[TOC]
主要是监听网络端口中的数据,并实时进行wc的计算。
测试代码如下:
package cn.xpleaf.bigdata.spark.java.streaming.p1;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.Arrays;
/**
* 使用Java开发SparkStreaming的第一个应用程序
*
* 用于监听网络socket中的一个端口,实时获取对应的文本内容
* 计算文本内容中的每一个单词出现的次数
*/
public class _01SparkStreamingNetWorkWCOps {
public static void main(String[] args) {
if(args == null || args.length < 2) {
System.err.println("Parameter Errors! Usage: <hostname> <port>");
System.exit(-1);
}
Logger.getLogger("org.apache.spark").setLevel(Level.OFF);
SparkConf conf = new SparkConf()
.setAppName(_01SparkStreamingNetWorkWCOps.class.getSimpleName())
/*
* 设置为local是无法计算数据,但是能够接收数据
* 设置为local[2]是既可以计算数据,也可以接收数据
* 当master被设置为local的时候,只有一个线程,且只能被用来接收外部的数据,所以不能够进行计算,如此便不会做对应的输出
* 所以在使用的本地模式时,同时是监听网络socket数据,线程个数必须大于等于2
*/
.setMaster("local[2]");
/**
* 第二个参数:Duration是SparkStreaming用于进行采集多长时间段内的数据将其拆分成一个个batch
* 该例表示每隔2秒采集一次数据,将数据打散成一个个batch(其实就是SparkCore中的一个个RDD)
*/
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(2));
String hostname = args[0].trim();
int port = Integer.valueOf(args[1].trim());
JavaReceiverInputDStream<String> lineDStream = jsc.socketTextStream(hostname, port);// 默认的持久化级别StorageLevel.MEMORY_AND_DISK_SER_2
JavaDStream<String> wordsDStream = lineDStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
});
JavaPairDStream<String, Integer> pairsDStream = wordsDStream.mapToPair(word -> {
return new Tuple2<String, Integer>(word, 1);
});
JavaPairDStream<String, Integer> retDStream = pairsDStream.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
retDStream.print();
// 启动流式计算
jsc.start();
// 等待执行结束
jsc.awaitTermination();
System.out.println("结束了没有呀,哈哈哈~");
jsc.close();
}
}启动程序,同时在主机上使用nc命令进行操作:
[uplooking@uplooking01 ~]$ nc -lk 4893
hello youe hello he hello me输出结果如下:
-------------------------------------------
Time: 1525929096000 ms
-------------------------------------------
(youe,1)
(hello,3)
(me,1)
(he,1)同时也可以在Spark UI上查看相应的作业执行情况:

可以看到,每2秒就会执行一次计算,即每隔2秒采集一次数据,将数据打散成一个个batch(其实就是SparkCore中的一个个RDD)。
测试代码如下:
package cn.xpleaf.bigdata.spark.scala.streaming.p1
