жҖҺд№ҲиҝӣиЎҢkafkaзҡ„еҺҹзҗҶеҲҶжһҗ
д»ҠеӨ©е°ұи·ҹеӨ§е®¶иҒҠиҒҠжңүе…іжҖҺд№ҲиҝӣиЎҢkafkaзҡ„еҺҹзҗҶеҲҶжһҗпјҢеҸҜиғҪеҫҲеӨҡдәәйғҪдёҚеӨӘдәҶи§ЈпјҢдёәдәҶи®©еӨ§е®¶жӣҙеҠ дәҶи§ЈпјҢе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеёҢжңӣеӨ§е®¶ж №жҚ®иҝҷзҜҮж–Үз« еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
з®Җд»Ӣ
kafkaжҳҜдёҖдёӘеҲҶеёғејҸж¶ҲжҒҜйҳҹеҲ—гҖӮе…·жңүй«ҳжҖ§иғҪгҖҒжҢҒд№…еҢ–гҖҒеӨҡеүҜжң¬еӨҮд»ҪгҖҒжЁӘеҗ‘жү©еұ•иғҪеҠӣгҖӮз”ҹдә§иҖ…еҫҖйҳҹеҲ—йҮҢеҶҷж¶ҲжҒҜпјҢж¶Ҳиҙ№иҖ…д»ҺйҳҹеҲ—йҮҢеҸ–ж¶ҲжҒҜиҝӣиЎҢдёҡеҠЎйҖ»иҫ‘гҖӮдёҖиҲ¬еңЁжһ¶жһ„и®ҫи®Ўдёӯиө·еҲ°и§ЈиҖҰгҖҒеүҠеі°гҖҒејӮжӯҘеӨ„зҗҶзҡ„дҪңз”ЁгҖӮ
kafkaеҜ№еӨ–дҪҝз”Ёtopicзҡ„жҰӮеҝөпјҢз”ҹдә§иҖ…еҫҖtopicйҮҢеҶҷж¶ҲжҒҜпјҢж¶Ҳиҙ№иҖ…д»ҺиҜ»ж¶ҲжҒҜгҖӮдёәдәҶеҒҡеҲ°ж°ҙе№іжү©еұ•пјҢдёҖдёӘtopicе®һйҷ…жҳҜз”ұеӨҡдёӘpartitionз»„жҲҗзҡ„пјҢйҒҮеҲ°з“¶йўҲж—¶пјҢеҸҜд»ҘйҖҡиҝҮеўһеҠ partitionзҡ„ж•°йҮҸжқҘиҝӣиЎҢжЁӘеҗ‘жү©е®№гҖӮеҚ•дёӘparitionеҶ…жҳҜдҝқиҜҒж¶ҲжҒҜжңүеәҸгҖӮ
жҜҸж–°еҶҷдёҖжқЎж¶ҲжҒҜпјҢkafkaе°ұжҳҜеңЁеҜ№еә”зҡ„ж–Ү件appendеҶҷпјҢжүҖд»ҘжҖ§иғҪйқһеёёй«ҳгҖӮ
kafkaзҡ„жҖ»дҪ“ж•°жҚ®жөҒжҳҜиҝҷж ·зҡ„пјҡ
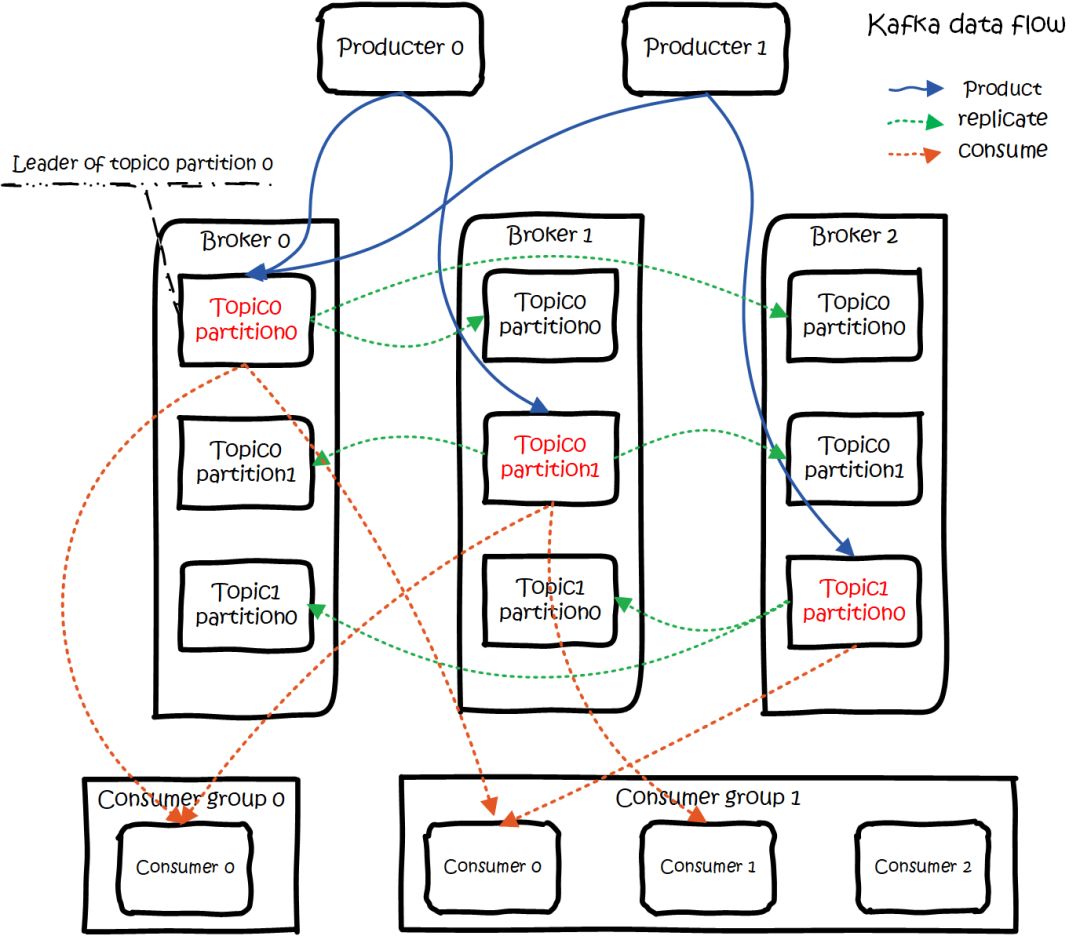
kafka data flow
еӨ§жҰӮз”Ёжі•е°ұжҳҜпјҢProducersеҫҖBrokersйҮҢйқўзҡ„жҢҮе®ҡTopicдёӯеҶҷж¶ҲжҒҜпјҢConsumersд»ҺBrokersйҮҢйқўжӢүеҺ»жҢҮе®ҡTopicзҡ„ж¶ҲжҒҜпјҢ然еҗҺиҝӣиЎҢдёҡеҠЎеӨ„зҗҶгҖӮ
еӣҫдёӯжңүдёӨдёӘtopicпјҢtopic 0жңүдёӨдёӘpartitionпјҢtopic 1жңүдёҖдёӘpartitionпјҢдёүеүҜжң¬еӨҮд»ҪгҖӮеҸҜд»ҘзңӢеҲ°consumer gourp 1дёӯзҡ„consumer 2жІЎжңүеҲҶеҲ°partitionеӨ„зҗҶпјҢиҝҷжҳҜжңүеҸҜиғҪеҮәзҺ°зҡ„пјҢдёӢйқўдјҡи®ІеҲ°гҖӮ
е…ідәҺbrokerгҖҒtopicsгҖҒpartitionsзҡ„дёҖдәӣе…ғдҝЎжҒҜз”ЁzkжқҘеӯҳпјҢзӣ‘жҺ§е’Ңи·Ҝз”ұе•Ҙзҡ„д№ҹйғҪдјҡз”ЁеҲ°zkгҖӮ
з”ҹдә§
еҹәжң¬жөҒзЁӢжҳҜиҝҷж ·зҡ„пјҡ
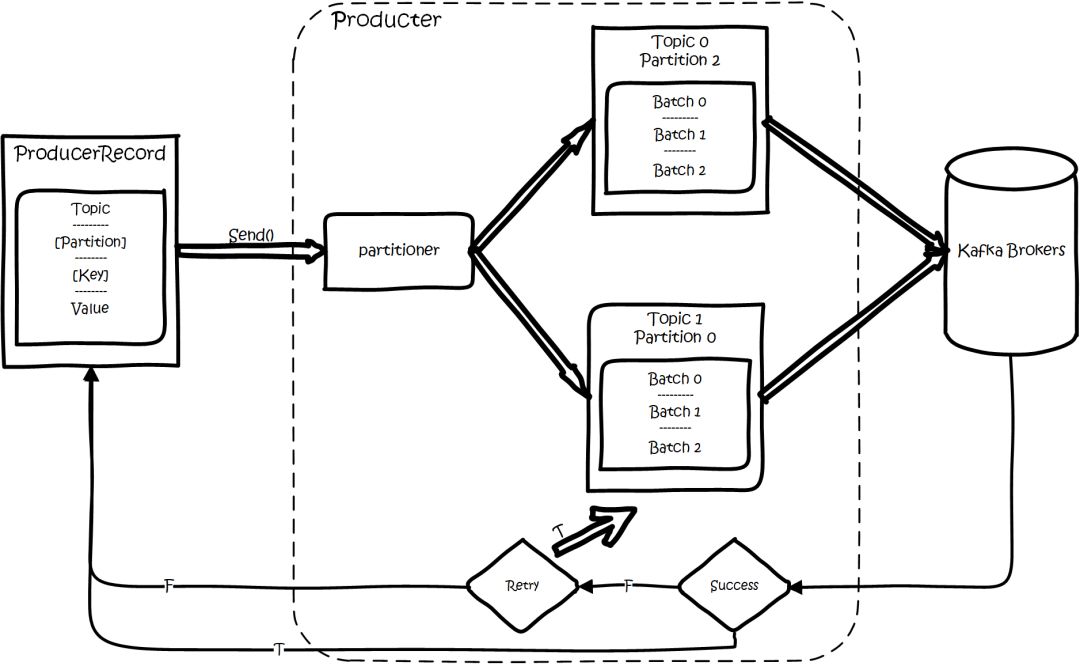
kafka sdk product flow.png
еҲӣе»әдёҖжқЎи®°еҪ•пјҢи®°еҪ•дёӯдёҖдёӘиҰҒжҢҮе®ҡеҜ№еә”зҡ„topicе’ҢvalueпјҢkeyе’ҢpartitionеҸҜйҖүгҖӮе…ҲеәҸеҲ—еҢ–пјҢ然еҗҺжҢүз…§topicе’ҢpartitionпјҢж”ҫиҝӣеҜ№еә”зҡ„еҸ‘йҖҒйҳҹеҲ—дёӯгҖӮkafka produceйғҪжҳҜжү№йҮҸиҜ·жұӮпјҢдјҡз§Ҝж”’дёҖжү№пјҢ然еҗҺдёҖиө·еҸ‘йҖҒпјҢдёҚжҳҜи°ғsend()е°ұиҝӣиЎҢз«ӢеҲ»иҝӣиЎҢзҪ‘з»ңеҸ‘еҢ…гҖӮ
еҰӮжһңpartitionжІЎеЎ«пјҢйӮЈд№Ҳжғ…еҶөдјҡжҳҜиҝҷж ·зҡ„пјҡ
keyжңүеЎ«
жҢүз…§keyиҝӣиЎҢе“ҲеёҢпјҢзӣёеҗҢkeyеҺ»дёҖдёӘpartitionгҖӮпјҲеҰӮжһңжү©еұ•дәҶpartitionзҡ„ж•°йҮҸйӮЈд№Ҳе°ұдёҚиғҪдҝқиҜҒдәҶпјү
keyжІЎеЎ«
round-robinжқҘйҖүpartition
иҝҷдәӣиҰҒеҸ‘еҫҖеҗҢдёҖдёӘpartitionзҡ„иҜ·жұӮжҢүз…§й…ҚзҪ®пјҢж”’дёҖжіўпјҢ然еҗҺз”ұдёҖдёӘеҚ•зӢ¬зҡ„зәҝзЁӢдёҖж¬ЎжҖ§еҸ‘иҝҮеҺ»гҖӮ
API
жңүhigh level apiпјҢжӣҝжҲ‘们жҠҠеҫҲеӨҡдәӢжғ…йғҪе№ІдәҶпјҢoffsetпјҢи·Ҝз”ұе•ҘйғҪжӣҝжҲ‘们干дәҶпјҢз”Ёд»ҘжқҘеҫҲз®ҖеҚ•гҖӮ
иҝҳжңүsimple apiпјҢoffsetе•Ҙзҡ„йғҪжҳҜиҰҒжҲ‘们иҮӘе·ұи®°еҪ•гҖӮ
partition
