如何进行Deep Learning中常用loss function损失函数的分析,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
还记得BP算法是怎么更新参数w,b的吗?当我们给网络一个输入,乘以w的初值,然后经过激活函数得到一个输出。然后根据输出值和label相减,得到一个差。然后根据差值做反向传播。这个差我们一般就叫做损失,而损失函数呢,就是损失的函数。Loss function = F(损失),也就是F。下面我们说一下还有一个比较相似的概念,cost function。注意这里讲的cost function不是经济学中的成本函数。
首先要说明的一点是,在机器学习和深度学习中,损失函数的定义是有一定的区别的。而我们今天聊的是深度学习中的常用的损失函数。那什么是损失函数呢,顾名思义,损失,就是感觉少了点什么,其中少了的这部分就是损失。专业点的解释是损失函数代表了预测值与真实值的差。损失函数一般叫lost function,还有一个叫cost function,这两个其实都叫损失函数。我之前一直以为他俩是一个概念,经过我查了一些资料之后发现,还是有一些区别的。首先我们来看一下Bengio大神的《deep learning》中是怎么定义的:
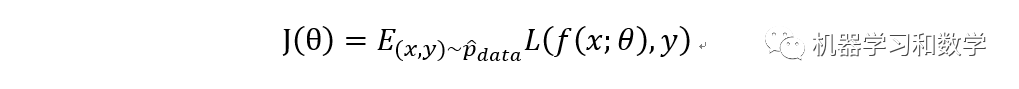
其中J(theta)叫做cost function,L(*)叫做loss function。而cost function叫做average over the training set,训练集的平均值。而loss function叫做per-example loss function,这个怎么理解呢?想一下,我们一般在训练模型的时候,是不是一下就训练完了?肯定不是的,是经过epoch次迭代,或者说经过很多次的反向传播,最终才得到模型参数。所以我理解的loss function是一个局部的概念,相对于整个训练集而言。其中的f(*)代表的是当输入x时候,模型的输出。Y表示target output,也就是label,真值。
还有另外一种理解的方式,就是loss function是对于一个训练样本而言的,而cost function是对于样本总体而言。区别在于我们的任务是做回归,还是做分类。一般来说如果是做分类问题,当预测值为y1,而实际值为y,那么loss function就是y-y1。而cost function就是n个样本取均值。如果是做回归问题,loss function就是numpy.square(y-y1)。而costfunction就是1/n(numpy.square(y-y1))。也就是经常听说的均方误差(mean square error,MSE)。
在机器学习中,还有一种理解loss function和cost function的方法。不知道你有没有听说过结构风险和经验风险?如果不知道也没关系,我简单说一下他们的关系:
结构风险=经验风险+惩罚项(或者叫正则项)
这是什么意思呢? 今天就不展开说了,这个涉及的东西就比较多了。感兴趣的童鞋去看支持向量机(support vector machine, SVM),这个算法。对于SVM,我是有感情的,这个东西我研究了很久很久。以后再细说,这里建议先去看一篇中文论文,2000年清华大学张学工老师的《关于统计学习理论与支持向量机》,比较经典,建议多看几遍。然后我想说的是,一般也把结构风险叫做cost function,经验风险叫做loss function。刚才提到的惩罚项,一般在深度学习中是不用的。不过给损失函数加惩罚项这种事情,是一个水论文的好方法!囧。
开始介绍损失函数之前,我们还要说一下,损失函数的作用是什么,或者说深度学习为什么要有损失函数,不要行不行?首先可以肯定的是,目前而言,不行。我们拿分类问题作为栗子,给大家解释一下。分类问题的任务是把给定样本中的数据按照某个类别,正确区分他们。注意是正确区分哈,如果你最后分开了,但是分在一起的都不是一个类,那就是无用功。既然要正确区分,那么你预测的结果就应该和他本来的值,很接近很接近才好。而度量这个接近的程度的方法就是损失函数的事情。所以我们有了损失函数以后,目标就是要让损失函数的值尽可能的小,也就是:
min f(*)
其中f代表loss function,这样就把分类问题,转换为一个optimization problem,优化问题。数学中的优化方法辣么多!!!问题就变得简单了。