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object _01SparkStreamingNetWorkOps {
def main(args: Array[String]): Unit = {
if (args == null || args.length < 2) {
System.err.println(
"""Parameter Errors! Usage: <hostname> <port>
|hostname: 监听的网络socket的主机名或ip地址
|port: 监听的网络socket的端口
""".stripMargin)
System.exit(-1)
}
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
val conf = new SparkConf()
.setAppName(_01SparkStreamingNetWorkOps.getClass.getSimpleName)
.setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(2))
val hostname = args(0).trim
val port = args(1).trim.toInt
val linesDStream:ReceiverInputDStream[String] = ssc.socketTextStream(hostname, port)
val wordsDStream:DStream[String] = linesDStream.flatMap({case line => line.split(" ")})
val pairsDStream:DStream[(String, Integer)] = wordsDStream.map({case word => (word, 1)})
val retDStream:DStream[(String, Integer)] = pairsDStream.reduceByKey{case (v1, v2) => v1 + v2}
retDStream.print()
ssc.start()
ssc.awaitTermination()
ssc.stop() // stop中的boolean参数,设置为true,关闭该ssc对应的SparkContext,默认为false,只关闭自身
}
}启动程序,同时在主机上使用nc命令进行操作:
[uplooking@uplooking01 ~]$ nc -lk 4893
hello youe hello he hello me输出结果如下:
-------------------------------------------
Time: 1525929574000 ms
-------------------------------------------
(youe,1)
(hello,3)
(me,1)
(he,1)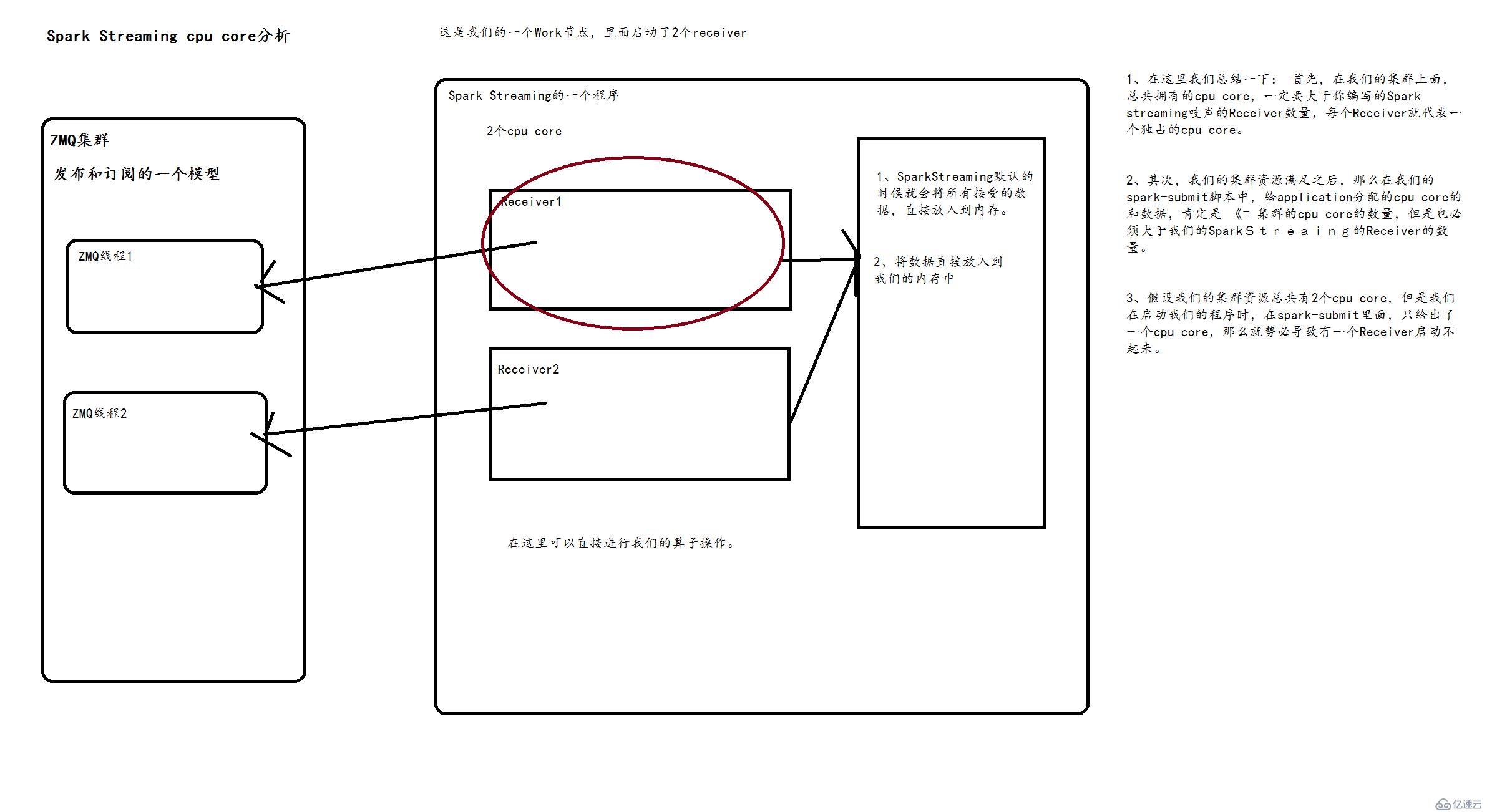
1、在Spark中有两种创建StreamingContext的方式
1)根据SparkConf进行创建
val conf = new SparkConf().setAppName(appname).setMaster(master);
val ssc = new StreamingContext(conf, Seconds(10));2)还可以根据SparkContext进行创建
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(10));appname,是用来在Spark UI上显示的应用名称。master,是一个Spark、Mesos或者Yarn集群的URL,或者是local[*]。
2、batch interval:Seconds(10)可以根据我们自己应用程序的情况进行不同的设置。
一、一个StreamingContext定义之后,必须执行以下程序进行实时计算的执行
1、创建输入DStream来创建输入不同的数据源。
2、对DStream定义transformation和output等各种算子操作,来定义我们需要的各种实时计算逻辑。
3、调用StreamingContext的start()方法,进行启动我们的实时处理数据。
4、调用StreamingContext的awaitTermination()方法,来等待应用程序的终止。可以使用CTRL+C手动停止,或者就是让它持续不断的运行进行计算。