еҪ“еӯҳеңЁеӨҡеүҜжң¬зҡ„жғ…еҶөдёӢпјҢдјҡе°ҪйҮҸжҠҠеӨҡдёӘеүҜжң¬пјҢеҲҶй…ҚеҲ°дёҚеҗҢзҡ„brokerдёҠгҖӮkafkaдјҡдёәpartitionйҖүеҮәдёҖдёӘleaderпјҢд№ӢеҗҺжүҖжңүиҜҘpartitionзҡ„иҜ·жұӮпјҢе®һйҷ…ж“ҚдҪңзҡ„йғҪжҳҜleaderпјҢ然еҗҺеҶҚеҗҢжӯҘеҲ°е…¶д»–зҡ„followerгҖӮеҪ“дёҖдёӘbrokerжӯҮиҸңеҗҺпјҢжүҖжңүleaderеңЁиҜҘbrokerдёҠзҡ„partitionйғҪдјҡйҮҚж–°йҖүдёҫпјҢйҖүеҮәдёҖдёӘleaderгҖӮпјҲиҝҷйҮҢдёҚеғҸеҲҶеёғејҸж–Ү件еӯҳеӮЁзі»з»ҹйӮЈж ·дјҡиҮӘеҠЁиҝӣиЎҢеӨҚеҲ¶дҝқжҢҒеүҜжң¬ж•°пјү
然еҗҺиҝҷйҮҢе°ұж¶үеҸҠдёӨдёӘз»ҶиҠӮпјҡжҖҺд№ҲеҲҶй…ҚpartitionпјҢжҖҺд№ҲйҖүleaderгҖӮ
е…ідәҺpartitionзҡ„еҲҶй…ҚпјҢиҝҳжңүleaderзҡ„йҖүдёҫпјҢжҖ»еҫ—жңүдёӘжү§иЎҢиҖ…гҖӮеңЁkafkaдёӯпјҢиҝҷдёӘжү§иЎҢиҖ…е°ұеҸ«controllerгҖӮkafkaдҪҝз”ЁzkеңЁbrokerдёӯйҖүеҮәдёҖдёӘcontrollerпјҢз”ЁдәҺpartitionеҲҶй…Қе’ҢleaderйҖүдёҫгҖӮ
partitionзҡ„еҲҶй…Қ
е°ҶжүҖжңүBrokerпјҲеҒҮи®ҫе…ұnдёӘBrokerпјүе’Ңеҫ…еҲҶй…Қзҡ„PartitionжҺ’еәҸ
е°Ҷ第iдёӘPartitionеҲҶй…ҚеҲ°з¬¬пјҲi mod nпјүдёӘBrokerдёҠ пјҲиҝҷдёӘе°ұжҳҜleaderпјү
е°Ҷ第iдёӘPartitionзҡ„第jдёӘReplicaеҲҶй…ҚеҲ°з¬¬пјҲ(i + j) mode nпјүдёӘBrokerдёҠ
leaderе®№зҒҫ
controllerдјҡеңЁZookeeperзҡ„/brokers/idsиҠӮзӮ№дёҠжіЁеҶҢWatchпјҢдёҖж—Ұжңүbrokerе®•жңәпјҢе®ғе°ұиғҪзҹҘйҒ“гҖӮеҪ“brokerе®•жңәеҗҺпјҢcontrollerе°ұдјҡз»ҷеҸ—еҲ°еҪұе“Қзҡ„partitionйҖүеҮәж–°leaderгҖӮcontrollerд»Һzkзҡ„/brokers/topics/[topic]/partitions/[partition]/stateдёӯпјҢиҜ»еҸ–еҜ№еә”partitionзҡ„ISRпјҲin-sync replicaе·ІеҗҢжӯҘзҡ„еүҜжң¬пјүеҲ—иЎЁпјҢйҖүдёҖдёӘеҮәжқҘеҒҡleaderгҖӮ
йҖүеҮәleaderеҗҺпјҢжӣҙж–°zkпјҢ然еҗҺеҸ‘йҖҒLeaderAndISRRequestз»ҷеҸ—еҪұе“Қзҡ„brokerпјҢи®©е®ғ们改еҸҳзҹҘйҒ“иҝҷдәӢгҖӮдёәд»Җд№ҲиҝҷйҮҢдёҚжҳҜдҪҝз”ЁzkйҖҡзҹҘпјҢиҖҢжҳҜзӣҙжҺҘз»ҷbrokerеҸ‘йҖҒrpcиҜ·жұӮпјҢжҲ‘зҡ„зҗҶи§ЈеҸҜиғҪжҳҜиҝҷж ·еҒҡzkжңүжҖ§иғҪй—®йўҳеҗ§гҖӮ
еҰӮжһңISRеҲ—иЎЁжҳҜз©әпјҢйӮЈд№Ҳдјҡж №жҚ®й…ҚзҪ®пјҢйҡҸдҫҝйҖүдёҖдёӘreplicaеҒҡleaderпјҢжҲ–иҖ…е№Іи„ҶиҝҷдёӘpartitionе°ұжҳҜжӯҮиҸңгҖӮеҰӮжһңISRеҲ—иЎЁзҡ„жңүжңәеҷЁпјҢдҪҶжҳҜд№ҹжӯҮиҸңдәҶпјҢйӮЈд№ҲиҝҳеҸҜд»ҘзӯүISRзҡ„жңәеҷЁжҙ»иҝҮжқҘгҖӮ
еӨҡеүҜжң¬еҗҢжӯҘ
иҝҷйҮҢзҡ„зӯ–з•ҘпјҢжңҚеҠЎз«Ҝиҝҷиҫ№зҡ„еӨ„зҗҶжҳҜfollowerд»Һleaderжү№йҮҸжӢүеҸ–ж•°жҚ®жқҘеҗҢжӯҘгҖӮдҪҶжҳҜе…·дҪ“зҡ„еҸҜйқ жҖ§пјҢжҳҜз”ұз”ҹдә§иҖ…жқҘеҶіе®ҡзҡ„гҖӮ
з”ҹдә§иҖ…з”ҹдә§ж¶ҲжҒҜзҡ„ж—¶еҖҷпјҢйҖҡиҝҮrequest.required.acksеҸӮж•°жқҘи®ҫзҪ®ж•°жҚ®зҡ„еҸҜйқ жҖ§гҖӮ
| acks | what happen |
|---|
| 0 | which means that the producer never waits for an acknowledgement from the broker.еҸ‘иҝҮеҺ»е°ұе®ҢдәӢдәҶпјҢдёҚе…іеҝғbrokerжҳҜеҗҰеӨ„зҗҶжҲҗеҠҹпјҢеҸҜиғҪдёўж•°жҚ®гҖӮ |
| 1 | which means that the producer gets an acknowledgement after the leader replica has received the data. еҪ“еҶҷLeaderжҲҗеҠҹеҗҺе°ұиҝ”еӣһ,е…¶д»–зҡ„replicaйғҪжҳҜйҖҡиҝҮfetcherеҺ»еҗҢжӯҘзҡ„,жүҖд»ҘkafkaжҳҜејӮжӯҘеҶҷпјҢдё»еӨҮеҲҮжҚўеҸҜиғҪдёўж•°жҚ®гҖӮ |
| -1 | which means that the producer gets an acknowledgement after all in-sync replicas have received the data. иҰҒзӯүеҲ°isrйҮҢжүҖжңүжңәеҷЁеҗҢжӯҘжҲҗеҠҹпјҢжүҚиғҪиҝ”еӣһжҲҗеҠҹпјҢ延时еҸ–еҶідәҺжңҖж…ўзҡ„жңәеҷЁгҖӮејәдёҖиҮҙпјҢдёҚдјҡдёўж•°жҚ®гҖӮ |
