小编给大家分享一下GWAS分析中如何使用PCA校正群体分层,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
GWAS通过分析case/control组之间的差异来寻找与疾病关联的SNP位点,然而case和control两组之间,可能本身就存在一定的差异,会影响关联分析的检测。
Population stratification,称之为群体分层,是最常见的差异来源,指的是case/control组的样本来自于不同的祖先群体,其分型结果自然是有差异的。GWAS分析的目的是寻找由于疾病导致的差异,其他的差异都属于系统误差,在进行分析时,需要进行校正。
对于群体分层的校正,通常采主成分分析的方法,即PCA, 对应的文章发表在nature genetics上,链接如下
https://www.nature.com/articles/ng1847

核心处理如下图所示

对分型结果对应的矩阵进行PCA分析,该矩阵中行为SNP位点,列为样本,分型结果为0,1,2。0表示没有突变,1表示杂合突变,2表示纯合突变。PCA分析之后,可以得到每个样本在PC1,PC2等主成分轴上对应的位置。
PCA本质属于排序分析,距离近的样本拥有相似的属性,根据PCA之后得到的位置信息,可以绘制如下所示的散点图
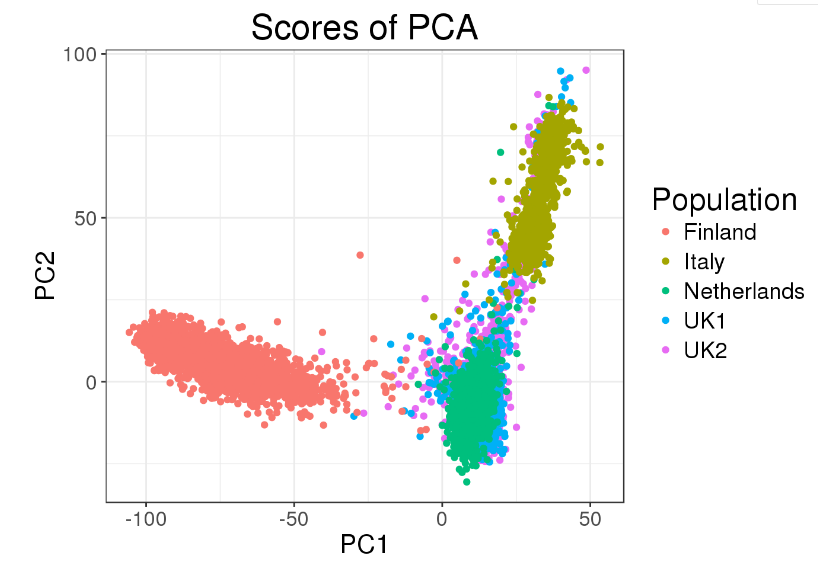
上图中每个点代表一个样本,绘图使用的信息就是这些样本在PC1和PC2两个轴上的位置。这样的散点图可以直观展示样本的分层情况,对于显著偏离总体的部分样本,可以去除之后在重新进行分析。在后续进行GWAS分析时,这些PC轴上的位置信息可以作为回归分析中的协变量,进行校正。
文章中将针对分型结果进行PCA分析的功能打包成了一个软件,名字为EIGENSTRAT, github的网址如下
https://github.com/chrchang/eigensoft/tree/master/EIGENSTRAT
该软件支持自动去除离群值样本,显示主成分的占比等很多功能,缺点就是执行速度比较慢。对于GWAS中的PCA而言,核心的信息其实就是样本在各个主成分轴上的位置信息,我们需要这些信息来进行后续的校正。
面对GWAS规模的分型结果,运行速度是非常重要的一个因素。为此,实践中常常采用以下两款软件
用法如下
plink \
--bfile sample \
--pca --out pca用法如下
gcta64 \
--bfile sample \
--make-grm \
--thread-num 5 \
--out gcta
gcta64 \
--grm gcta \
--pca 20 \
--thread-num 5 \
--out pca二者输出结果虽然不是完全相同,但是分布的趋势是一致的。不同之处在于,GCTA支持多线程,运行速度更快。输出结果有多个文件,核心是一个后缀为eigenvec的文件,该文件保存了样本在各个主成分轴上的位置信息,可以用于后续的校正。
这两个软件运行速度快,但是有个缺点就是不会输出各个主成分的占比,如果想要这个信息,可以考虑类似功能的R包,比如vcfR,SNPRelate,bigsnpr等。
以上是“GWAS分析中如何使用PCA校正群体分层”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