5、也可以通过调用StreamingContext的stop()方法,来停止应用程序。
二、备注(十分重要)
1、只要我们一个StreamingContext启动之后,我们就不能再往这个Application其中添加任何计算逻辑了。比如执行start()方法之后,还给某个DStream执行一个算子,这是不允许的。
2、一个StreamingContext停止之后,是肯定不能够重启的。调用stop()之后,不能再调用start()
3、必须保证一个JVM同时只能有一个StreamingContext启动。在你的应用程序中,不能创建两个StreamingContext。
4、调用stop()方法时,会同时停止内部的SparkContext,如果不希望如此,还希望后面继续使用SparkContext创建其他类型的Context,比如SQLContext,那么就用stop(false)。
5、一个SparkContext可以创建多个StreamingContext,只要上一个先用stop(false)停止,再创建下一个即可。(注意与第2点的区别,这里是再创建了一个StreamingContext)

输入DStream代表了来自数据源的输入数据流。我们之前做过了一些例子,比如从文件读取、从TCP、从HDFS读取等。每个DSteam都会绑定一个Receiver对象,该对象是一个关键的核心组件,用来从我们的各种数据源接受数据,并将其存储在Spark的内存当中,这个内存的StorageLevel,我们可以自己进行指定,老师在以后的例子中会讲解这部分。
Spark Streaming提供了两种内置的数据源支持:
1、基础数据源:SSC API中直接提供了对这些数据源的支持,比如文件、tcp socket、Akka Actor等。
2、高级数据源:比如Kafka、Flume、Kinesis和Twitter等数据源,要引入第三方的JAR来完成我们的工作。
3、自定义数据源:比如我们的ZMQ、RabbitMQ、ActiveMQ等任何格式的自定义数据源。关于自定义数据源,老师在讲解最后一个项目的时候,会使用此自定义数据源如果从ZMQ中读取数据。官方提供的Spark-ZMQ是基于zmq2.0版本的,因为现在的 生产环境都是基于ZMQ4以上的版本了,所以必须自己定义并实现了一个自定义的receiver机制。
1、如果我们想要在我们的Spark Streaming应用中并行读取N多数据的话,我们可以启动创建多个DStream。这样子就会创建多个Receiver,老师最多的一个案例是启动了128个Receive,每个receiver每秒的数据是1000W以上。
2、但是要注意的是,我们Spark Streaming Application的Executor进程,是个长时间运行的一个进程,因此它会独占分给他的cpu core。所以它只能自己处理这件事情了,不能再干其他活了。
3、使用本地模式local运行我们的Spark Streaming程序时,绝对不能使用local或者 local[1]的模式。因为Spark Streaming运行的时候,必须要至少要有2个线程。如果只给了一条的话,Spark Streaming Application程序会直接hang在哪儿。 两条线程的一条用来分配给Receiver接收数据,另外一条线程用来处理接受到的数据。因此我们想要进行本地测试的话,必须满足local[N],这个N一定要大于2
4、如果我们想要在我们的Spark进群上运行的话,那么首先,必须要求我们的集群每个节点上,有>1个cpu core。其次,给Spark Streaming的每个executor分配的core,必须>1,这样,才能保证分配到executor上运行的输入DStream,两条线程并行,一条运行Receiver,接收数据;一条处理数据。否则的话,只会接收数据,不会处理数据。
基于HDFS文件的实时计算,其实就是监控我们的一个HDFS目录,只要其中有新文件出现,就实时处理。相当于处理实时的文件流。
===》Spark Streaming会监视指定的HDFS目录,并且处理出现在目录中的文件。
1)在HDFS中的所有目录下的文件,必须满足相同的格式,不然的话,不容易处理。必须使用移动或者重命名的方式,将文件移入目录。一旦处理之后,文件的内容及时改变,也不会再处理了。
2)基于HDFS的数据结源读取是没有receiver的,因此不会占用一个cpu core。
3)实际上在下面的测试案例中,一直也没有效果,也就是监听不到HDFS中的文件,本地文件也没有效果;
测试代码如下:
package cn.xpleaf.bigdata.spark.scala.streaming.p1
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* SparkStreaming监听hdfs的某一个目录的变化(新增文件)
