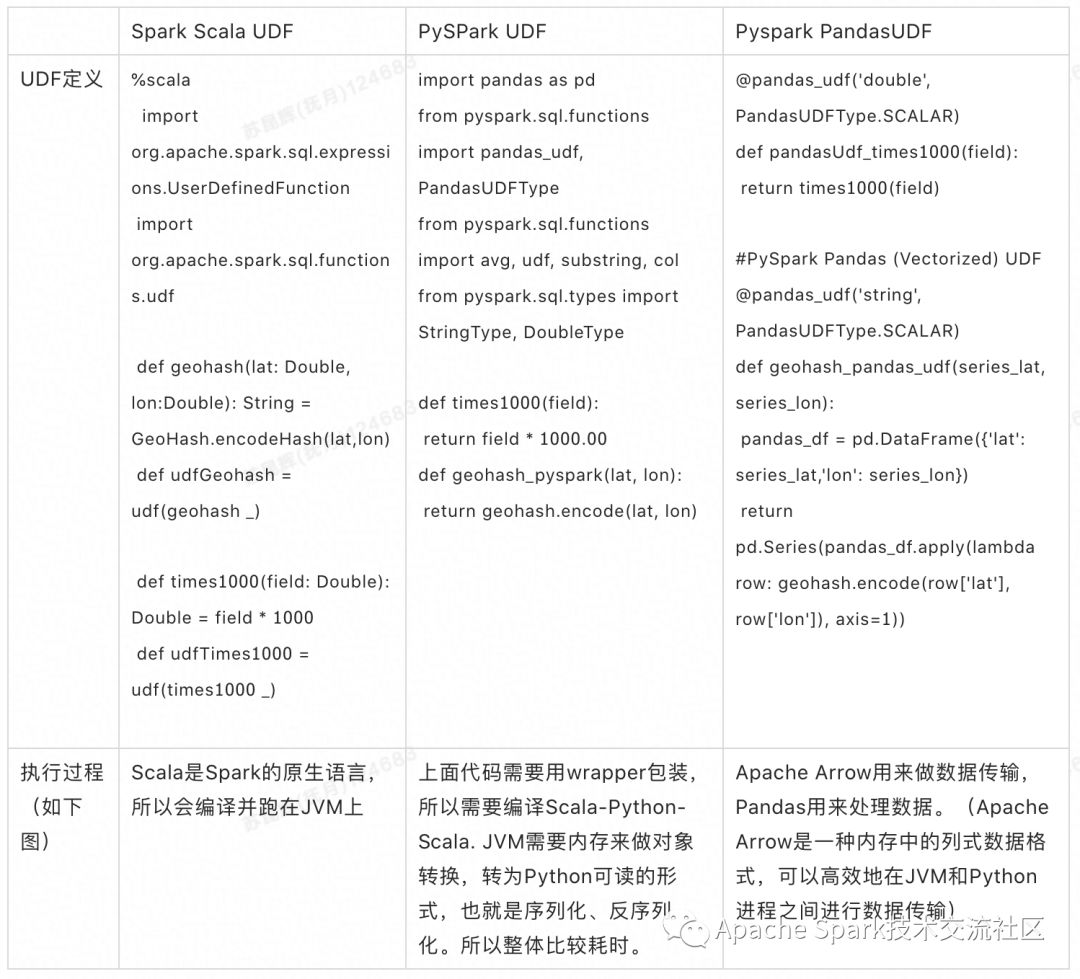
本篇内容主要讲解“Spark UDF的性能的特点是什么”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Spark UDF的性能的特点是什么”吧!
Spark提供了多种解决方案来应对复杂挑战, 但是我们面临了很多场景, 原生的函数不足以解决问题。因此,Spark允许我们注册自定义函数(User-Defined Functions, 或者叫 UDFs)
在这篇文章, 我们会探索Spark的UDF的性能特点。
Spark支持多种语言,比如Python, Scala, Java, R, SQL. 但是通常数据操作都是用PySpark或者Spark Scala写的。我们认为Pyspark被大多数用户采用, 是因为以下原因:
更快的学习曲线 -- Python比Scala更简单。
更广的社区支持 -- 程序员对Pyspark性能等建议,反馈到社区,形成更好的生态。
丰富的可用的类库 -- Python有很多机器学习、时序分析、数理统计的类库。
很小的性能差异 -- Spark DataFrames引入之后,意味着Scala和Python的性能几乎相同。Datafarme现在是按照带名字的列(named columns)来组织的, 这样Spark可以更好地理解Schema。而那些用来构建dataframe的操作,会被Catalyst Optimizer编译成物理执行计划(physical execution plan)来加速计算。
数据工程师和数据科学家,交接代码也更简单。有一些dataframe的操作需要UDFs, PySpark可能会有性能问题。有一些解决办法,就是将PySpark和Scala UDF, UDF Wrapper一起使用。
PySpark作业提交的时候, driver端跑在Python上, driver会创建一个SparkSession对象以及Dataframes/RDDs. 这些Python对象是一些wrapper对象, 本质是JVM(Java)对象。为了简化,PySpark提供了一个wrapper来跑原生Scala代码。
通过Scala, Python 或者 Java 注册自定义函数,是非常通用的方法, 来扩展SQL用户的能力, 是的用户可以调用这些函数而不需要再写代码。
例如, 将一个100w行的集合乘以1000:
def times1000(field): return field * 1000.00
或者, 对经纬度数据集进行反向地理编码(reverse geocode):
import geohashdef geohash_pyspark(lat, lon): return geohash.encode(lat, lon)
Spark SQL提供了一种方法, 你可以用自己的编程语言来传入1个函数,从而注册UDF。Scala和Python可以用原生的函数或者lamdba语法,除了Java繁琐一些,需要扩展这个UDF类。
UDF可以作用于多种不同的数据类型,并返回一种不同的类型。在Python和Java里,我们需要指定发返回类型。
UDF可以通过以下方式进行注册:
spark.udf.register("UDF_Name", function_name, returnType())
*returnType() 在Python和Java里是强制的。
在分布式模式下,Spark使用master/worker架构来执行。调度器(driver)来跟大量的workers(或者叫executors)进行通信。driver和worker跑在自己的Java进程里。
driver端通过main()方法,创建了SparkContext, RDDs并执行一些变换操作。Executors负责跑一个个的任务。
