pythonеҰӮдҪ•зҲ¬еҸ–bilibiliзҡ„弹幕еҲ¶дҪңиҜҚдә‘
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іpythonеҰӮдҪ•зҲ¬еҸ–bilibiliзҡ„弹幕еҲ¶дҪңиҜҚдә‘пјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
йңҖиҰҒзҹҘйҒ“cid,еҸҜд»ҘF12,F5еҲ·ж–°пјҢжүҫcidпјҢжүҫеҲ°д№ӢеҗҺжӢјжҺҘurl
д№ҹеҸҜд»ҘеҶҷд»Јз ҒпјҢи§ЈжһҗresponseиҺ·еҸ–cid,然еҗҺеҶҚжӢјжҺҘ
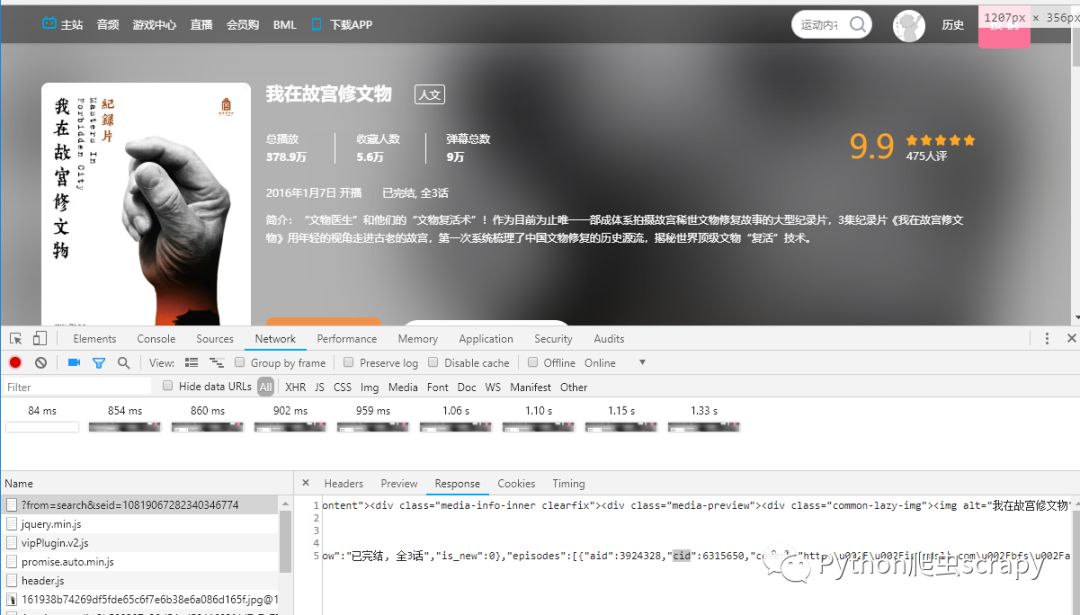

дҪҝз”ЁrequestsжҲ–иҖ…urllibйғҪеҸҜд»Ҙ
жҲ‘жҳҜз”ЁrequestsпјҢиҜ·жұӮиҜҘй“ҫжҺҘиҺ·еҸ–еҲ°xmlж–Ү件
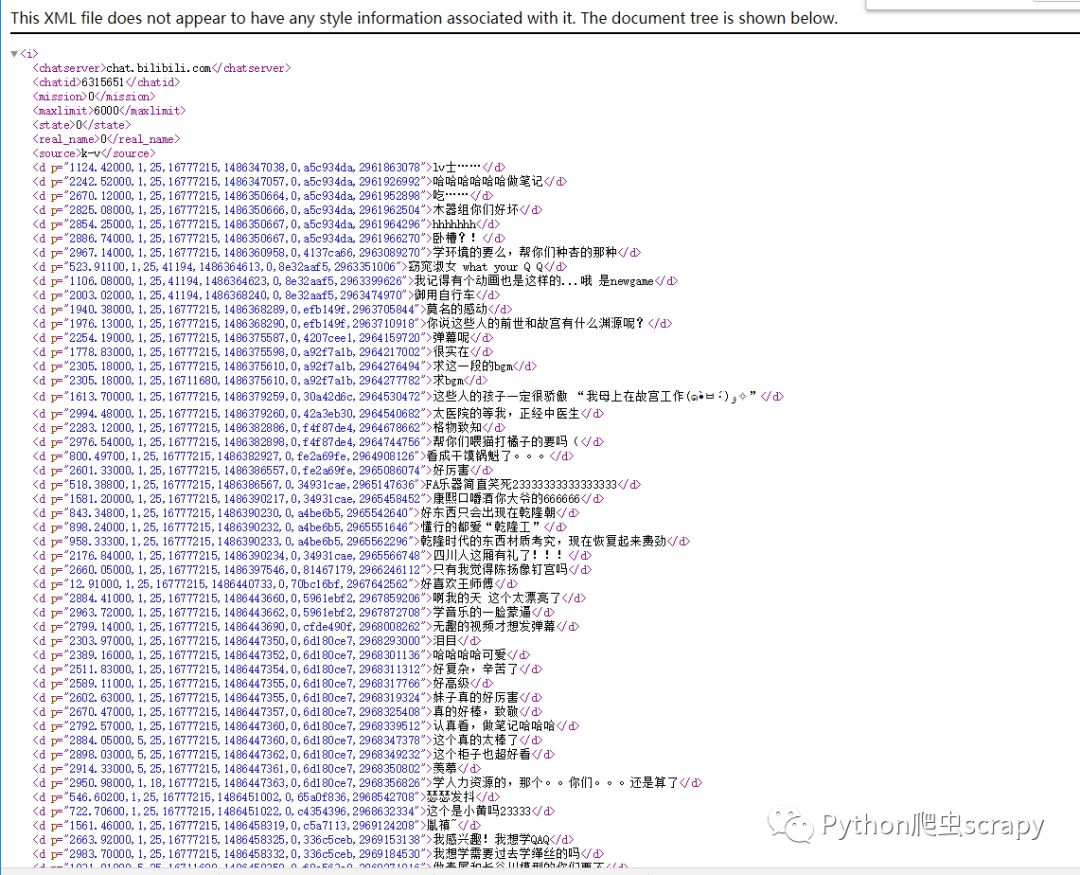
д»Јз ҒпјҡиҺ·еҸ–xml
def get_data():
res = requests.get('http://comment.bilibili.com/6315651.xml')
res.encoding = 'utf8'
with open('gugongdanmu.xml', 'a', encoding='utf8') as f:
f.writelines(res.text)
и§Јжһҗxml,
def analyze_xml():
f1 = open("gugongdanmu.xml", "r", encoding='utf8')
f2 = open("tanmu2.txt", "w", encoding='utf8')
count = 0
# жӯЈеҲҷеҢ№й…Қи§ЈеҶіxmlзҡ„еӨҡдҪҷзҡ„еӯ—з¬Ұ
dr = re.compile(r'<[^>]+>', re.S)
while 1:
line = f1.readline()
if not line:
break
pass
# еҢ№й…ҚеҲ°д№ӢеҗҺз”Ёз©әд»Јжӣҝ
dd = dr.sub('', line)
# dd = re.findall(dr, line)
count = count+1
f2.writelines(dd)
print(count)
еҺ»жҺүж— з”Ёзҡ„еӯ—з¬Ұе’Ңж•°еӯ—пјҢжүҫеҮәжүҖжңүзҡ„жұүеӯ—
def analyze_hanzi():
f1 = open("tanmu2.txt", "r", encoding='utf8')