*/
object _02SparkStreamingHDFSOps {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
val conf = new SparkConf()
.setAppName(_02SparkStreamingHDFSOps.getClass.getSimpleName)
.setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(5))
val linesDStream:DStream[String] = ssc.textFileStream("hdfs://ns1/input/spark/streaming/")
// val linesDStream:DStream[String] = ssc.textFileStream("D:/data/spark/streaming")
linesDStream.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).print()
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}1、利用Kafka的Receiver方式进行集成
2、利用Kafka的Direct方式进行集成
Spark-Streaming获取kafka数据的两种方式-Receiver与Direct的方式,可以从代码中简单理解成Receiver方式是通过zookeeper来连接kafka队列,Direct方式是直接连接到kafka的节点上获取数据了。
这种方式使用Receiver来获取数据。Receiver是使用Kafka的高层次Consumer API来实现的。receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming启动的job会去处理那些数据。然而,在默认的配置下,这种方式可能会因为底层的失败而丢失数据。如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL)。该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中。所以,即使底层节点出现了失败,也可以使用预写日志中的数据进行恢复。
补充说明:
(1)、Kafka中的topic的partition,与Spark中的RDD的partition是没有关系的。所以,在KafkaUtils.createStream()中,提高partition的数量,只会增加一个Receiver中,读取partition的线程的数量。不会增加Spark处理数据的并行度。
(2)、可以创建多个Kafka输入DStream,使用不同的consumer group和topic,来通过多个receiver并行接收数据。
(3)、如果基于容错的文件系统,比如HDFS,启用了预写日志机制,接收到的数据都会被复制一份到预写日志中。因此,在KafkaUtils.createStream()中,设置的持久化级别是StorageLevel.MEMORY_AND_DISK_SER。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>1.6.2</version>
</dependency>启动kafka服务
kafka-server-start.sh -daemon config/server.properties创建topic
kafka-topics.sh --create --topic spark-kafka --zookeeper uplooking01:2181,uplooking02:2181,uplooking03:2181 --partitions 3 --replication-factor 3列举kafka中已经创建的topic
kafka-topics.sh --list --zookeeper uplooking01:2181,uplooking02:2181,uplooking03:2181列举每个节点都保护那些topic、Partition
kafka-topics.sh --describe --zookeeper uplooking01:2181, uplooking02:2181, uplooking03:21821 --topic spark-kafka
leader:负责处理消息的读和写,leader是从所有节点中随机选择的.
replicas:列出了所有的副本节点,不管节点是否在服务中.