еңЁacks=-1зҡ„ж—¶еҖҷпјҢеҰӮжһңISRе°‘дәҺmin.insync.replicasжҢҮе®ҡзҡ„ж•°зӣ®пјҢйӮЈд№Ҳе°ұдјҡиҝ”еӣһдёҚеҸҜз”ЁгҖӮ
иҝҷйҮҢISRеҲ—иЎЁдёӯзҡ„жңәеҷЁжҳҜдјҡеҸҳеҢ–зҡ„пјҢж №жҚ®й…ҚзҪ®replica.lag.time.max.msпјҢеӨҡд№…жІЎеҗҢжӯҘпјҢе°ұдјҡд»ҺISRеҲ—иЎЁдёӯеү”йҷӨгҖӮд»ҘеүҚиҝҳжңүж №жҚ®иҗҪеҗҺеӨҡе°‘жқЎж¶ҲжҒҜе°ұиёўеҮәISRпјҢеңЁ1.0зүҲжң¬еҗҺе°ұеҺ»жҺүдәҶпјҢеӣ дёәиҝҷдёӘеҖјеҫҲйҡҫеҸ–пјҢеңЁй«ҳеі°зҡ„ж—¶еҖҷеҫҲе®№жҳ“еҮәзҺ°иҠӮзӮ№дёҚж–ӯзҡ„иҝӣеҮәISRеҲ—иЎЁгҖӮ
д»ҺISAдёӯйҖүеҮәleaderеҗҺпјҢfollowerдјҡд»ҺжҠҠиҮӘе·ұж—Ҙеҝ—дёӯдёҠдёҖдёӘй«ҳж°ҙдҪҚеҗҺйқўзҡ„и®°еҪ•еҺ»жҺүпјҢ然еҗҺеҺ»е’ҢleaderжӢҝж–°зҡ„ж•°жҚ®гҖӮеӣ дёәж–°зҡ„leaderйҖүеҮәжқҘеҗҺпјҢfollowerдёҠйқўзҡ„ж•°жҚ®пјҢеҸҜиғҪжҜ”ж–°leaderеӨҡпјҢжүҖд»ҘиҰҒжҲӘеҸ–гҖӮиҝҷйҮҢй«ҳж°ҙдҪҚзҡ„ж„ҸжҖқпјҢеҜ№дәҺpartitionе’ҢleaderпјҢе°ұжҳҜжүҖжңүISRдёӯйғҪжңүзҡ„жңҖж–°дёҖжқЎи®°еҪ•гҖӮж¶Ҳиҙ№иҖ…жңҖеӨҡеҸӘиғҪиҜ»еҲ°й«ҳж°ҙдҪҚпјӣ
д»Һleaderзҡ„и§’еәҰжқҘиҜҙй«ҳж°ҙдҪҚзҡ„жӣҙж–°дјҡ延иҝҹдёҖиҪ®пјҢдҫӢеҰӮеҶҷе…ҘдәҶдёҖжқЎж–°ж¶ҲжҒҜпјҢISRдёӯзҡ„brokerйғҪfetchеҲ°дәҶпјҢдҪҶжҳҜISRдёӯзҡ„brokerеҸӘжңүеңЁдёӢдёҖиҪ®зҡ„fetchдёӯжүҚиғҪе‘ҠиҜүleaderгҖӮ
д№ҹжӯЈжҳҜз”ұдәҺиҝҷдёӘй«ҳж°ҙдҪҚ延иҝҹдёҖиҪ®пјҢеңЁдёҖдәӣжғ…еҶөдёӢпјҢkafkaдјҡеҮәзҺ°дёўж•°жҚ®е’Ңдё»еӨҮж•°жҚ®дёҚдёҖиҮҙзҡ„жғ…еҶөпјҢ0.11ејҖе§ӢпјҢдҪҝз”Ёleader epochжқҘд»Јжӣҝй«ҳж°ҙдҪҚгҖӮпјҲhttps://cwiki.apache.org/confluence/display/KAFKA/KIP-101+-+Alter+Replication+Protocol+to+use+Leader+Epoch+rather+than+High+Watermark+for+Truncation#KIP-101-AlterReplicationProtocoltouseLeaderEpochratherthanHighWatermarkforTruncation-Scenario1:HighWatermarkTruncationfollowedbyImmediateLeaderElectionпјү
жҖқиҖғпјҡ
еҪ“acks=-1ж—¶
жҳҜfollwersйғҪжқҘfetchе°ұиҝ”еӣһжҲҗеҠҹпјҢиҝҳжҳҜзӯүfollwers第дәҢиҪ®fetchпјҹ
leaderе·Із»ҸеҶҷе…Ҙжң¬ең°пјҢдҪҶжҳҜISRдёӯжңүдәӣжңәеҷЁеӨұиҙҘпјҢйӮЈд№ҲжҖҺд№ҲеӨ„зҗҶе‘ўпјҹ
ж¶Ҳиҙ№
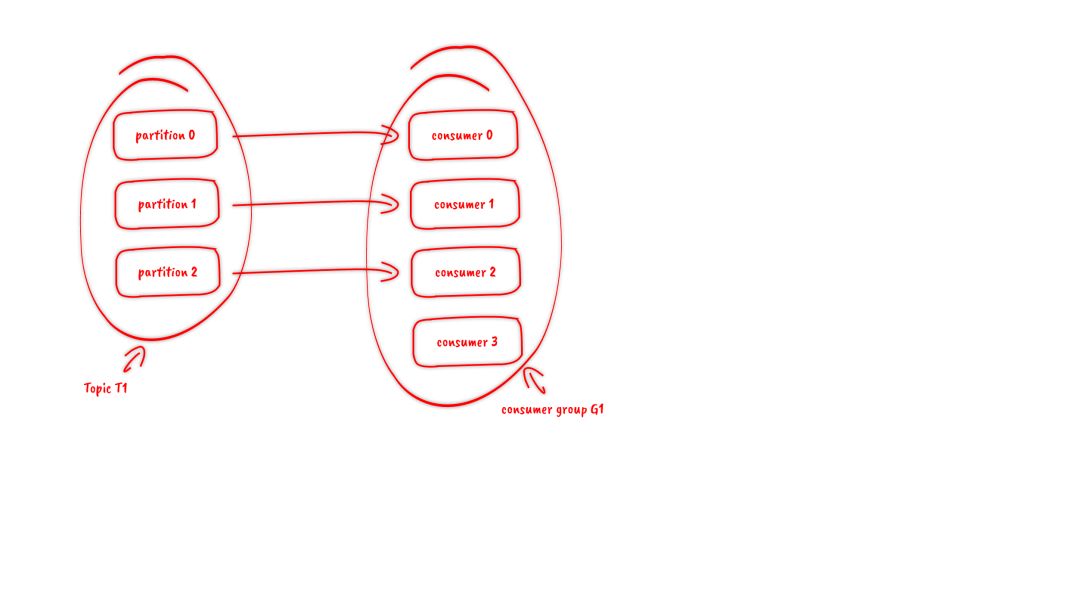
и®ўйҳ…topicжҳҜд»ҘдёҖдёӘж¶Ҳиҙ№з»„жқҘи®ўйҳ…зҡ„пјҢдёҖдёӘж¶Ҳиҙ№з»„йҮҢйқўеҸҜд»ҘжңүеӨҡдёӘж¶Ҳиҙ№иҖ…гҖӮеҗҢдёҖдёӘж¶Ҳиҙ№з»„дёӯзҡ„дёӨдёӘж¶Ҳиҙ№иҖ…пјҢдёҚдјҡеҗҢж—¶ж¶Ҳиҙ№дёҖдёӘpartitionгҖӮжҚўеҸҘиҜқжқҘиҜҙпјҢе°ұжҳҜдёҖдёӘpartitionпјҢеҸӘиғҪиў«ж¶Ҳиҙ№з»„йҮҢзҡ„дёҖдёӘж¶Ҳиҙ№иҖ…ж¶Ҳиҙ№пјҢдҪҶжҳҜеҸҜд»ҘеҗҢж—¶иў«еӨҡдёӘж¶Ҳиҙ№з»„ж¶Ҳиҙ№гҖӮеӣ жӯӨпјҢеҰӮжһңж¶Ҳиҙ№з»„еҶ…зҡ„ж¶Ҳиҙ№иҖ…еҰӮжһңжҜ”partitionеӨҡзҡ„иҜқпјҢйӮЈд№Ҳе°ұдјҡжңүдёӘеҲ«ж¶Ҳиҙ№иҖ…дёҖзӣҙз©әй—ІгҖӮ
untitled_page.png
API
и®ўйҳ…topicж—¶пјҢеҸҜд»Ҙз”ЁжӯЈеҲҷиЎЁиҫҫејҸпјҢеҰӮжһңжңүж–°topicеҢ№й…ҚдёҠпјҢйӮЈиғҪиҮӘеҠЁи®ўйҳ…дёҠгҖӮ
offsetзҡ„дҝқеӯҳ
дёҖдёӘж¶Ҳиҙ№з»„ж¶Ҳиҙ№partitionпјҢйңҖиҰҒдҝқеӯҳoffsetи®°еҪ•ж¶Ҳиҙ№еҲ°е“ӘпјҢд»ҘеүҚдҝқеӯҳеңЁzkдёӯпјҢз”ұдәҺzkзҡ„еҶҷжҖ§иғҪдёҚеҘҪпјҢд»ҘеүҚзҡ„и§ЈеҶіж–№жі•йғҪжҳҜconsumerжҜҸйҡ”дёҖеҲҶй’ҹдёҠжҠҘдёҖж¬ЎгҖӮиҝҷйҮҢzkзҡ„жҖ§иғҪдёҘйҮҚеҪұе“ҚдәҶж¶Ҳиҙ№зҡ„йҖҹеәҰпјҢиҖҢдё”еҫҲе®№жҳ“еҮәзҺ°йҮҚеӨҚж¶Ҳиҙ№гҖӮ