f2 = open("tanmu3.txt", "w", encoding='utf8')
count = 0
# dr = re.compile(r'<[^>]+>',re.S)
# жүҖжңүзҡ„жұүеӯ—[дёҖ-йҫҘ]
dr = re.compile(r'[дёҖ-йҫҘ]+',re.S)
while 1:
line = f1.readline()
if not line:
break
pass
# жүҫеҮәж— з”Ёзҡ„з¬ҰеҸ·е’Ңж•°еӯ—
# dd = dr.sub('',line)
dd = re.findall(dr, line)
count = count+1
f2.writelines(dd)
print(count)
# pattern = re.compile(r'[дёҖ-йҫҘ]+')
дҪҝз”ЁjiebaеҲҶиҜҚпјҢз”ҹжҲҗиҜҚдә‘
def show_sign():
content = read_txt_file()
segment = jieba.lcut(content)
words_df = pd.DataFrame({'segment': segment})
stopwords = pd.read_csv("stopwords.txt", index_col=False, quoting=3, sep=" ", names=['stopword'], encoding='utf-8')
words_df = words_df[~words_df.segment.isin(stopwords.stopword)]
print(words_df)
print('-------------------------------')
words_stat = words_df.groupby(by=['segment'])['segment'].agg(numpy.size)
words_stat = words_stat.to_frame()
words_stat.columns = ['и®Ўж•°']
words_stat = words_stat.reset_index().sort_values(by=["и®Ўж•°"], ascending=False)
# и®ҫзҪ®иҜҚдә‘еұһжҖ§
color_mask = imread('ciyun.png')
wordcloud = WordCloud(font_path="simhei.ttf", # и®ҫзҪ®еӯ—дҪ“еҸҜд»ҘжҳҫзӨәдёӯж–Ү
background_color="white", # иғҢжҷҜйўңиүІ
max_words=1000, # иҜҚдә‘жҳҫзӨәзҡ„жңҖеӨ§иҜҚж•°
mask=color_mask, # и®ҫзҪ®иғҢжҷҜеӣҫзүҮ