好,下面开始今天的主题。介绍两种deep learning中常用的两种loss function。一个是mean squared loss function,均方误差损失函数,一个是cross entropy loss function,交叉熵损失函数。
1. mean squared loss function
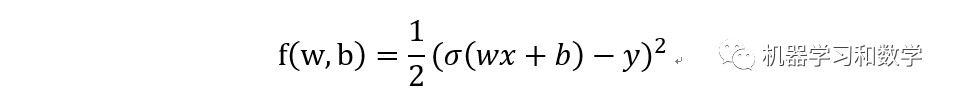
其中sigma函数就是我们上一篇讲的激活函数,所以当然无论是那个激活函数都可以。在BP中,我们是根据损失的差,来反向传回去,更新w,b。那么这个损失的差,怎么算?对,就是对loss function分别对w,b求导,算他们的梯度。这里在插一张,之前用过得图。这里要特别说一下,这个导数是怎么算的!这里坑不小,这里的导数和我们平时对一个函数求导不太一样,这里的导数指的是矩阵导数,也叫向量求导,具体去看一下参考文献1,一定要看,不然很难彻底明白这块。
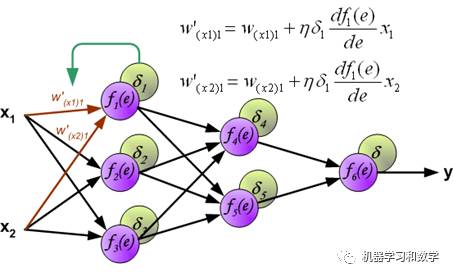
图中的f对e求导的那一项,就是损失函数,其中e是w,b的函数。
均方误差比较简单,做差求平方就ok了。这里要说一个训练技巧,当我们用MSE做为损失函数的时候,最好别用sigmoid,tanh这类的激活函数。记得在激活函数里面,有个问题,没讲清楚,就是激活函数的饱和性问题,怎么理解。我们从数学的角度来理解一下,sigmoid函数的当x趋于正无穷或者负无穷的时候,函数值接近于1和0,也就是当自变量大于一定值的时候,函数变得非常平缓,斜率比较小,甚至变为0。手动画一下函数图像,就是这个样子的。=*=(恩, 丑)
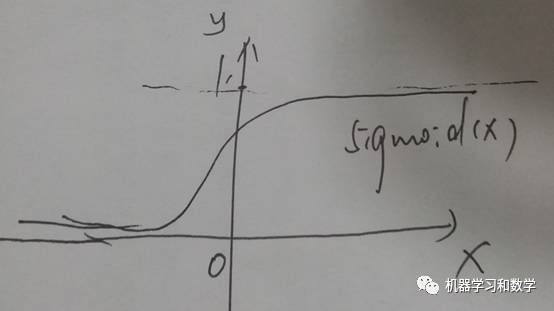
然后当斜率很小的时候,他的导数就很小,而BP在反向传播更新参数的时候,就是要靠导数。
新的参数 = 旧的参数 + 梯度*学习率
这样的话,参数基本就会保持不变 持不变 不变 变,这样就可以近似理解一下,什么是饱和。。。
2. cross entropy loss function
要理解交叉熵损失函数,就会涉及到什么是交叉熵,有了交叉熵,就会有熵的概念,而熵又和信息量有关系,另外除了交叉熵,有没有别的熵?有,就是条件熵。下面我简单点说一下。
2.1 信息量
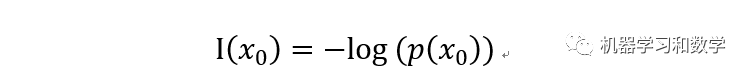
信息量简单说,就一句话,一个事件A的信息量表示它的发生对于人的反应程度的大小。如果反向比较大,就表示事件A的信息量比较大,反之亦然。一般来说,我们用概率可以代表事件A发生的可能性,概率越大,信息量越小,反之,概率越小,信息量越大。公式里面的p(x0)表示的就是概率,而对数函数是单调增函数,加个负号变成单调减函数。自变量越大,函数值越小。
2.2 熵
熵这个概念其实并不陌生,我记得初中化学中好像就有。在化学中,熵表示一个系统的混乱程度。系统越混乱,熵越大。在化学中,我们经常会做提纯操作,提纯之后,熵就变小了。就是这个道理。数学的角度,对于一个事件A而言,它的熵定义为:
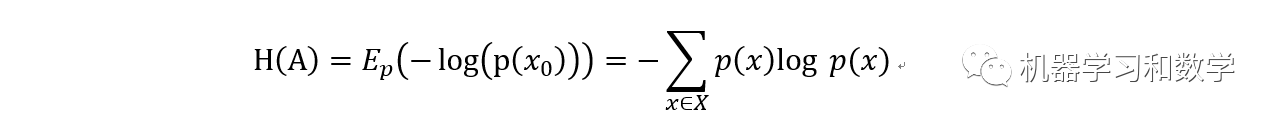
其中E表示数学期望。
2.3 相对熵
相对熵也叫KL(Kullback-Leibler divergence)散度,或者叫KL距离。这个东西现在很有名,因为最近两年比较火的生成对抗网络(Generative Adversarial Networks,GAN),大神Goodfellow在论文中,度量两个分布的距离就用到了KL散度,还有一个叫JS散度。他们都是度量两个随机变量分布的方法,当然还有其他一些方法,感兴趣的同学可以去看看参考文献2。 相对熵的定义为,给两个随机变量的分布A和B。
KL(AB)=E(log(A/B)) [不想敲公式,囧]
2.4 交叉熵
交叉熵和条件熵很像,定义为:
交叉熵(A,B)=条件熵(A,B)+H(A)
H(A)表示的是事件A的熵。
2.5 交叉熵损失函数
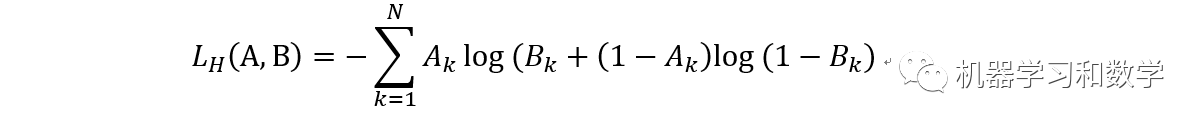
其中N表示样本量。
而在深度学习中,交叉熵损失函数定义为:
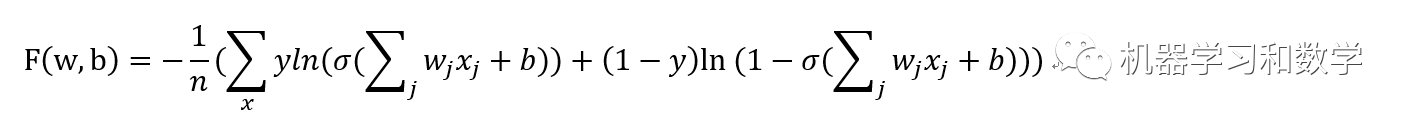
然后我们对w,b求导:
[ 自己求 ]
求导之后,可以看到导函数中没有激活函数的导数那一项。这样就巧妙的避免了激活函数的饱和性问题。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/alvinpy/blog/4392322



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