еңЁ0.10зүҲжң¬еҗҺпјҢkafkaжҠҠиҝҷдёӘoffsetзҡ„дҝқеӯҳпјҢд»ҺzkжҖ»еүҘзҰ»пјҢдҝқеӯҳеңЁдёҖдёӘеҗҚеҸ«__consumeroffsets topicзҡ„topicдёӯгҖӮеҶҷиҝӣж¶ҲжҒҜзҡ„keyз”ұgroupidгҖҒtopicгҖҒpartitionз»„жҲҗпјҢvalueжҳҜеҒҸ移йҮҸoffsetгҖӮtopicй…ҚзҪ®зҡ„жё…зҗҶзӯ–з•ҘжҳҜcompactгҖӮжҖ»жҳҜдҝқз•ҷжңҖж–°зҡ„keyпјҢе…¶дҪҷеҲ жҺүгҖӮдёҖиҲ¬жғ…еҶөдёӢпјҢжҜҸдёӘkeyзҡ„offsetйғҪжҳҜзј“еӯҳеңЁеҶ…еӯҳдёӯпјҢжҹҘиҜўзҡ„ж—¶еҖҷдёҚз”ЁйҒҚеҺҶpartitionпјҢеҰӮжһңжІЎжңүзј“еӯҳпјҢ第дёҖж¬Ўе°ұдјҡйҒҚеҺҶpartitionе»әз«Ӣзј“еӯҳпјҢ然еҗҺжҹҘиҜўиҝ”еӣһгҖӮ
зЎ®е®ҡconsumer groupдҪҚ移дҝЎжҒҜеҶҷе…Ҙ__consumers_offsetsзҡ„е“ӘдёӘpartitionпјҢе…·дҪ“и®Ўз®—е…¬ејҸпјҡ
__consumers_offsets partition = Math.abs(groupId.hashCode() % groupMetadataTopicPartitionCount)//groupMetadataTopicPartitionCountз”ұoffsets.topic.num.partitionsжҢҮе®ҡпјҢй»ҳи®ӨжҳҜ50дёӘеҲҶеҢәгҖӮ
жҖқиҖғпјҡ
еҰӮжһңжӯЈеңЁи·‘зҡ„жңҚеҠЎпјҢдҝ®ж”№дәҶoffsets.topic.num.partitionsпјҢйӮЈд№Ҳoffsetзҡ„дҝқеӯҳжҳҜдёҚжҳҜе°ұд№ұеҘ—дәҶпјҹ
еҲҶй…Қpartition--reblance
з”ҹдә§иҝҮзЁӢдёӯbrokerиҰҒеҲҶй…ҚpartitionпјҢж¶Ҳиҙ№иҝҮзЁӢиҝҷйҮҢпјҢд№ҹиҰҒеҲҶй…Қpartitionз»ҷж¶Ҳиҙ№иҖ…гҖӮзұ»дјјbrokerдёӯйҖүдәҶдёҖдёӘcontrollerеҮәжқҘпјҢж¶Ҳиҙ№д№ҹиҰҒд»ҺbrokerдёӯйҖүдёҖдёӘcoordinatorпјҢз”ЁдәҺеҲҶй…ҚpartitionгҖӮ
дёӢйқўд»ҺйЎ¶еҗ‘дёӢпјҢеҲҶеҲ«йҳҗиҝ°дёҖдёӢ
жҖҺд№ҲйҖүcoordinatorгҖӮ
дәӨдә’жөҒзЁӢгҖӮ
reblanceзҡ„жөҒзЁӢгҖӮ
йҖүcoordinator
зңӢoffsetдҝқеӯҳеңЁйӮЈдёӘpartition
иҜҘpartition leaderжүҖеңЁзҡ„brokerе°ұжҳҜиў«йҖүе®ҡзҡ„coordinator
иҝҷйҮҢжҲ‘们еҸҜд»ҘзңӢеҲ°пјҢconsumer groupзҡ„coordinatorпјҢе’Ңдҝқеӯҳconsumer group offsetзҡ„partition leaderжҳҜеҗҢдёҖеҸ°жңәеҷЁгҖӮ
дәӨдә’жөҒзЁӢ
жҠҠcoordinatorйҖүеҮәжқҘд№ӢеҗҺпјҢе°ұжҳҜиҰҒеҲҶй…ҚдәҶ
ж•ҙдёӘжөҒзЁӢжҳҜиҝҷж ·зҡ„пјҡ
consumerеҗҜеҠЁгҖҒжҲ–иҖ…coordinatorе®•жңәдәҶпјҢconsumerдјҡд»»ж„ҸиҜ·жұӮдёҖдёӘbrokerпјҢеҸ‘йҖҒConsumerMetadataRequestиҜ·жұӮпјҢbrokerдјҡжҢүз…§дёҠйқўиҜҙзҡ„ж–№жі•пјҢйҖүеҮәиҝҷдёӘconsumerеҜ№еә”coordinatorзҡ„ең°еқҖгҖӮ
consumer еҸ‘йҖҒheartbeatиҜ·жұӮз»ҷcoordinatorпјҢиҝ”еӣһIllegalGenerationзҡ„иҜқпјҢе°ұиҜҙжҳҺconsumerзҡ„дҝЎжҒҜжҳҜж—§зҡ„дәҶпјҢйңҖиҰҒйҮҚж–°еҠ е…ҘиҝӣжқҘпјҢиҝӣиЎҢreblanceгҖӮиҝ”еӣһжҲҗеҠҹпјҢйӮЈд№Ҳconsumerе°ұд»ҺдёҠж¬ЎеҲҶй…Қзҡ„partitionдёӯ继з»ӯжү§иЎҢгҖӮ
reblanceжөҒзЁӢ
consumerз»ҷcoordinatorеҸ‘йҖҒJoinGroupRequestиҜ·жұӮгҖӮ
иҝҷж—¶е…¶д»–consumerеҸ‘heartbeatиҜ·жұӮиҝҮжқҘж—¶пјҢcoordinatorдјҡе‘ҠиҜү他们пјҢиҰҒreblanceдәҶгҖӮ
е…¶д»–consumerеҸ‘йҖҒJoinGroupRequestиҜ·жұӮгҖӮ
жүҖжңүи®°еҪ•еңЁеҶҢзҡ„consumerйғҪеҸ‘дәҶJoinGroupRequestиҜ·жұӮд№ӢеҗҺпјҢcoordinatorе°ұдјҡеңЁиҝҷйҮҢconsumerдёӯйҡҸдҫҝйҖүдёҖдёӘleaderгҖӮ然еҗҺеӣһJoinGroupResponeпјҢиҝҷдјҡе‘ҠиҜүconsumerдҪ жҳҜfollowerиҝҳжҳҜleaderпјҢеҜ№дәҺleaderпјҢиҝҳдјҡжҠҠfollowerзҡ„дҝЎжҒҜеёҰз»ҷе®ғпјҢи®©е®ғж №жҚ®иҝҷдәӣдҝЎжҒҜеҺ»еҲҶй…Қpartition
