这篇文章主要介绍基于Flink的MQ-Hive实时数据集成如何实现字节跳动,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
在数据中台建设过程中,一个典型的数据集成场景是将 MQ (Message Queue,例如 Kafka、RocketMQ 等)的数据导入到 Hive 中,以供下游数仓建设以及指标统计。由于 MQ-Hive 是数仓建设第一层,因此对数据的准确性以及实时性要求比较高。
已有方案及痛点
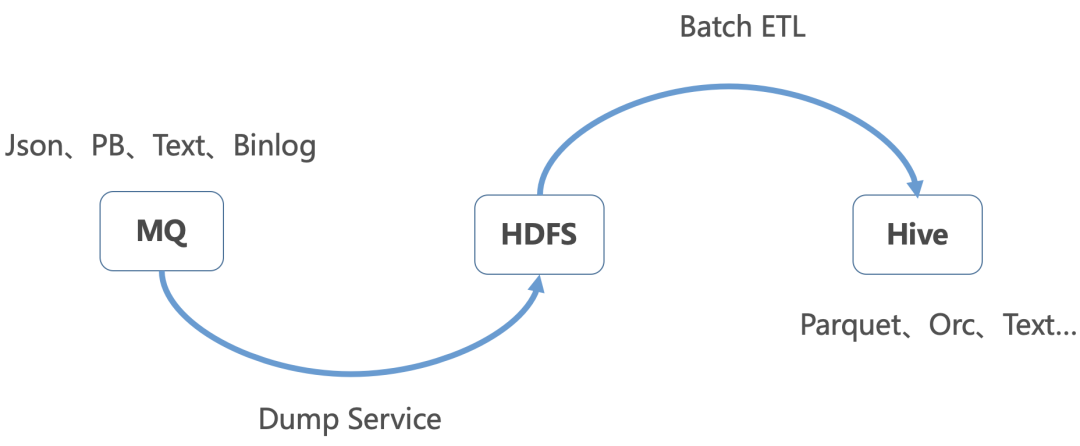
字节跳动内已有解决方案如下图所示,主要分了两个步骤:
通过 Dump 服务将 MQ 的数据写入到 HDFS 文件