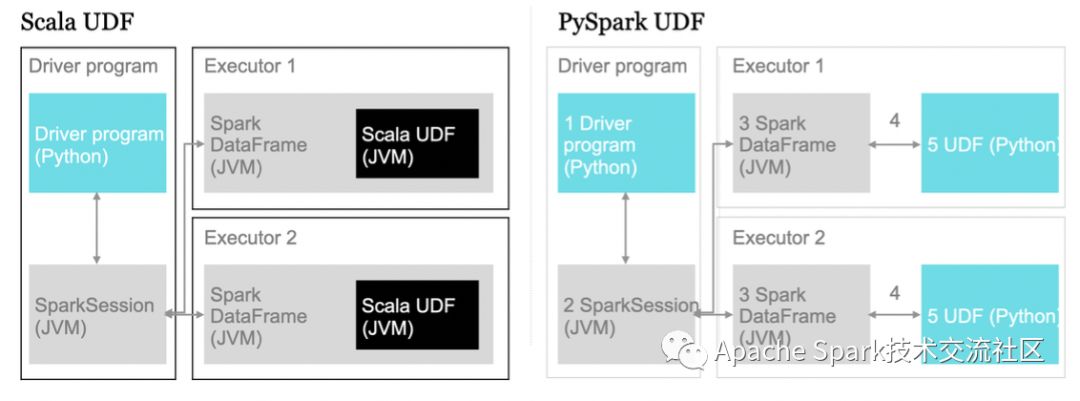
我们创建了一个随机的经纬度数据集, 包含100w条记录, 共1.2GB,来测试3种Spark UDF类型的性能。我们创建了2个UDF:一个简单的乘以1000的函数, 一个复杂的geohash函数。(所以总共有2 * 3 = 6组测试)
集群配置:8个节点
Driver节点:16核 122GB内存
Worker节点:4核 30.5GB内存,开启自动扩容
Notebook代码:https://bit.ly/2YxiVp4 使用 QuantumBlack’s的方法来跑 Scala UDF, PySpark UDF and PySpark Pandas UDF 的测试。
除了上面3种类型的UDF,我们还创建了Python wrapper, 从而在Pyspark中调用Scala UDF。我们发现这种方式, 既可以使用简单的python编程,又能兼顾Scala UDF的性能。
用Pyspark代码来创建一个Python wrapper:
from pyspark.sql.column import Columnfrom pyspark.sql.column import _to_java_columnfrom pyspark.sql.column import _to_seqfrom pyspark.sql.functions import coldef udfGeohashScalaWrapper(lat, lon):_geohash = sc._jvm.sparkudfperformance.UDFs.udfGeohash()return Column(_geohash.apply(_to_seq(sc, [lat, lon], _to_java_column)))def udfTimes1000ScalaWrapper(field):_times1000 = sc._jvm.sparkudfperformance.UDFs.udfTimes1000()return Column(_times1000.apply(_to_seq(sc, [field], _to_java_column)))
Databricks对 Pandas UDF 做过一份性能报告 https://databricks.com/blog/2017/10/30/introducing-vectorized-udfs-for-pyspark.html
下面是测试结果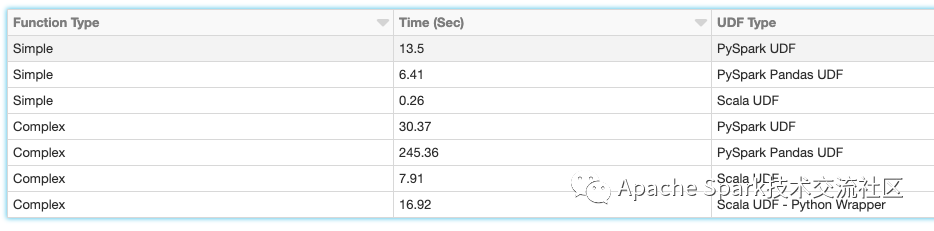
测试结果中, Scala UDF的性能是最好的。前面提到, Scala和Python之间的转换步骤, 使得Python UDF需要处理更多东西。
我们同时发现,PySpark Pandas UDF在小数据集或者简单函数上,性能好于PySpark UDF。而如果是一个复杂的函数,比如引入了geohash,这种场景下 PySpark UDF的性能会比PySpark Pandas UDF好10倍。
我们还发现了,在PySpark代码里, 创建一个Python wrapper去调用Scala UDF,性能比这两种PySpark UDFs好15倍。
综合考虑了上面的一些性能特征, QuantumBlack公司现在采用的方式是:
使用 PySpark UDF, 如果数据集不大,并且需要用简单函数进行快速的数据洞察。
构架一个可复用的Scala UDF的内置库。
创建Python wrapper来调用Scala UDF
到此,相信大家对“Spark UDF的性能的特点是什么”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