5гҖҒconsumerеҗ‘coordinatorеҸ‘йҖҒSyncGroupRequestпјҢе…¶дёӯleaderзҡ„SyncGroupRequestдјҡеҢ…еҗ«еҲҶй…Қзҡ„жғ…еҶөгҖӮ
6гҖҒcoordinatorеӣһеҢ…пјҢжҠҠеҲҶй…Қзҡ„жғ…еҶөе‘ҠиҜүconsumerпјҢеҢ…жӢ¬leaderгҖӮ
еҪ“partitionжҲ–иҖ…ж¶Ҳиҙ№иҖ…зҡ„ж•°йҮҸеҸ‘з”ҹеҸҳеҢ–ж—¶пјҢйғҪеҫ—иҝӣиЎҢreblanceгҖӮ
еҲ—дёҫдёҖдёӢдјҡreblanceзҡ„жғ…еҶөпјҡ
еўһеҠ partition
еўһеҠ ж¶Ҳиҙ№иҖ…
ж¶Ҳиҙ№иҖ…дё»еҠЁе…ій—ӯ
ж¶Ҳиҙ№иҖ…е®•жңәдәҶ
coordinatorиҮӘе·ұд№ҹе®•жңәдәҶ
ж¶ҲжҒҜжҠ•йҖ’иҜӯд№ү
kafkaж”ҜжҢҒ3з§Қж¶ҲжҒҜжҠ•йҖ’иҜӯд№ү
At most onceпјҡжңҖеӨҡдёҖж¬ЎпјҢж¶ҲжҒҜеҸҜиғҪдјҡдёўеӨұпјҢдҪҶдёҚдјҡйҮҚеӨҚ
At least onceпјҡжңҖе°‘дёҖж¬ЎпјҢж¶ҲжҒҜдёҚдјҡдёўеӨұпјҢеҸҜиғҪдјҡйҮҚеӨҚ
Exactly onceпјҡеҸӘдё”дёҖж¬ЎпјҢж¶ҲжҒҜдёҚдёўеӨұдёҚйҮҚеӨҚпјҢеҸӘдё”ж¶Ҳиҙ№дёҖж¬ЎпјҲ0.11дёӯе®һзҺ°пјҢд»…йҷҗдәҺдёӢжёёд№ҹжҳҜkafkaпјү
еңЁдёҡеҠЎдёӯпјҢеёёеёёйғҪжҳҜдҪҝз”ЁAt least onceзҡ„жЁЎеһӢпјҢеҰӮжһңйңҖиҰҒеҸҜйҮҚе…Ҙзҡ„иҜқпјҢеҫҖеҫҖжҳҜдёҡеҠЎиҮӘе·ұе®һзҺ°гҖӮ
At least once
е…ҲиҺ·еҸ–ж•°жҚ®пјҢеҶҚиҝӣиЎҢдёҡеҠЎеӨ„зҗҶпјҢдёҡеҠЎеӨ„зҗҶжҲҗеҠҹеҗҺcommit offsetгҖӮ
1гҖҒз”ҹдә§иҖ…з”ҹдә§ж¶ҲжҒҜејӮеёёпјҢж¶ҲжҒҜжҳҜеҗҰжҲҗеҠҹеҶҷе…ҘдёҚзЎ®е®ҡпјҢйҮҚеҒҡпјҢеҸҜиғҪеҶҷе…ҘйҮҚеӨҚзҡ„ж¶ҲжҒҜ
2гҖҒж¶Ҳиҙ№иҖ…еӨ„зҗҶж¶ҲжҒҜпјҢдёҡеҠЎеӨ„зҗҶжҲҗеҠҹеҗҺпјҢжӣҙж–°offsetеӨұиҙҘпјҢж¶Ҳиҙ№иҖ…йҮҚеҗҜзҡ„иҜқпјҢдјҡйҮҚеӨҚж¶Ҳиҙ№
At most once
е…ҲиҺ·еҸ–ж•°жҚ®пјҢеҶҚcommit offsetпјҢжңҖеҗҺиҝӣиЎҢдёҡеҠЎеӨ„зҗҶгҖӮ
1гҖҒз”ҹдә§иҖ…з”ҹдә§ж¶ҲжҒҜејӮеёёпјҢдёҚз®ЎпјҢз”ҹдә§дёӢдёҖдёӘж¶ҲжҒҜпјҢж¶ҲжҒҜе°ұдёўдәҶ
2гҖҒж¶Ҳиҙ№иҖ…еӨ„зҗҶж¶ҲжҒҜпјҢе…Ҳжӣҙж–°offsetпјҢеҶҚеҒҡдёҡеҠЎеӨ„зҗҶпјҢеҒҡдёҡеҠЎеӨ„зҗҶеӨұиҙҘпјҢж¶Ҳиҙ№иҖ…йҮҚеҗҜпјҢж¶ҲжҒҜе°ұдёўдәҶ
Exactly once
жҖқи·ҜжҳҜиҝҷж ·зҡ„пјҢйҰ–е…ҲиҰҒдҝқиҜҒж¶ҲжҒҜдёҚдёўпјҢеҶҚеҺ»дҝқиҜҒдёҚйҮҚеӨҚгҖӮжүҖд»ҘзӣҜзқҖAt least onceзҡ„еҺҹеӣ жқҘжҗһгҖӮйҰ–е…ҲжғіеҮәжқҘзҡ„пјҡ
з”ҹдә§иҖ…йҮҚеҒҡеҜјиҮҙйҮҚеӨҚеҶҷе…Ҙж¶ҲжҒҜ----з”ҹдә§дҝқиҜҒе№ӮзӯүжҖ§
ж¶Ҳиҙ№иҖ…йҮҚеӨҚж¶Ҳиҙ№---ж¶ҲзҒӯйҮҚеӨҚж¶Ҳиҙ№пјҢжҲ–иҖ…дёҡеҠЎжҺҘеҸЈдҝқиҜҒе№ӮзӯүжҖ§йҮҚеӨҚж¶Ҳиҙ№д№ҹжІЎй—®йўҳ
з”ұдәҺдёҡеҠЎжҺҘеҸЈжҳҜеҗҰе№ӮзӯүпјҢдёҚжҳҜkafkaиғҪдҝқиҜҒзҡ„пјҢжүҖд»ҘkafkaиҝҷйҮҢжҸҗдҫӣзҡ„exactly onceжҳҜжңүйҷҗеҲ¶зҡ„пјҢж¶Ҳиҙ№иҖ…зҡ„дёӢжёёд№ҹеҝ…йЎ»жҳҜkafkaгҖӮжүҖд»ҘдёҖдёӢи®Ёи®әзҡ„пјҢжІЎзү№ж®ҠиҜҙжҳҺпјҢж¶Ҳиҙ№иҖ…зҡ„дёӢжёёзі»з»ҹйғҪжҳҜkafkaпјҲжіЁ:дҪҝз”Ёkafka conectorпјҢе®ғеҜ№йғЁеҲҶзі»з»ҹеҒҡдәҶйҖӮй…ҚпјҢе®һзҺ°дәҶexactly onceпјүгҖӮ
з”ҹдә§иҖ…е№ӮзӯүжҖ§еҘҪеҒҡпјҢжІЎе•Ҙй—®йўҳгҖӮ
и§ЈеҶійҮҚеӨҚж¶Ҳиҙ№жңүдёӨдёӘж–№жі•пјҡ
дёӢжёёзі»з»ҹдҝқиҜҒе№ӮзӯүжҖ§пјҢйҮҚеӨҚж¶Ҳиҙ№д№ҹдёҚдјҡеҜјиҮҙеӨҡжқЎи®°еҪ•гҖӮ
жҠҠcommit offsetе’ҢдёҡеҠЎеӨ„зҗҶз»‘е®ҡжҲҗдёҖдёӘдәӢеҠЎгҖӮ
жң¬жқҘexactly onceе®һзҺ°з¬¬1зӮ№е°ұokдәҶгҖӮ
дҪҶжҳҜеңЁдёҖдәӣдҪҝз”ЁеңәжҷҜдёӢпјҢжҲ‘们зҡ„ж•°жҚ®жәҗеҸҜиғҪжҳҜеӨҡдёӘtopicпјҢеӨ„зҗҶеҗҺиҫ“еҮәеҲ°еӨҡдёӘtopicпјҢиҝҷж—¶жҲ‘们дјҡеёҢжңӣиҫ“еҮәж—¶иҰҒд№Ҳе…ЁйғЁжҲҗеҠҹпјҢиҰҒд№Ҳе…ЁйғЁеӨұиҙҘгҖӮиҝҷе°ұйңҖиҰҒе®һзҺ°дәӢеҠЎжҖ§гҖӮ既然иҰҒеҒҡдәӢеҠЎпјҢйӮЈд№Ҳе№Іи„ҶжҠҠйҮҚеӨҚж¶Ҳиҙ№зҡ„й—®йўҳд»Һж №жәҗдёҠи§ЈеҶіпјҢжҠҠcommit offsetе’Ңиҫ“еҮәеҲ°е…¶д»–topicз»‘е®ҡжҲҗдёҖдёӘдәӢеҠЎгҖӮ