isr:是正在服务中的节点.产生数据
kafka-console-producer.sh --topic spark-kafka --broker-list uplooking01:9092,uplooking02:9092,uplooking03:9092消费数据
kafka-console-consumer.sh --topic spark-kafka --zookeeper uplooking01:2181,uplooking02:2181,uplooking03:2181测试代码如下:
package cn.xpleaf.bigdata.spark.scala.streaming.p1
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Kafka和SparkStreaming基于Receiver的模式集成
*/
object _03SparkStreamingKafkaReceiverOps {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
val conf = new SparkConf()
.setAppName(_03SparkStreamingKafkaReceiverOps.getClass.getSimpleName)
.setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(5))
// ssc.checkpoint("hdfs://ns1/checkpoint/streaming/kafka") // checkpoint文件保存到hdfs中
ssc.checkpoint("file:///D:/data/spark/streaming/checkpoint/streaming/kafka") // checkpoint文件保存到本地文件系统
/**
* 使用Kafka Receiver的方式,来创建的输入DStream,需要使用SparkStreaming提供的Kafka整合API
* KafkaUtils
*/
val zkQuorum = "uplooking01:2181,uplooking02:2181,uplooking03:2181"
val groupId = "kafka-receiver-group-id"
val topics:Map[String, Int] = Map("spark-kafka"->3)
// ReceiverInputDStream中的key就是当前一条数据在kafka中的key,value就是该条数据对应的value
val linesDStream:ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkQuorum, groupId, topics)
val retDStream = linesDStream.map(t => t._2).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)
retDStream.print()
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}在kafka中生产数据:
[uplooking@uplooking02 kafka]$ kafka-console-producer.sh --topic spark-kafka --broker-list uplooking01:9092,uplooking02:9092,uplooking03:9092