再通过 Batch ETL 将 HDFS 数据导入到 Hive 中,并添加 Hive 分区
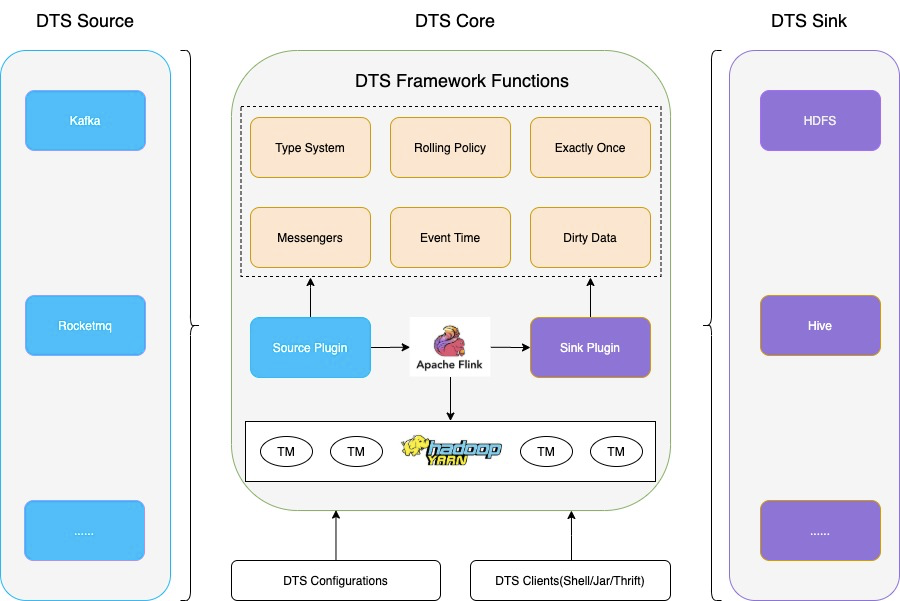
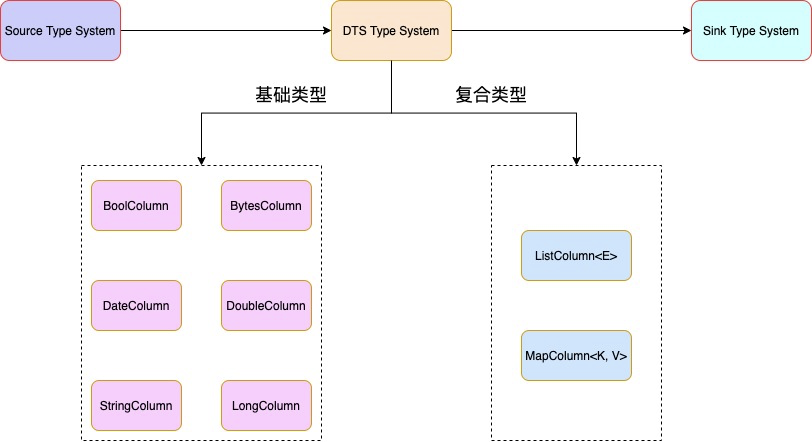
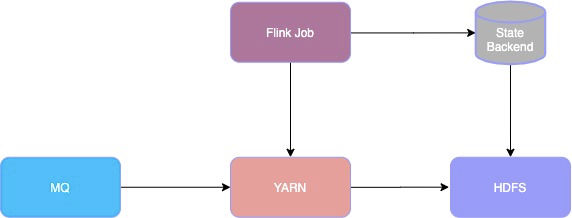