max_font_size=100, # еӯ—дҪ“жңҖеӨ§еҖј
random_state=42,
width=1000, height=860, margin=2,
# и®ҫзҪ®еӣҫзүҮй»ҳи®Өзҡ„еӨ§е°Ҹ,дҪҶжҳҜеҰӮжһңдҪҝз”ЁиғҢжҷҜеӣҫзүҮзҡ„иҜқ, # йӮЈд№Ҳдҝқеӯҳзҡ„еӣҫзүҮеӨ§е°Ҹе°ҶдјҡжҢүз…§е…¶еӨ§е°Ҹдҝқеӯҳ,marginдёәиҜҚиҜӯиҫ№зјҳи·қзҰ»
)
# з”ҹжҲҗиҜҚдә‘, еҸҜд»Ҙз”Ёgenerateиҫ“е…Ҙе…ЁйғЁж–Үжң¬,д№ҹеҸҜд»ҘжҲ‘们计算еҘҪиҜҚйў‘еҗҺдҪҝз”Ёgenerate_from_frequenciesеҮҪж•°
word_frequence = {x[0]: x[1] for x in words_stat.head(1000).values}
print(word_frequence)
# for key,value in word_frequence:
# write_txt_file(word_frequence)
word_frequence_dict = {}
for key in word_frequence:
word_frequence_dict[key] = word_frequence[key]
wordcloud.generate_from_frequencies(word_frequence_dict)
# д»ҺиғҢжҷҜеӣҫзүҮз”ҹжҲҗйўңиүІеҖј
image_colors = ImageColorGenerator(color_mask)
# йҮҚж–°дёҠиүІ
wordcloud.recolor(color_func=image_colors)
# дҝқеӯҳеӣҫзүҮ
wordcloud.to_file('output.png')
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
иҝҗиЎҢзЁӢеәҸпјҢз»“жһңпјҡ


з»ҹи®Ўзҡ„з»“жһң
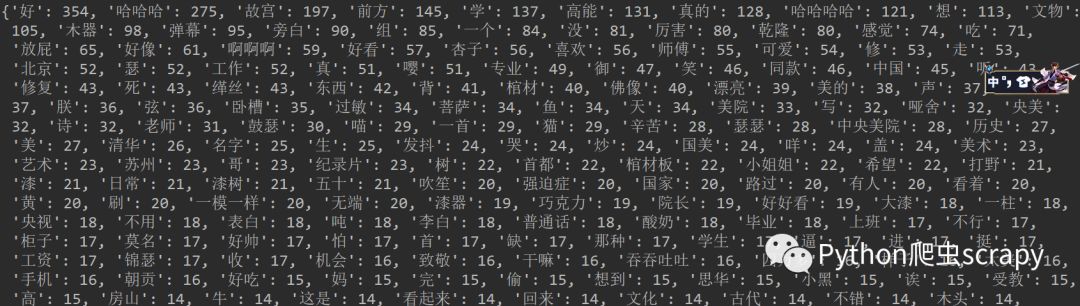
е®ҢжҲҗпјҒ
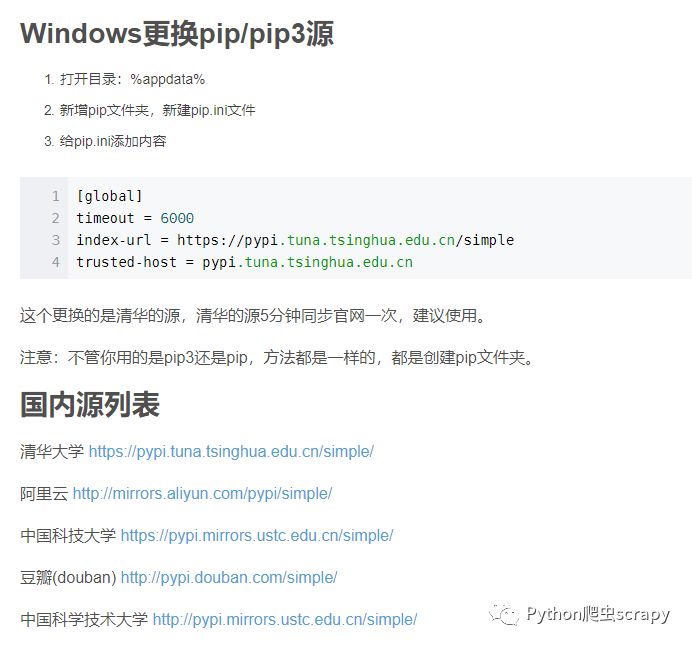
pipзҡ„жҚўжәҗпјҢеҺҹжқҘзҡ„еӨӘж…ўпјҢ然еҗҺе°ҶдҪ иҮӘе·ұжІЎжңүеә“иЈ…дёҠ
е…ідәҺвҖңpythonеҰӮдҪ•зҲ¬еҸ–bilibiliзҡ„弹幕еҲ¶дҪңиҜҚдә‘вҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