hello you hello he hello me输出结果如下:
-------------------------------------------
Time: 1525965130000 ms
-------------------------------------------
(hello,3)
(me,1)
(you,1)
(he,1)在上面的代码中,还启用了Spark Streaming的预写日志机制(Write Ahead Log,WAL)。
如果数据保存在本地文件系统,则如下:
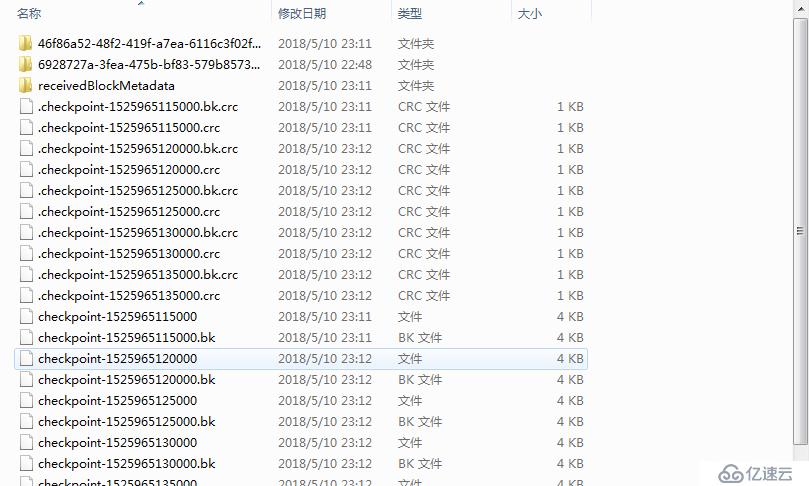
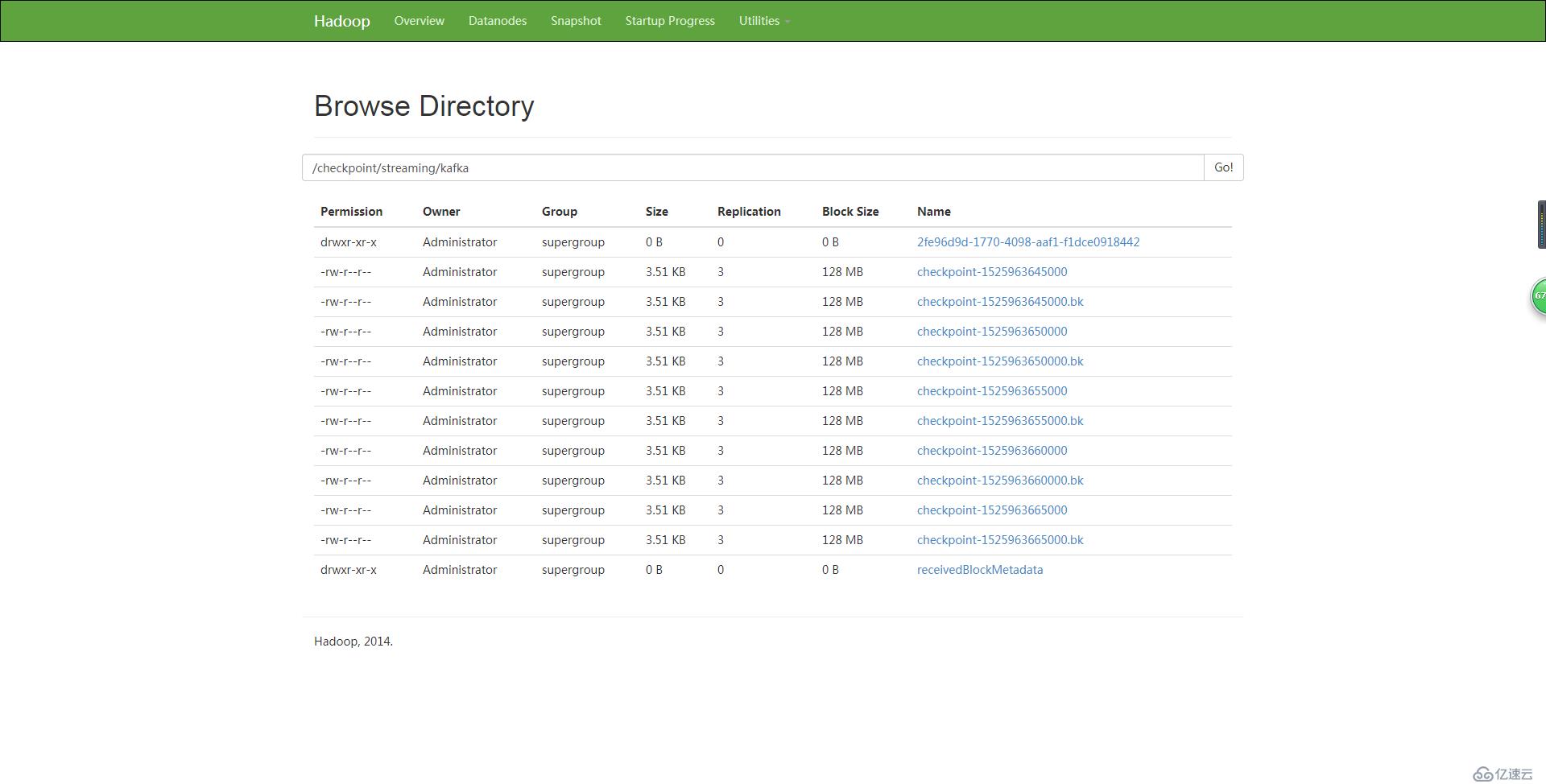
如果数据保存在HDFS中,则如下:
(1)Direct的方式是会直接操作kafka底层的元数据信息,这样如果计算失败了,可以把数据重新读一下,重新处理。即数据一定会被处理。拉数据,是RDD在执行的时候直接去拉数据。
(2)由于直接操作的是kafka,kafka就相当于你底层的文件系统。这个时候能保证严格的事务一致性,即一定会被处理,而且只会被处理一次。而Receiver的方式则不能保证,因为Receiver和ZK中的数据可能不同步,Spark Streaming可能会重复消费数据,这个调优可以解决,但显然没有Direct方便。而Direct api直接是操作kafka的,spark streaming自己负责追踪消费这个数据的偏移量或者offset,并且自己保存到checkpoint,所以它的数据一定是同步的,一定不会被重复。即使重启也不会重复,因为checkpoint了,但是程序升级的时候,不能读取原先的checkpoint,面对升级checkpoint无效这个问题,怎么解决呢?升级的时候读取我指定的备份就可以了,即手动的指定checkpoint也是可以的,这就再次完美的确保了事务性,有且仅有一次的事务机制。那么怎么手动checkpoint呢?构建SparkStreaming的时候,有getorCreate这个api,它就会获取checkpoint的内容,具体指定下这个checkpoint在哪就好了。
(3)由于底层是直接读数据,没有所谓的Receiver,直接是周期性(Batch Intervel)的查询kafka,处理数据的时候,我们会使用基于kafka原生的Consumer api来获取kafka中特定范围(offset范围)中的数据。这个时候,Direct Api访问kafka带来的一个显而易见的性能上的好处就是,如果你要读取多个partition,Spark也会创建RDD的partition,这个时候RDD的partition和kafka的partition是一致的。而Receiver的方式,这2个partition是没任何关系的。这个优势是你的RDD,其实本质上讲在底层读取kafka的时候,kafka的partition就相当于原先hdfs上的一个block。这就符合了数据本地性。RDD和kafka数据都在这边。所以读数据的地方,处理数据的地方和驱动数据处理的程序都在同样的机器上,这样就可以极大的提高性能。不足之处是由于RDD和kafka的patition是一对一的,想提高并行度就会比较麻烦。提高并行度还是repartition,即重新分区,因为产生shuffle,很耗时。这个问题,以后也许新版本可以自由配置比例,不是一对一。因为提高并行度,可以更好的利用集群的计算资源,这是很有意义的。