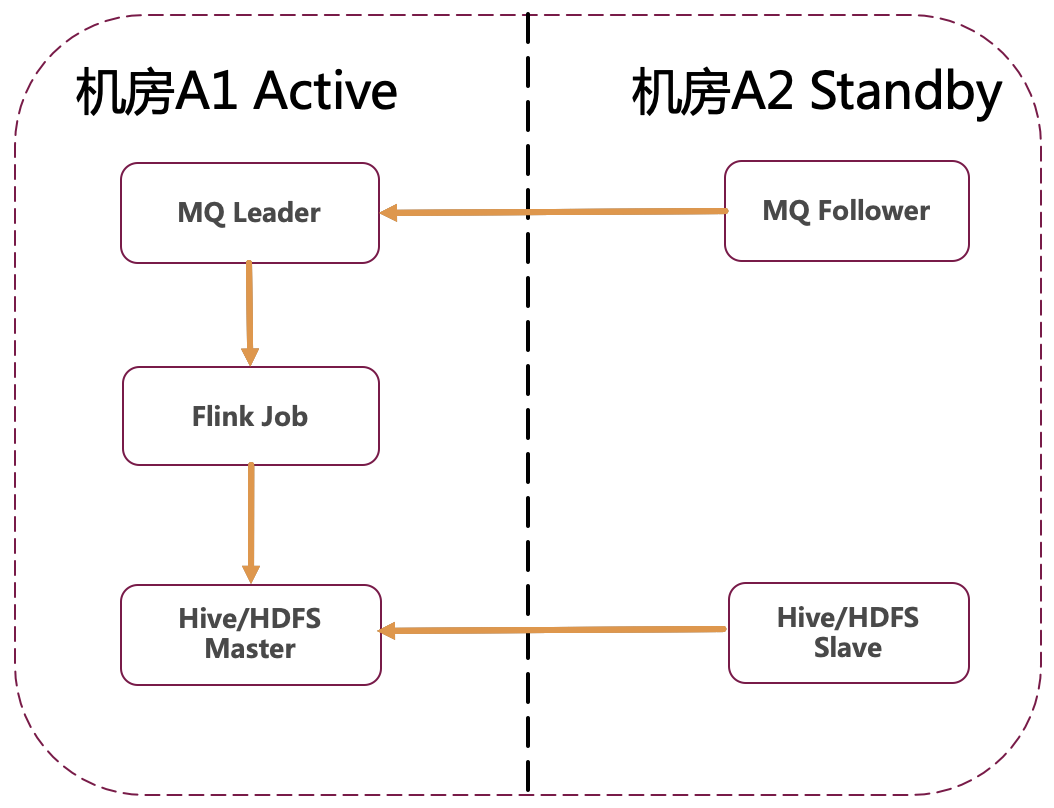
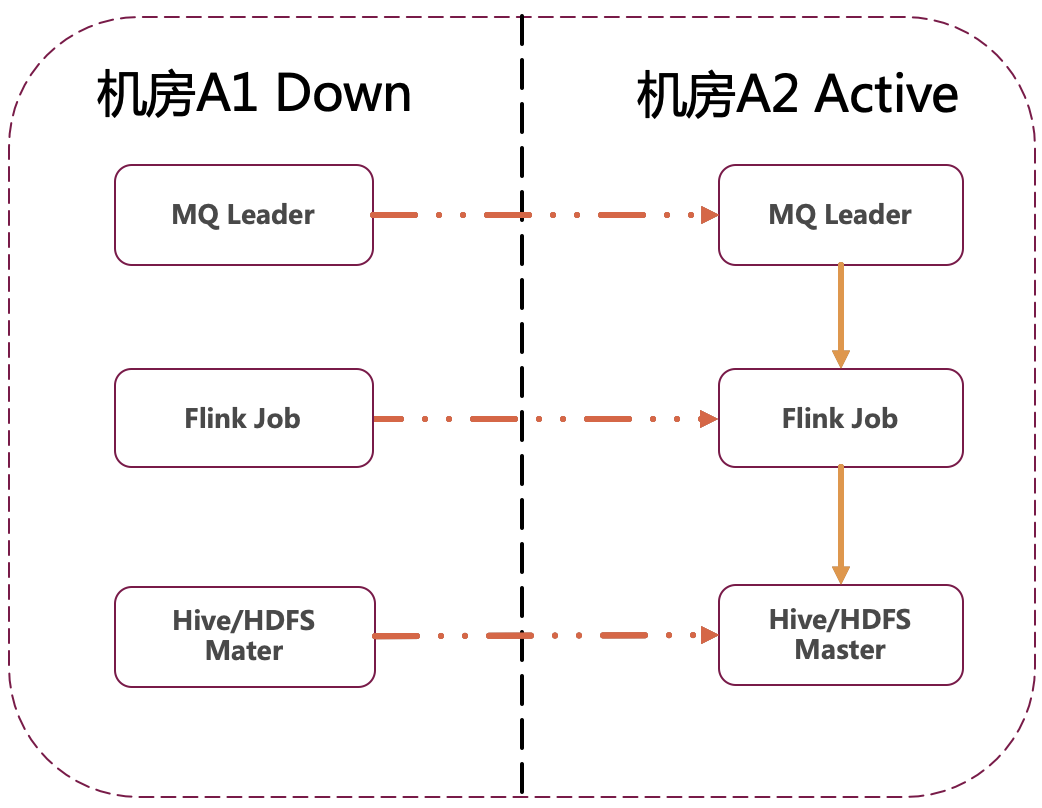
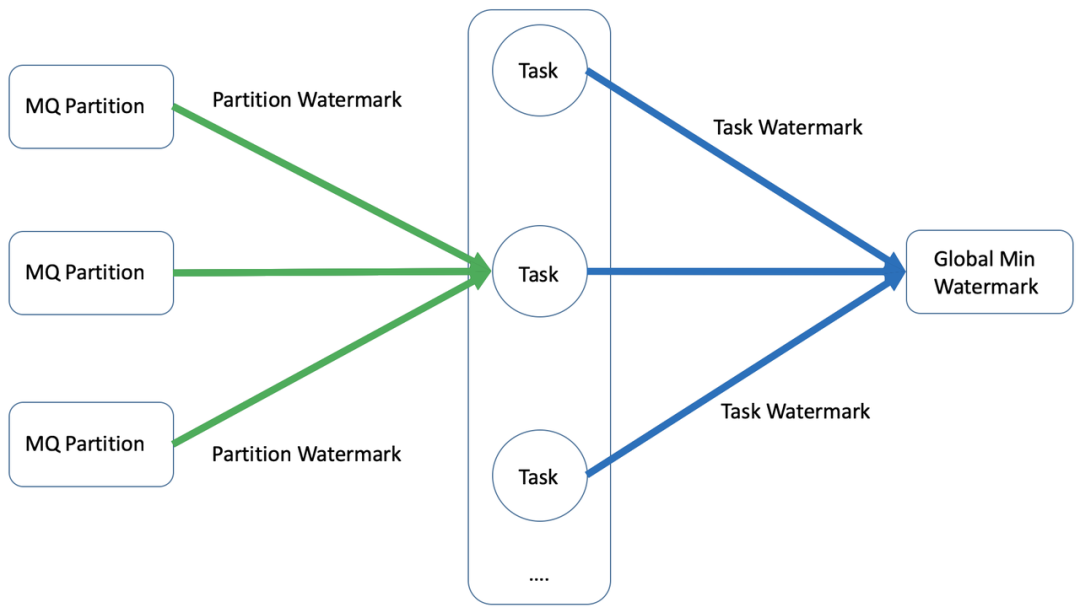
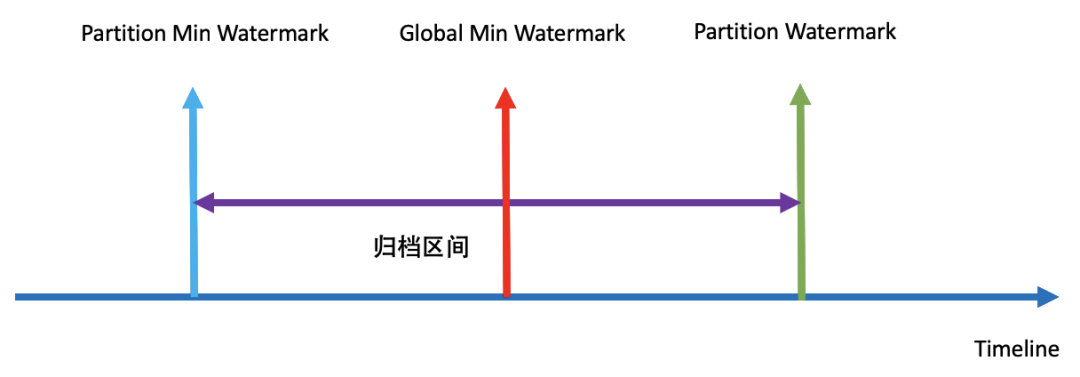
