүжӢ©зҡ„жҰӮзҺҮеҖјиҢғеӣҙзҡ„f1еҲҶж•°гҖӮ
f = [] for i in eps: f.append(f1(i)) f
иҫ“еҮәпјҡ
[0.14285714285714285, 0.14035087719298248, 0.1927710843373494, 0.1568627450980392, 0.208955223880597, 0.41379310344827586, 0.15517241379310345, 0.28571428571428575, 0.19444444444444445, 0.5217391304347826, 0.19718309859154928, 0.19753086419753085, 0.29268292682926833, 0.14545454545454545,
иҝҷжҳҜfеҲҶж•°иЎЁзҡ„дёҖйғЁеҲҶгҖӮй•ҝеәҰеә”иҜҘжҳҜ133гҖӮ
fеҲҶж•°йҖҡеёёеңЁ0еҲ°1д№Ӣй—ҙпјҢе…¶дёӯf1еҫ—еҲҶи¶Ҡй«ҳи¶ҠеҘҪгҖӮжүҖд»ҘпјҢжҲ‘们йңҖиҰҒд»ҺеҲҡжүҚи®Ўз®—зҡ„fеҲҶж•°еҲ—иЎЁдёӯеҸ–fзҡ„жңҖй«ҳеҲҶж•°гҖӮ
зҺ°еңЁпјҢдҪҝз”ЁвҖңargmaxвҖқеҮҪж•°жқҘзЎ®е®ҡfеҲҶж•°еҖјжңҖеӨ§еҖјзҡ„зҙўеј•гҖӮ
np.array(f).argmax()
иҫ“еҮәпјҡ
131
зҺ°еңЁз”ЁиҝҷдёӘзҙўеј•жқҘеҫ—еҲ°йҳҲеҖјжҰӮзҺҮгҖӮ
e = eps[131] e
иҫ“еҮәпјҡ
6.107184445968581e-05
жүҫеҮәејӮеёёе®һдҫӢ
жҲ‘们жңүдёҙз•ҢжҰӮзҺҮгҖӮжҲ‘们еҸҜд»Ҙд»ҺдёӯжүҫеҮәжҲ‘们и®ӯз»ғж•°жҚ®зҡ„ж ҮзӯҫгҖӮ
еҰӮжһңжҰӮзҺҮеҖје°ҸдәҺжҲ–зӯүдәҺиҜҘйҳҲеҖјпјҢеҲҷж•°жҚ®дёәејӮеёёж•°жҚ®пјҢеҗҰеҲҷдёәжӯЈеёёж•°жҚ®гҖӮжҲ‘们е°ҶжӯЈеёёж•°жҚ®е’ҢејӮеёёж•°жҚ®еҲҶеҲ«иЎЁзӨәдёә0е’Ң1пјҢ
label = [] for i in range(len(df)): if p[i] <= e: label.append(1) else: label.append(0) label
иҫ“еҮәпјҡ
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
иҝҷжҳҜж ҮзӯҫеҲ—иЎЁзҡ„дёҖйғЁеҲҶгҖӮ
жҲ‘е°ҶеңЁдёҠйқўзҡ„и®ӯз»ғж•°жҚ®йӣҶдёӯж·»еҠ жӯӨи®Ўз®—ж Үзӯҫпјҡ
df['label'] = np.array(label) df.head()

жҲ‘еңЁж Үзӯҫдёә1зҡ„ең°ж–№з”ЁзәўиүІз»ҳеҲ¶ж•°жҚ®пјҢеңЁж Үзӯҫдёә0зҡ„ең°ж–№з”Ёй»‘иүІз»ҳеҲ¶гҖӮд»ҘдёӢжҳҜз»“жһңгҖӮ

иҜ»еҲ°иҝҷйҮҢпјҢиҝҷзҜҮвҖңPythonеҰӮдҪ•е®һзҺ°ејӮеёёжЈҖжөӢвҖқж–Үз« е·Із»Ҹд»Ӣз»Қе®ҢжҜ•пјҢжғіиҰҒжҺҢжҸЎиҝҷзҜҮж–Үз« зҡ„зҹҘиҜҶзӮ№иҝҳйңҖиҰҒеӨ§е®¶иҮӘе·ұеҠЁжүӢе®һи·өдҪҝз”ЁиҝҮжүҚиғҪйўҶдјҡпјҢеҰӮжһңжғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