(4)不需要开启wal机制,从数据零丢失的角度来看,极大的提升了效率,还至少能节省一倍的磁盘空间。从kafka获取数据,比从hdfs获取数据,因为zero copy的方式,速度肯定更快。
从高层次的角度看,之前的和Kafka集成方案(reciever方法)使用WAL工作方式如下:
1)运行在Spark workers/executors上的Kafka Receivers连续不断地从Kafka中读取数据,其中用到了Kafka中高层次的消费者API。
2)接收到的数据被存储在Spark workers/executors中的内存,同时也被写入到WAL中。只有接收到的数据被持久化到log中,Kafka Receivers才会去更新Zookeeper中Kafka的偏移量。
3)接收到的数据和WAL存储位置信息被可靠地存储,如果期间出现故障,这些信息被用来从错误中恢复,并继续处理数据。
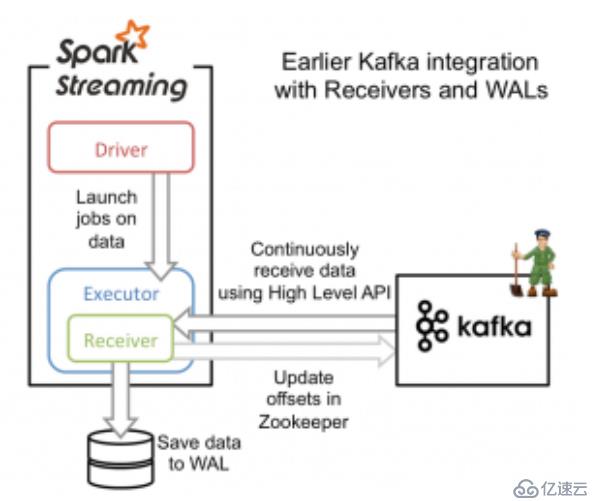
为了构建这个系统,新引入的Direct API采用完全不同于Receivers和WALs的处理方式。它不是启动一个Receivers来连续不断地从Kafka中接收数据并写入到WAL中,而是简单地给出每个batch区间需要读取的偏移量位置,最后,每个batch的Job被运行,那些对应偏移量的数据在Kafka中已经准备好了。这些偏移量信息也被可靠地存储(checkpoint),在从失败中恢复
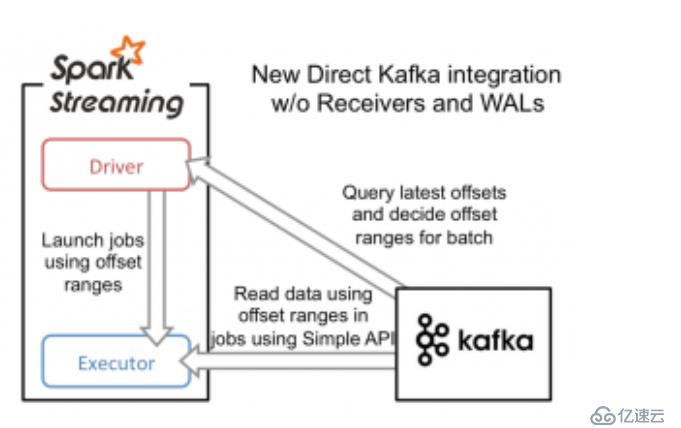
测试代码如下:
package cn.xpleaf.bigdata.spark.scala.streaming.p1
import kafka.serializer.StringDecoder
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Kafka和SparkStreaming基于Direct的模式集成
*
* 在公司中使用Kafka-Direct方式
*/
object _04SparkStreamingKafkaDirectOps {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
val conf = new SparkConf()
.setAppName(_04SparkStreamingKafkaDirectOps.getClass.getSimpleName)
.setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(5))
// ssc.checkpoint("hdfs://ns1/checkpoint/streaming/kafka") // checkpoint文件也是可以保存到hdfs中的,不过必要性不大了,对于direct的方式来说
val kafkaParams:Map[String, String] = Map("metadata.broker.list"-> "uplooking01:9092,uplooking02:9092,uplooking03:9092")
val topics:Set[String] = Set("spark-kafka")
val linesDStream:InputDStream[(String, String)] = KafkaUtils.