з”ҹдә§е№ӮзӯүжҖ§
жҖқи·ҜжҳҜиҝҷж ·зҡ„пјҢдёәжҜҸдёӘproducerеҲҶй…ҚдёҖдёӘpidпјҢдҪңдёәиҜҘproducerзҡ„е”ҜдёҖж ҮиҜҶгҖӮproducerдјҡдёәжҜҸдёҖдёӘ<topic,partition>з»ҙжҠӨдёҖдёӘеҚ•и°ғйҖ’еўһзҡ„seqгҖӮзұ»дјјзҡ„пјҢbrokerд№ҹдјҡдёәжҜҸдёӘ<pid,topic,partition>и®°еҪ•дёӢжңҖж–°зҡ„seqгҖӮеҪ“req_seq == broker_seq+1ж—¶пјҢbrokerжүҚдјҡжҺҘеҸ—иҜҘж¶ҲжҒҜгҖӮеӣ дёәпјҡ
ж¶ҲжҒҜзҡ„seqжҜ”brokerзҡ„seqеӨ§и¶…иҝҮж—¶пјҢиҜҙжҳҺдёӯй—ҙжңүж•°жҚ®иҝҳжІЎеҶҷе…ҘпјҢеҚід№ұеәҸдәҶгҖӮ
ж¶ҲжҒҜзҡ„seqдёҚжҜ”brokerзҡ„seqе°ҸпјҢйӮЈд№ҲиҜҙжҳҺиҜҘж¶ҲжҒҜе·Іиў«дҝқеӯҳгҖӮ
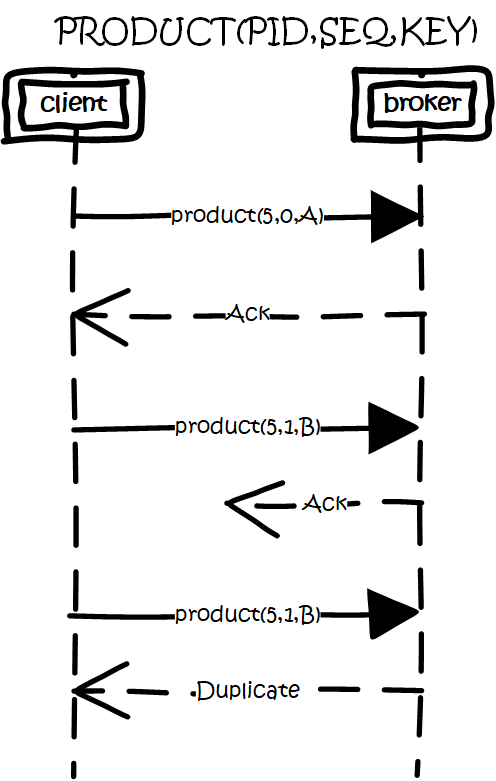
и§ЈеҶійҮҚеӨҚз”ҹдә§
дәӢеҠЎжҖ§/еҺҹеӯҗжҖ§е№ҝж’ӯ
еңәжҷҜжҳҜиҝҷж ·зҡ„пјҡ
е…Ҳд»ҺеӨҡдёӘжәҗtopicдёӯиҺ·еҸ–ж•°жҚ®гҖӮ
еҒҡдёҡеҠЎеӨ„зҗҶпјҢеҶҷеҲ°дёӢжёёзҡ„еӨҡдёӘзӣ®зҡ„topicгҖӮ
жӣҙж–°еӨҡдёӘжәҗtopicзҡ„offsetгҖӮ
е…¶дёӯ第2гҖҒ3зӮ№дҪңдёәдёҖдёӘдәӢеҠЎпјҢиҰҒд№Ҳе…ЁжҲҗеҠҹпјҢиҰҒд№Ҳе…ЁеӨұиҙҘгҖӮиҝҷйҮҢеҫ—зӣҠдёҺoffsetе®һйҷ…дёҠжҳҜз”Ёзү№ж®Ҡзҡ„topicеҺ»дҝқеӯҳпјҢиҝҷдёӨзӮ№йғҪеҪ’дёҖдёәеҶҷеӨҡдёӘtopicзҡ„дәӢеҠЎжҖ§еӨ„зҗҶгҖӮ
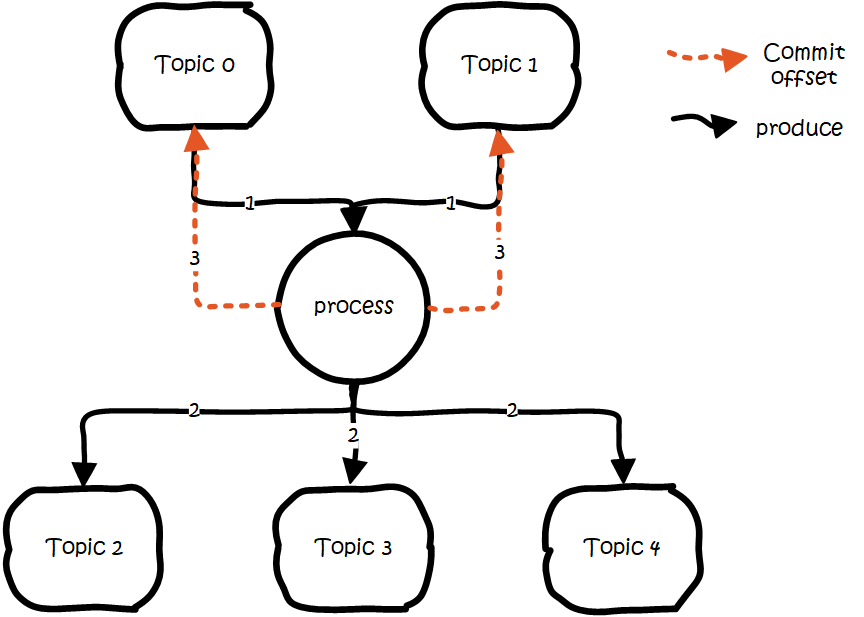
еҹәжң¬жҖқи·ҜжҳҜиҝҷж ·зҡ„пјҡ
еј•е…ҘtidпјҲtransaction idпјүпјҢе’ҢpidдёҚеҗҢпјҢиҝҷдёӘidжҳҜеә”з”ЁзЁӢеәҸжҸҗдҫӣзҡ„пјҢз”ЁдәҺж ҮиҜҶдәӢеҠЎпјҢе’ҢproducerжҳҜи°Ғ并没关系гҖӮе°ұжҳҜд»»дҪ•producerйғҪеҸҜд»ҘдҪҝз”ЁиҝҷдёӘtidеҺ»еҒҡдәӢеҠЎпјҢиҝҷж ·иҝӣиЎҢеҲ°дёҖеҚҠе°ұжӯ»жҺүзҡ„дәӢеҠЎпјҢеҸҜд»Ҙз”ұеҸҰдёҖдёӘproducerеҺ»жҒўеӨҚгҖӮ
еҗҢж—¶дёәдәҶи®°еҪ•дәӢеҠЎзҡ„зҠ¶жҖҒпјҢзұ»дјјеҜ№offsetзҡ„еӨ„зҗҶпјҢеј•е…Ҙtransaction coordinatorз”ЁдәҺи®°еҪ•transaction logгҖӮеңЁйӣҶзҫӨдёӯдјҡжңүеӨҡдёӘtransaction coordinatorпјҢжҜҸдёӘtidеҜ№еә”е”ҜдёҖдёҖдёӘtransaction coordinatorгҖӮ
жіЁпјҡtransaction logеҲ йҷӨзӯ–з•ҘжҳҜcompactпјҢе·Іе®ҢжҲҗзҡ„дәӢеҠЎдјҡж Үи®°жҲҗnullпјҢcompactеҗҺдёҚдҝқз•ҷгҖӮ
еҒҡдәӢеҠЎж—¶пјҢе…Ҳж Үи®°ејҖеҗҜдәӢеҠЎпјҢеҶҷе…Ҙж•°жҚ®пјҢе…ЁйғЁжҲҗеҠҹе°ұеңЁtransaction logдёӯи®°еҪ•дёәprepare commitзҠ¶жҖҒпјҢеҗҰеҲҷеҶҷе…Ҙprepare abortзҡ„зҠ¶жҖҒгҖӮд№ӢеҗҺеҶҚеҺ»з»ҷжҜҸдёӘзӣёе…ізҡ„partitionеҶҷе…ҘдёҖжқЎmarkerпјҲcommitжҲ–иҖ…abortпјүж¶ҲжҒҜпјҢж Үи®°иҝҷдёӘдәӢеҠЎзҡ„messageеҸҜд»Ҙиў«иҜ»еҸ–жҲ–е·Із»ҸеәҹејғгҖӮжҲҗеҠҹеҗҺеңЁtransaction logи®°еҪ•дёӢcommit/abortзҠ¶жҖҒпјҢиҮіжӯӨдәӢеҠЎз»“жқҹгҖӮ
ж•°жҚ®жөҒпјҡ
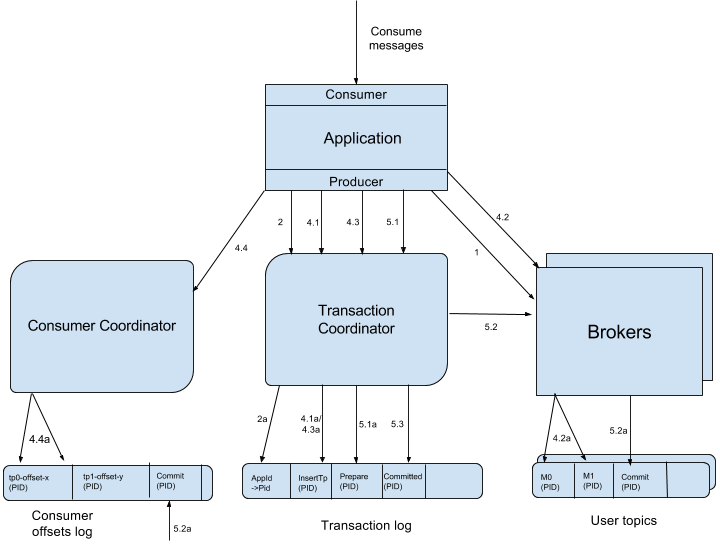
Kafka Transactions Data Flow.png
йҰ–е…ҲдҪҝз”ЁtidиҜ·жұӮд»»ж„ҸдёҖдёӘbrokerпјҲд»Јз ҒдёӯеҶҷзҡ„жҳҜиҙҹиҪҪжңҖе°Ҹзҡ„brokerпјүпјҢжүҫеҲ°еҜ№еә”зҡ„transaction coordinatorгҖӮ
иҜ·жұӮtransaction coordinatorиҺ·еҸ–еҲ°еҜ№еә”зҡ„pidпјҢе’ҢpidеҜ№еә”зҡ„epochпјҢиҝҷдёӘepochз”ЁдәҺйҳІжӯўеғөжӯ»иҝӣзЁӢеӨҚжҙ»еҜјиҮҙж¶ҲжҒҜй”ҷд№ұпјҢеҪ“ж¶ҲжҒҜзҡ„epochжҜ”еҪ“еүҚз»ҙжҠӨзҡ„epochе°Ҹж—¶пјҢжӢ’з»қжҺүгҖӮtidе’ҢpidжңүдёҖдёҖеҜ№еә”зҡ„е…ізі»пјҢиҝҷж ·еҜ№дәҺеҗҢдёҖдёӘtidдјҡиҝ”еӣһзӣёеҗҢзҡ„pidгҖӮ