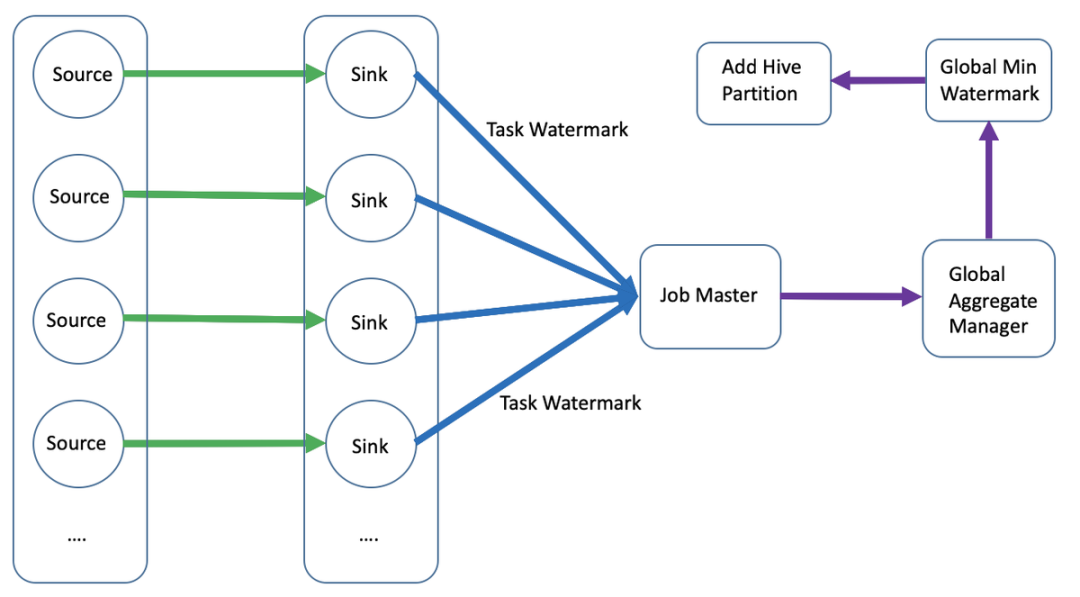
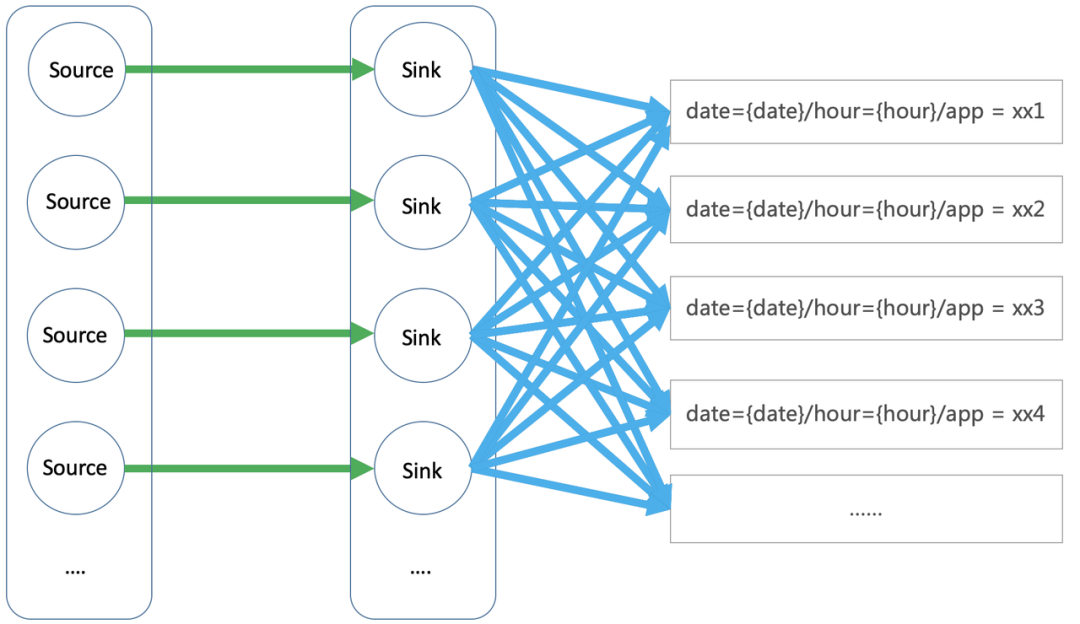
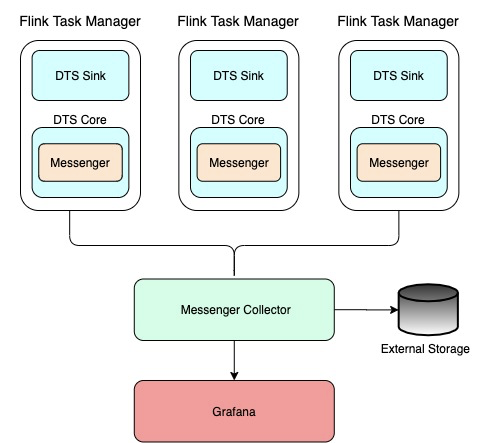
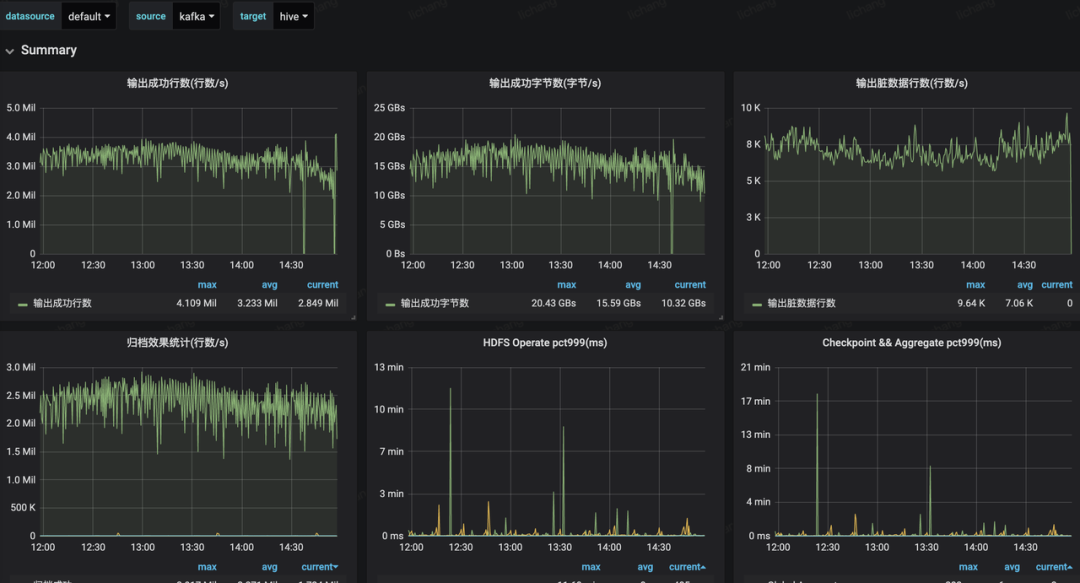