// 参数分别为:key类型,value类型,key的×××,value的×××
createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
val retDStream = linesDStream.map(t => t._2).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)
retDStream.print()
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}生产数据:
[uplooking@uplooking02 kafka]$ kafka-console-producer.sh --topic spark-kafka --broker-list uplooking01:9092,uplooking02:9092,uplooking03:9092
hello you hello he hello me输出结果如下:
-------------------------------------------
Time: 1525966750000 ms
-------------------------------------------
(hello,3)
(me,1)
(you,1)
(he,1)测试代码如下:
package cn.xpleaf.bigdata.spark.scala.streaming.p1
import java.io.{BufferedReader, InputStreamReader}
import java.net.Socket
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* SparkStreaming自定义Receiver
* 通过模拟Network来学习自定义Receiver
*
* 自定义的步骤:
* 1.创建一个类继承一个类或者实现某个接口
* 2.复写启动的个别方法
* 3.进行注册调用
*/
object _05SparkStreamingCustomReceiverOps {
def main(args: Array[String]): Unit = {
if (args == null || args.length < 2) {
System.err.println(
"""Parameter Errors! Usage: <hostname> <port>
|hostname: 监听的网络socket的主机名或ip地址
|port: 监听的网络socket的端口
""".stripMargin)
System.exit(-1)
}
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
val conf = new SparkConf()
.setAppName(_05SparkStreamingCustomReceiverOps.getClass.getSimpleName)
.setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(5))
val hostname = args(0).trim
val port = args(1).trim.toInt
val linesDStream:ReceiverInputDStream[String] = ssc.receiverStream[String](new MyNetWorkReceiver(hostname, port))
val retDStream:DStream[(String, Int)] = linesDStream.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)
retDStream.print()
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
/**
* 自定义receiver
*/
class MyNetWorkReceiver(storageLevel:StorageLevel) extends Receiver[String](storageLevel) {
private var hostname:String = _
private var port:Int = _
def this(hostname:String, port:Int, storageLevel:StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2) {
this(storageLevel)
this.hostname = hostname
this.port = port
}
/**
* 启动及其初始化receiver资源
*/
override def onStart(): Unit = {
val thread = new Thread() {
override def run(): Unit = {
receive()
}
}
thread.setDaemon(true) // 设置成为后台线程
thread.start()
}
// 接收数据的核心api 读取网络socket中的数据
def receive(): Unit = {
val socket = new Socket(hostname, port)
val ins = socket.getInputStream()
val br = new BufferedReader(new InputStreamReader(ins))
var line:String = null
while((line = br.readLine()) != null) {
store(line)
}
ins.close()
socket.close()
}
override def onStop(): Unit = {
}
}启动nc,并输入数据:
[uplooking@uplooking01 ~]$ nc -lk 4893
hello you hello he hello me输出结果如下:
(hello,3)
(me,1)
(you,1)
(he,1)免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