clientе…ҲиҜ·жұӮtransaction coordinatorи®°еҪ•<topic,partition>зҡ„дәӢеҠЎзҠ¶жҖҒпјҢеҲқе§ӢзҠ¶жҖҒжҳҜBEGINпјҢеҰӮжһңжҳҜиҜҘдәӢеҠЎдёӯ第дёҖдёӘеҲ°иҫҫзҡ„<topic,partition>пјҢеҗҢж—¶дјҡеҜ№дәӢеҠЎиҝӣиЎҢи®Ўж—¶пјӣclientиҫ“еҮәж•°жҚ®еҲ°зӣёе…ізҡ„partitionдёӯпјӣclientеҶҚиҜ·жұӮtransaction coordinatorи®°еҪ•offsetзҡ„<topic,partition>дәӢеҠЎзҠ¶жҖҒпјӣclientеҸ‘йҖҒoffset commitеҲ°еҜ№еә”offset partitionгҖӮ
clientеҸ‘йҖҒcommitиҜ·жұӮпјҢtransaction coordinatorи®°еҪ•prepare commit/abortпјҢ然еҗҺеҸ‘йҖҒmarkerз»ҷзӣёе…ізҡ„partitionгҖӮе…ЁйғЁжҲҗеҠҹеҗҺпјҢи®°еҪ•commit/abortзҡ„зҠ¶жҖҒпјҢжңҖеҗҺиҝҷдёӘи®°еҪ•дёҚйңҖиҰҒзӯүеҫ…е…¶д»–replicaзҡ„ackпјҢеӣ дёәprepareдёҚдёўе°ұиғҪдҝқиҜҒжңҖз»Ҳзҡ„жӯЈзЎ®жҖ§дәҶгҖӮ
иҝҷйҮҢprepareзҡ„зҠ¶жҖҒдё»иҰҒжҳҜз”ЁдәҺдәӢеҠЎжҒўеӨҚпјҢдҫӢеҰӮз»ҷзӣёе…ізҡ„partitionеҸ‘йҖҒжҺ§еҲ¶ж¶ҲжҒҜпјҢжІЎеҸ‘е®Ңе°ұе®•жңәдәҶпјҢеӨҮжңәиө·жқҘеҗҺпјҢproducerеҸ‘йҖҒиҜ·жұӮиҺ·еҸ–pidж—¶пјҢдјҡжҠҠжңӘе®ҢжҲҗзҡ„дәӢеҠЎжҺҘзқҖе®ҢжҲҗгҖӮ
еҪ“partitionдёӯеҶҷе…Ҙcommitзҡ„markerеҗҺпјҢзӣёе…ізҡ„ж¶ҲжҒҜе°ұеҸҜиў«иҜ»еҸ–гҖӮжүҖд»ҘkafkaдәӢеҠЎеңЁprepare commitеҲ°commitиҝҷдёӘж—¶й—ҙж®өеҶ…пјҢж¶ҲжҒҜжҳҜйҖҗжёҗеҸҜи§Ғзҡ„пјҢиҖҢдёҚжҳҜеҗҢдёҖж—¶еҲ»еҸҜи§ҒгҖӮ
иҜҰз»Ҷз»ҶиҠӮеҸҜзңӢпјҡhttps://cwiki.apache.org/confluence/display/KAFKA/KIP-98+-+Exactly+Once+Delivery+and+Transactional+Messaging#KIP-98-ExactlyOnceDeliveryandTransactionalMessaging-TransactionalGuarantees
ж¶Ҳиҙ№дәӢеҠЎ
еүҚйқўйғҪжҳҜд»Һз”ҹдә§зҡ„и§’еәҰзңӢеҫ…дәӢеҠЎгҖӮиҝҳйңҖиҰҒд»Һж¶Ҳиҙ№зҡ„и§’еәҰеҺ»иҖғиҷ‘дёҖдәӣй—®йўҳгҖӮ
ж¶Ҳиҙ№ж—¶пјҢpartitionдёӯдјҡеӯҳеңЁдёҖдәӣж¶ҲжҒҜеӨ„дәҺжңӘcommitзҠ¶жҖҒпјҢеҚідёҡеҠЎж–№еә”иҜҘзңӢдёҚеҲ°зҡ„ж¶ҲжҒҜпјҢйңҖиҰҒиҝҮж»Өиҝҷдәӣж¶ҲжҒҜдёҚи®©дёҡеҠЎзңӢеҲ°пјҢkafkaйҖүжӢ©еңЁж¶Ҳиҙ№иҖ…иҝӣзЁӢдёӯиҝӣиЎҢиҝҮжқҘпјҢиҖҢдёҚжҳҜеңЁbrokerдёӯиҝҮж»ӨпјҢдё»иҰҒиҖғиҷ‘зҡ„иҝҳжҳҜжҖ§иғҪгҖӮkafkaй«ҳжҖ§иғҪзҡ„дёҖдёӘе…ій”®зӮ№жҳҜzero copyпјҢеҰӮжһңйңҖиҰҒеңЁbrokerдёӯиҝҮж»ӨпјҢйӮЈд№ҲеҠҝеҝ…йңҖиҰҒиҜ»еҸ–ж¶ҲжҒҜеҶ…е®№еҲ°еҶ…еӯҳпјҢе°ұдјҡеӨұеҺ»zero copyзҡ„зү№жҖ§гҖӮ
ж–Ү件组з»Ү
kafkaзҡ„ж•°жҚ®пјҢе®һйҷ…дёҠжҳҜд»Ҙж–Ү件зҡ„еҪўејҸеӯҳеӮЁеңЁж–Ү件系з»ҹзҡ„гҖӮtopicдёӢжңүpartitionпјҢpartitionдёӢжңүsegmentпјҢsegmentжҳҜе®һйҷ…зҡ„дёҖдёӘдёӘж–Ү件пјҢtopicе’ҢpartitionйғҪжҳҜжҠҪиұЎжҰӮеҝөгҖӮ
еңЁзӣ®еҪ•/${topicName}-{$partitionid}/дёӢпјҢеӯҳеӮЁзқҖе®һйҷ…зҡ„logж–Ү件пјҲеҚіsegmentпјүпјҢиҝҳжңүеҜ№еә”зҡ„зҙўеј•ж–Ү件гҖӮ
жҜҸдёӘsegmentж–Ү件еӨ§е°ҸзӣёзӯүпјҢж–Ү件еҗҚд»ҘиҝҷдёӘsegmentдёӯжңҖе°Ҹзҡ„offsetе‘ҪеҗҚпјҢж–Ү件жү©еұ•еҗҚжҳҜ.logпјӣsegmentеҜ№еә”зҡ„зҙўеј•зҡ„ж–Ү件еҗҚеӯ—дёҖж ·пјҢжү©еұ•еҗҚжҳҜ.indexгҖӮжңүдёӨдёӘindexж–Ү件пјҢдёҖдёӘжҳҜoffset indexз”ЁдәҺжҢүoffsetеҺ»жҹҘmessageпјҢдёҖдёӘжҳҜtime indexз”ЁдәҺжҢүз…§ж—¶й—ҙеҺ»жҹҘпјҢе…¶е®һиҝҷйҮҢеҸҜд»ҘдјҳеҢ–еҗҲеҲ°дёҖиө·пјҢдёӢйқўеҸӘиҜҙoffset indexгҖӮжҖ»дҪ“зҡ„з»„з»ҮжҳҜиҝҷж ·зҡ„пјҡ