基于 Flink 实时解决方案
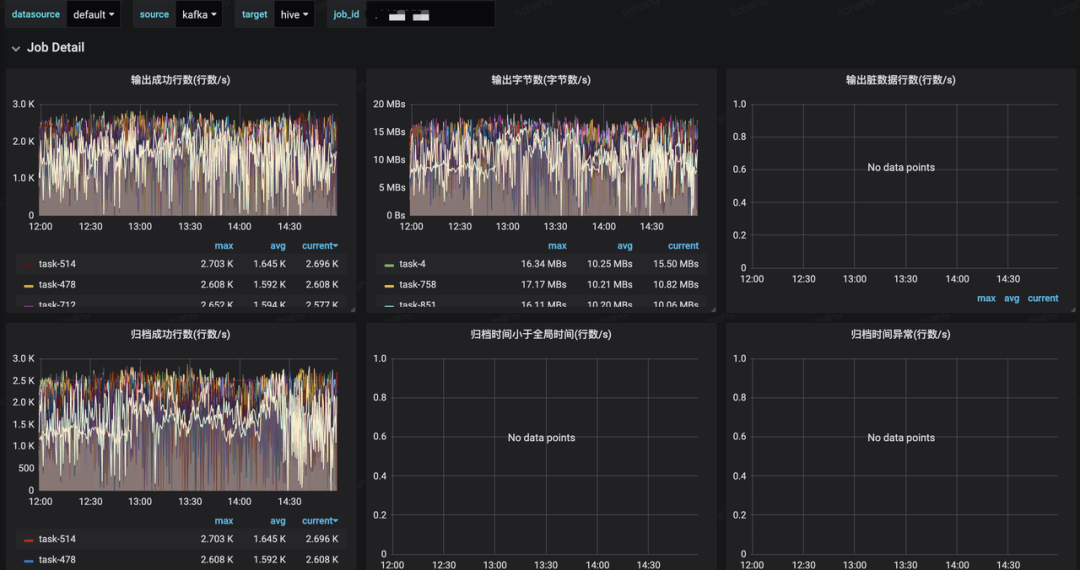
以上是“基于Flink的MQ-Hive实时数据集成如何实现字节跳动”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