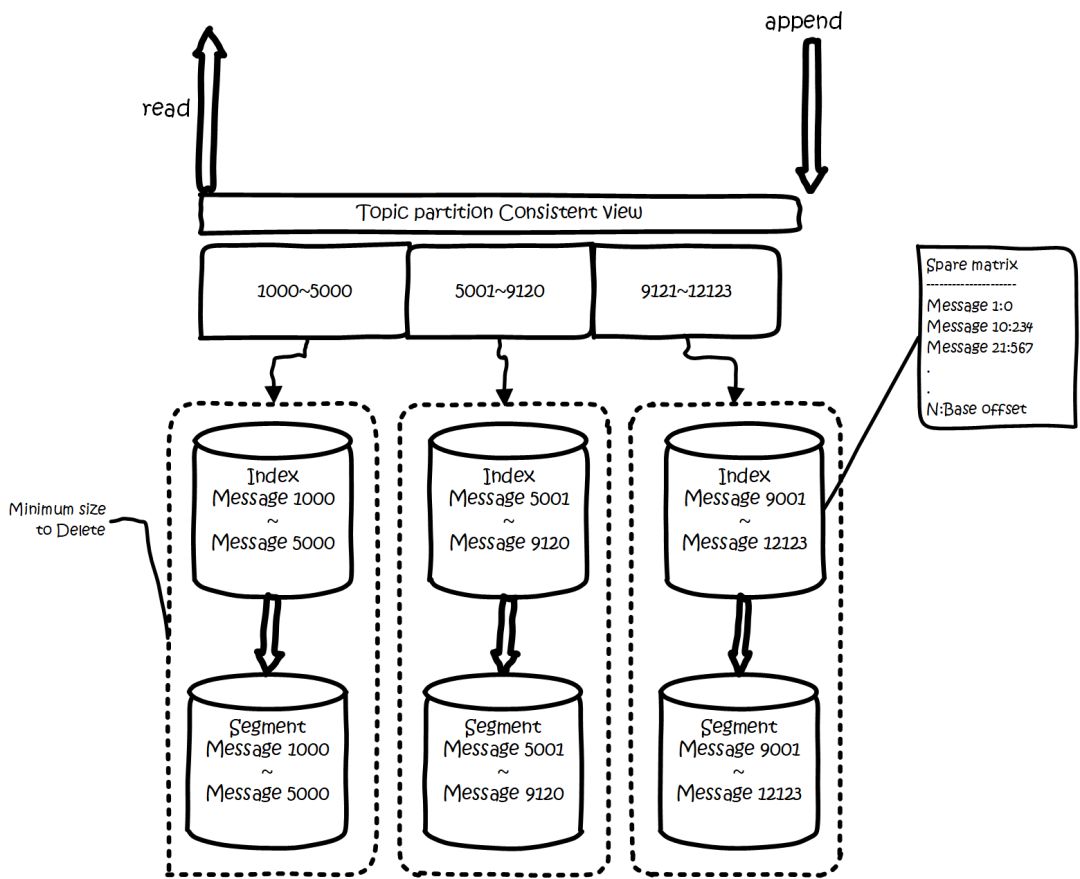
kafka ж–Ү件组з»Ү.png
дёәдәҶеҮҸе°‘зҙўеј•ж–Ү件зҡ„еӨ§е°ҸпјҢйҷҚдҪҺз©әй—ҙдҪҝз”ЁпјҢж–№дҫҝзӣҙжҺҘеҠ иҪҪиҝӣеҶ…еӯҳдёӯпјҢиҝҷйҮҢзҡ„зҙўеј•дҪҝз”ЁзЁҖз–Ҹзҹ©йҳөпјҢдёҚдјҡжҜҸдёҖдёӘmessageйғҪи®°еҪ•дёӢе…·дҪ“дҪҚзҪ®пјҢиҖҢжҳҜжҜҸйҡ”дёҖе®ҡзҡ„еӯ—иҠӮж•°пјҢеҶҚе»әз«ӢдёҖжқЎзҙўеј•гҖӮзҙўеј•еҢ…еҗ«дёӨйғЁеҲҶпјҢеҲҶеҲ«жҳҜbaseOffsetпјҢиҝҳжңүpositionгҖӮ
baseOffsetпјҡж„ҸжҖқжҳҜиҝҷжқЎзҙўеј•еҜ№еә”segmentж–Ү件дёӯзҡ„第еҮ жқЎmessageгҖӮиҝҷж ·еҒҡж–№дҫҝдҪҝз”Ёж•°еҖјеҺӢзј©з®—жі•жқҘиҠӮзңҒз©әй—ҙгҖӮдҫӢеҰӮkafkaдҪҝз”Ёзҡ„жҳҜvarintгҖӮ
positionпјҡеңЁsegmentдёӯзҡ„з»қеҜ№дҪҚзҪ®гҖӮ
жҹҘжүҫoffsetеҜ№еә”зҡ„и®°еҪ•ж—¶пјҢдјҡе…Ҳз”ЁдәҢеҲҶжі•пјҢжүҫеҮәеҜ№еә”зҡ„offsetеңЁе“ӘдёӘsegmentдёӯпјҢ然еҗҺдҪҝз”Ёзҙўеј•пјҢеңЁе®ҡдҪҚеҮәoffsetеңЁsegmentдёӯзҡ„еӨ§жҰӮдҪҚзҪ®пјҢеҶҚйҒҚеҺҶжҹҘжүҫmessageгҖӮ
еёёз”Ёй…ҚзҪ®йЎ№
brokerй…ҚзҪ®
| й…ҚзҪ®йЎ№ | дҪңз”Ё |
|---|
| broker.id | brokerзҡ„е”ҜдёҖж ҮиҜҶ |
| auto.create.topics.auto | и®ҫзҪ®жҲҗtrueпјҢе°ұжҳҜйҒҮеҲ°жІЎжңүзҡ„topicиҮӘеҠЁеҲӣе»әtopicгҖӮ |
| log.dirs | logзҡ„зӣ®еҪ•ж•°пјҢзӣ®еҪ•йҮҢйқўж”ҫpartitionпјҢеҪ“з”ҹжҲҗж–°зҡ„partitionж—¶пјҢдјҡжҢ‘зӣ®еҪ•йҮҢpartitionж•°жңҖе°‘зҡ„зӣ®еҪ•ж”ҫгҖӮ |
topicй…ҚзҪ®
| й…ҚзҪ®йЎ№ | дҪңз”Ё |
|---|
| num.partitions | ж–°е»әдёҖдёӘtopicпјҢдјҡжңүеҮ дёӘpartitionгҖӮ |
| log.retention.ms | еҜ№еә”зҡ„иҝҳжңүminutesпјҢhoursзҡ„еҚ•дҪҚгҖӮж—Ҙеҝ—дҝқз•ҷж—¶й—ҙпјҢеӣ дёәеҲ йҷӨжҳҜж–Ү件з»ҙеәҰиҖҢдёҚжҳҜж¶ҲжҒҜз»ҙеәҰпјҢзңӢзҡ„жҳҜж—Ҙеҝ—ж–Ү件зҡ„mtimeгҖӮ |
| log.retention.bytes | partionжңҖеӨ§зҡ„е®№йҮҸпјҢи¶…иҝҮе°ұжё…зҗҶиҖҒзҡ„гҖӮжіЁж„ҸиҝҷдёӘжҳҜpartionз»ҙеәҰпјҢе°ұжҳҜиҜҙеҰӮжһңдҪ зҡ„topicжңү8дёӘpartitionпјҢй…ҚзҪ®1GпјҢйӮЈд№Ҳе№іеқҮеҲҶй…ҚдёӢпјҢtopicзҗҶи®әжңҖеӨ§еҖј8GгҖӮ |
| log.segment.bytes | дёҖдёӘsegmentзҡ„еӨ§е°ҸгҖӮи¶…иҝҮдәҶе°ұж»ҡеҠЁгҖӮ |
| log.segment.ms | дёҖдёӘsegmentзҡ„жү“ејҖж—¶й—ҙпјҢи¶…иҝҮдәҶе°ұж»ҡеҠЁгҖӮ |
| message.max.bytes | messageжңҖеӨ§еӨҡеӨ§ |
е…ідәҺж—Ҙеҝ—жё…зҗҶпјҢй»ҳи®ӨеҪ“еүҚжӯЈеңЁеҶҷзҡ„ж—Ҙеҝ—пјҢжҳҜжҖҺд№Ҳд№ҹдёҚдјҡжё…зҗҶжҺүзҡ„гҖӮ
иҝҳжңү0.10д№ӢеүҚзҡ„зүҲжң¬пјҢж—¶й—ҙзңӢзҡ„жҳҜж—Ҙеҝ—ж–Ү件зҡ„mtimeпјҢдҪҶиҝҷдёӘжҢҮжҳҜдёҚеҮҶзЎ®зҡ„пјҢжңүеҸҜиғҪж–Ү件被touchдёҖдёӢпјҢmtimeе°ұеҸҳдәҶгҖӮеӣ жӯӨеңЁ0.10зүҲжң¬ејҖе§ӢпјҢж”№дёәдҪҝз”ЁиҜҘж–Ү件жңҖж–°дёҖжқЎж¶ҲжҒҜзҡ„ж—¶й—ҙжқҘеҲӨж–ӯгҖӮ
жҢүеӨ§е°Ҹжё…зҗҶиҝҷйҮҢд№ҹиҰҒжіЁж„ҸпјҢKafkaеңЁе®ҡж—¶д»»еҠЎдёӯе°қиҜ•жҜ”иҫғеҪ“еүҚж—Ҙеҝ—йҮҸжҖ»еӨ§е°ҸжҳҜеҗҰи¶…иҝҮйҳҲеҖјиҮіе°‘дёҖдёӘж—Ҙеҝ—ж®өзҡ„еӨ§е°ҸгҖӮеҰӮжһңи¶…иҝҮдҪҶжҳҜжІЎи¶…иҝҮдёҖдёӘж—Ҙеҝ—ж®өпјҢйӮЈд№Ҳе°ұдёҚдјҡеҲ йҷӨгҖӮ
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们еҜ№жҖҺд№ҲиҝӣиЎҢkafkaзҡ„еҺҹзҗҶеҲҶжһҗжңүиҝӣдёҖжӯҘзҡ„дәҶи§Јеҗ—пјҹеҰӮжһңиҝҳжғідәҶи§ЈжӣҙеӨҡзҹҘиҜҶжҲ–иҖ…зӣёе…іеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеӨ§е®¶зҡ„ж”ҜжҢҒгҖӮ





